一、集合(对应数据库的表)
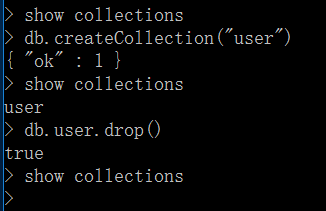
1、查看当前库里的所有集合
show collections
2、新建集合
显式创建
db.createCollection("user")
隐式创建
db.user.insert({name:"zhangsan"})
3、删除集合
db.user.dorp()
二、文档(对应数据库中的行)
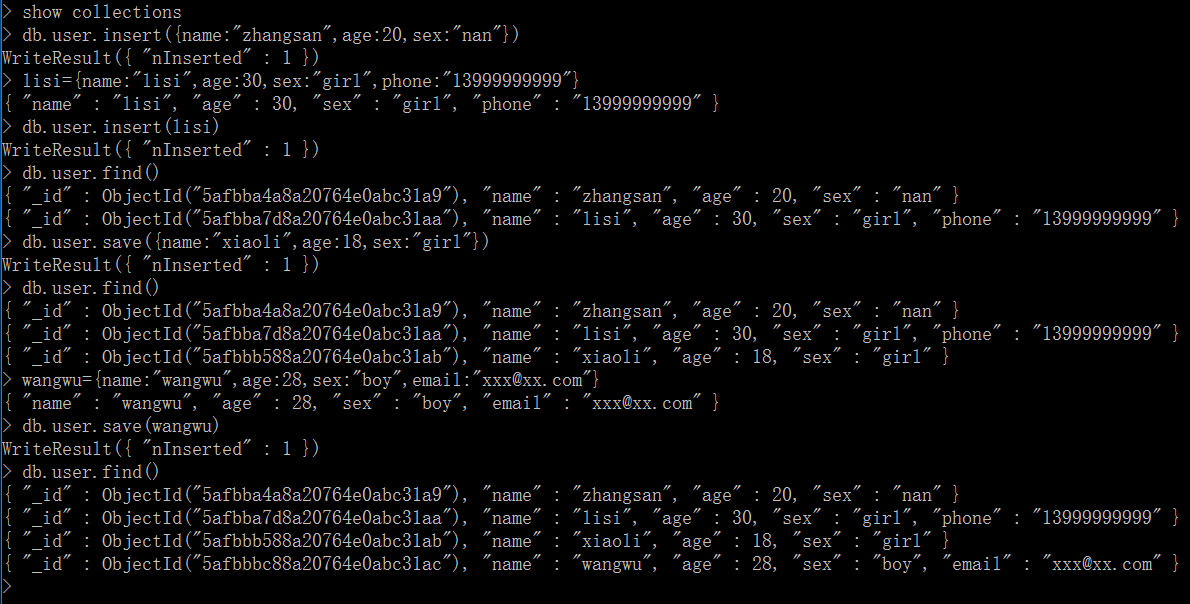
1、新增(insert、save、insertOne/insertMany)
1.1、使用insert方法新增
db.user.insert({name:"zhangsan",age:20,sex:"boy"})
或者先定义变量再保存变量
lisi={name:"lisi",age:30,sex:"girl",phone:"13999999999"}
db.user.insert(lisi)
1.2、使用save方法新增
db.user.save({name:"xiaoli",age:18,sex:"girl"})
或者先定义变量再保存变量
wangwu={name:"wangwu",age:28,sex:"boy",email:"xxx@xx.com"}
db.user.save(wangwu)
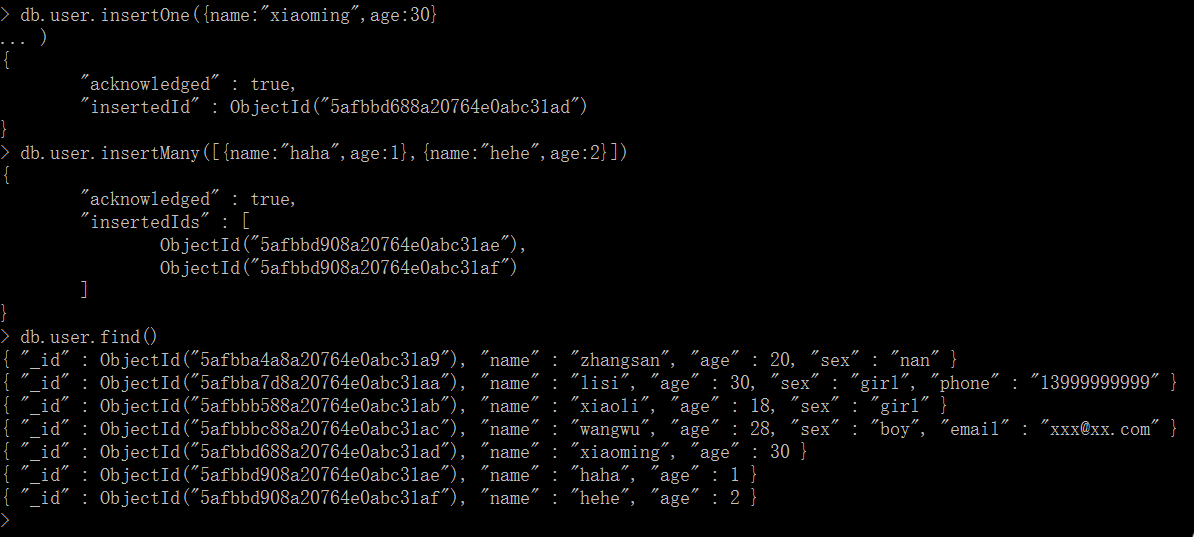
1.3、使用insertOne(单条插入,等同于insert)和insertMany(批量插入)
db.user.insertOne( obj, <optional params> ) - insert a document, optional parameters are: w, wtimeout, j db.user.insertMany( [objects], <optional params> ) - insert multiple documents, optional parameters are: w, wtimeout, j
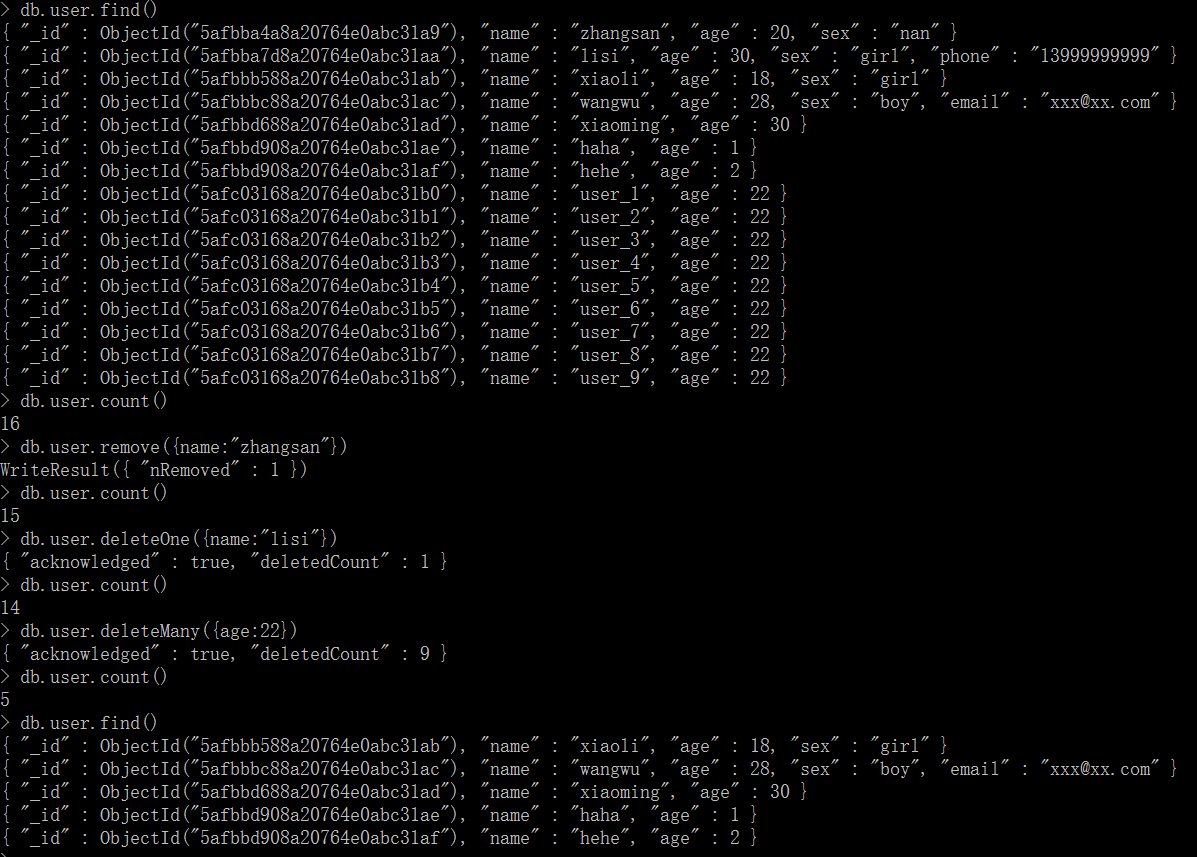
2、删
db.user.remove({name:"wangwu"})
db.user.deleteOne({name:"lisi"})
