为什么80%的码农都做不了架构师?>>> 
Scrapy架构
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
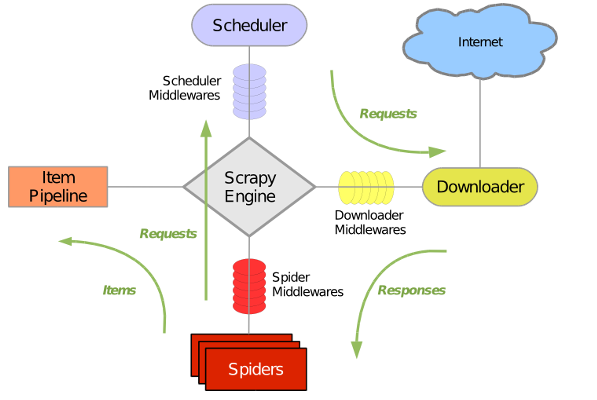
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心)
- 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
|____scrapy.cfg # Scrapy部署时的配置文件
|____tproject_name # 项目的模块,引入的时候需要从这里引入
| |______init__.py
| |____items.py # Items的定义,定义爬取的数据结构
| |____middlewares.py # Middlewares的定义,定义爬取时的中间件
| |____pipelines.py # Pipelines的定义,定义数据管道
| |____settings.py # 配置文件
| |____spiders # 放置Spiders的文件夹
| | |______init__.py
| | |______spider_name.py 爬虫编写步骤
- 创建一个Scrapy项目
- 定义提取的Item
- 编写爬取网站的 spider 并提取 Item
- 编写 Item Pipeline 来存储提取到的Item(即数据)
创建项目
创建一个新的Scrapy项目,运行下列命令:
scrapy startproject tutorial定义Item
Item 是保存爬取到的数据的容器;
Item 提供了额外保护机制来避免拼写错误导致的未定义字段错误。
通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个Item。
在item中定义相应的字段。编辑 tutorial 目录中的 items.py 文件:
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()创建爬虫
进入tutorial目录,输入命令:
scrapy genspider example www.example.com在目录tutorial/spiders下会出现example.py文件,内容如下:
# -*- coding: utf-8 -*-
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['www.example.com']
start_urls = ['http://www.example.com/']
def parse(self, response):
pass为了创建一个Spider,必须继承 scrapy.Spider 类, 且定义一些属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() :是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
在此基础上,修改parse()函数下的函数体来实现页面的爬去:
def parse(self, response):
filename = response.url.split("/")[-2] + '.html'
with open(filename, 'wb') as f:
f.write(response.body)爬取内容
进入项目的根目录,执行下列命令启动spider:
scrapy crawl example
在文件根目录下会出现www.example.com.html,内容如下:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
·················Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
提取Item
选择器
Scrapy使用了一种基于 XPath 和 CSS 表达式机制:
Selector有四个基本的方法(点击相应的方法可以看到详细的API文档):
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.extract(): 序列化该节点为unicode字符串并返回list。re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
执行下列命令来启动shell,最好给网址加上双引号:
scrapy shell "http://www.example.com/"输出结果如下:
2018-06-10 15:16:15 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: tutorial)
2018-06-10 15:16:15 [scrapy.utils.log] INFO: Versions: lxml 4.1.1.0, libxml2 2.9.5, cssselect 1.0.1, parsel 1.2.0, w3lib 1.18.0, Twisted 17.9.0, Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:14:34) [MSC v.1900 32 bit (Intel)], pyOpenSSL 17.3.0 (OpenSSL 1.1.0g 2 Nov 2017), cryptography 2.1.3, Platform Windows-10-10.0.15063-SP0
2018-06-10 15:16:15 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tutorial', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'tutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders']}
2018-06-10 15:16:16 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2018-06-10 15:16:16 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
·······················································当shell载入后,您将得到一个包含response数据的本地 response 变量。输入 response.body 将输出response的包体, 输出 response.headers 可以看到response的包头。
更为重要的是, response 拥有一个 selector 属性, 该属性是以该特定 response 初始化的类 Selector 的对象。 您可以通过使用 response.xpath() 或 response.css() 来对 response 进行查询。
>>> response.xpath("//title")
[<Selector xpath='//title' data='<title>Example Domain</title>'>]
>>> response.xpath("//title").extract()
['<title>Example Domain</title>']在spider爬虫文件中修改如下:
# -*- coding: utf-8 -*-
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example2'
allowed_domains = ['www.example.com']
start_urls = ['http://www.example.com/']
def parse(self, response):
for sel in response.xpath("//p"):
text = sel.extract()
