ext2文件系统
宗旨:技术的学习是有限的。分享的精神是无限的。
一、整体存储布局
一个磁盘能够划分成多个分区,每一个分区必须先用格式化工具(比如某种mkfs命令)格 式化成某种格式的文件系统,然后才干存储文件,格式化的过程会在磁盘上写一些管理存储布局的 信息。

文件系统中存储的最小单位是块(Block),一个块到底多大是在格式化时确定的,比如mke2fs的-b选项能够设定块大小为1024、 2048或4096字节。而上图中启动块(Boot Block) 的大小是确定的,就是1KB,启动块是由PC标准规定的,用来存储磁盘分区信息和启动信息,不论什么文件系统都不能使用启动块。
启动块之后才是ext2文件系统的開始。ext2文件系统将整个分区划成若干个相同大小的块组(Block Group),每一个块组都由下面部分组成。
1、 超级块(SuperBlock)
描写叙述整个分区的文件系统信息,比如块大小、文件系统版本、上次mount的时间等等。
超级块在每一个块组的开头都有一份拷贝。
2、 块组描写叙述符表(GDT,GroupDescriptor Table)
由非常多块组描写叙述符组成,整个分区分成多少个块组就相应有多少个块组描写叙述符。每一个块组描写叙述符(GroupDescriptor)存储一个块组的描写叙述信息,比如在这个块组中从哪里開始是inode表,从哪里開始是数据块。空暇的inode和数据块还有多少个等等。
和超级块类似。块组描写叙述符表在每一个块组的开头也都有一份拷贝,这些信息是非常重要的,一旦超级块意外损坏就会丢失整个分区的数据。一旦块组描写叙述符意外损坏就会丢失整个块组的数据,因此它们都有多份拷贝。通常内核仅仅用到第0个块组中的拷贝。当运行e2fsck检查文件系统一致性时。第0个块组中的超级块和块组描写叙述符表就会复制到其他块组。这样当第0个块组的开头意外损坏时就能够用其他拷贝来恢复。从而降低损失。
3、块位图(BlockBitmap)
一个块组中的块是这样利用的:数据块存储全部文件的数据,比方某个分区的块大小 是1024字节,某个文件是2049字节。那么就须要三个数据块来存,即使第三个块仅仅存了一个 字节也须要占用一个整块;超级块、块组描写叙述符表、块位图、 inode位图、 inode表这几部分 存储该块组的描写叙述信息。
那么怎样知道哪些块已经用来存储文件数据或其他描写叙述信息,哪些块仍然空暇可用呢?块位图就是用来描写叙述整个块组中哪些块已用哪些块空暇的,它本身占一个块,当中的每一个bit代表本块组中的一个块,这个bit为1表示该块已用。这个bit为0表示该块 空暇可用。
为什么用df命令统计整个磁盘的已用空间很快呢?由于仅仅须要查看每一个块组的块位图就可以。而不须要搜遍整个分区。相反,用du命令查看一个较大文件夹的已用空间就很慢。由于 不可避免地要搜遍整个文件夹的全部文件。
与此相联系的还有一个问题是:在格式化一个分区时到底会划出多少个块组呢?基本的限制在于块位图本身必须仅仅占一个块。用mke2fs格式化时默认块大小是1024字节,能够用-b參数指定块大小。如今设块大小指定为b字节,那么一个块能够有8b个bit。这样大小的一个块位图就 能够表示8b个块的占用情况,因此一个块组最多能够有8b个块。假设整个分区有s个块。那么就能够有s/(8b)个块组。格式化时能够用-g參数指定一个块组有多少个块,可是通常不须要手 动指定, mke2fs工具会计算出最优的数值。
4、 inode位图(inodeBitmap)
和块位图类似。本身占一个块,当中每一个bit表示一个inode是否空暇可用。
5、 inode表(inodeTable)
我们知道,一个文件除了数据须要存储之外,一些描写叙述信息也须要存储,比如文件类型(常 规、文件夹、符号链接等)。权限。文件大小。创建/改动/訪问时间等,也就是ls -l命令看到 的那些信息。这些信息存在inode中而不是数据块中。
每一个文件都有一个inode,一个块组中的全部inode组成了inode表。
inode表占多少个块在格式化时就要决定并写入块组描写叙述符中, mke2fs格式化工具的默认策略 是一个块组有多少个8KB就分配多少个inode。
因为数据块占了整个块组的绝大部分,也能够 近似觉得数据块有多少个8KB就分配多少个inode,换句话说。假设平均每一个文件的大小 是8KB,当分区存满的时候inode表会得到比較充分的利用。数据块也不浪费。假设这个分区 存的都是非常大的文件(比方电影),则数据块用完的时候inode会有一些浪费,假设这个分区 存的都是非常小的文件(比方源码),则有可能数据块还没用完inode就已经用完了。数据块 可能有非常大的浪费。
假设用户在格式化时可以对这个分区以后要存储的文件大小做一个预測,也可以用mke2fs的-i參数手动指定每多少个字节分配一个inode。
6、 数据块(DataBlock)
依据不同的文件类型有下面几种情况 对于常规文件,文件的数据存储在数据块中。 对于文件夹。该文件夹下的全部文件名称和文件夹名存储在数据块中,注意文件名称保存在它所在 文件夹的数据块中。除文件名称之外, ls -l命令看到的其他信息都保存在该文件的inode中。注意这个概念:文件夹也是一种文件,是一种特殊类型的文件。对于符号链接,假设目标路径名较短则直接保存在inode中以便更快地查找,假设目标 路径名较长则分配一个数据块来保存。设备文件、 FIFO和socket等特殊文件没有数据块,设备文件的主设备号和次设备号保存 在inode中。
二、研究文件系统格式
首先创建一个1MB的文件并清零(用一个文件取代整个分区)
dd if=/dev/zero of=fs count=256 bs=4K
cp命令能够把一个文件拷贝成还有一个文件。而dd命令能够把一个文件的一部分拷贝成还有一个文件。这个命令的作用是把/dev/zero文件开头的1M(256×4K)字节拷贝成文件名称为fs的文件。
/dev/zero是一个特殊的设备文件,它没有磁盘数据块,对它进行读操作传给设 备号为1, 5的驱动程序。
/dev/zero这个文件能够看作是无穷大的,无论从哪里開始读,读出来的 都是字节0x00。因此这个命令拷贝了1M个0x00到fs文件。 if和of參数表示输入文件和输出文件,count和bs參数表示拷贝多少次,每次拷多少字节。

