同步容器
同步容器是指那些对所有的操作都进行加锁(synchronize)的容器。比如Vector、HashTable和Collections.synchronizedXXX返回系列对象:
可以看到,它的绝大部分方法都被加了同步(带个小时钟图标)。
虽然Vector这么劳神费力地搞了这么多同步方法,但在最终使用的时候它并不一定真的“安全”。
同步容器的复合操作不安全
啊?不是说Vector和HashTable是线程安全的吗?虽然Vector的方法增加了同步,但是像下面这种“先检查再操作”复合操作其实是不安全的:
//两个同步的原子操作合在一起就不再具有原子性了 public void getLast(Vector vector) { int size = vector.size(); vector.get(size); }
所以,以后再听说某个类是线程安全的,不能就觉得万事大吉了,应该留个心想想其安全的真正含义。
Vector和HashTable这些类的线程安全指的是它所提供的单个方法具有原子性,一个线程访问的时候其他线程不能访问。在进行复合操作时还需要咱们自己去保证线程安全:
public void getLast(Vector vector) { //客户端显式锁保证符合操作的同步 synchronized (vector) { int size = vector.size(); vector.get(size); } }
这种不安全的问题在遍历集合的时候仍然存在。Vector能做的仅仅就是在出现多线程访问导致集合内容冲突时(版本号与进入遍历之前不一样了)给一个异常提醒:
final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); }
一定要明白,ConcurrentModificationException异常的真正目的其实是在提醒咱的系统中存在多线程安全问题,需要我们去解决。不解决程序也能跑,但是指不定那天就见鬼了,这要靠运气。
书中还指出,像Vector这样把锁隐藏在代码端的设计,会导致客户端经常忘记去同步。即“状态与保护它的代码越远,程序员越容易忘记在访问状态时使用正确的同步”。这里的状态就是指的容器的数据元素。
即使同步容器在单方法的上能够做到“安全”,但是它会使CPU的吞吐量下降、降低系统的伸缩性,因此才有了下面的并发容器。
并发容器
JDK5针对于每一种同步容器,都设计了一个对应的并发容器,队列(Queue)和双向队列(Deque)是新增的集合类型。
ConcurrentHashMap使用分段锁运行多个线程并发访问
为了解决同步访问时的低吞吐量问题,ConcurrentHashMap使用了分段锁的方式,允许多个线程并发访问。
同步锁的机制是,使用16把锁,每一把锁负责1/16的散列桶的同步访问。你可能猜到了,如果存储的数据采用了一个糟糕的散列函数,那么ConcurrentHashMap的效果HashTable一样了。
ConcurrentHashMap也有它的问题,既然允许多个线程同时访问了,那么size()和isEmpty()方法的结果就不准确了。书中说这是一种权衡,认为多线程状态下size和isEmpty方法没有那么重要了。但是在使用ConcurrentHashMap是我们应该知道确实有这样的问题。
计算机世界里经常出现这样的权衡问题。是的,没有免费午餐,得到一些好处的同时就需要付出另外一些代价。典型的例子就是分布式系统中的CAP原则,即一致性、可用性和分区容错性三者不可兼得。
CopyOnWriteArrayList应用于读远大于写的场景
顾名思义,添加或修改时直接复制一个新的底层数组来存储数据。因为要复制,所以比较适合应用于写远小于读的场景。比如事件通知系统,注册和注销(写)的操作就远大于接收事件的操作。
阻塞队列应用于生产者-消费者模式
队列嘛就是一个存储单元,数据可以按序存入然后按序取出。关键在于阻塞。在生产者-消费者模式中。生成者可以往队列里存数据,消费者负责从队列里获取数据。阻塞的含义是当队列里没有数据时,消费者在take数据时会被阻塞,直到有生产者往队列里put了一个数据。相反,如果队列里的数据已经满了,那么生产者也只能等到消费者take走了一个数据之后才能put数据。
阻塞队列的两个好处:
1,使生产者和消费者解耦,他们之间不需要额外的直接对话通信;
2,阻塞队列可以协调生产者和消费者的速度,让较快的一方等待较慢的一方,不至于使未处理的消息累积过大;
阻塞方法与中断方法
个人总结:catch到InterruptException时要么继续往上抛,实在不能抛了就要标记当期线程为interrupt。
Thread.currentThread().interrupt();
切忌try-catch完了之后什么都不做,直接给和谐了。
同步工具类
CountDownLatch(计数器)-等待多个结果
当需要等待多个条件都满足时才执行下一步,就可以用Latch来做计数器:
public class CountDownLatchTest { public static void main(String[] args) throws InterruptedException { final Random r = new Random(); final CountDownLatch latch = new CountDownLatch(5); for(int i = 0; i < 5; i++) { new Thread(new Runnable() { @Override public void run() { try { Thread.sleep(r.nextInt(5) * 1000); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } System.out.println(Thread.currentThread().getName() + " execute complated!"); latch.countDown(); } }).start(); } System.out.println("Wait for sub thread execute..."); latch.await(); System.out.println("All Thread execute complated!"); } }
测试结果:
Wait for sub thread execute... Thread-4 execute complated! Thread-1 execute complated! Thread-0 execute complated! Thread-3 execute complated! Thread-2 execute complated! All Thread execute complated!
