API接口的加速利器-varnish使用大全(含生产集群环境布署)
Varnish是什么
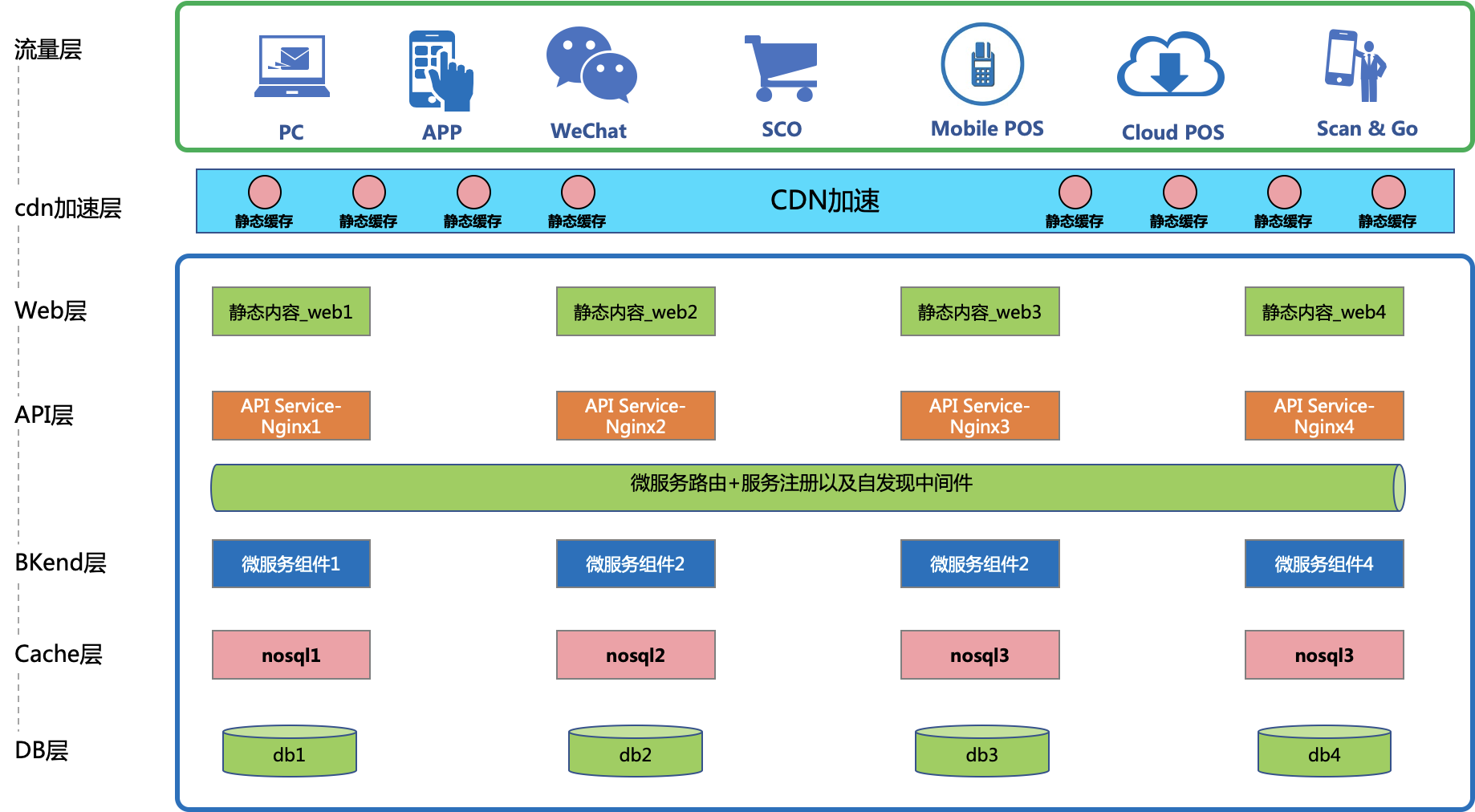
这是一张标准的新零售行业中的微服务化组件从前到后的架构概览图。
我们都知道,凡是静态内容,一般我们都有cdn来进行缓存,cdn缓过的内容之前会从cdn处返回给到前端流量层客户端。
但是,往往我们有一些这样的东西,相信大家并不陌生,如:http://localhost:8081/service/getBigResponse?userid=ymk,然后该api接口会返回下面这样的一个json串。
[{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":504,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":505,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":506,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":507,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":508,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":509,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":510,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":511,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":512,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":513,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":514,"userid":"ymk"},
{"name":"abc","barcode":"","quantities":"33","price":"12.00","id":515,"userid":"ymk"},
这个json串,一般在企业级环境特别是零售电商都不下千行,假设我们说它的大小是25k。
25k?大吗?不大,好,我们套上你的真实生产环境,并发我们说假设1万,1万的并发其实很小,除非你之前的项目实在是。。。此处省略一些字!
我们把1万并发*25k=差不多要245mb的流量,而且这个1万并发是每秒哦,我们假设这样的行为持续了:5分钟,那你的网站从前到api层、到bkend层都就会被造成:5*60*245mb的压力。
所以,业界在很早前就已经相过,我们是不是可以把api里,根据访问路径,每一个参数如:?userid=ymk和userid=abc这样的请求后返回的不同的值也可以类似cdn一样缓存起来?
