官方参考 配置 地址 :http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
一、
在Hadoop-senior.zuoyan.com 的主机上
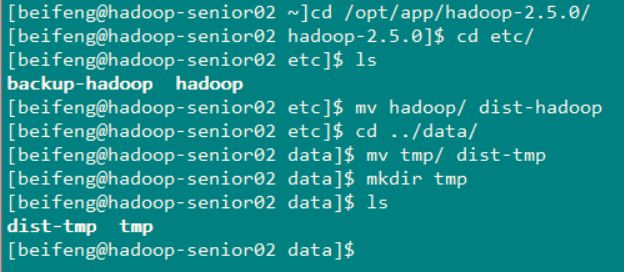
首先将Hadoop安装目录下 etc下的hadoop的配置文件进行备份 使用命令: cp -r hadoop dist-hadoop
然后在Hadoop安装目录下 data 文件夹内 将tmp 文件夹 重命名 使用命令 : mv tmp dits-tmp ,重命名完成后,在创建一个文件夹 mkdir tmp
然后在其余的 两台主机上也重复这个操作
将hadoop安装目录下的etc下的hadoop的所有配置文件复制文件为 dist-hadoop 然后再Hadoop的主安装目录中的data 下的 tmp 目录重命名为 dist-tmp 然后在创建新的数据存放目录
说明:图片中使用的命令有错误,不应该是重命名hadoop 而应该是重新复制文件,将复制文件的名字设置为 dist-hadoop
二、修改配置文件
打开core-site.xml 和 hdfs-site.xml 文件
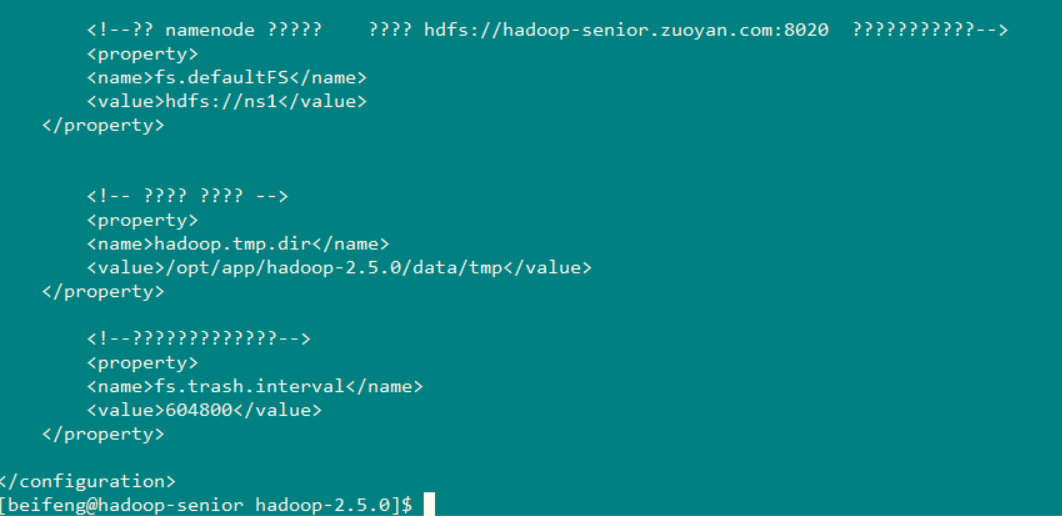
在core-site.xml 文件中配置
因为是NameNode 的高可用行,配制两台机器的NameNode ,需要修改这个,所以需要配置成集群

