AUC是指:从一堆样本中随机抽一个,抽到正样本的概率比抽到负样本的概率大的可能性!
AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,accuracy,precision。如果你经常关注数据挖掘比赛,比如kaggle,那你会发现AUC和logloss基本是最常见的模型评价指标。为什么AUC和logloss比accuracy更常用呢?因为很多机器学习的模型对分类问题的预测结果都是概率,如果要计算accuracy,需要先把概率转化成类别,这就需要手动设置一个阈值,如果对一个样本的预测概率高于这个预测,就把这个样本放进一个类别里面,低于这个阈值,放进另一个类别里面。所以这个阈值很大程度上影响了accuracy的计算。使用AUC或者logloss可以避免把预测概率转换成类别。
AUC是Area under curve的首字母缩写。Area under curve是什么呢,从字面理解,就是一条曲线下面区域的面积。所以我们要先来弄清楚这条曲线是什么。这个曲线有个名字,叫ROC曲线。ROC曲线是统计里面的概率,最早由电子工程师在二战中提出来(更多关于ROC的资料可以参考维基百科)。
ROC曲线是基于样本的真实类别和预测概率来画的,具体来说,ROC曲线的x轴是伪阳性率FPR(false positive rate),y轴是真阳性率TPR(true positive rate)。那么问题来了,什么是真、伪阳性率呢?对于二分类问题,一个样本的类别只有两种,我们用0,1分别表示两种类别,0和1也可以分别叫做阴性和阳性。当我们用一个分类器进行概率的预测的时候,对于真实为0的样本,我们可能预测其为0或1,同样对于真实为1的样本,我们也可能预测其为0或1,这样就有四种可能性:
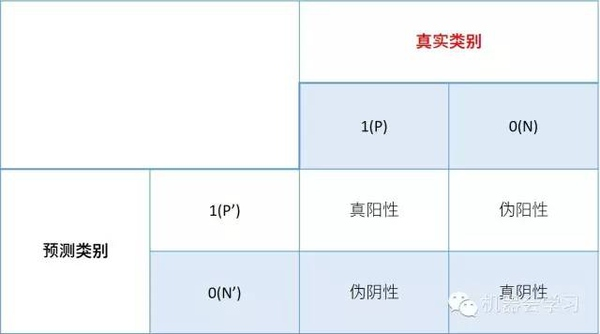
真阳性率=(真阳性的数量)/(真阳性的数量+伪阴性的数量)
伪阳性率=(伪阳性的数量)/(伪阳性的数量+真阴性的数量)
ROC关注两个指标
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率
有了上面两个公式,我们就可以计算真、伪阳性率了。但是如何根据预测的概率得到真伪阳性、阴性的数量。
我们来看一个具体例子,比如有5个样本:
真实的类别(标签)是y=c(1,1,0,0,1)
一个分类器预测样本为1的概率是p=c(0.5,0.6,0.55,0.4,0.7)
如文章一开始所说,我们需要选定阈值才能把概率转化为类别,选定不同的阈值会得到不同的结果。如果我们选定的阈值为0.1,那5个样本被分进1的类别,如果选定0.3,结果仍然一样。如果选了0.45作为阈值,那么只有样本4被分进0,其余都进入1类。一旦得到了类别,我们就可以计算相应的真、伪阳性率,当我们把所有计算得到的不同真、伪阳性率连起来,就画出了ROC曲线,我们不需要手动做这个,因为很多程序包可以自动计算真、伪阳性率,比如在R里面,下面的代码可以计算以上例子的真、伪阳性率并且画出ROC曲线:
通过AUC的定义我们知道了AUC是什么,怎么算,但是它的意义是什么呢。如果从定义来理解AUC的含义,比较困难,实际上AUC和Mann–Whitney U test有密切的联系,我会在第三部说明。从Mann–Whitney U statistic的角度来解释,AUC就是从所有1样本中随机选取一个样本, 从所有0样本中随机选取一个样本,然后根据你的分类器对两个随机样本进行预测,把1样本预测为1的概率为p1,把0样本预测为1的概率为p0,p1>p0的概率就等于AUC。所以AUC反应的是分类器对样本的排序能力。根据这个解释,如果我们完全随机的对样本分类,那么AUC应该接近0.5。另外值得注意的是,AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价分类器性能的一个原因。
在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。

用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。