如今fs的大小仍然是1MB,但不再是全0了。当中已经有了块组和描写叙述信息。
用dumpe2fs工具能够 查看这个分区的超级块和块组描写叙述符表中的信息:
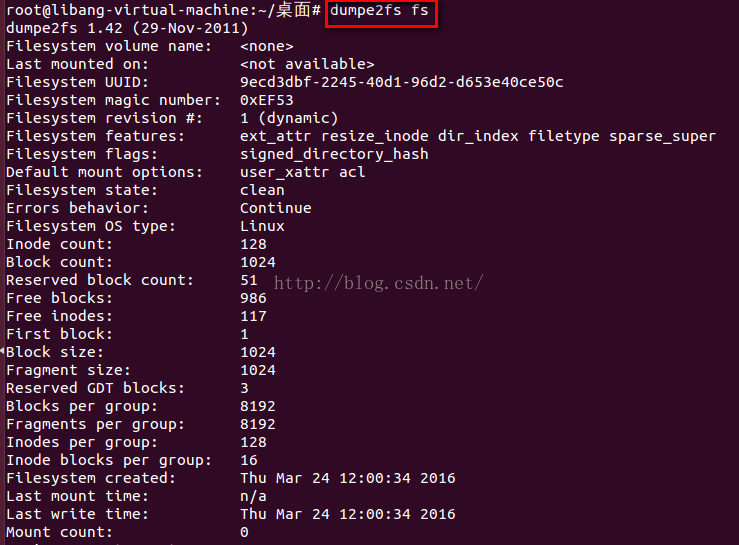

