迁移到MySQL的架构演进(一)
这是学习笔记的第 2010 篇文章
我们经过了一个相对漫长的周期把SQL Server业务迁移到了MySQL分布式架构,整个过程算是跌宕起伏。我来复现一下这个过程。
迁移前,我们做了业务梳理,发现这个业务其实可以划分为两个大类,一个是数据业务,一个是账单业务。数据业务负责事务性数据,而账单业务是状态数据的操作历史。整体的系统现状梳理如下表10-4。
表10-4 数据业务与账单业务的对比
数据业务 | 账单业务 | |
数据量 | 400G+ | 1024G+ |
数据特点 | 数据读写(插入,修改,查询) | 数据写入为主(插入,查询) |
数据属性 | 事务性数据 | 流水型数据 |
数据保留周期 | 物理备份保留周期1个月账单数据保留在2周以上 | |
数据同步策略 | 数据业务通过调用存储过程生成账单数据 | |
改造前架构如下图所示,对数据做了过滤,整体上库里面的表有上万张,虽然是多个独立的业务单元,但是状态数据和流水数据是彼此通过存储过程级联调用。
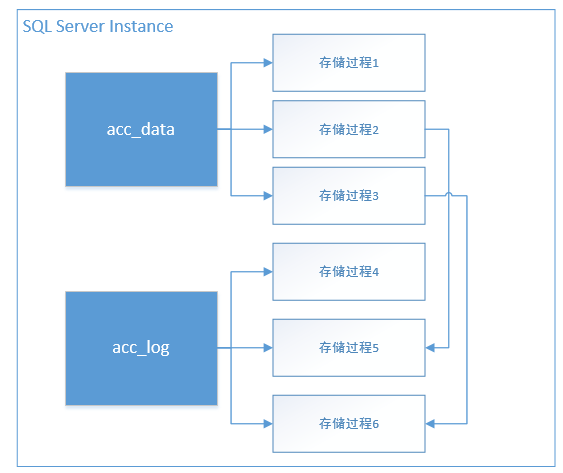
对这样一个系统做整体的改造,存在大量存储过程,业务耦合度较高的情况下,要拆分为分布式架构是很困难的,主要体现在3个地方:
(1)研发和运维对于分布式架构的理解有限,认为要改造可行,但是改动量极大,基本会在做和不做之间摇摆。
(2)对于大家的常规理解来说,希望达到的效果是一种透明平移的状态,即原来的存储过程我们都无缝的平移过来,显然在MySQL分布式的架构下,这种方案是不可行的,而且如果硬着头皮做完,那么效果也肯定不好。
(3)对于分布式的理解,不是仅仅把业务拆开那么简答,我们始终要找到一个平衡点,不是所有业务都需要拆分做成分布式。分布式能带来好处,但是同时分布式也会带来维护的复杂成本。
所以对于架构的改进,我们为了能够落地,同时在这个过程中尽可能和研发团队保持架构的同步迭代,我们整体上走过了如下图所示的4个阶段。

(1)功能阶段:梳理需求,对存储过程进行转义,适配MySQL方向
(2)架构阶段: 对系统架构和业务架构进行改进设计,支持分布式扩展
(3)性能阶段: 对系统压力进行增量测试,全量测试,全面优化性能问题
(4)迁移阶段: 设计数据迁移方案,完成线上环境到MySQL分布式环境的迁移
我们主要讨论上面3个阶段,我总结为8个架构演进策略,我们逐个来说一下。
10.4.2 功能设计阶段
策略1:功能平移