在hdfs-site.xml 配置文件中配制:
首先去除掉
<!--配置secondary namenode 所在的主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-senior03.zuoyan.com:50090</value>
</property>
在 /opt/app/hadoop2.5.0/data 目录下创建文件夹 dfs/jn 用来存放NameNode的 日志信息
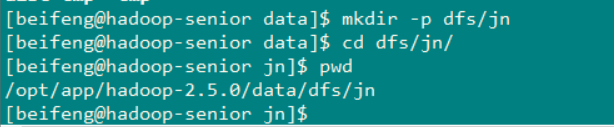
然后在从hdfs-site.xml 文件中配置
<!--配置Hadoop NameNode 的HA -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- NameNode RPC Adress -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop-senior.zuoyan.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop-senior02.zuoyan.com:8020</value>
</property>
<!-- 配置 WEB 界面的 访问地址和端口 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop-senior.zuoyan.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop-senior02.zuoyan.com:50070</value>
</property>
<!--配置 NameNode Shared EDITS Address 和NameNode 日志文件存放的位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-senior.zuoyan.com:8485;hadoop-senior02.zuoyan.com:8485;hadoop-senior03.zuoyan.com:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/app/hadoop-2.5.0/data/dfs/jn</value>
</property>
<!-- 配置 HDFS PROXY Client -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置两个 NameNode的隔离机制 -->
<!-- 使用的方式是 ssh-fence 要求是两个NameNode 之间能够无密码登录 两个主机之间能互相ssh无密钥登录 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/beifeng/.ssh/id_rsa</value>
</property>
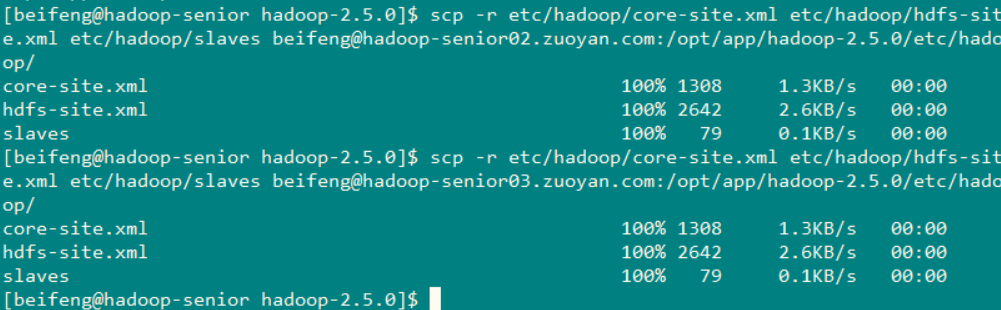
配置好 主机一(hadoop-senior.zuoyan.com) 需要将配置文件进行同步
使用命令 scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml etc/hadoop/slaves beifeng@hadoop-senior02.zuoyan.com:/opt/app/hadoop-2.5.0/etc/hadoop/
开始启动QJM HA:
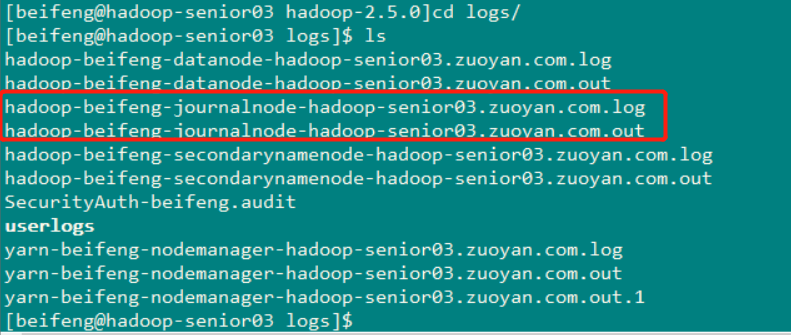
完成后,分别启动三个节点的journalnode 使用命令: sbin/hadoop-daemon.sh start journalnode 每个节点启动后 使用jps查看一下进程,看任务是否启动