依据上面讲过的知识简单计算一下,块大小是1024字节, 1MB的分区共同拥有1024个块,第0个块是启 动块,启动块之后才算ext2文件系统的開始,因此Group 0占领第1个到第1023个块,共1023个 块。块位图占一个块。共同拥有1024×8=8192个bit,足够表示这1023个块了,因此仅仅要一个块组就够了。默认是每8KB分配一个inode。因此1MB的分区相应128个inode,这些数据都和dumpe2fs的输 出吻合。
用常规文件制作而成的文件系统也能够像磁盘分区一样mount到某个文件夹:
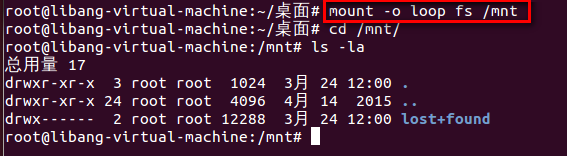
-o loop选项告诉mount这是一个常规文件而不是一个块设备文件。
mount会把它的数据块中的数据 当作分区格式来解释。文件系统格式化之后在根文件夹下自己主动生成三个子目 录:., ..和lost+found。其他子文件夹下的.表示当前文件夹, ..表示上一级文件夹,而根文件夹 的.和..都表示根文件夹本身。 lost+found文件夹由e2fsck工具使用,假设在检查磁盘时发现错误,就把有错误的块挂在这个文件夹下。由于这些块不知道是谁的,找不到主。就放在这里“失物招领”了。
如今能够在/mnt文件夹下加入删除文件,这些操作会自己主动保存到文件fs中。然后把这个分区umount下 来。以确保全部的修改都保存到文件里了。sudo umount /mnt
如今我们用二进制查看工具查看这个文件系统的全部字节。而且同dumpe2fs工具的输出信息相比較,就能够非常好地理解文件系统的存储布局了。
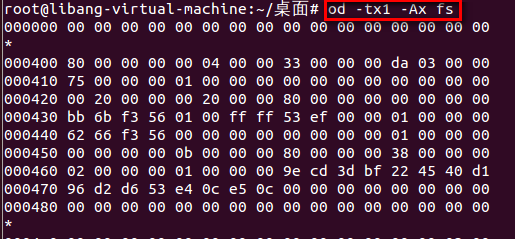
【截图中省略N行】
以*开头的行表示这一段数据全是零因此省略了。
具体分析od输出的信息:
从000000開始的1KB是启动块。因为这不是一个真正的磁盘分区,启动块的内容所有为零。 从000400到0007ff的1KB是超级块,对比着dumpe2fs的输出信息,具体分析例如以下:
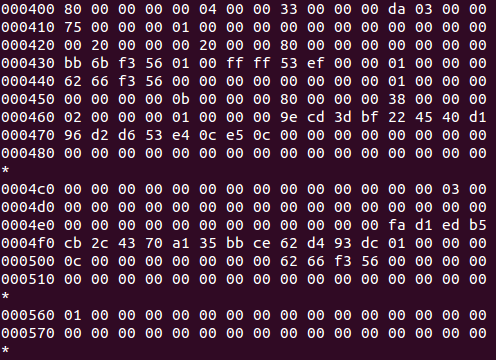
超级块中从0004d0到末尾的204个字节是填充字节,保留未用。注意, ext2文件系统 中各字段都是按小端存储的。假设把字节在文件里的位置看作地址,那么靠近文件开头的是低地 址,存低字节。
从000800開始是块组描写叙述符表,这个文件系统较小,仅仅有一个块组描写叙述符,对比着dumpe2fs的输出 信息分析例如以下:
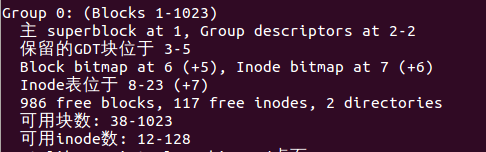

整个文件系统是1MB,每一个块是1KB。应该有1024个块,除去启动块还有1023个块,分别编号 为1-1023。它们全都属于Group 0。当中, Block 1是超级块,接下来的块组描写叙述符指出。块位图 是Block 6,因此中间的Block 2-5是块组描写叙述符表,当中Block 3-5保留未用。块组描写叙述符还指 出, inode位图是Block 7, inode表是从Block 8開始的,那么inode表到哪个块结束呢?因为超级块 中指出每一个块组有128个inode。每一个inode的大小是128字节。因此共占16个块, inode表的范围 是Block 8-23。
从Block 24開始就是数据块了。块组描写叙述符中指出,空暇的数据块有986个,因为文件系统是新创 建的,空暇块是连续的Block 38-1023,用掉了前面的Block 24-37。从块位图中能够看出,前37位 (前4个字节加最后一个字节的低5位)都是1。就表示Block 1-37已用:

