mysql 蘑菇查询_sql语句 基本
1、sql不区分大小写,一般结尾要加分号;
2、select 列,列,列 from 表
3、distinct ,返回列中不同的值。需要哪个列不同,关键词哪个列
4、where子句,select 列 from 表 where 列 运算符 值
= <>(!=) > = <= between like
条件值(非数字)用单引号环绕(有的双引号也可以)
5、AND OR,连接where子句
6、order by,对结果集进行排序,默认升序。desc倒序。排序条件可累加,先执行第一条,在第一条的基础上执行第二条。
ORDER BY Company DESC, OrderNumber ASC
7、top子句,要返回结果数。select top 2(top 50 percent)* from xxx。有的数据库系统不支持,如mysql,在尾部用limit
8、like 操作符,在where子句中使用,模糊匹配
LIKE "1%",匹配以1开头的
"%g" 匹配以g结尾的
not like "%g"
9、和like搭配在一起的,就是通配符,%代替1个or多个,_代替一个,([ ]弄成一个集合,弄成一个不想匹配的集合[^ ])-->mysql不支持
10、in 操作符,在where子句中使用,
WHERE column_name IN (value1,value2,...)
11、between操作符,在where子句中使用,取值范围(数值,文本,日期)。not between
BETWEEN 'AAAAAAAAAA' AND 'oJrlVsHBS6'。mysql出来的结果是包含边界值的
12、as ,给表or列重命名。表重命名用于列和where子句中,列重命名用于结果集的列名
13、join,根据2个or多个表列之间的关系,从这些表中查询数据 on
INNER JOIN: 如果表中有至少一个匹配,则返回行
LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
FULL JOIN: 只要其中一个表中存在匹配,就返回行
SELECT c_item.`id`,c_item.`user_id`,c_item.`serial`,c_user_account_log.`user_id`,c_user_account_log.`status`,c_user.`key`FROM (c_item INNER JOIN c_user_account_log ON c_item.`user_id`=c_user_account_log.`user_id`)LEFT JOIN c_user ON c_user.id=c_item.`user_id`;
where 放在join后面 group by 放在最后面
14、union操作符,合并两个或多个 SELECT 语句的结果集,默认去重,不去重union all
要有相似的数据类型
15、select into,创建表的复制备份
16、create db create table
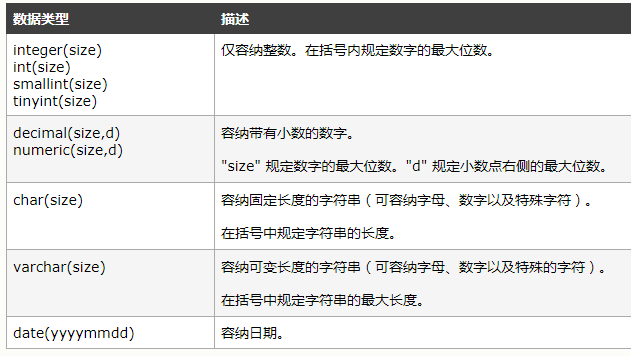
char的长度是不可变的,而varchar的长度是可变的,也就是说,定义一个char[10]和varchar[10],如果存进去的是‘csdn’,那么char所占的长度依然为10,除了字符‘csdn’外,后面跟六个空格,而varchar就立马把长度变为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的,尽管如此,char的存取数度还是要比varchar要快得多,因为其长度固定,方便程序的存储与查找;但是char也为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可谓是以空间换取时间效率,而varchar是以空间效率为首位的。再者,char的存储方式是,对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节;而varchar的存储方式是,对每个英文字符占用2个字节,汉字也占用2个字节,两者的存储数据都非unicode的字符数据。
17、约束,constraints。限制加入表的数据的类型
NOT NULL
UNIQUE
PRIMARY KEY
FOREIGN KEY
CHECK
DEFAULT
primary key与unique key都是唯一性约束。二者区别: 1.作为primary key的1个或多个列必须为NOT NULL(有的数据库需要明确指明,有的会自动设置为NOT NULL) 而unique key约束的列可以为null,这是primary key与unique key最大的区别。
2.一个表只能有一个primary key(单列或多列,多列主键叫联合主键),但可以有多个unique key。
每个表都应该有一个主键,并且每个表只能有一个主键。
一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY
FOREIGN KEY (Id_P) REFERENCES Persons(Id_P)
18、CREATE INDEX 语句
用于在表中创建索引。 在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
19、drop 删除索引 表 数据库
20、alter 添加修改删除列
21、AUTO_INCREMENT,创建表时定义的自增
22、mysql中key 、primary key 、unique key 与index区别
参考文章:http://blog.csdn.net/nanamasuda/article/details/52543177

23、null和0不一样,用is null is not null操作符
SQL函数
Aggregate 合计函数
Scalar 函数
1、AVG(列)
SELECT Customer FROM Orders WHERE OrderPrice>(SELECT AVG(OrderPrice) FROM Orders)
2、COUNT(列) 函数返回匹配指定条件的行数。
3、FIRST(列) 函数返回指定的字段中第一个记录的值。
4、LAST(列) 函数返回指定的字段中最后一个记录的值。
5、MAX MIN函数返回一列中的最大值。NULL 值不包括在计算中。
6、SUM 函数返回数值列的总数(总额)。仅对数值型,对别的型会报错。
7、合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句。GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组
8、在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
基本心得:
SELECT c_item.id,c_item.user_id,COUNT(c_item.user_id),c_user.`key` FROM c_item LEFT JOIN c_user ON c_item.`user_id`=c_user.`id` GROUP BY c_item.user_id;
group by放在left join后面
SELECT COUNT(c_item.user_id),c_user.`key` FROM c_item LEFT JOIN c_user ON c_item.`user_id`=c_user.`id` WHERE c_item.`user_id`=21;
where 放在left join后面
SELECT c_item.`id`,c_item.`user_id`,c_item.`serial`,c_user_account_log.`user_id`,c_user_account_log.`status`,c_user.`key`FROM (c_item INNER JOIN c_user_account_log ON c_item.`user_id`=c_user_account_log.`user_id`)LEFT JOIN c_user ON c_user.id=c_item.`user_id`;
join可嵌套,在from之后打括号,再join别的表
SELECT id,MAX(item_id) FROM c_user_account_log WHERE user_id=21 AND STATUS=1;
where可以和非合计函数一起使用
SELECT COUNT(c_item.user_id),c_user.`key` FROM c_item LEFT JOIN c_user ON c_item.`user_id`=c_user.`id` WHERE c_item.`user_id`=21;
SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用
SELECT Customer,SUM(OrderPrice) FROM Orders
WHERE Customer='Bush' OR Customer='Adams'
GROUP BY Customer
HAVING SUM(OrderPrice)>1500
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value
where group by having