很可惜,一些主流的cdn暂时不支持这种缓存,因此在5年多前我们是自己在gateway处,书写相应的规则来作到根据请求的url、参数名的不同而缓存访问后的响应的。
这样,我们就可以直接在web这一层直接把用户请求的同样的内容给返回回去了,一方面减少了网站的整体压力另一方面加速了前端访问的请求。
不过,需要注意的点是:
不是什么东西都可以这样做缓存的!特别是一些实时性很强的数据如:下完订单库存的显示也是动态的扣减的,这种就不可以把订单请求给缓存哦,这会造成数据上的“脏读”。
那么什么东西可以被缓存呢?我举一例来说:sku为红富士产地南海a-001的相关产品信息,这种信息就可以使用“缓存”,因为你的这个sku除非被“下架”,要不然,它的信息是始终不会变的,那么不管全国是a还是b还是c来访问这个sku,你的这个sku信息都是不会在短时间内改变的,对吧?
那么我们为了解决根据api的请求、参数的不同而缓存不同的商品,大家试试看可以自己利用redis来写这个url解析,如果你只是解决一个请求,那么你会觉得写一个这样的解释器并不难,但如果你要考虑电商、o2o类网站内上千个url的处理,光一个这样的解析器你可能就要开发好几个月呢!
所以我们才有了varnish,varnish就是用来解决类似上述这样的web层api请求访问缓存用的,它是一个开箱即用的开源组件,你不需要写那么复杂的http协议、url路径解压,你要做的事就是:哪一些url请求需要被缓存,把它们一个个列进varnish,varnish自动会根据请求的url、参数的不同而动态的去缓存不同的返回内容。
安装Varnish
不多bb,直接进入主题。此处我们使用的是centos7.x+
安装前的依赖包安装
我们使用标准的编译式安装,编译varnish前我们需要先安装一系列的依赖包,请使用如下命令:
yum install autoconf automake jemalloc-devel libedit-devel libtool ncurses-devel pcre-devel pkgconfig python-docutils python-sphinx graphviz下载varnish 4.1.11
wget https://varnish-cache.org/_downloads/varnish-4.1.11.tgz开始编译
tar -xzvf varnish-4.1.11.tgz
cd varnish-4.1.11/
./configure --prefix=/usr/local/varnish4
make && make install
ln -s /usr/local/varnish4/sbin/* /usr/sbin/
ln -s /usr/local/varnish4/bin/* /usr/local/bin/
cp -a /usr/local/varnish4/share/doc/varnish/example.vcl /usr/local/varnish4/var/varnish/default.vcl此处我们做了如下7步事:
- 解压varnish 4.11源码包;
- 进入被解压的源码包;
- 指定varnish在编译和安装后装在/usr/local/varnish4这个目录下;
- 使用centos的gcc编译并在编译结束后install;
- 把varnish的sbin(启动终止varnish)命令行工具链接到通用访问目录下,相当于加了一个path环境变量;
- 把varnish的bin(varnish的一些辅助服务命令如:varnish log服务)命令行工具链接到通用访问目录下,相当于加了一个path环境变量;
- varnish的核心配置为.vcl文件,它里面用的是简单的c语言来书写这些核心配置的,因此我们copy一个样本.vcl文件进入/varnish安装目录/var/varnish下;
创建varnish远程admin端口
varnish启动时会有一个admin端口,这个admin端口需要使用到生成的密钥,那么怎么生成这个密钥,我们可以使用下面的命令
dd if=/dev/random of=/etc/vc cont=1此时,我们在后续管理varnish就可以使用以下的命令了
./varnishadm -S /etc/vc -T 127.0.0.1:9994配置varnish
配置场景及期望目标
如前面所提到的,varnish的一些缓存、路由、时效的配置都是在.vcl文件中所描述的。
所以我们这边以这么一个sample来解释我们的常用配置(如果有多个url请求也可以使用类似我这种写法)。
先来看看我们需要配置的业务场景:
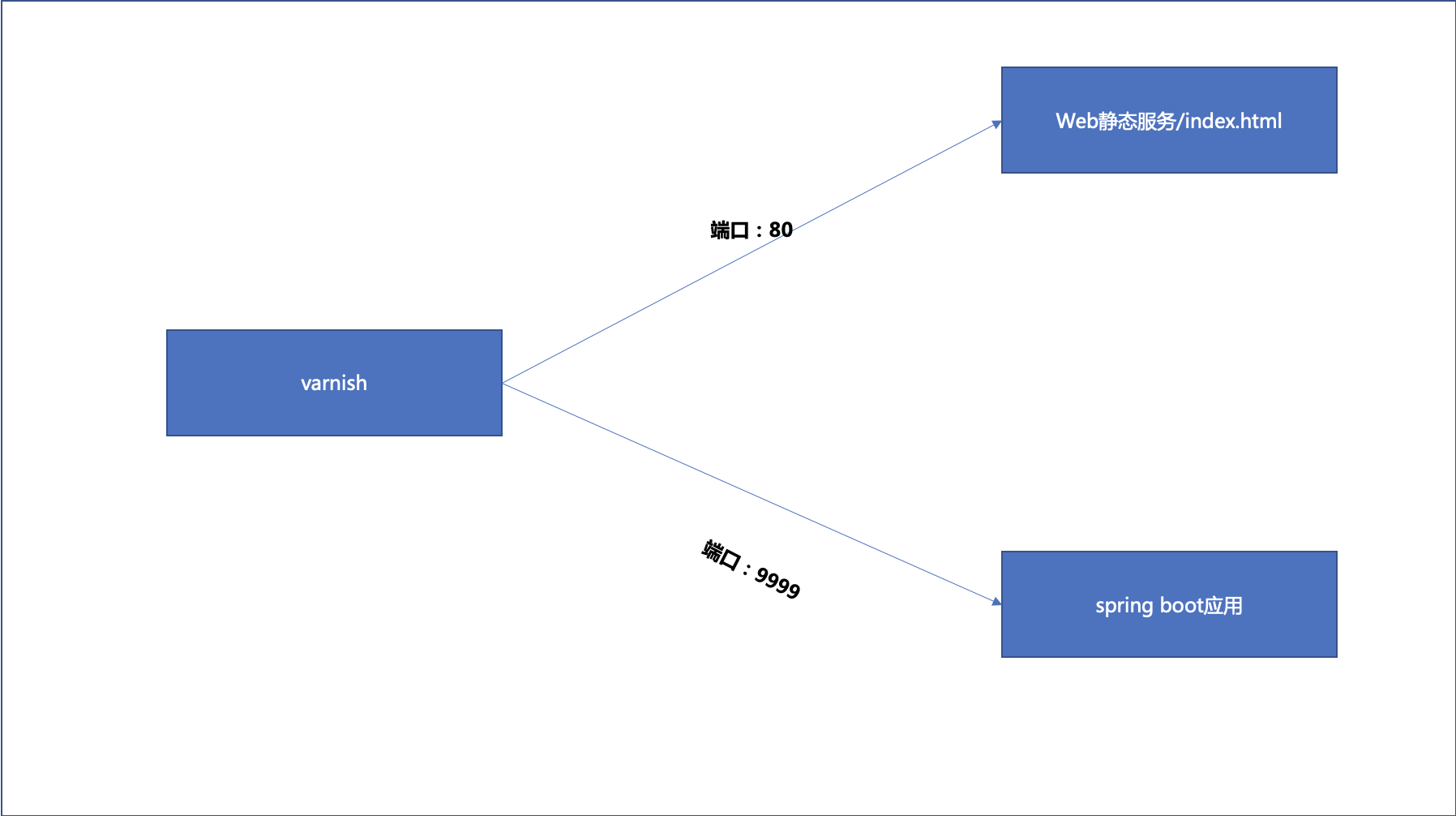
我们要完成的事就是:
- 对于web服务器上的一个静态的html工程进行缓存;
- 对于app服务器运行在9999端口上的api http://localhost:8081/service/getBigResponse?userid=xxx 进行缓存
为了验证,我们在数据库表中建有一张这样的表:
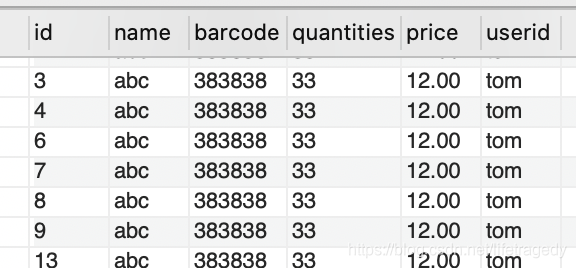
