Cloudera Manager集群(CDH6.2.0.1)完整搭建指南
目录
引子
下载所有安装包准备离线安装
大数据安装前的环境规划
基础环境准备
host名与ip绑定
各主机间设成免密登录
安装openjdk
各节点间关selinux关firewalld
然后使用以下命令在各个节点禁firewalld
普通用户(appadmin)sudo su提权时的免密
设置大数据集群的文件打开数
设置大数据使用系统最大物理内存
安装离线安装时的Yum源
先设nginx
开始设置离线Yum源
设置mysql
导入GPG key(如果没有这步操作,很可能cloudera服务安装失败)manager节点
安装CDH的Manager节点
对/opt/cloudera目录进行赋权
正式安装前的初始化数据库中的数据
CDH-6.2.0的正式安装
附录:如何干净的铲除大数据
在agent即一般节点上卸载大数据
在Server即Management节点上卸载大数据
引子
啊,大数据!
其实并不难,难的是你“愿不愿意学”。因此我们以一篇大数据的环境搭建来入门。
2005年,会在redhat 7上搭建oracle,搭完跑通,就能拿到5000块钱。因此,在那时流行着一句话:如何学linux?在linux上会装oracle了你就会linux了。
那么大数据的安装将是在linux上安装10几个乃至几十个oracle的工作量,涉及到的知识之广,分门别类。在此,我以一文将这些知识点全部串通起来,使得按照此文安装的人员可以迅速在1天内即完成大数据集群的安装以及了解到一些相关的原理。
下载所有安装包准备离线安装
请去以下网址下载cdh所有的离线安装包,推荐使用cdh yum离线安装方式。
https://archive.cloudera.com/cdh6/6.2.0/parcels/
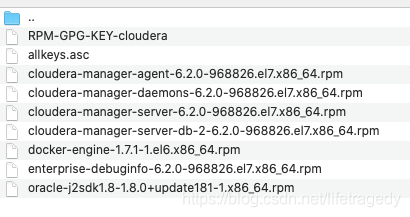
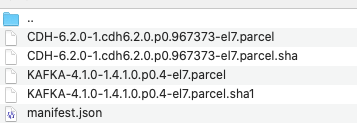
![]()
此处,记得mysql一定要安装5.7.26及以上,这是基本。不要试图连线安装mysql,因为mysql的官方yum源太慢,一秒才20,30k的速度下载,你会等疯掉的。

把相关的下载包我们部部上传到主服务器,比如说:192.168.0.1的/home/appadmin目录下,建立一个cdh6.2.0,把所有这些文件全部放在这个目录下。
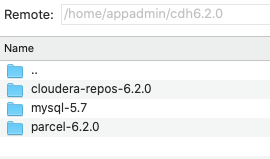
- 所有rpm以及allkeys.asc和RPM-GPG-KEY-cloudera放在cloudera-repos-6.2.0目录下
- 所有的.parcel以及CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel.sha(可能没有,没有后面教你怎么生成)以及manifest.json放在parcel-6.2.0目录下
- mysql的所有内容位于mysql5.7包下
大数据安装前的环境规划
全部使用centos7.4及以上,内存全部为:16gb,cpu:2c及以上即可,硬盘一定要使用ssd,每台200gb即可。
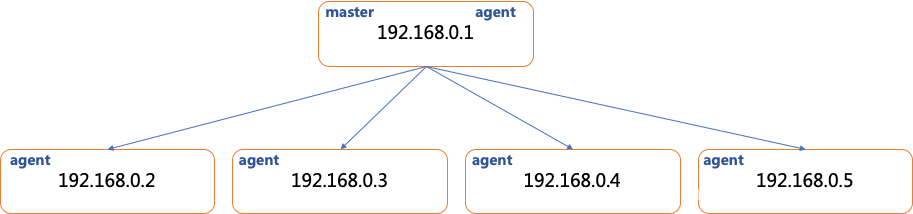
我们一共有5台主机:
- 192.168.0.1
- 192.168.0.2
- 192.168.0.3
- 192.168.0.4
- 192.168.0.5