可以查看一下启动日志(这个步骤不是必须要做的 可以看见journalnode 的启动日志):
在NameNode1节点上 对文件系统进行格式化,产生fsimage 文件 使用命令 : bin/hdfs namenode -format 然后再启动NameNode
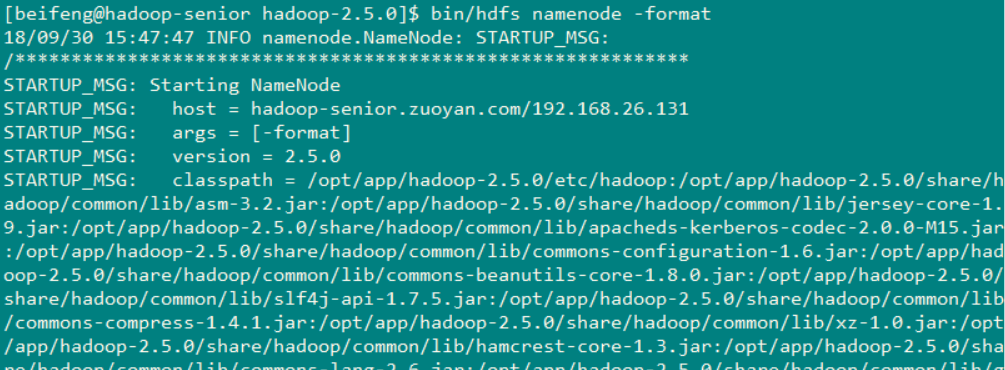

在NameNode1 上启动namenode 使用命令 : bin/hadoop-daemon.sh start namenode
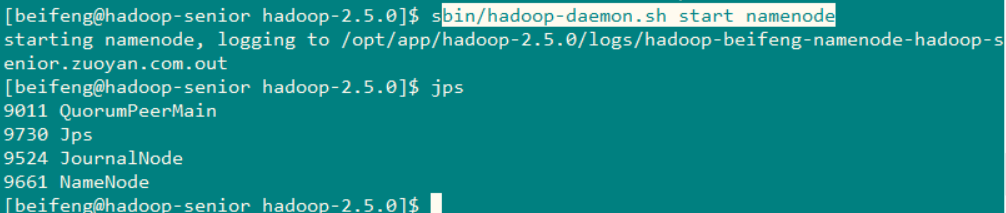
之后在NameNode2 上同步NameNode1 的元数据信息
使用命令:bin/hdfs namenode -bootstrapStandby

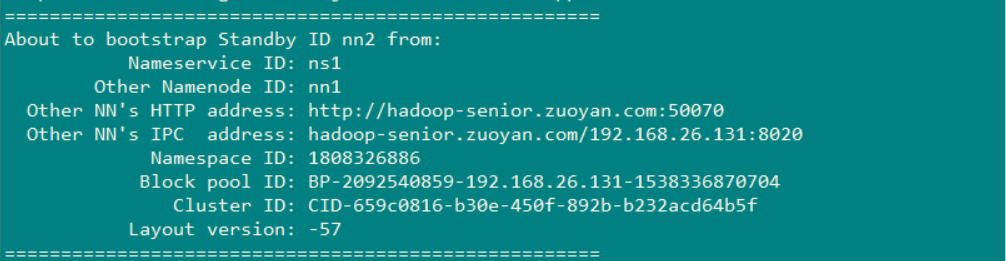
可以看到复制镜像文件是从Hadoop-senior.zuoyan.com 上拷贝