在表中,我们存储了3种不同的userid对应的数据。
select id,name,barcode,quantities,price,userid from sample_table where userid='ymk';
select id,name,barcode,quantities,price,userid from sample_table where userid='tom';
select id,name,barcode,quantities,price,userid from sample_table where userid='chris';然后我们制作了一个controller,它所对应的api为:/service/getBigResponse?userid=xxx,它所对应的代码很简单:
controller层代码
@GetMapping(value = "/getBigResponse", produces = "application/json")
@ResponseBody
public List<ProductBean> getBigResponse(@RequestParam(value = "userid") String userid) {
List<ProductBean> list = new ArrayList<ProductBean>();
return sampleDataService.getSampleData(userid);
}service层代码
@Service
public class SampleDataService {
// private final static Logger logger = LoggerFactory.getLogger(SampleDataService.class);
@Resource
private SampleDataDao sampleDataDao;
public List<ProductBean> getSampleData(String userid) {
return sampleDataDao.getSampleData(userid);
}
}dao层代码
@Component
public class SampleDataDao {
private final static Logger logger = LoggerFactory.getLogger(SampleDataDao.class);
@Resource
private JdbcTemplate jdbcTemplate;
public List<ProductBean> getSampleData(String userid) {
List<ProductBean> prodList = new ArrayList<ProductBean>();
String sampleSql = "select id,name,barcode,quantities,price,userid from sample_table where userid=?";
prodList = jdbcTemplate.query(sampleSql, new RowMapper<ProductBean>() {
@Override
public ProductBean mapRow(ResultSet rs, int rowNum) throws SQLException {
ProductBean product = new ProductBean();
product.setId(rs.getInt("id"));
product.setName(rs.getString("name"));
product.setQuantities(rs.getString("quantities"));
product.setPrice(rs.getString("price"));
product.setUserid(rs.getString("userid"));
return product;
}
}, userid);
if (logger.isDebugEnabled()) {
logger.debug(">>>>>>get sampleData list size->" + prodList.size());
}
return prodList;
}
}这个api在前台访问后有:41kb。所以如果并发量大时,它就会给网站造成很大的性能压力与冲击。
所以我们使用varnish后,做到的效果应该如下:
不过全国有多少人访问,只要有了第一个人访问过/service/getBigResponse?userid=chris,那么后面所有访问/service/getBigResponse?userid=chris的用户将直接从varnish返回访问结果,而不会再走一圈controller->service->dao→db了。
这边多说一句,哪怕你后端做了redis,这个流量压力也是会渗透到controller->service→redis这样的层面的。和从varnish端直接返回,你们觉得,哪个更快?哪个更优?
