Spark上的深度学习框架再添新兵:Yahoo开源TensorFlowOnSpark
前言
\\2月13日,雅虎宣布开源TensorFlowOnSpark。TensorFlowOnSpark 为 Apache Hadoop 和 Apache Spark 集群带来可扩展的深度学习。 通过结合深入学习框架 TensorFlow 和大数据框架 Apache Spark 、Apache Hadoop 的显着特征,TensorFlowOnSpark 能够在 GPU 和 CPU 服务器集群上实现分布式深度学习。
\\Yahoo Big ML团队成员Lee Yang、Jun Shi、Bobbie Chern和Andy Feng日前合著了一篇文章,详细介绍了他们开源的TensorFlowOnSpark的方方面面。InfoQ翻译并整理本文。
\\正文
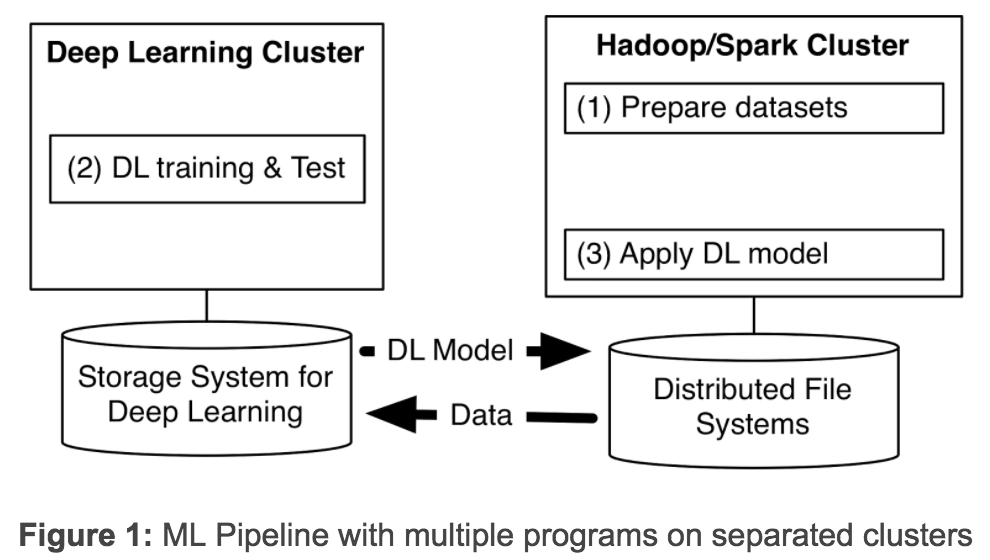
\\深度学习(DL)在最近几年快马加鞭地发展。在Yahoo,我们发现,为了从海量数据中获得洞察力,需要部署分布式深度学习。现有的DL框架通常需要为深度学习设置单独的集群,迫使我们为机器学习流程创建多个程序(见图1)。拥有独立的集群需要我们在它们之间传递大型数据集,从而引起不必要的系统复杂性和端到端的学习延迟。
\\
去年我们通过开发和发布CaffeOnSpark来解决scaleout问题,我们的开源框架,支持在相同的Spark和Hadoop集群进行分布式深度学习和大数据处理。我们在Yahoo使用CaffeOnSpark来改善我们的NSFW图像检测,比如自动从现场直播等自动识别电竞比赛等。借助社区的宝贵意见和贡献,CaffeOnSpark已经升级,支持LSTM,带有一个新的数据层,可用于训练和测试交错,还有一个Python API以及在Docker容器上的部署。对我们来说,这些极大提升了用户体验。但对于那些使用深层学习框架TensorFlow的用户怎么办呢 ?于是我们仿效之前的做法,开发了TensorFlowOnSpark。
\\在TensorFlow的首次发布后,谷歌在2016年4月发布了增强的TensorFlow与分布式深度学习功能。在2016年10月,TensorFlow宣布支持HDFS。然而,在Google云之外,用户仍然需要一个专用于TensorFlow应用程序的集群。TensorFlow程序不能部署在现有的大数据集群上,从而增加了那些希望大规模利用这种技术的成本和延迟。