然后启动NameNode2 使用命令: sbin/hadoop-daemon.sh start namenode
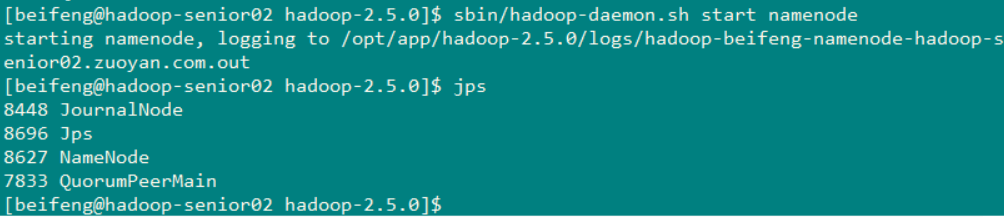
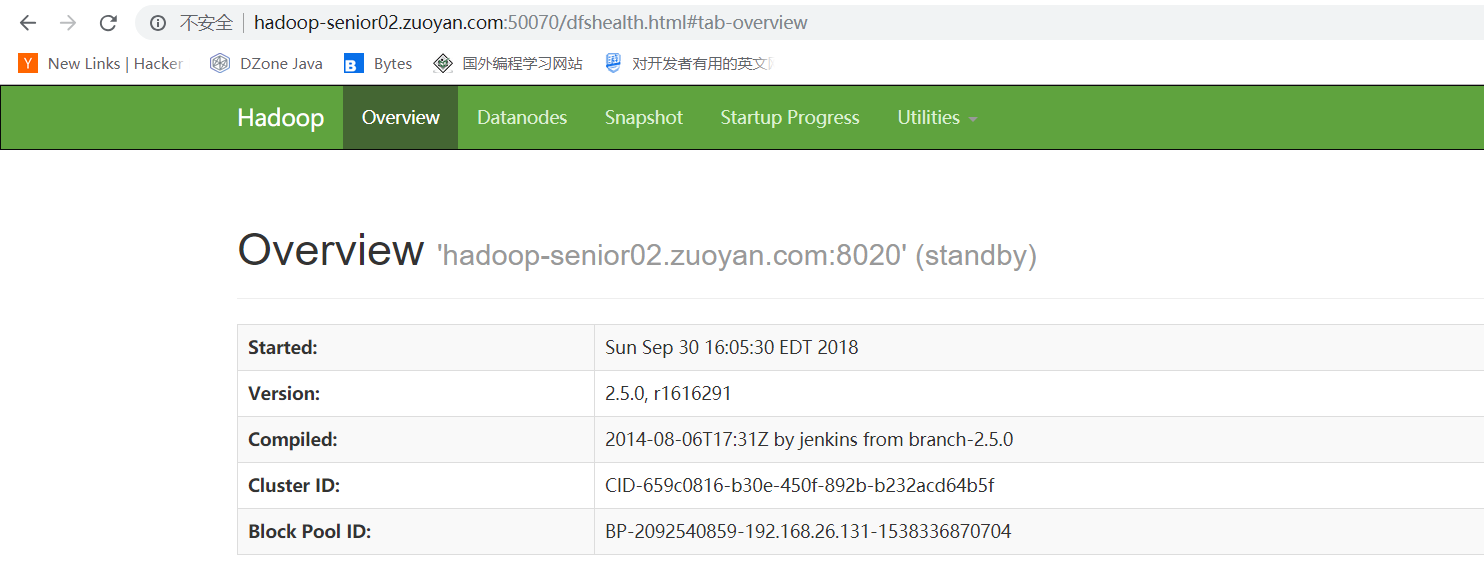
然后分别访问这两个主机的50070 发现如果可以访问 就初步配置成功