对于一个已经运行稳定的商业数据库系统,如果要把它改造为基于MySQL分布式架构,很自然会存在一种距离感,这是一种重要不紧急的事情,而且从改进的步调来说,是很难一步到位的。所以我们在这里实行的是迭代的方案,如图所示。
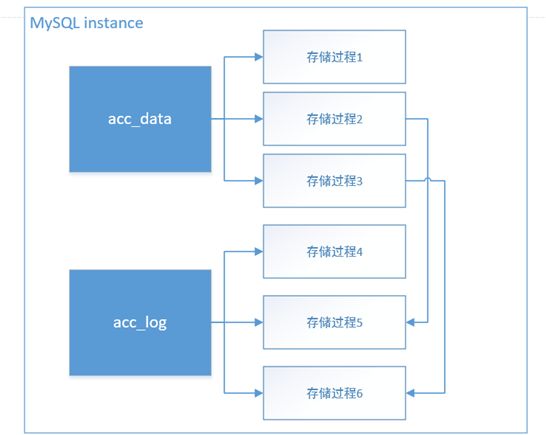
就如同大家开始预期的那样,既然里面有大量的存储过程逻辑,我们是不是把存储过程转义到MySQL里面就可以了呢。在没有做完这件事情之前,大家谁都不能做这个决定,况且MySQL单机的性能和商业数据库相比本身存在差距,在摇摆不定中,我们还是选择既有的思维来进行存储过程转义,
在初始阶段,这部分的时间投入会略大一些,在功能和调用方式上,我们需要做到这种适配,尽可能让应用层少改动或者不改动逻辑代码。
存储过程转义之后,我们的架构演进才算是走入了轨道,接下来我们要做的是系统拆分。
10.4.3 系统架构演进阶段
策略2:系统架构拆分
我们在之前做业务梳理达成的共识是:系统分为数据业务和账单业务,那么我们下一步的改造的目标也很明确了,一来数据库的存储容量太大,一个TB级别的MySQL库,存在上万张表,而且业务的请求极高,很明显单机存在着较大的风险,系统拆分是把原来的一个实例拆成两个实例,通过这种拆分就能够强行把存储过程的依赖解耦。而拆分的核心思路是对于账单数据的写入从实时转为异步,这样对于前端的响应就会更加高效。
拆分后的架构如下图所示。
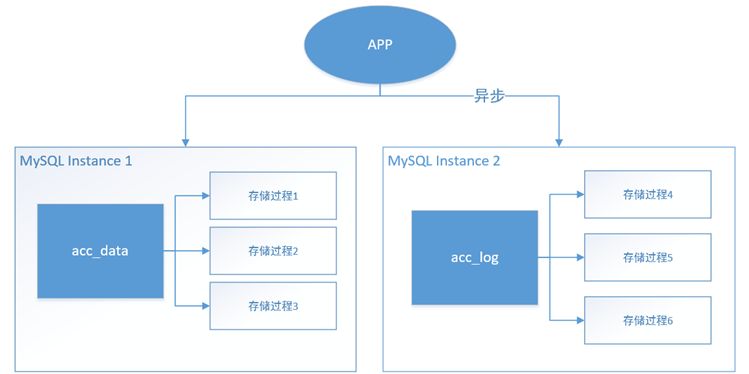
当然拆分后,新的问题出现了,账单业务的写入量按照规划是很高的,无论从单机的写入性能和存储容量都难以扩展,所以我们需要想出新的解决方案。
策略3:写入水平扩展
账单数据从业务模型上属于流水型数据,不存在事务,所以我们的改进就是把账单业务的存储过程转变为insert语句,在转换之后,我们把账单数据库改造为基于中间件的分布式架构,这个过程对于应用同学来说是透明的,因为它的调用方式依然是SQL。
同时因为之前的账单数据有大量的表,数据分布参差不齐,表结构都相同,所以我们也借此机会把数据入口做了统一,根据业务模型梳理了几个固定的数据入口。这样一来,对于应用来说,数据写入方式更简单,更清晰了,改造后的架构如下图

这个改造对于应用同学的收益是很大的,因为这个架构改造让他们直接感受到不用修改任何逻辑和代码,数据库层就能够快速实现存储容量和性能的水平扩展。
账单的改进暂时告一段落,我们开始聚焦于数据业务,发现这部分的读请求非常高,读写比例可以达到8:1左右,我们继续开始架构的改进。
