数据刷新中的并行改进(二) (r5笔记第76天)
在之前的博文中分享了数据刷新中的并行改进建议,但是对于方案的落地还是有很多的细节需要实现。首先是关于很多的表怎么把它们合理的进行并行切分。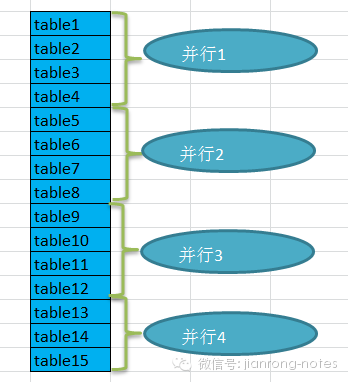 根据实际的情况,因为这些数据字典表都相对数据量都不大,所以存在的分区表很少,所以可以考虑按照segment的大小来作为并行切分的基准。所以在分布式环境中,在进行了并行切分之后,数据的刷新速度也是会有差异的。为了尽量减少同一个数据源的刷新瓶颈,所以还是考虑在每个节点考虑采用并行刷新,完成一个节点,然后下一个,所以实际的情况就可能会是下面的样子。黄色部分表示还没有开始,绿色部分表示正在刷新,灰色部分表示已经完成。所以同样的表在不同的节点中可能刷新速度也会有所不同。
根据实际的情况,因为这些数据字典表都相对数据量都不大,所以存在的分区表很少,所以可以考虑按照segment的大小来作为并行切分的基准。所以在分布式环境中,在进行了并行切分之后,数据的刷新速度也是会有差异的。为了尽量减少同一个数据源的刷新瓶颈,所以还是考虑在每个节点考虑采用并行刷新,完成一个节点,然后下一个,所以实际的情况就可能会是下面的样子。黄色部分表示还没有开始,绿色部分表示正在刷新,灰色部分表示已经完成。所以同样的表在不同的节点中可能刷新速度也会有所不同。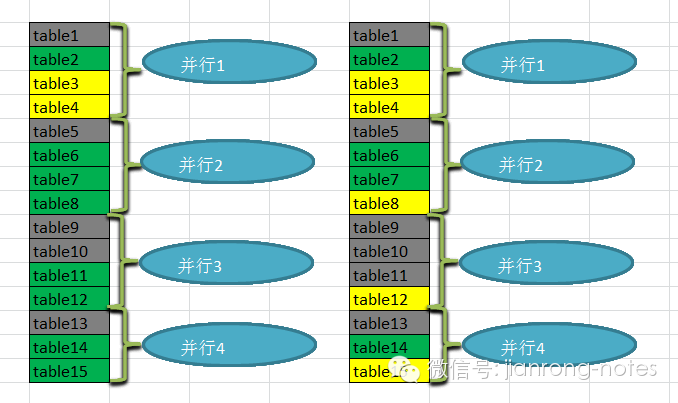 所以目前为止,难点有三个,一个是能够把多个表进行并行切分,第二个就是能够合理的同步刷新的进度,第三个就是能够在多个节点间持续的进行切换。首先第一个问题是并行切分的部分,可以参考下面的代码。这个脚本会把多个表进行切分,然后生成物化视图刷新的语句,不同的节点会生成单独的一套脚本便于控制和管理。par_file_name=$1sort -rn -k2 $par_file_name > ${par_file_name}_tmpmv ${par_file_name}_tmp ${par_file_name}par_no=$2obj_length=`cat ${par_file_name}|wc -l `echo $obj_lengthsid_list=cust01,usg01,usg02,usg03,usg04for i in {1..$par_no}do for tmp_sid in {$sid_list} do sed -n ''$i'p' ${par_file_name}> par${i}_${par_file_name} doneexport par${i}_sum=`cat par${i}_${par_file_name}|awk '{print $2}' | awk '{sum+=$1}END{print sum}'`#echo `eval echo \\${par${i}_sum}`donefunction getMin{param_no=$#for i in {1..$param_no}doexport par${i}_=`eval echo \\${${i}}`donemin_sum=$par1_min_par=par1_for i in {2..$param_no};doj=`expr $i - 1`tmp_cur_par=par${i}_tmp_cur_sum=`eval echo \\${${tmp_cur_par}}`if [ $min_sum -le $tmp_cur_sum ]then min_sum=$min_sum min_par=$min_parelse min_sum=$tmp_cur_sum min_par=$tmp_cur_parfidoneecho $min_par}function getSumList{for k in {1..$par_no}do#export par${k}_sum=`cat par${k}_${par_file_name}|awk '{print $2}' | awk '{sum+=$1}END{print sum}'`#echo `eval echo \\${par${k}_sum}`#par_list="$par_list `eval echo \\${par${k}_sum}`"#echo $par_listtmp_sum=`cat par${k}_${par_file_name}|awk '{print $2}' | awk '{sum+=$1}END{print sum}'`echo $tmp_sum#tmp_par_list=${tmp_par_list} "" $tmp_sumdone#echo $tmp_par_list}j=`expr $par_no + 1`for i in {$j..${obj_length}}dotmp_obj=`sed -n ''$i'p' ${par_file_name}'`tmp_obj2=`sed -n ''$i'p' ${par_file_name}|awk '{print "execute dbms_mview.refresh('\''"$1"'\'','\''C'\'');"}'`par_list=`getSumList`tmp_par=`getMin $par_list`echo 'move '`sed -n ''$i'p' ${par_file_name}|awk '{print $1}'` ' to '$tmp_parecho $tmp_obj >> ${tmp_par}${par_file_name}for tmp_sid in {$sid_list}doecho $tmp_obj2 >> ${tmp_par}${par_file_name}.$tmp_siddonetmp_par=0donefor i in {1..$par_no}docat par${i}_${par_file_name}|awk '{print $2}' | awk '{sum+=$1}END{print sum}'done脚本运行方式如下,比如我们需要把tab_parall.lst中的内容进行切分,切分为10个并行线程,可以这样运行脚本。ksh split.sh tab_parall.lst 10tab_parall.lst的内容如下:table1 1000000table2 800000table3 500000table4 300000.....生成的脚本如下:-rw-r--r-- 1 prodbuser dba 2132 Jun 22 18:36 par10_tab_parall.lst-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.cust01-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.usg01-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.usg02-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.usg03-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.usg04-rw-r--r-- 1 prodbuser dba 101 Jun 22 18:35 par1_tab_parall.lst-rw-r--r-- 1 prodbuser dba 976 Jun 22 18:36 par2_tab_parall.lst-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.cust01-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.usg01-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.usg02-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.usg03-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.usg04-rw-r--r-- 1 prodbuser dba 1997 Jun 22 18:36 par3_tab_parall.lst-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.cust01-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.usg01-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.usg02-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.usg03-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.usg04-rw-r--r-- 1 prodbuser dba 2077 Jun 22 18:36 par4_tab_parall.lstv
