一次耐人寻味的SQL优化:除了SQL改写,还要考虑什么?
作者介绍
黄浩,现任职于中国惠普,从业十年,始终专注于SQL。在华为做项目的两年多,做过大大小小的SQL多达1500个。闲暇之余,喜欢将部分案例写成博客发表在华为内部数据库官方社区,反响强烈,已连续四个月蝉联该社区最佳博主。目前已开设专栏“优哉悠斋”,成为首个受邀社区“专家访谈”的外协人员。
这是一次值得纪念的优化,值得回忆的内容非常丰富,虽然这个SQL本身并不复杂,几乎是一个相对规范式的SQL,所以,这次优化的重点并不是SQL的改写,而更多的是业务需求、物理模型的优化。在长达3个月,历经5个版本的优化过程中,也不泛优化与开发、功能与性能、测试与开发间关系的微妙变化,其间各方的博弈也耐人寻味。
事出有因
系统存在一个功能,“编辑日志查询”,顾名思义就是查询被修改的历史记录(这个功能的存在性有待商榷)。功能刚上线的时候,由于数据量少,相安无事,使用甚欢。由于基本上都是大批量的编辑,导致了日志数据量急剧增长,每天的增量大概在100万左右,两个月后,数据量无情的增长到了6000万,性能隐患也日益凸显,终于换来了一封来自业务用户的邮件,于是我也收到了一个需要优化的SQL,如下:

大胆假设,小心求证
我做SQL优化有个习惯,拿到SQL的时候,并不急于去看执行计划,而是先要快速浏览一遍SQL,一看结构,二看内容,因为我坚信80%的性能问题是由于SQL写法不当导致的,比如冗余的对象访问、冗余的关联条件、冗余的过滤条件、无意义的DISTINCT\UNION\GROUP\ORDER、自定义函数等等这些常见的问题。这个SQL也不例外,很明显TimeZone_Date_Translator这个自定义函数可能会是性能瓶颈。
为了验证自己的判断,我将函数去掉后,再执行,果然性能得到了质的提升。因为符合了性能指标,我也没有深入的分析原因。
问题严重化
逝者如斯,RP_PLAN_LOG_T表的数据量日复一日的增加,一个月后,又收到了一封来自一线业务用户的邮件,这次的邮件内容措辞相对上一封,要严厉了很多,大意是:该功能的性能问题已经严重影响到一线业务效率,查询数据居然要等待30s之久,更有甚者直接超时报错(120s),因此强烈要求该功能的性能要在5s内。
这封邮件犹如一颗巨石,在平静的水面炸开了锅。
SQL还是那个SQL,我在PL SQL里面执行,平均耗时在10秒内,也没有邮件中说的30s之久呀。难道是执行计划的走偏导致的?因为这是动态拼凑的SQL,SQLID变化无常,所以分析当时执行计划是否走偏的难度很高。
办案讲究的是犯罪现场,而现在“犯罪现场”肯定是不存在的了,那能否可以重现“犯罪现场”呢?虽然此种方案也并不能支撑“执行计划走偏”的原因分析,但是至少可以为我们拓展思维:会不会是查询条件变化?会不会是网络原因?