\\为了打破这个限制,一些社区项目将TensorFlow连接到Spark集群。SparkNet在Spark执行器添加了运行TensorFlow网络的能力。DataBricks提出TensorFrame,用来使用TensorFlow程序操纵Apache Spark的DataFrames(数据帧)。虽然这些方法是在正确的方向迈出了一步,但我们检查其代码后,发现我们无法使多个TensorFlow进程直接相互通信,我们也无法实现异步分布式学习,我们还必须花费大量精力来迁移现有的TensorFlow程序。
\\TensorFlowOnSpark
\\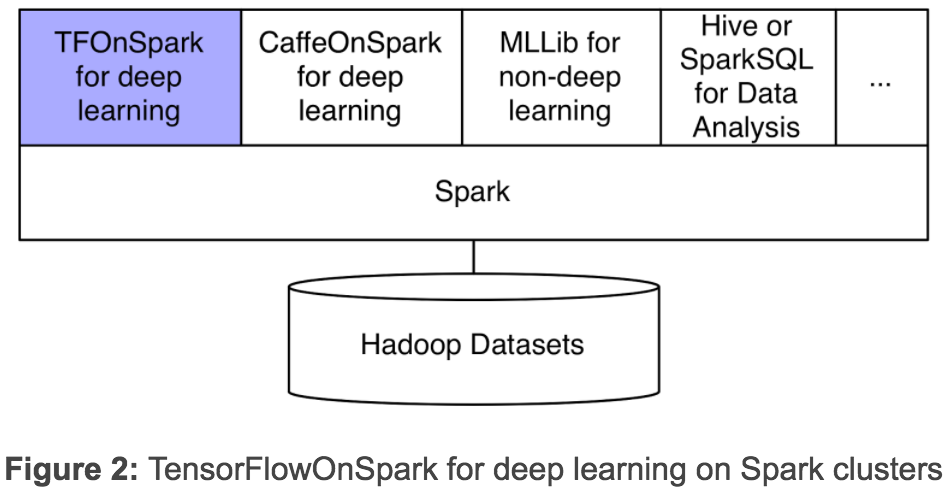
我们的新框架TensorFlowOnSpark(TFoS),支持TensorFlow在Spark和Hadoop集群上分布式执行。如上图2所示,TensorFlowOnSpark被设计为与SparkSQL、MLlib和其他Spark库一起在一个单独流水线或程序(如Python notebook)中运行。
\\TensorFlowOnSpark支持所有类型的TensorFlow程序,可以实现异步和同步的训练和推理。它支持模型并行性和数据的并行处理,以及TensorFlow工具(如Spark集群上的TensorBoard)。
\\任何TensorFlow程序都可以轻松地修改为在TensorFlowOnSpark上运行。通常情况下,需要改变的Python代码少于10行。许多Yahoo平台使用TensorFlow的开发人员很容易迁移TensorFlow程序,以便在TensorFlowOnSpark上执行。
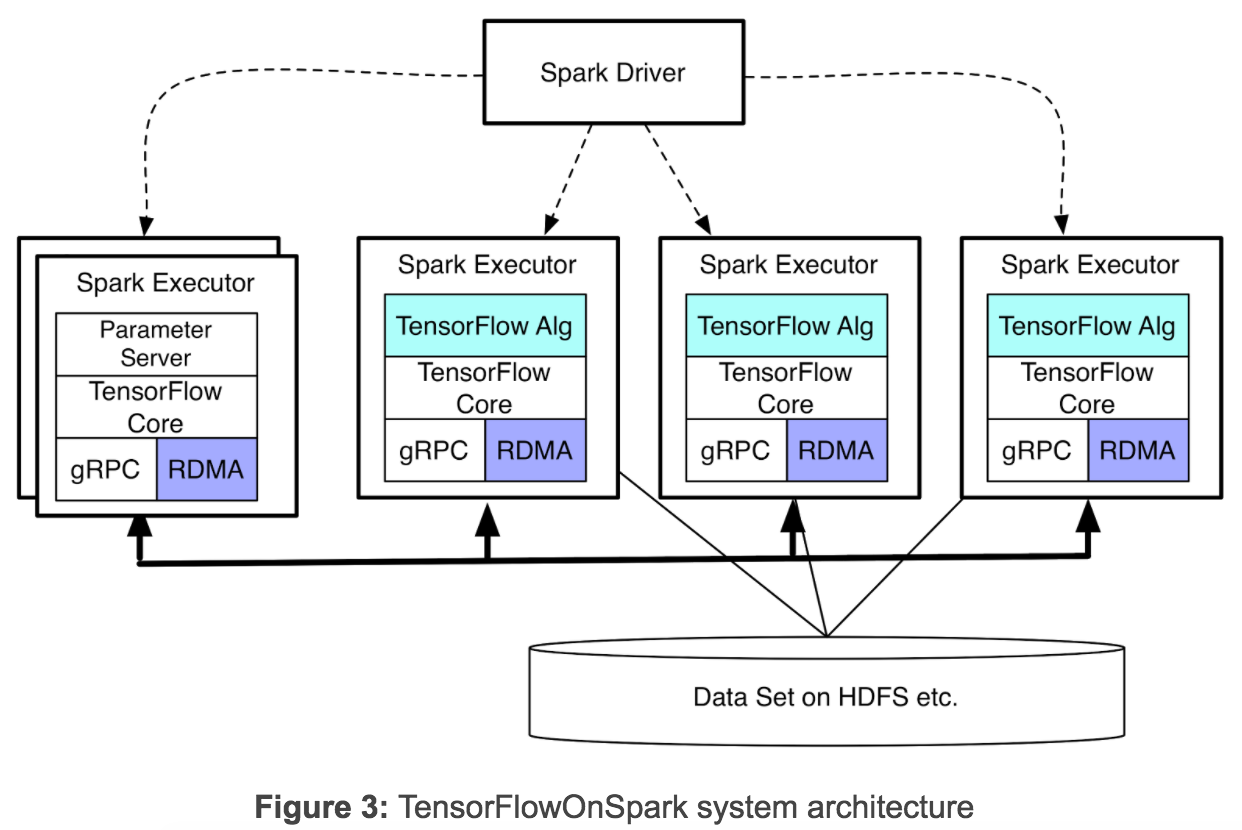
\\TensorFlowOnSpark支持TensorFlow进程(计算节点和参数服务节点)之间的直接张量通信。过程到过程的直接通信机制使TensorFlowOnSpark程序能够在增加的机器上很轻松的进行扩展。如图3所示,TensorFlowOnSpark不涉及张量通信中的Spark驱动程序,因此实现了与独立TensorFlow集群类似的可扩展性。
\\
TensorFlowOnSpark提供两种不同的模式来提取训练和推理数据:
\\- **TensorFlow QueueRunners:**TensorFlowOnSpark利用TensorFlow的file readers和QueueRunners直接从HDFS文件中读取数据。Spark不涉及访问数据。\\t
- Spark Feeding :Spark RDD数据被传输到每个Spark执行器里,随后的数据将通过feed_dict传入TensorFlow图。\