开始配置
键入以下命令进行配置
vi /usr/local/varnish4/var/varnish/default.vcl把下面这一陀放入到default.vcl文件内
vcl 4.0;
probe nghealthy { #定义一个前端健康检测的标准
.url = "/"; #检查通过访问nginx上的静态目录的根即index.html的返回值来判断web应用是否健康
.interval = 5s; #每隔5秒检查一下
.timeout = 2s; #检查信号发出后超过2s没反应认为后台相应的服务挂了
}
probe backwebhealth { #定义一个后端健康检测的标准
.url = "/healthy"; #检查通过访问spring boot上的一个叫/health的get请求的返回值来判断spring boot应用是否健康
.interval = 5s; #每隔5秒检查一下
.timeout = 2s; #检查信号发出后超过2s没反应认为后台相应的服务挂了
}
backend static
{
.host = "10.224.16.105"; #定义varnish连接的web服务的地址在哪
.port = "80"; #定义varnish通过哪个端口连接上web服务的地址
.probe = nghealthy; #定义该服务的健康检查的配置取的是哪一段配置
}
backend dynamic
{
.host = "10.224.17.138"; #定义varnish连接的spring boot应用服务器的地址在哪
.port = "9999"; #定义varnish连接的spring boot的应用服务器的端口是什么
.probe = backwebhealth; #定义该服务的健康检查的配置取的是哪一段配置
}
sub vcl_recv #这个就是vcl语句使用的就是c语法这里面定义了varnish的缓存规则了
{
if(req.url ~ "\\.html") #如果是.html那么需要缓存因此使用的是return hash这就代表走缓存
{
set req.backend_hint=static;
return(hash);
}
if(req.url ~ "(?i)/service/getBigResponse") #如果是/service/getBigResponse这条api那么需要使用缓存,问号i代表不区分大小写