于是,根据邮件里面零碎的信息,我们在生产环境的功能界面上重现了“现场”,但是结果并没有“犯罪”,也就是说并没有出现邮件中说的达到30s之久。因为是根据只言片语拼凑的“现场”,所以可能存在模拟失真的可能性。
为了模拟的真实性,我们联系上了“案发”当事人,在询问了“案发”条件后,才得知:原来用户是在选定某个“项目编码”下查询条件下检索了近一年的日志数据。而由于该日志功能才启用了不到4个月,也就是说是查询了某个项目下所有的日志数据。根据用户提供的信息,我们在PL SQL中执行了SQL,确实达到了30s之久,结果数据集的量也达到了500万+。
至此,我们可以得出这样的结论:本次查询的性能问题的原因归结于数据量,基表的数据量(近一个亿)及结果集数据量(500万+)。
那么,如何解决呢?一方面是如洪水般迅猛增涨的基表数据,另一方面是超大的结果集返回。针对这两个问题,我给出了如下的解决方案:
-
引入表分区技术,即将基表RP_PLAN_LOG_T表按照operate_time字段按月分区,以实现数据的分区命中
-
为实现数据的分区命中,在查询界面将operate_time作为必选条件,而且尽量做到不跨月
-
为配合1、2两点,创建project_number和operate_time的联合索引
事情往往是从扯皮开始的
现在,问题来了,这些事情谁来落实呢?先说第二点吧,这是改需求呀,需要与BA协商,找到了BA,BA说自己也做不了主呀,还得要跟业务用户去确认,这一来二往的,开发人员性子急,就不耐烦了:还是不改了吧,太麻烦了。
再说第一点,数据分区的责任定位也不明确,开发人员说这需要DBA来做,DBA又说这属于应用范畴,理应开发人员写脚本,他们负责执行就好了。扯来扯去,最后又把BA扯出来了:这个事情需要时间来做,BA应该下个需求单,有了需求单,就能评估人天,这样有人天了,自然就有人来做了。
而BA也在为自己辩护:这属于纯技术范畴,与业务需求无关,说白了是当初在设计模型的时候就该考虑分区技术,因此这个需求单不能下。
最后,开发、BA、DBA、用户及我达成协议:分区由DBA来实施,不过需要在下个版本实施;用户确认可以将operate_time作为必选条件,并且尽量做到压缩查询周期;开发人员在project_number和operate_time字段上创建联合索引。
自查的勇气
为了避免用户由“怨责”转变成“投诉”,项目组对该功能的性能也重视起来,要求性能测试人员严格把关,如果性能超过5S就不放行。这样,开发人员就开始对该功能的性能自检自查,测试人员也在积极的准备数据做性能验证。我的责任还是对SQL进行分析并优化。
第一次是粗略的过了一遍SQL,发现了TimeZone_Date_Translator自定义函数;第二次直接是优化了对象模型;这一次才是真正的正面又深入的打量这个SQL,其中一段代码引起了我的兴趣:
这段代码是获取字段subtitlename值的标量子查询,从代码看,该值的获取逻辑如下:

以operate_type为“其他”为例,在展开之前,我们先看看相关的模型结构。
RP_PLAN_LOG_T的模型如下:
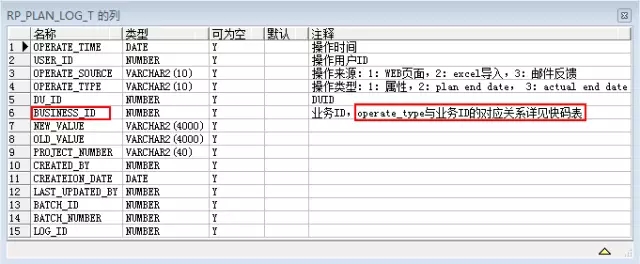
该模型中有个BUSINESS_ID的字段,这个字段存放业务ID:属性类型(即OPERATE_TYPE=1)对应的是RP_PLAN_EXTENSION_T.PLAN_EXTENSION_ID,其他类型(即operate_type in(2,3,4,5,7,8,9))对应的是RP_TASK_T.TASK_ID,Site Owner(即operate_type = 6)为-100,所以,在获取字段subtitlename值的时候需要根据operate_type的值分别到不同的表中获取对应的name值。
我们再看看RP_TASK_T和RP_PLAN_EXTENSION_T的模型结构
先看RP_TASK_T表模型:
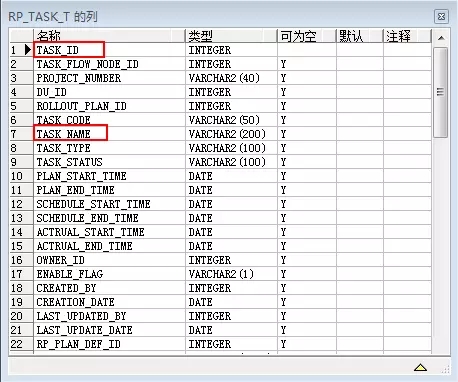
模型中TASK_ID是主键,但是如果你按照常规理解TASK_ID与TASK_NAME存在一对一的关系的话,那你就错了,这也是玄机所在。在RP_TASK_T表中,TASK_NAME与TASK_ID是一对多的关系,即同一个TASK_NAME对应多个TASK_ID。