在块位图中, Block 38-1023相应的位都是0(一直到001870那一行最后一个字节的低7位),接下 来的位已经超出了文件系统的空间,无论是0还是1都没有意义。可见。块位图每一个字节中的位应该 按从低位到高位的顺序来看。以后随着文件系统的使用和加入删除文件。块位图中的1就变得不连续了。
块组描写叙述符指出,空暇的inode有117个,因为文件系统是新创建的,空暇的inode也是连续 的。 inode编号从1到128,空暇的inode编号从12到128。
从inode位图能够看出。前11位都是1,表 示前11个inode已用:

001c00这一行的128位就表示了全部inode,因此以下的行无论是0还是1都没有意义。
已用 的11个inode中。前10个inode是被ext2文件系统保留的,当中第2个inode是根文件夹, 第11个inode是lost+found文件夹,块组描写叙述符也指出该组有两个文件夹,就是根文件夹和lost+found。
探索文件系统另一个非常实用的工具debugfs,它提供一个命令行界面,能够对文件系统做各种操 作,比如查看信息、恢复数据、修正文件系统中的错误。以下用debugfs打开fs文件,然后在提示 符下输入help看看它都能做哪些事情:

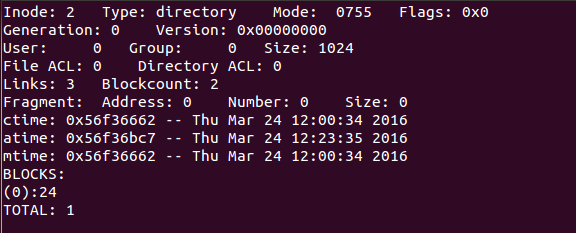
把以上信息和od命令的输出对比起来分析:【根文件夹的inode】

上图中的st_mode以八进制表示。包括了文件类型和文件权限,最高位的4表示文件类型为文件夹(各 种文件类型的编码详见stat(2)),低位的755表示权限。 Size是1024,说明根文件夹如今仅仅有一个数 据块。
Links为3表示根文件夹有三个硬链接,各自是根文件夹下的.和..,以及lost+found子文件夹下 的..。
注意。尽管我们通经常使用/表示根文件夹,可是并没有名为/的硬链接,其实。 /是路径分隔 符,不能在文件名称中出现。这里的Blockcount是以512字节为一个块来数的,并不是格式化文件系统 时所指定的块大小。磁盘的最小读写单位称为扇区( Sector) 。一般是512字节。所 以Blockcount是磁盘的物理块数量,而非分区的逻辑块数量。根文件夹数据块的位置由上图中 的Blocks[0]指出。也就是第24个块,它在文件系统中的位置是24×0x400=0x6000,从od命令的输 出中找到006000地址【根文件夹数据块】

文件夹的数据块由很多不定长的记录组成。每条记录描写叙述该文件夹下的一个文件,在上图中用框表示。 第一条记录描写叙述inode号为2的文件,也就是根文件夹本身。该记录的总长度为12字节,当中文件名称的 长度为1字节,文件类型为2(见下表,注意此处的文件类型编码和st_mode不一致)。文件名称是.。第二条记录也是描写叙述inode号为2的文件(根文件夹)。该记录总长度为12字节,当中文件名称的长度 为2字节。文件类型为2。文件名称字符串是..。
第三条记录一直延续到该数据块的末尾,描 述inode号为11的文件( lost+found文件夹),该记录的总长度为1000字节(和前面两条记录加起来 是1024字节),文件类型为2。文件名称字符串是lost+found,后面全是0字节。
假设要在根文件夹下创 建新的文件。能够把第三条记录截短,在原来的0字节处创建新的记录。假设该文件夹下的文件名称太 多,一个数据块不够用,则会分配新的数据块,块编号会填充到inode的Blocks[1]字段。