db.user.deleteMany({age:29})
3、改
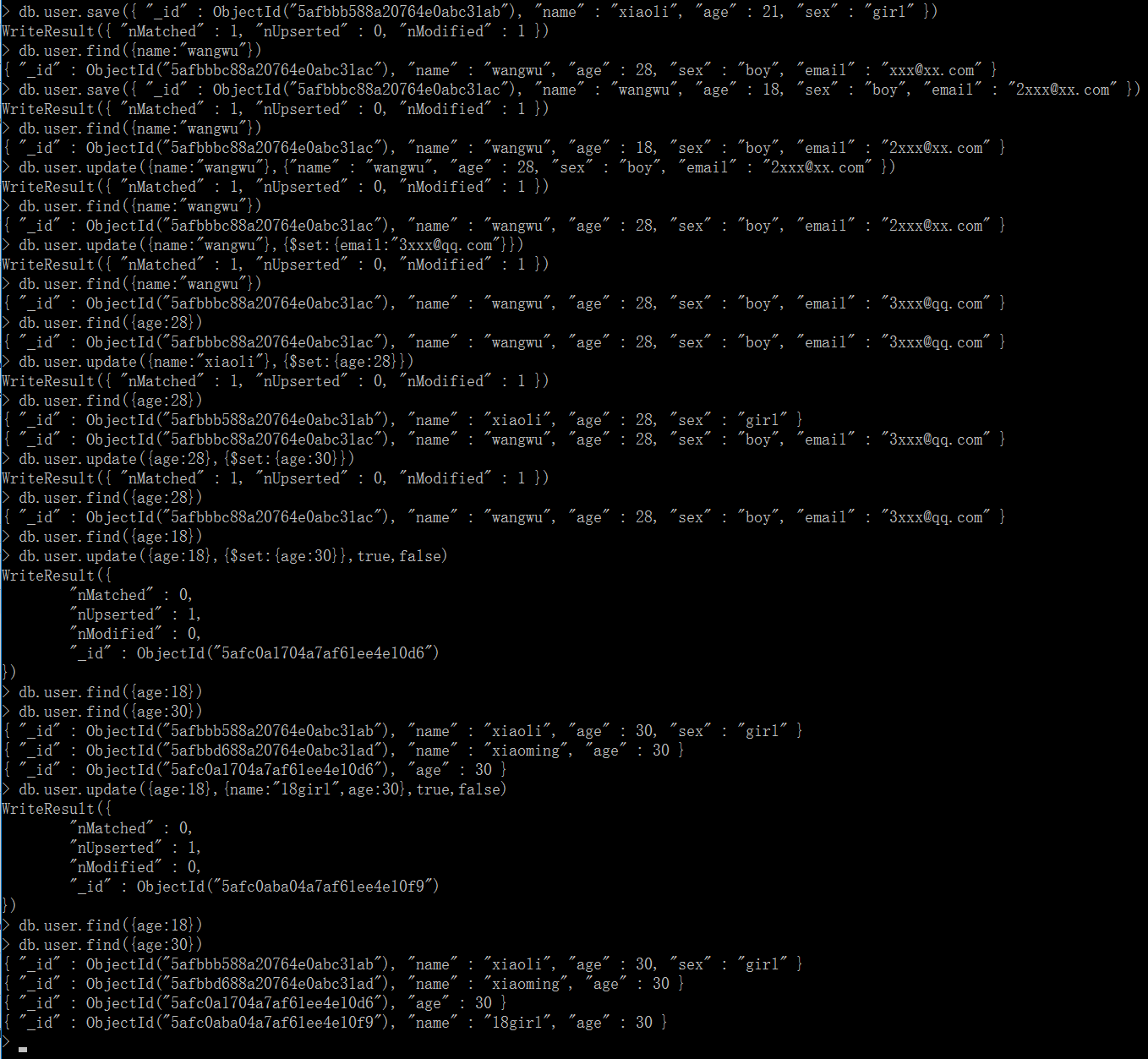
3.1、save方法
带id的save为更新(只更新一条)
db.user.save({ "_id" : ObjectId("5afbbbc88a20764e0abc31ac"), "name" : "wangwu", "age" : 18, "sex" : "boy", "email" : "2xxx@xx.com" })
3.2、update方法
db.user.update( query, object[, upsert_bool, multi_bool] )
upsert_bool:true表示如果没找到query相关的记录,则插入一条值为obj的记录
muliti_bool: true表示如果query查到多条,则全部更新下
其中局部修改器有2个:修改器: $inc 和 $set。
$set就是赋值的意思,$inc是自增的意思
带过滤条件的全量更新(只更新匹配的第一条)
db.user.update({name:"wangwu"},{"name" : "wangwu", "age" : 28, "sex" : "boy", "email" : "2xxx@xx.com" })
带过滤条件的更新某些字段(只更新匹配的第一条)
db.user.update({name:"wangwu"},{$set:{email:"3xxx@qq.com"}})
查询数据不存在,新增一条
db.user.update({age:18},{$set:{age:30}},true,false)
db.user.update({age:18},{name:"18girl",age:30},true,false)
根据muliti_bool参数的true和false不同,3.2版本开始引入了单条更新和多条更新的方法
db.user.updateOne( filter, update, <optional params> ) - update the first matching document, optional parameters are: upsert, w, wtimeout, j db.user.updateMany( filter, update, <optional params> ) - update all matching documents, optional parameters are: upsert, w, wtimeout, j