print(text)执行爬虫,运行结果如下:
·································································
2018-06-10 15:22:59 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://www.example.com/robots.txt> (referer: None)
2018-06-10 15:22:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.example.com/> (referer: None)
<p>This domain is established to be used for illustrative examples in documents. You may use this
domain in examples without prior coordination or asking for permission.</p>
<p><a href="http://www.iana.org/domains/example">More information...</a></p>
2018-06-10 15:22:59 [scrapy.core.engine] INFO: Closing spider (finished)
··································································使用item
前面已经在item.py文件中定义了三个item,这里将使用这三个item。
在爬虫文件example.py中先导入文件:
from turtle.items import TutorialItem修改爬虫文件内容如下:
# -*- coding: utf-8 -*-
import scrapy
from tutorial.items import TutorialItem
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['www.example.com']
start_urls = ['http://www.example.com/']
def parse(self, response):
item = TutorialItem()
item["title"] = response.xpath("//title/text()").extract()
item["link"] = response.xpath("//a/@href").extract()
item["desc"] = response.xpath("//p[1]/text()").extract()
return item然后运行爬虫,结果如下:
·······························································
2018-06-10 15:42:02 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.example.com/>
{'desc': ['This domain is established to be used for illustrative examples in '
'documents. You may use this\n'
' domain in examples without prior coordination or asking for '
'permission.'],
'link': ['http://www.iana.org/domains/example'],
'title': ['Example Domain']}
2018-06-10 15:42:02 [scrapy.core.engine] INFO: Closing spider (finished)
·······························································保存爬取到的数据
把爬取内容保存到json文件:
scrapy crawl example -o items.json在文件根目录就会出现items.json文件,内容如下:
[
{"title": ["Example Domain"], "link": ["http://www.iana.org/domains/example"], "desc": ["This domain is established to be used for illustrative examples in documents. You may use this\n domain in examples without prior coordination or asking for permission."]}
]追踪链接(Following links)
申明:一下内容来自于Scrapy 1.0中文手册,仅作内容补充之用。
接下来, 不仅仅满足于爬取 Books 及 Resources 页面, 您想要获取获取所有 Python directory 的内容。
既然已经能从页面上爬取数据了,为什么不提取您感兴趣的页面的链接,追踪他们, 读取这些链接的数据呢?
下面是实现这个功能的改进版spider:
import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/",
]
def parse(self, response):
for href in response.css("ul.directory.dir-col > li > a::attr('href')"):
url = response.urljoin(response.url, href.extract())
yield scrapy.Request(url, callback=self.parse_dir_contents)
def parse_dir_contents(self, response):
for sel in response.xpath('//ul/li'):
item = DmozItem()
item['title'] = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item
现在, parse() 仅仅从页面中提取我们感兴趣的链接,使用 response.urljoin 方法构造一个绝对路径的URL(页面上的链接都是相对路径的), 产生(yield)一个请求, 该请求使用 parse_dir_contents() 方法作为回调函数, 用于最终产生我们想要的数据.。
这里展现的即是Scrpay的追踪链接的机制: 当您在回调函数中yield一个Request后, Scrpay将会调度,发送该请求,并且在该请求完成时,调用所注册的回调函数。
基于此方法,您可以根据您所定义的跟进链接的规则,创建复杂的crawler,并且, 根据所访问的页面,提取不同的数据.
一种常见的方法是,回调函数负责提取一些item,查找能跟进的页面的链接, 并且使用相同的回调函数yield一个 Request:
def parse_articles_follow_next_page(self, response):
for article in response.xpath("//article"):
item = ArticleItem()
... extract article data here
yield item
next_page = response.css("ul.navigation > li.next-page > a::attr('href')")
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse_articles_follow_next_page)
上述代码将创建一个循环,跟进所有下一页的链接,直到找不到为止 – 对于爬取博客、论坛以及其他做了分页的网站十分有效。