{
set req.backend_hint=dynamic;
return(hash);
}
}
sub vcl_backend_response {
set beresp.ttl = 7200s; #缓存超时,当超时到了varnish里的内容会失效,此时http请求过来就是透过varnish直接请求后端了
}
sub vcl_deliver {
if (obj.hits > 0) { # 为响应添加X-Cache首部,显示缓存是否命中
set resp.http.X-Cache = "HIT from " + server.ip;
} else {
set resp.http.X-Cache = "MISS";
}
}启动varnish
全部配置配完了,我们就可以启动varnish啦。varnish的启动简单的话就一句话,可是我们说的是生产级的应用,因此我们需要优化varnish。
本人经过整理,稍稍对varnish的启动参数做了微调,即达到了性能差100%的差距,下面我给出varnish启动时的必要的一些参数,这些参数的修改是有着直接影响的。
Varnish的启动参数很有意思,它是直接写在命令行里的,请先切换到/usr/local/varnish/sbin目录下运行下面这条命令:
./varnishd -a :9993 -T 127.0.0.1:9996 -f ../var/varnish/default.vcl -s malloc,2G \
-p thread_pools=24 \
-p thread_pool_min=500 \
-p thread_pool_max=10000 \
-p thread_pool_timeout=120 \
-p timeout_idle=60 \
-p timeout_linger=1 \
-p http_resp_hdr_len=16k \
-p http_max_hdr=256 \
-p http_req_hdr_len=16k \
-p lru_interval=120Varnish的日志
varnish的日志默认是不会产生的,它是使用varnish的日志启动命令来启动的,用以下命令输出varnish的启动与运行日志即可(无论是在varnish启动前还是启动后都可以启动varnish的日志)。