4、查
db.user.find([query],[fields]) - query is an optional query filter. fields is optional set of fields to return.
find方法如下很多子方法
find(<predicate>, <projection>) modifiers .sort({...}) .limit(<n>) .skip(<n>) .batchSize(<n>) - sets the number of docs to return per getMore .collation({...}) .hint({...}) .readConcern(<level>) .readPref(<mode>, <tagset>) .count(<applySkipLimit>) - total # of objects matching query. by default ignores skip,limit .size() - total # of objects cursor would return, honors skip,limit .explain(<verbosity>) - accepted verbosities are {'queryPlanner', 'executionStats', 'allPlansExecution'} .min({...}) .max({...}) .maxScan(<n>) .maxTimeMS(<n>) .comment(<comment>) .snapshot() .tailable(<isAwaitData>) .noCursorTimeout() .allowPartialResults() .returnKey() .showRecordId() - adds a $recordId field to each returned object Cursor methods .toArray() - iterates through docs and returns an array of the results .forEach(<func>) .map(<func>) .hasNext() .next() .close() .objsLeftInBatch() - returns count of docs left in current batch (when exhausted, a new getMore will be issued) .itcount() - iterates through documents and counts them .getQueryPlan() - get query plans associated with shape. To get more info on query plans, call getQueryPlan().help(). .pretty() - pretty print each document, possibly over multiple lines
db.user.findOne([query], [fields], [options], [readConcern]) db.user.findOneAndDelete( filter, <optional params> ) - delete first matching document, optional parameters are: projection, sort, maxTimeMS db.user.findOneAndReplace( filter, replacement, <optional params> ) - replace first matching document, optional parameters are: projection, sort, maxTimeMS, upsert, returnNewDocument db.user.findOneAndUpdate( filter, update, <optional params> ) - update first matching document, optional parameters are: projection, sort, maxTimeMS, upsert, returnNewDocument
由于查询比较复杂,特在后面的blog中详细说明