Semaphore(信号量)控制资源并发访问数量

Semaphore可以实现资源访问控制,在初始化时可以指定一个数量,这个数量表示可以同时访问资源的线程数。
也可以理解成许可证。访问资源前问Semaphore获取(acquire)访问许可,如果还有剩余的许可就能正常获取到,否则就会等待,知道有其他线程归还(release)许可了。
public static void main(String[] args) { Semaphore s = new Semaphore(3); for(int i = 0;i<10;i++) { new Thread(new Runnable() { @Override public void run() { try { System.out.println(System.currentTimeMillis() +":"+ Thread.currentThread().getName() + " waiting for Permit..."); s.acquire(); System.out.println(System.currentTimeMillis() +":"+ Thread.currentThread().getName() + " doing his job..."); Thread.sleep(5000); s.release(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } }).start(); } }
测试结果如下,可以看到每次同时执行的线程数永远只有3个:
1514272606904:Thread-0 waiting for Permit... 1514272606904:Thread-3 waiting for Permit... 1514272606904:Thread-0 doing his job... 1514272606904:Thread-1 waiting for Permit... 1514272606905:Thread-5 waiting for Permit... 1514272606904:Thread-3 doing his job... 1514272606905:Thread-1 doing his job... 1514272606905:Thread-4 waiting for Permit... 1514272606905:Thread-6 waiting for Permit... 1514272606905:Thread-2 waiting for Permit... 1514272606905:Thread-7 waiting for Permit... 1514272606905:Thread-8 waiting for Permit... 1514272606905:Thread-9 waiting for Permit... 1514272611905:Thread-5 doing his job... 1514272611905:Thread-6 doing his job... 1514272611905:Thread-4 doing his job... 1514272616905:Thread-7 doing his job... 1514272616905:Thread-2 doing his job... 1514272616905:Thread-8 doing his job... 1514272621906:Thread-9 doing his job...
当把Semaphore的许可数量设置为1时,Semaphore就变成了一个互斥锁。
Barrier(栅栏)实现并行计算
栅栏有着和计数器一样的功能,他们都可以等待一些线程执行完毕后再近些某项操作。
不同之处在于栅栏可以重置,它可以让多个线程同时到达某个状态或结果之后再继续往下一个目标出发。
并行计算时,各个子线程计算的速度可能不一样,需要等待每个线程计算完成之后再继续执行下一步计算:
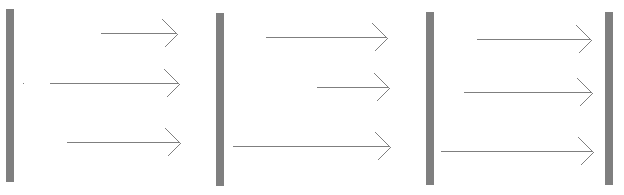
垂直线表示计算状态,水平箭头的长度表示计算时间的差异。
public class BarrierTest { static int hours = 0; static boolean stopAll = false; public static void main(String[] args) { CyclicBarrier barrier = new CyclicBarrier(3, new Runnable() { @Override public void run() { System.out.println("every on stop,wait for a minute."); hours++; if(hours>8) { System.out.println("times up,Go off work!"); stopAll = true; } } }); Random r = new Random(); //barrier. for(int i = 0;i<3;i++) { new Thread(new Runnable() { @Override public void run() { while(!stopAll) { System.out.println(Thread.currentThread().getName() + " is working..."); try { Thread.sleep(r.nextInt(2) * 1000); barrier.await(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } catch (BrokenBarrierException e) { e.printStackTrace(); } } } }).start(); } } }
测试结果:
... ... every on stop,wait for a minute. Thread-1 is working... Thread-2 is working... Thread-0 is working... every on stop,wait for a minute. Thread-1 is working... Thread-0 is working... Thread-2 is working... every on stop,wait for a minute. Thread-0 is working... Thread-1 is working... Thread-2 is working... every on stop,wait for a minute. times up,Go off work!