事实上,TASK_NAME作为一个实体,也是存在一个独立的模型,即SDS_ACTIVITY_T,其结构如下:
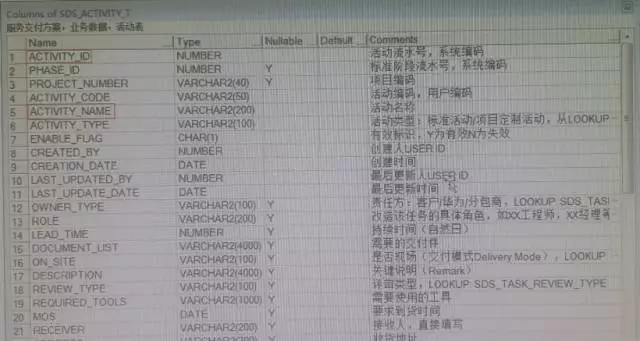
在这个模型里,ACTVITY_NAME就是对应RP_TASK_T中的TASK_NAME,并且该模型里面的ACTVITY_ID与ACTVITY_NAME在同一个project_number下是一一对应的。
看到这里就清晰了,原来,为了获取subtitlename字段值,我们还可以从SDS_ACTIVITY_T表中拿ACTVITY_NAME字段,如果在RP_PLAN_LOG_T表中存放了ACTVITY_ID字段值的话。
也就是说,目前operate_type in(2,3,4,5,7,8,9)的情况下,有两种途径可以获取到subtitlename字段值。而这两种途径的优劣在哪里呢?我们对比下rp_task_t和SDS_ACTIVITY_T表的数据量就知道了:
| 表 | 存量 | 增量 |
| RP_TASK_T | 2千万+ | 大 |
| RP_TASK_HIS_T | 420万+ | 大 |
| SDS_ACTIVITY_T | 11万+ | 小 |
由此可见,两种途径孰优孰劣显而易见。
无独有偶,operate_type = 6的情况与此同出一辙,也是存在另一种通过小数据量的表获取subtitlename的途径。
正当其时,测试人员提了一个性能BUG单,内容是:当选择了subtitlename查询条件时,查询响应非常慢,达到了20s之久。这也印证了我的分析:当前获取subtitlename字段值是一个潜在的性能瓶颈。
说是潜在的,原因是如果该字段不作为查询条件,则不会触发,因为该SQL的结果集是分页的,每次只返回15条数据,而作为标量子查询,也就是执行15次而已;但是,一旦作为了查询条件,则执行的次数则是巨大的,而标量子查询中的表都是千万级的大表。所以就成为了严重的性能瓶颈。
至此,我以BUG单为契机,适时的提出了优化方案:将business_id拆分成两个字段,分别存储ACTVITY_ID和ATTRIBUTE_ID。
看热闹的不嫌事大
当我提交这个方案时,开发人员甚为激动,倒不是因为有了方案而激动,而是因为这个方案于他们而言有点不太靠谱,他给出了如下理由:
-
增加字段,这是伤筋动骨之举,只能在万不得已的情况下才能实施;
-
该表的数据并非一个来源,表结构改动后,会涉及到多个来源的代码同步修改;
-
目前RP_PLAN_LOG_T表的数据量已经上亿了,增加字段,就意味着需要对历史数据进行初始化,动作太大;
-
现在已接近版本上线日,如此大动作在短时间内完成,风险太大。
其实,说白了,就是这个版本的工作计划无法承受该方案,所以站在他们的立场,目前正在如火如荼进行版本的功能开发,这是优先保障的,而我的方案被当成了:看热闹不嫌事大;但是如果是在原有模型的基础上,我实难完成优化目标。
时间一天一天过去了,待到上线前一天,这个BUG单依然open着,而按照上线变更条例,如果有BUG单没有close掉,是不能上线的。最后关头,在测试人员的紧逼之下,开发的SE动用了“特权”:将该BUG单移至到下个版本。尽管测试人员强烈反对,但是功能优先性能的大条件不容挑衅。
断腕的决心
测试人员上个版本吃了哑巴亏,在版本上线后,第一时间盯着开发人员优化该功能。毕竟头上悬着业务用户这把利剑,开发人员也不敢马虎,也投入了人力优化。方案很简单,但是对于整个功能代码而言,涉及到的内容就远比在表上增加两个字段复杂得多,从如下邮件截图可窥一斑:

总结
该功能的性能优化在经历了自定义函数、分区、索引、业务方案、模型方案后,性能总算是稳定了下来,但是仍然留给了我很多疑问:
-
模型设计初期是否能考虑全面?是否能做到一步到位?
-
日志查询的意义何在?一次性查询十万百万的数据意义何在?
-
能否有一套成熟的方案来应对查询条件的动态化?查询条件是动态组合的,显然索引不可能动态组合。
本文就先到这。关于以上疑问,后续会另写文章继续分享。
本文来自云栖社区合作伙伴"DBAplus",原文发布时间:2016-11-03