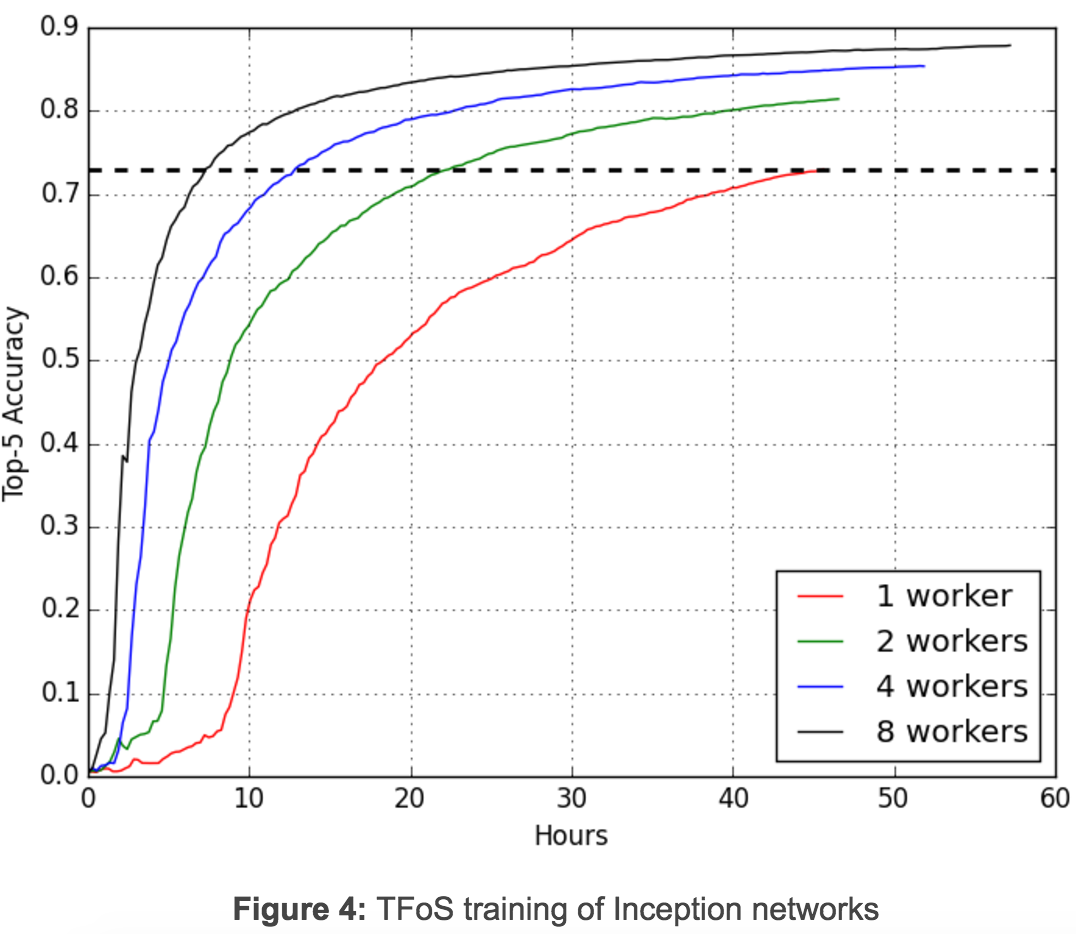
图4说明初始图像分类中同时进行的分布式训练如何使用TFoS中通过QueueRunners的一个简单设置进行扩展:每个节点一个GPU、一个读入以及批处理为32。四个TFoS工作同时进行,训练100,000步。两天后,当这些工作完成时,这些工作的前5个准确度分别为0.730、0.814、0.854和0.879。精确度达到0.730的单计算节点工作需要46小时,对于双计算节点则需要22.5小时,4计算节点需要13小时,8计算节点工需要7.5小时。TFoS因此实现了接近模型训练的近线性可扩展性。这是非常令人鼓舞的,虽然TFoS可扩展性会因不同的型号和超级数而有所不同。
\\
分布式TensorFlow的RDMA
\\在Yahoo的Hadoop集群上,GPU节点通过以太网和Infiniband连接。Infiniband提供更快的连接,并支持通过RDMA直接访问其他服务器的内存。然而,当前TensorFlow版本仅支持使用gRPC}通过以太网的分布式学习。为了加快分布式学习,我们增强了TensorFlow C ++层,以支持Infiniband上的RDMA。
\\为结合我们发布的TFoS,我们除了默认的“GRPC”协议外,还引入了新的TensorFlow服务器协议。任何分布式TensorFlow程序可以通过指定利用tf.train.ServerDef()或tf.train.Server()中的protocol=\"grpc_rdma\"来使用增强版的TensorFlow。
\\使用此新协议,就需要创建RDMA汇集管理器以确保张量直接写入远程服务器的内存。我们最小化张量缓冲区的创建:Tensor缓冲区在开始时分配一次,然后在一个TensorFlow作业的所有训练步骤中重复使用。从我们早期的实验与大型模型(如VGG-19网络)来看,业已证明,与现有GRPC相比,我们的TDMA实现在训练时间上显著加速了。
\\由于支持RDMA是一个高度要求的能力(见TensorFlow issue#2916),我们决定把现有的实现版本作为一个alpha版向TensorFlow社区开放。在接下来的几周内,我们将进一步优化RDMA实现,并分享一些详细的基准测试结果。
\\简单的CLI和API
\\TFoS程序由标准的Apache Spark命令spark-submit来启动。如下图所示,用户可以在CLI中指定Spark执行器的数目,每个执行器的GPU数量和参数服务器的数目。用户还可以指定是否要使用TensorBoard(-tensorboard)和/或RDMA(-rdma)。