我们会在192.168.0.1上安装cloudera manager这个中央控制端,在其它各节点安装cloudera agent即子节点。为了充分利用资源,我们会在192.168.0.1上也安装一个agent(子节点)端。整体结构如下:
基础环境准备
host名与ip绑定
在每台机器上编辑/etc/hosts文件中列入
|
|
各主机间设成免密登录
因为大数据安装是以离线方式,因此在实际安装时会从master即cdh01节点,把那个上g的parcel通过scp“下发”到每一台主机上。cdh群要求各主机间必须为root或者是非root但是需要免密登的帐户来执行这个过程。
显然,我们不可能在生产环境使用root帐号安装cdh群,因此我们会使用appadmin这个帐号,因此我们在每一台机器上都有appadmin这个帐号,它同时还必须为sudo提权资格用户。然后在5台机器间我们把appadmin设成免密登录。
第一步:在appadmin远程ssh已经登录的情况下执行下面这个命令
|
|
提到提示后什么都不用管,直接回车+回车+回车,三个回车代表密码为空、密钥生成路径为默认,即在当前/home/appadmin/目录下会产生一个.ssh的目录,里面会有2个文件:
- id_rsa
- id_rsa.pub
第二步:生成authorized_keys文件
|
|
id_rsa是公钥内容,它的意思就是把公钥内容全部写入一个新的文件叫authorized_keys文件,为什么一定要是authorized_keys这个名字呢?
![]()
那是因为在/etc/ssh/sshd_config中,有这么一行语句
它规定了你的免密登录时寻找的文件名是一个什么名字、在哪找到它?你也可以更改,不过如果你更改了这个文件记得一定要systemctl restart sshd才能生效。
第三步:在2号节点、3号节点、4号节点、5号节点重复以第一步到第二步,每个节点的.ssh目录内生成各自的authorized_keys文件
第四步:在2,3,4,5节点上分别执行以下的命令
|
|
它的作用是把本机自己的authorized_keys内的内容“追加”到目标服务器即master节点也是192.168.0.1的authorized_keys文件内容里,而不是覆盖,是追加进去。
因此,当2,3,4,5这四个节点运行完上述命令后,你在192.168.0.1的authorized_keys文件中会看到5条内容,如下sample所示:
第五步:把1号节点上这个authorized_keys远程拷贝到另外所有节点上并覆盖其它节点上的authorized_keys
|
|
截止这一步后,你在任意一台机器上做ssh appadmin@另一个机器的ip,你即可发觉,不需要再次输入密码了,那么,大数据集群节点间的免密登录宣告成功。
安装openjdk
yum install java-1.8.0-openjdk.x86_64
每一台参于cdh节点的机器,必须安装。
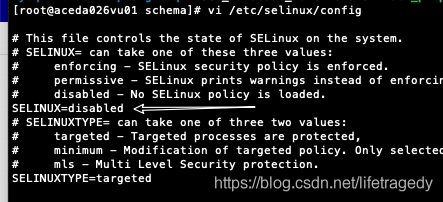
各节点间关selinux关firewalld
|
|
记得文件一定一定要长成下面这个样子,如果你打开文件这边是:enforcing,一定要把SELINUX=enforcing改成下面这个样,一定一定不要改错地方改到SELINUXTYPE上去啊,那边不要碰,碰错了,centos启动不了,然后你可以百度搜:改错 selinux SELINUXTYPE后怎么办,答案是:使用centos的紧急模式,然后自己使用修改centos的grub文件修复去搞定吧,蛮煅练人的!