首先,切换到/usr/local/varnish/bin目录,运行以下这条命令:
./varnishlog -D -a -w /var/log/varnish/varnish.log验证varnish
验证varnish的正确性
我们通过varnish暴露的地址与端口:10.224.16.105:9993,使用了10个请求,先后访问/service/getBigResponse?userid=1这个url请求。
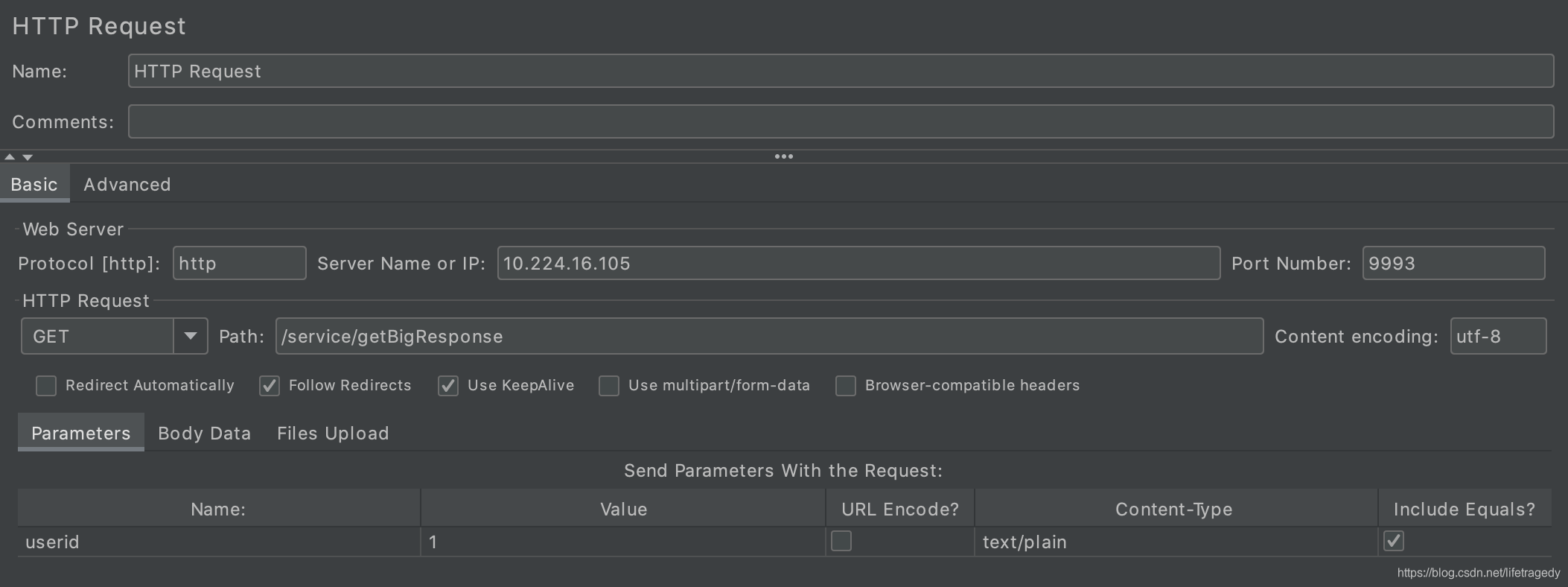
于是我们得到以下10个结果,我们来看第一个请求,如上面所述,它因为是第一次因此它肯定不会走varnish,它走的是原站请求。
我们接着往后看第二个、第三个、第四个请求头
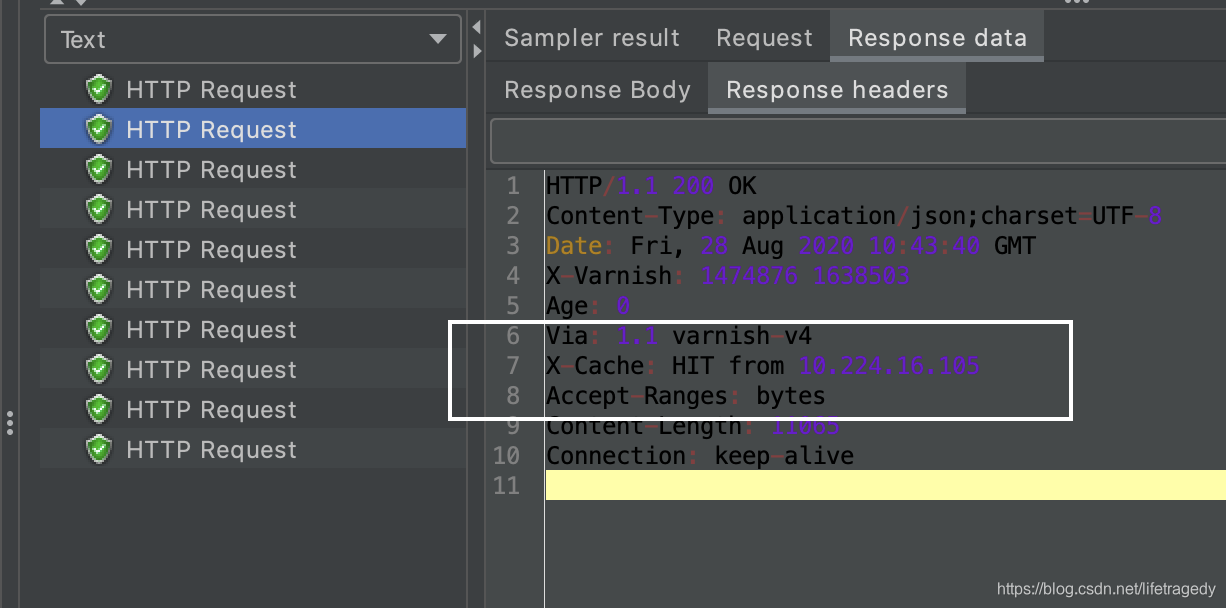
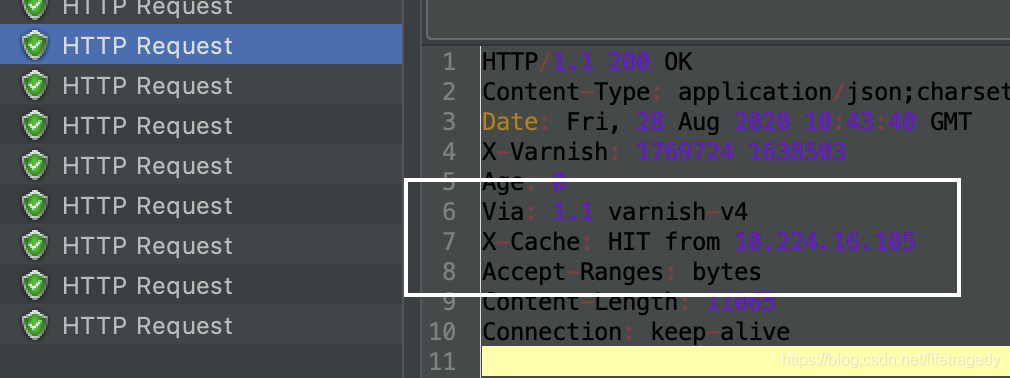

全部为命中,这说明varnish的配置完全如我们预期。
验证varnish带来的性能上的提升
我们使用50个线程共运行20次,分成
-
直接访问源站的/service/getBigResponse
-
通过varnish访问/service/getBigResponse
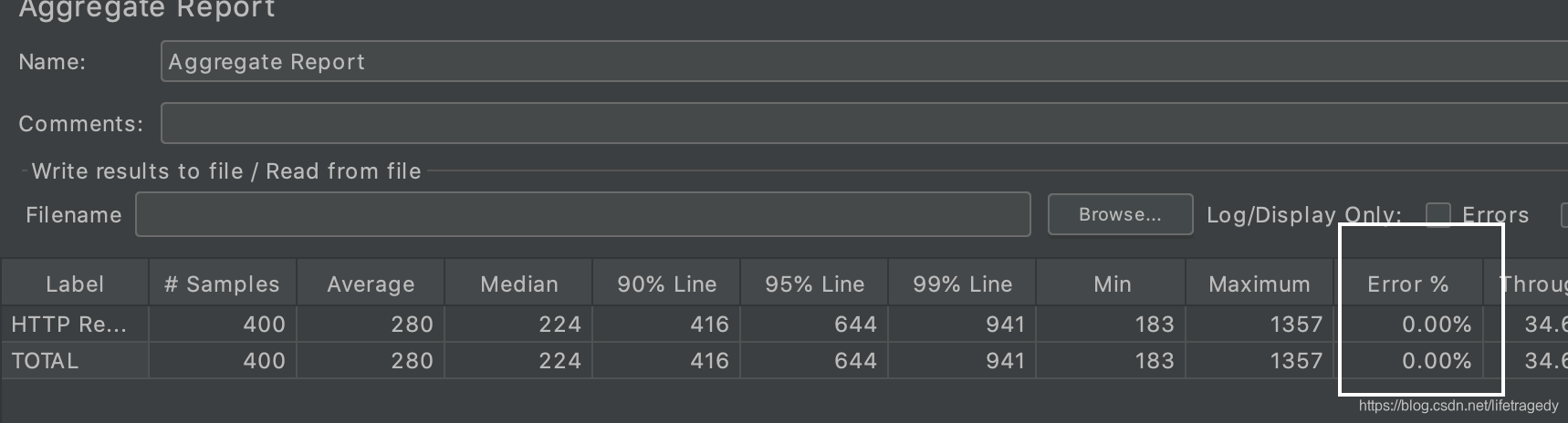
 这是测试后的截图,我们先来看“平均响应时间”这一栏,仅此一项,使用varnish后可以提高27.77%的效就。
这是测试后的截图,我们先来看“平均响应时间”这一栏,仅此一项,使用varnish后可以提高27.77%的效就。
别急,还有!
来看最高响应时间这一栏的区别。
不使用访问varnish直接访问源站走了ng->controller→service→dao这样的一个回路,当然这个一栏的时间大,这同时也意味着后台的cpu、内存、网络来回的io承受着高度的压力;
而使用了访问varnish来代理后台api接口,整体网站几乎这个压力下降了665%;
速度:提升27.77%;
压力:下降665%;
整体我们可以得到27.77%+665%约等于692.77%这个性能提升。
别急,更有后面的猛料!
对于大并发(2.5万qps)下,我们创造过单接口提升195%的提升,这仅仅只是单根微信小程序端的api接口的性能提升还没有算后端服务的整体消耗的下降呢!

