Hive:分区和分桶
简介
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”。
分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助。
分区是一种根据“分区列”(partition column)的值对表进行粗略划分的机制。Hive中每个分区对应着表很多的子目录,将所有的数据按照分区列放入到不同的子目录中去。
为什么要分区?
庞大的数据集可能需要耗费大量的时间去处理。在许多场景下,可以通过分区的方法减少每一次扫描总数据量,这种做法可以显著地改善性能。
数据会依照单个或多个列进行分区,通常按照时间、地域或者是商业维度进行分区。比如vido表,分区的依据可以是电影的种类和评级,另外,按照拍摄时间划分可能会得到更一致的结果。为了达到性能表现的一致性,对不同列的划分应该让数据尽可能均匀分布。最好的情况下,分区的划分条件总是能够对应where语句的部分查询条件。
Hive的分区使用HDFS的子目录功能实现。每一个子目录包含了分区对应的列名和每一列的值。但是由于HDFS并不支持大量的子目录,这也给分区的使用带来了限制。我们有必要对表中的分区数量进行预估,从而避免因为分区数量过大带来一系列问题。
Hive查询通常使用分区的列作为查询条件。这样的做法可以指定MapReduce任务在HDFS中指定的子目录下完成扫描的工作。HDFS的文件目录结构可以像索引一样高效利用。
1.Hive分区表
Hive使用select语句进行查询的时候一般会扫描整个表内容,会消耗很多时间做没必要的工作。
Hive可以在创建表的时候指定分区空间,这样在做查询的时候就可以很好的提高查询的效率。
创建分区表的语法:
create table tablename(
name string
)partitioned by(key,type...);
示例
drop table if exists employees;
create table if not exists employees(
name string,
salary float,
subordinate array<string>,
deductions map<string,float>,
address struct<street:string,city:string,num:int>
) partitioned by (date_time string,type string)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile
location '/hive/inner';
附:上述语句表示在建表时划分了date_time和type两个分区也叫双分区,一个分区的话就叫单分区,上述语句执行完以后我们查看表的结果会发现多了分区的两个字段。
desc employees;结果如下:
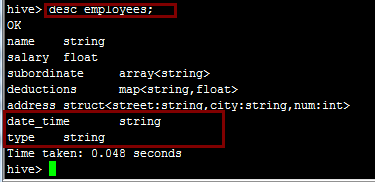
注:在文件系统中的表现为date_time为一个文件夹,type为date_time的子文件夹。
向分区表中插入数据(要指定分区)
hive> load data local inpath '/usr/local/src/employee_data' into table employees partition(date_time='2015-01_24',type='userInfo');
Copying data from file:/usr/local/src/employee_data
Copying file: file:/usr/local/src/employee_data
Loading data to table default.employees partition (date_time=2015-01_24, type=userInfo)
OK
Time taken: 0.22 seconds
hive>
数据插入后在文件系统中显示为:
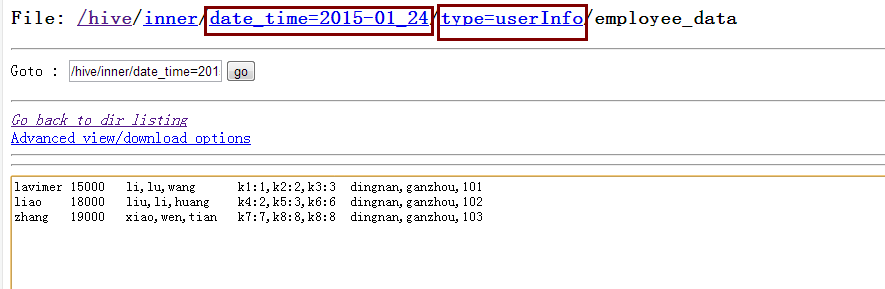
注:从上图中我们就可以发现type分区是作为子文件夹的形式存在的。
添加分区:
alter table employees add if not exists partition(date_time='2088-08-18',type='liaozhongmin');注:我们可以先添加分区,再向对应的分区中添加数据。
查看分区:
show partitions employees;附:employees在这里表示表名。
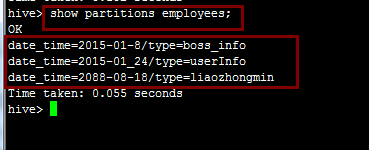
删除不想要的分区
alter table employees drop if exists partition(date_time='2015-01_24',type='userInfo');
再次查看分区:
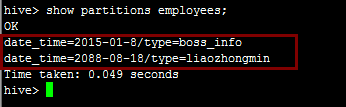
2.Hive桶表
对于每一个表或者是分区,Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive是针对某一列进行分桶。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶中。分桶的好处是可以获得更高的查询处理效率。使取样更高效。
示例:
create table bucketed_user(
id int,
name string
)
clustered by(id) sorted by(name) into 4 buckets
row format delimited fields terminated by '\t'
stored as textfile;
我们使用用户id来确定如何划分桶(Hive使用对值进行哈希并将结果除于桶的个数取余数的方式进行分桶)
另外一个要注意的问题是使用桶表的时候我们要开启桶表:
set hive.enforce.bucketing = true;
现在我们将表employees中name和salary查询出来再插入到这张表中:
insert overwrite table bucketed_user select salary,name from employees;
我们通过查询语句可以查看插进来的数据:
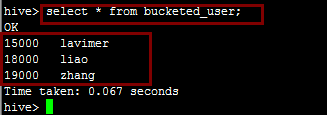
数据在文件中的表现形式如下,分成了四个桶:
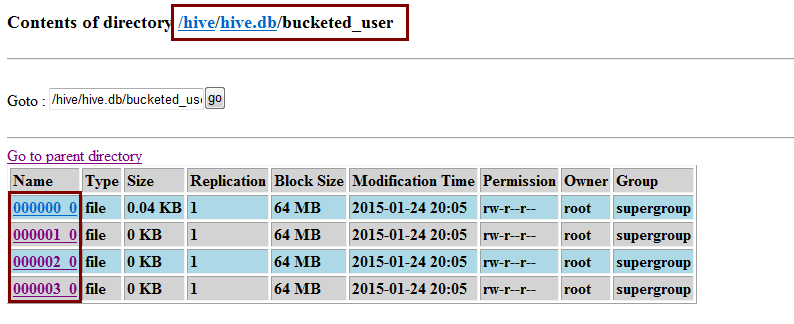
当从桶表中进行查询时,hive会根据分桶的字段进行计算分析出数据存放的桶中,然后直接到对应的桶中去取数据,这样做就很好的提高了效率。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
按我的理解,所谓Hive中的分桶,实际就是指的MapReduce中的分区。根据Reduce的数量,分成不同个数的文件。
分区和分桶最大的区别就是分桶随机分割数据库,分区是非随机分割数据库。
因为分桶是按照列的哈希函数进行分割的,相对比较平均;而分区是按照列的值来进行分割的,容易造成数据倾斜。
其次两者的另一个区别就是分桶是对应不同的文件(细粒度),分区是对应不同的文件夹(粗粒度)。
注意:普通表(外部表、内部表)、分区表这三个都是对应HDFS上的目录,桶表对应是目录里的文件
原文参考:https://blog.csdn.net/lzm1340458776/article/details/43085423