然后使用以下命令在各个节点禁firewalld
|
|
普通用户(appadmin)sudo su提权时的免密
大数据在安装时,如果你是普通用户,安装时会使用sudo su提权root,但是此时因为是在图形化界面安装,因此你不可能每次sudo su时有机会输入你的密码,那么我们就一次性把sudo su提权时也做成免密即可,你可以使用以下命令:
|
|
然后你sudo su一下,发现直接就可以切换到了root权限了。分别在每台centos下运行。
设置大数据集群的文件打开数
默认centos打开文件数为1024,为了修改这个值,在每一个节点上,你需要做三步。
第1步:
|
|
第二步:
|
|
然后把文件内容改成:
|
|
第三步:
|
|
在最后加入以下几行
|
|
三步执行后,重启每一个节点。
设置大数据使用系统最大物理内存
在每台机器上运行
|
|
你也可以直接把这两条语句,写入/etc/rc.local,让服务器在启动时可以自动执行上述两条语句。
重启。
安装离线安装时的Yum源
我们的大数据会采用基于rpm的离线安装,因此我们需要设置离线安装yum源
先设nginx
如果你的nginx没有安装请使用如下命令安装
|
|
安装后请使用以下命令设成nginix开机自启动
|
|
设置nginx配置
|
|
我们在Server段内加入如下配置
|
|
它的意思就是我们会在nginx下挂一个虚拟目录,此虚拟目录允许“目录”浏览,因为nginx默认是不允许目录浏览的,这是owasp top10安全规范,我们这边也只是临时开启。因此这边的autoindex on;就代表开启了nginx的目录允许浏览权限。
然后我们在nginx的web根目录一般为/usr/share/nginx/html下再建立一个目录叫:cloudera-repos,全路径看起来是长成这个样的:/usr/share/nginx/html/cloudera-repos。
然后我们把/home/appadmin/cdh6.2.0/cloudera-repos-6.2.0内的所有东西全部copy到/usr/share/nginx/html/cloudera-repos。为了方便我们再运行一下这条命令
|
|

全部设完后使用以下命令重启nginx服务,如果一切服务启动正常那么我们可以继续到下一步了。
|
|
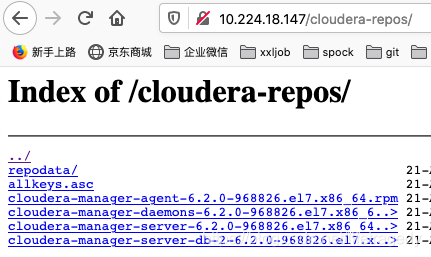
然后我们使用浏览器访问:http://192.168.0.1/cloudera-repos/,可以看到这个页面即宣告此步成功
如果你的nginx用的是1.1.8及以下的版本,上述nginx的conf文件中你需要这样设
|
|
这边的alias代表,你的cloudera-repos目录不在/usr/share/nginx/html目录下,可以外挂在其它目录下。
开始设置离线Yum源
|
|
然后输入以下内容
|
|
把我们上传的cloudera-repos-6.2.0里的所有内容copy 到/usr/share/nginx/html/cloudera-repos里,并运行以下命令,建立yum源
|
|
然后输入以下命令,进行Yum源的clean
|
|
必须在每一台大数据节点上设置Yum源。
设置mysql
cdh群有自己的群的元信息,为全元信息是记录在mysql中的,因此我们必须安装整套的mysql5.7.26+版本。
先查询centos是否自带了mariadb,如果有,一定记得卸掉。
|
|
假设我们看到这样的信息
mariadb-libs-5.5.52-1.el7.x86_64
然后我们使用下面命令来卸掉它
|
|
然后我们把mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar使用tar -xvf mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar解压。
解压后你会得到一堆的rpm,在解压目录下我们运行
|
|
安装时它会安装所有的mysql依赖,尤其是mysql-lib-python这些依赖包都是cdh在运行时依赖的。因此不要仅仅安装mysql-community-server这个东西,而是一定要安装mysql-bundle这个大包。
装完后:
|
|
然后我们修改/etc/my.cnf文件,把下面这一堆东东全部覆盖进去
|
|
然后请重启。
mysql5.7后默认在安装后会给一个默认的用户名、密码,我们可以通过以下命令取得这个默认密码:
|
|
然后我们使用
|
|
登录mysql,输入刚才grep显示出来的mysql密码,然后在mysql>命令提示行下输入以下命令
|
|
退出后重启mysqld服务。
然后再次用root和新密码登录,运行以下建表语句,这些新建的库和表就是给到大数据在安装时,其中有一步hive-metastore信息的安装用的。
|
|