Varnish的集群搭建-真正走向生产环境
位于云环境的架构
一般来说,国内稍微选进一点的零售已经都使用云环境了,因此在云环境上Varnish是这样的一个搭建的。
这边的这个ILB,你可以认为是一个"F5",它起到了load balance,下面可以挂多个Varnish。
这边需要注意的几个地方是:
- Varnish的配置必须>=你的原先Web服务器的硬件配置;
- Varnish必竟是在你的Web服务器(一般来说我们用的都是Nginx)上多架设了一层,为了不影响你的原先系统做到“透明无缝“的移植,Varnish上一定要配备固态硬盘同时和原先的Web服务器间以万兆光纤的内网带网通讯;
- 此处需要注意的一点特别强调一下,varnish的位置必须位于流量层Nginx的后面,反向代理各service Nginx的前面这么一个位置上;
- 如果后端的api service不是用的ng作反向代理,用的是注册中心、云原生一类的东西,那么你的varnish就必须位于流量层nginx的后端,service的前端这么一个位置

位于数据中心环境的架构

还有一种是位于数据中心(DC)环境内的Varnish的搭建方法,由于没有类似ILB以及云上多ip分段间的影响,我们一般都会使用Haproxy来挂载多个Varnish,为了Haproxy本身的高可用我们也会使用多个Haproxy(至少1组2个Haproxy)来做这个虚IP。
同样,它的配置必须>=你的Web服务器的硬件配置。
这也是我们接下来会重点展开的内容,因为在我们的本机或者是家里的服务器环境,我们没有这么奢侈可以让我们用ILB这样的东西,但是我们可以有多个vm,那么我们就使用Haproxy来模拟ILB搭建Varnish的集群吧,等以后到了云上,你Haproxy这一层都可以不用搭建了,直接在云上购买一个ILB,挂上你的多个Varnish服务进程即可。
演示生产上以集群方式的Varnish-搭建要求
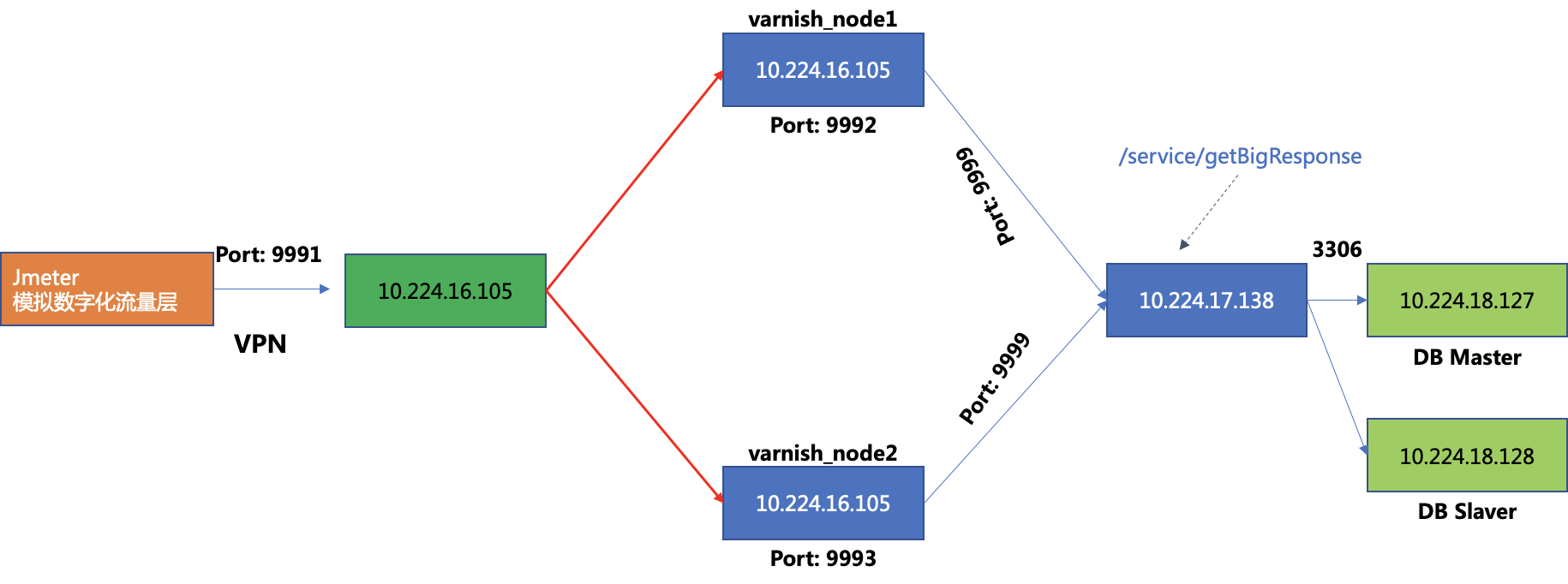
我很穷(可是我很温柔),因此我们在一台vm上搭建2个Varnish节点,它们分别运行在9992与9993端口上。
接下去我们用两个varnish通过9999端口连至后台的一个spring boot 应用10.224.1.138上。
然后我们在前台使用jmeter调用http://10.224.16.195:9991/service/getbigResponse以实现varnish通过haproxy做成的集群的访问。
安装varnish
前面我们已经安装过一个varnish了,步骤一样,我们再安装一个varnish4_node2 。
我们在其的/var/varnish子目录下同样有一个和之前单机版varnish一模一样的default.vcl文件。

然后我们使用相同的命令,启动第二节点,这样,我们有两个varnish,一个运行在9992端口,一个运行在9993端口。
./varnishd -a :9992 -T 127.0.0.1:9995 -f ../var/varnish/default.vcl -s malloc,2G \
-p thread_pools=24 \
-p thread_pool_min=500 \
-p thread_pool_max=10000 \
-p thread_pool_timeout=120 \
-p timeout_idle=60 \
-p timeout_linger=1 \
-p http_resp_hdr_len=16k \
-p http_max_hdr=256 \
-p http_req_hdr_len=16k \
-p lru_interval=120
接下去我们就要配置haproxy了。
安装和配置haproxy
yum -y install haproxy开启haproxy的日志功能
haproxy默认使用的是centos的rsyslog来输出日志的。
因此我们先配置rsyslog。
配置rsyslog需要配置2个文件:
- /etc/sysconfig/rsyslog
- /etc/rsyslog.conf
/etc/sysconfig/rsyslog的配置
把#SYSLOGD_OPTIONS=""这句注释掉,改成下面这样。
# Options for rsyslogd
# Syslogd options are deprecated since rsyslog v3.
# If you want to use them, switch to compatibility mode 2 by "-c 2"
# See rsyslogd(8) for more details
#SYSLOGD_OPTIONS=""