另外还有一种叫Exchanger的Barrier,它可以用来做线程间的数据交换。
构建高效可伸缩的结果缓存
简单的用synchronize + HashMap实现结果缓存:
public class ComputeMemroyCache<T,V> { HashMap<T,V> cache = new HashMap<T,V>(); Computable<T,V> computable; public ComputeMemroyCache(Computable<T,V> computable) { this.computable = computable; } public synchronized V compute(T t) { V result = cache.get(t); if(result == null) { result = computable.compute(t); cache.put(t, result); } return result; } } public interface Computable<T,V> { public V compute(T t); }
这种缓存有时甚至比没有缓存还要糟糕:
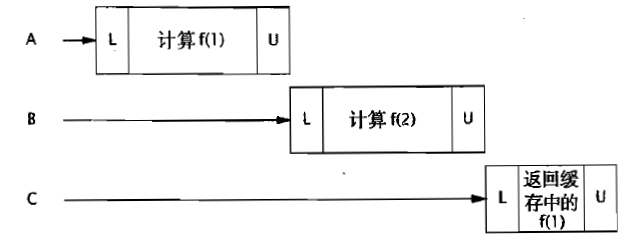
如果计算的对象不多,那么系统仅仅是有个很长的热身阶段,否则的话,低命中率的缓存没有起到实际的作用,糟糕的同步反而使程序的吞吐量急剧下降。
如果去掉同步,并且使用ConcurrentHashMap,结果会好一点儿,但是还是会出现重复计算一个结果的情况。因为compute中有“先检查后计算”的行为(非原子操作)。
这里一个最严重的问题是,计算代码和客户度调用同步了,就是一定要计算到一个结果之后才往Map中缓存结果,如果计算时间过长,就会导致后面很多请求的堆积。下面的改进中使用了FutureTask来讲计算推迟到另外一个线程,从而可以立即将“正在计算”的动作存放都Map中:
public class FutureTaskComputeMemroyCache<T,V> { ConcurrentHashMap<T,FutureTask<V>> cache = new ConcurrentHashMap<T,FutureTask<V>>(); Computable<T,V> computable; public FutureTaskComputeMemroyCache(Computable<T,V> computable) { this.computable = computable; } public V compute(T t) throws InterruptedException, ExecutionException { FutureTask<V> result = cache.get(t); if(result == null) { result = new FutureTask<V>(new Callable<V>() { @Override public V call() throws Exception { return computable.compute(t); } }); cache.put(t, result); result.run(); } return result.get(); } }
还缺一点儿,上面的代码还是会存在重复计算的问题。还是因为“检查并计算”的复合操作!真是够烦人的。这里要记住:既然都使用了ConcurrentHashMap,那么在存取值的时候一定要记住是否还能简单的get,一定要考虑复合操作是否需要避免的问题。因为ConcurrentHashMap已经我们准备好了解决复合操作的putIfAbsent方法。使用了ConcurrentHashMap而没使用putIfAbsent那太可惜也太浪费。
public class FutureTaskComputeMemroyCache<T,V> { ConcurrentHashMap<T,FutureTask<V>> cache = new ConcurrentHashMap<T,FutureTask<V>>(); Computable<T,V> computable; public FutureTaskComputeMemroyCache(Computable<T,V> computable) { this.computable = computable; } public V compute(T t) throws InterruptedException, ExecutionException { FutureTask<V> result = cache.get(t); if(result == null) { result = new FutureTask<V>(new Callable<V>() { @Override public V call() throws Exception { return computable.compute(t); } }); FutureTask<V> existed = cache.putIfAbsent(t, result); if(existed==null) {//之前没有启动计算时这里才需要启动 result.run(); } } return result.get(); } }
待完善
1,如果FutureTask计算失败,需要从缓存种移除;
2,缓存过期
这里仅尝试实现了缓存过期:
public class TimeoutFutureTaskComputeMemroyCache<T,V> { ConcurrentHashMap<T,ComputeFutureTask<V>> cache = new ConcurrentHashMap<T,ComputeFutureTask<V>>(); Computable<T,V> computable; public TimeoutFutureTaskComputeMemroyCache(Computable<T,V> computable) { this.computable = computable; } public V compute(T t) throws InterruptedException, ExecutionException { ComputeFutureTask<V> result = cache.get(t); if(result == null) { result = new ComputeFutureTask<V>(new Callable<V>() { @Override public V call() throws Exception { return computable.compute(t); } },1000 * 60);//一分钟超时 ComputeFutureTask<V> existed = cache.putIfAbsent(t, result); if(existed==null) {//之前没有启动计算时这里才需要启动 result.run(); }else if(existed.timeout()) {//超时重新计算 cache.replace(t, existed, result); result.run(); } } return result.get(); } class ComputeFutureTask<X> extends FutureTask<X>{ long timestamp; long age; public ComputeFutureTask(Callable<X> callable,long age) { super(callable); timestamp = System.currentTimeMillis(); this.age =age; } public long getTimestamp() { return timestamp; } public void setTimestamp(long timestamp) { this.timestamp = timestamp; } public boolean timeout() { return System.currentTimeMillis() - timestamp > age; } } }