因为是开发测试环境,特别这篇文章写过第一次动手安装cdh群的朋友们,因此我这边密码全部用的是111111,6个1,其实用户名和database名请一定不要更改。
导入GPG key(如果没有这步操作,很可能cloudera服务安装失败)manager节点
在我们的master即manager也是192.168.0.1节点上执行下面的语句:
|
|
或者我们在/home/appadmin/opt/cdh6.2.0的cloudera-repos下运行
|
|
安装CDH的Manager节点
在192.168.0.1节点上运行以下命令:
|
|
安装后它会在/opt目录下生成一个cloudera目录,所有的server,manager端内容就安装在这个目录下了
对/opt/cloudera目录进行赋权
先把我们上传的/home/appadmin/cdh6.2.0/parcel-6.2.0目录下的内容全部copy到/opt/cloudera/parcel-repos下,然后运行以下命令对parcel-repos目录下的CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel.sha生成.sha签名文件
|
|
然后再运行以下命令,对这些文件夹和内容进行赋权
|
|
正式安装前的初始化数据库中的数据
进入到/opt/cloudera/cm/schema下,运行
|
|
运行号console端会提示输入scm的密码,这个就是6个1了。
如果你的mysql不和CDH群的Master节点在一台机器上,那么请使用如下命令
|
|
看到successful后,我们可以使用以下命令启动cdh manager节点
|
|
然后我们观察启动日志,大数据是依赖于你的服务器性能的,性能好的话,一条命令下去,几秒种就启好了,我们的开发测试机,一般单节点少于64gb内存都需要启动一会,因此我们需要通过日志来观察是否启动顺利:
|
|
当看到了"started jetty“字样,代表我们的cdh server端的management服务启动完毕,此时,你就可以使用http://192.168.0.1:7180,然后默认用户名和密码为admin/admin来进行登录。
而此时,才真正开始cdh群的安装
CDH-6.2.0的正式安装


此步选择cloudera express来安装,express足以应对大都大中型企业的大数据应用了,根本不需要付钱,同时cdh也根本就是免费的,有人说不用cdh的话承认自己不会装也算了,还要加一条理由“cdh收费”,这边有看到收费吗?express我们都已经用了10几年了,用的比发明它的人都熟了,收费?哪天你听到java收费你不是去做快递了准备?

集群名随便,经验告诉你不要有下划线、空格、特殊字符就可以了。
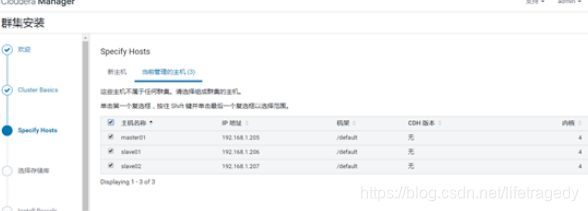
在这一步就是使用hostname填入所有的大数据主机节点即可。
如前文中所述,此处必须把每台机器的ip和hostname在/etc/hosts内做映射,之前我们使用cdh5.x时,如果dns里已经做了所有的服务器的hostname映射即可,但是cdh6.2.x一定要使用/etc/hosts绑定,这一点是官方列的,一定要小心,否则后面装完,页面会出现一堆的javascript错误,你自己都不知道该怎么办了。
接下去就很简单了,因此cdh的正式安装是基于网页的图形化向导,国际化做得一级棒,支持中文、在线帮助都很不错,因此后面都是图形化界面选选,然后下一步下一步就行了。
最后,给出万一把大数据装坏了,要重装,怎么把原来装的大数据彻底铲干净的全网唯一正确做法。
附录:如何干净的铲除大数据
在agent即一般节点上卸载大数据
运行以下命令
systemctl stop cloudera-scm-agent
yum install cloudera-manager-agent cloudera-manager-daemons
ps -ef |grep java如果还有任何java进程的话,直接kill -9了吧。
然后使用下面一堆命令
systemctl stop cloudera-scm-server
systemctl stop cloudera-scm-agent
yum erase cloudera-manager-agent cloudera-manager-daemons
yum erase cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server
rrm -rf /usr/share/cmf /var/lib/cloudera* /var/cache/yum/x86_64/6/cloudera* /var/log/cloudera* /var/run/cloudera*
rm -rf /etc/cloudera*
rpm -qa | grep cloudera
for f in `rpm -qa | grep cloudera ` ; do rpm -e ${f} ; done