所以目前为止,难点有三个,一个是能够把多个表进行并行切分,第二个就是能够合理的同步刷新的进度,第三个就是能够在多个节点间持续的进行切换。首先第一个问题是并行切分的部分,可以参考下面的代码。这个脚本会把多个表进行切分,然后生成物化视图刷新的语句,不同的节点会生成单独的一套脚本便于控制和管理。par_file_name=$1sort -rn -k2 $par_file_name > ${par_file_name}_tmpmv ${par_file_name}_tmp ${par_file_name}par_no=$2obj_length=`cat ${par_file_name}|wc -l `echo $obj_lengthsid_list=cust01,usg01,usg02,usg03,usg04for i in {1..$par_no}do for tmp_sid in {$sid_list} do sed -n ''$i'p' ${par_file_name}> par${i}_${par_file_name} doneexport par${i}_sum=`cat par${i}_${par_file_name}|awk '{print $2}' | awk '{sum+=$1}END{print sum}'`#echo `eval echo \\${par${i}_sum}`donefunction getMin{param_no=$#for i in {1..$param_no}doexport par${i}_=`eval echo \\${${i}}`donemin_sum=$par1_min_par=par1_for i in {2..$param_no};doj=`expr $i - 1`tmp_cur_par=par${i}_tmp_cur_sum=`eval echo \\${${tmp_cur_par}}`if [ $min_sum -le $tmp_cur_sum ]then min_sum=$min_sum min_par=$min_parelse min_sum=$tmp_cur_sum min_par=$tmp_cur_parfidoneecho $min_par}function getSumList{for k in {1..$par_no}do#export par${k}_sum=`cat par${k}_${par_file_name}|awk '{print $2}' | awk '{sum+=$1}END{print sum}'`#echo `eval echo \\${par${k}_sum}`#par_list="$par_list `eval echo \\${par${k}_sum}`"#echo $par_listtmp_sum=`cat par${k}_${par_file_name}|awk '{print $2}' | awk '{sum+=$1}END{print sum}'`echo $tmp_sum#tmp_par_list=${tmp_par_list} "" $tmp_sumdone#echo $tmp_par_list}j=`expr $par_no + 1`for i in {$j..${obj_length}}dotmp_obj=`sed -n ''$i'p' ${par_file_name}'`tmp_obj2=`sed -n ''$i'p' ${par_file_name}|awk '{print "execute dbms_mview.refresh('\''"$1"'\'','\''C'\'');"}'`par_list=`getSumList`tmp_par=`getMin $par_list`echo 'move '`sed -n ''$i'p' ${par_file_name}|awk '{print $1}'` ' to '$tmp_parecho $tmp_obj >> ${tmp_par}${par_file_name}for tmp_sid in {$sid_list}doecho $tmp_obj2 >> ${tmp_par}${par_file_name}.$tmp_siddonetmp_par=0donefor i in {1..$par_no}docat par${i}_${par_file_name}|awk '{print $2}' | awk '{sum+=$1}END{print sum}'done脚本运行方式如下,比如我们需要把tab_parall.lst中的内容进行切分,切分为10个并行线程,可以这样运行脚本。ksh split.sh tab_parall.lst 10tab_parall.lst的内容如下:table1 1000000table2 800000table3 500000table4 300000.....生成的脚本如下:-rw-r--r-- 1 prodbuser dba 2132 Jun 22 18:36 par10_tab_parall.lst-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.cust01-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.usg01-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.usg02-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.usg03-rw-r--r-- 1 prodbuser dba 4639 Jun 22 18:36 par10_tab_parall.lst.usg04-rw-r--r-- 1 prodbuser dba 101 Jun 22 18:35 par1_tab_parall.lst-rw-r--r-- 1 prodbuser dba 976 Jun 22 18:36 par2_tab_parall.lst-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.cust01-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.usg01-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.usg02-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.usg03-rw-r--r-- 1 prodbuser dba 2045 Jun 22 18:36 par2_tab_parall.lst.usg04-rw-r--r-- 1 prodbuser dba 1997 Jun 22 18:36 par3_tab_parall.lst-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.cust01-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.usg01-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.usg02-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.usg03-rw-r--r-- 1 prodbuser dba 4296 Jun 22 18:36 par3_tab_parall.lst.usg04-rw-r--r-- 1 prodbuser dba 2077 Jun 22 18:36 par4_tab_parall.lstv