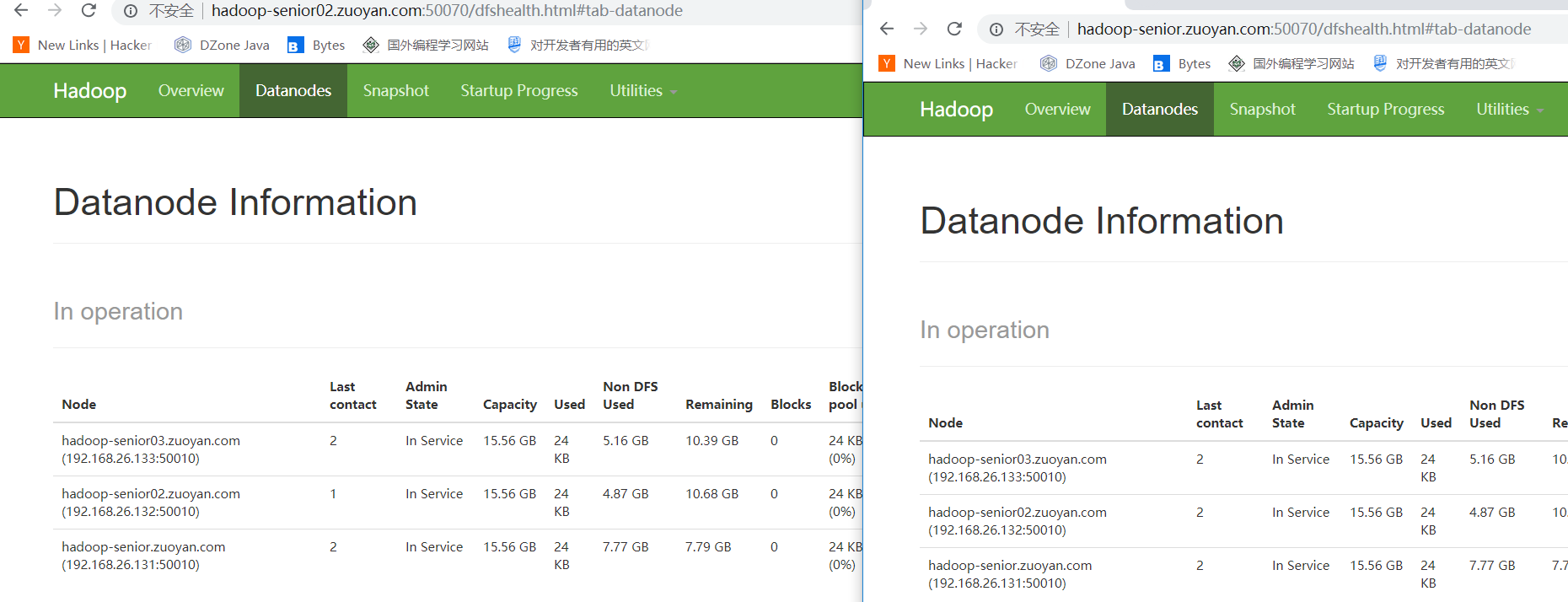
然后启动所有机器上的DataNode 使用命令:sbin/start-dfs.sh (也可以使用命令 一个个启动 sbin/hadoop-daemon.sh start datanode 我这里省事,就所有机器的都启动)
打开WEB界面 发现两个NameNode 都可以进行管理 这样就是配置成功!!!
使用命令将第一个节点改变为活跃状态,使用命令: bin/hdfs haadmin -transitionToActive nn1
(可以看到这个NameNode 节点 已经改变为活跃状态)

也可以通过命令 来查看节点的状态 (可以看到这两个主机 一个是active 一个是 standby)

现在查看一下 HDFS文件系统上的文件 来进行测试NameNode
(下面没有打印出文件 这个上面说没有找到ns1 这个原因技就是我们在配置Proxy的时候 没有改变myclsur)

下面这个内容配置错误的原因,我现在已经更改过来了

更改完成后,在执行一下 (就可以看见文件目录已经循环出来了)

使用命令创建文件目录

将文件上传到文件系统上

通过文件管理的web界面进行查看 (就会发现文件已经上传成功)

然后 在测试HA的读取功能 使用命令: bin/hdfs dfs -text /user/zuoyan/conf/core-site.xml
文件已经成功 正常的被读取出来了

然后通过命令 将 nn1 切换称 standby 将nn2 切换成 active
将节点切换成Standby的命令 :bin/hdfs haadmin -transitionToStandby nn1
将节点切换成Active 的命令 : bin/hdfs haadmin -transitionToActive nn2

切换之后在用NameNode 1 去读取HDFS上的文件 测试 是否能正常读取文件
(切换之后已经正常的读取出来了,证明节点切换 对集群是没有影响的)
完成到这样 HDFS的高可用 已经初步搭建好了