rm -rf /var/run/hadoop* /var/run/flume-ng /var/run/cloudera* /var/run/oozie/ /var/run/sqoop2 /var/run/zookeeper /var/run/hbase /var/run/impala /var/run/hive /var/run/hdfs-sockets
rm -rf /usr/lib/hadoop /usr/lib/hadoop* /usr/lib/hive /usr/lib/hbase /usr/lib/oozie /usr/lib/sqoop* /usr/lib/zookeeper /usr/lib/bigtop* /usr/lib/flume-ng /usr/lib/hcatalog
rm -rf /usr/bin/hadoop* /usr/bin/zookeeper* /usr/bin/hbase* /usr/bin/hive* /usr/bin/hdfs /usr/bin/mapred /usr/bin/yarn /usr/bin/sqoop* /usr/bin/oozie
rm -rf /etc/alternatives/*
rm -rf /etc/hadoop* /etc/zookeeper* /etc/hive* /etc/hue /etc/impala /etc/sqoop* /etc/oozie /etc/hbase* /etc/hcatalog
rm -rf /var/lib/flume-ng /var/lib/hadoop* /var/lib/hue /var/lib/oozie /var/lib/solr /var/lib/sqoop*
rm /tmp/.scm_prepare_node.lock
rm -rf /opt/cloudera/parcel-cache /opt/cloudera/parcels
rpm --import RPM-GPG-KEY-cloudera在Server即Management节点上卸载大数据
systemctl stop cloudera-scm-server
yum erase cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server
ps -ef |grep java如果还有任何java进程的话,直接kill -9了吧。
然后使用下面一堆命令
rrm -rf /usr/share/cmf /var/lib/cloudera* /var/cache/yum/x86_64/6/cloudera* /var/log/cloudera* /var/run/cloudera*
rm -rf /etc/cloudera*
rpm -qa | grep cloudera
for f in `rpm -qa | grep cloudera ` ; do rpm -e ${f} ; done
rm -rf /var/run/hadoop* /var/run/flume-ng /var/run/cloudera* /var/run/oozie/ /var/run/sqoop2 /var/run/zookeeper /var/run/hbase /var/run/impala /var/run/hive /var/run/hdfs-sockets
rm -rf /usr/lib/hadoop /usr/lib/hadoop* /usr/lib/hive /usr/lib/hbase /usr/lib/oozie /usr/lib/sqoop* /usr/lib/zookeeper /usr/lib/bigtop* /usr/lib/flume-ng /usr/lib/hcatalog
rm -rf /usr/bin/hadoop* /usr/bin/zookeeper* /usr/bin/hbase* /usr/bin/hive* /usr/bin/hdfs /usr/bin/mapred /usr/bin/yarn /usr/bin/sqoop* /usr/bin/oozie
rm -rf /etc/alternatives/*
rm -rf /etc/hadoop* /etc/zookeeper* /etc/hive* /etc/hue /etc/impala /etc/sqoop* /etc/oozie /etc/hbase* /etc/hcatalog
rm -rf /var/lib/flume-ng /var/lib/hadoop* /var/lib/hue /var/lib/oozie /var/lib/solr /var/lib/sqoop*
rm /tmp/.scm_prepare_node.lock
rm -rf /opt/cloudera/parcel-cache /opt/cloudera/parcels
rpm --import RPM-GPG-KEY-cloudera