SYSLOGD_OPTIONS="-r -m 0"/etc/rsyslog.conf的配置
第一步,放开下面这两个参数
#$ModLoad imudp
#$UDPServerRun 514
# rsyslog configuration file
# For more information see /usr/share/doc/rsyslog-*/rsyslog_conf.html
# If you experience problems, see http://www.rsyslog.com/doc/troubleshoot.html
#### MODULES ####
# The imjournal module bellow is now used as a message source instead of imuxsock.
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
#$ModLoad imklog # reads kernel messages (the same are read from journald)
#$ModLoad immark # provides --MARK-- message capability
# Provides UDP syslog reception
$ModLoad imudp
$UDPServerRun 514第二步,在文件最后增加这么两句话
local7.* /var/log/boot.log
local0.* /var/log/haproxy/haproxy.log
local2.* /var/log/haproxy/haproxy.log修改完必后我们就要开发配置haproxy了。
haproxy的配置
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 65545
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode http
#log global
log 127.0.0.1 local2
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 5m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 65545
option http-pretend-keepalive
frontend web 10.224.16.105:9991
bind 10.224.16.105:9991
stats enable
stats uri /haproxy_admin
stats hide-version
stats refresh 2s
use_backend varnish_srvs
# 指定后端的Varnish缓存服务器
# 使用的端口是varnish的默认端口,这一点需要在varnish服务器中进行配置
backend varnish_srvs
#暂时注掉#balance uri
#暂时注掉#hash-type consistent
balance roundrobin
server varnish1 10.224.16.105:9992 weight 1 check
server varnish2 10.224.16.105:9993 weight 1 check在这个haproxy里我们把haproxy指向了两个varnish节点,同时我们还开启了一个haproxy的admin界面,http://10.224.16.105:9991/haproxy_admin

核心配置解说如下:
- balance roundrobin,使用集群模式;
- maxconn 65545,这个值必须放大,如果这个值不够大或者<后台nginx或者是spring boot应用的线程,haproxy会在前端http连接到达一定数量时打断客户端连接,造成大量socket time out的http错误;
- log 127.0.0.1 local2,这边指定了haproxy的日志行为level 2
log level解说
local 0: debug –有调式信息的,日志信息最多
local 1: info –一般信息的日志,最常用
local 2: notice –最具有重要性的普通条件的信息
local 3: warning –警告级别
local 4: err –错误级别,阻止某个功能或者模块不能正常工作的信息
local 5: crit –严重级别,阻止整个系统或者整个软件不能正常工作的信息
local 6: alert –需要立刻修改的信息
local 7: emerg –内核崩溃等严重信息
none –什么都不记录
从上到下,级别从低到高,记录的信息越来越少
启动haproxy
systemctl restart rsyslog #启动haproxy前我们让之前修改的rsyslog生效
systemctl restart haproxy访问 http://10.224.16.105:9991/haproxy_admin,看到如下界面

验证haproxy+两个varnish群
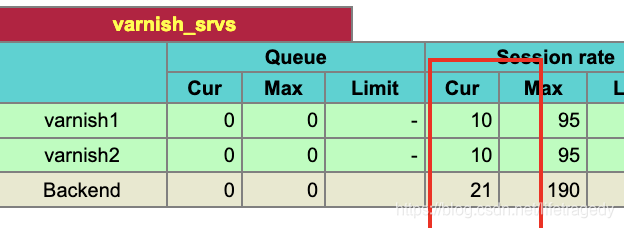
我们通过haproxy的端口把并发发到2个varnish上。
我们起了50个线程,连续100次的访问haproxy。
通过haproxy的admin端,我们可以看到请求已经落入两个varnish节点上了。
我们在并发请求持续的时候,杀9993这个节点。

啊杀!
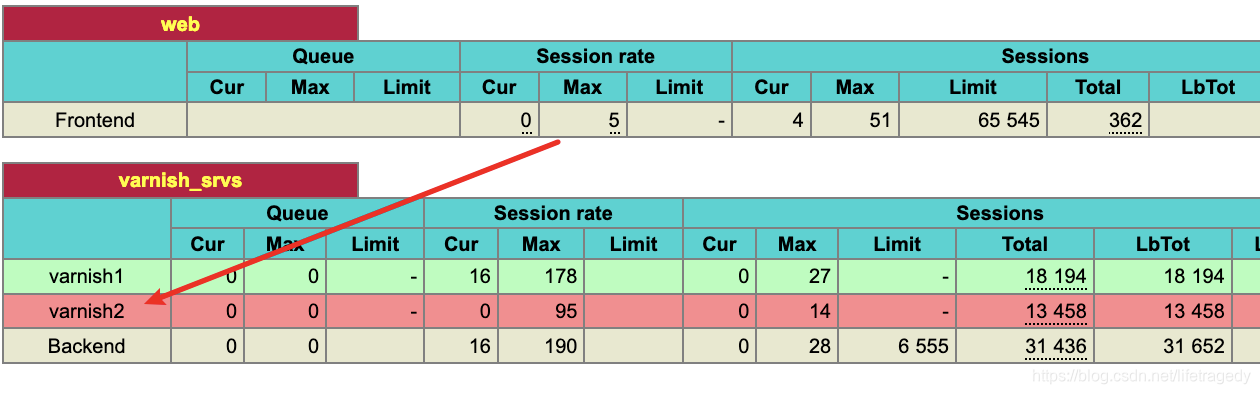
再来看请求,一点没有错误,因为所有的请求都被haproxy给转到了运行在9992端口上的varnish服务了。
至此,整个varnish具备了上生产的条件了。