\\\ spark-submit –master ${MASTER} \\ \ ${TFoS_HOME}/examples/slim/train_image_classifier.py \\ \ –model_name inception_v3 \\\ –train_dir hdfs://default/slim_train \\ \ –dataset_dir hdfs://default/data/imagenet \\\ –dataset_name imagenet \\\ –dataset_split_name train \\\ –cluster_size ${NUM_EXEC} \\\ –num_gpus ${NUM_GPU} \\\ –num_ps_tasks ${NUM_PS} \\\ –sync_replicas \\\ –replicas_to_aggregate ${NUM_WORKERS} \\\ –tensorboard \\\ –rdma \\\
TFoS提供了一个高层次的Python API(在我们示例Python notebook说明):
\\- TFCluster.reserve() … construct a TensorFlow cluster from Spark executors\\t
- TFCluster.start() … launch Tensorflow program on the executors\\t
- TFCluster.train() or TFCluster.inference() … feed RDD data to TensorFlow processes\\t
- TFCluster.shutdown() … shutdown Tensorflow execution on executors\
开放源码
\\TensorFlowOnSpark、TensorFlow的RDMA增强包、多个示例程序(包括MNIST,cifar10,创建以来,VGG)来说明TensorFlow方案TensorFlowOnSpark,并充分利用RDMA的简单转换过程。亚马逊机器映像也可对AWS EC2应用TensorFlowOnSpark。
\\感谢杜小芳对本文的审校。
\\给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。