多选框位置调整_水下目标检测竞赛冠军方案:多图像融合增强 | URPC 2019

本文授权转载自:AI科技评论
作者 | Bbuf 编辑 | 杨晓凡
下面要介绍的论文发于2019年12月,题为「ROIMIX: PROPOSAL-FUSION AMONG MULTIPLE IMAGESFOR UNDERWATER OBJECT DETECTION」。

axriv地址为:https://arxiv.org/abs/1911.03029
近年来,通用的目标检测算法已经证明了其卓越的性能。然而,关于水下目标检测的话题却很少被研究。和一般的数据集相比,水下图像通常具有色偏和低对比度的特点,并且沉淀物也会导致水下图像模糊。另外,由于水下动物的生活习性,它们通常在图像上挨得很近。为了解决这些问题,本论文的工作是研究增强策略以模拟重叠,遮挡和模糊的目标,并构建一个可以有更好的泛化能力的模型。论文提出了一种称为ROIMIX的增强方法,该方法可以表征图像之间的相互作用。之前的图像增强方法都是在单张图像上运行,而ROIMIX是应用于多个图像以创建增强后的训练样本数据。实验结果表明,此方法在PASCAL VOC数据集和URPC数据集上均提高了双阶段目标检测器的性能。
研究背景
很多目标检测器在通用数据集如PACCAL VOC,MSCOCO上实现了比较好的性能。然而,水下环境更加复杂并且由于光照影响导致水下图像往往存在对比度低,纹理失真和光照不均匀的特点,这导致检测更加困难。
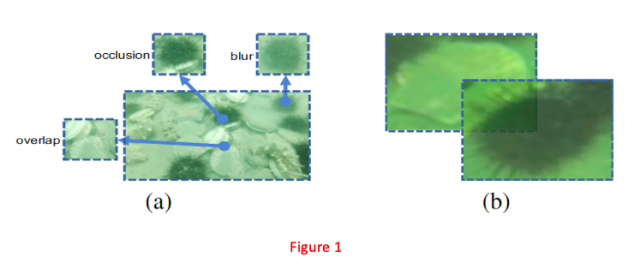
Figure1(a)展示了密集分布的生物,它们彼此覆盖,并且因为一些沉淀物变得模糊。水下机器人检测比赛(URPC)提供了有挑战性的水下目标检测数据集,该数据集包含大量重叠,遮挡和模糊的水下生物。现有的数据增强方法对重叠,遮挡和模糊目标还没有进行很好的研究。如果检测模型仅仅适应训练数据,它将缺乏泛化能力,无法应对复杂的水下环境。
因此,论文提出通过在多个图像之间混合候选区域来模拟目标的重叠,遮挡和模糊。从理论上分析,遵循经验风险最小化原则(ERM),深度模型致力于最小化训练数据上的平均误差,但是它们有过拟合的风险。具体来说,ERM指导深层模型记忆训练数据,而不是从中概况。同时,这些模型容易受到对抗样本的攻击。数据增强被用来缓解过拟合问题,根据最小风险(VRM)原则,通过增强策略在类似于训练数据的样本上对模型进行了优化。在图像分类领域,平移和翻转是增强训练数据量的常用策略。
诸如Mixup,CutMix之类的方法致力于创造更好的训练数据。本文提出了一种称为RoIMix的数据增强算法,可以提高模型对重叠,遮挡和模糊目标的检测能力。这个方法被用于双阶段检测器如Faster-RCNN上,和之前在单个物体上进行数据增强的方法相比,ROIMIX更注重图像之间的交互。直接在目标检测中应用像Mixup这样的图像级融合会导致来自不同图像的区域建议框未对齐,如Figure1(b)所示。
为了准确模拟重叠,遮挡和模糊的情况,论文执行了候选框级别融合。用这种方式,此方法在Pascal VOC和URPC上取得了出色的目标检测性能,并在URPC 2019水下目标检测竞赛上夺冠。
相关工作
数据增强
数据增强是训练深度学习模型的关键策略。 在图像分类领域,常用的数据增强策略包括旋转,平移或翻转。 Zhang等提出将两个随机训练图像混合以产生邻近训练数据,作为一种正则化方法。 区域删除方法如Cutout会从输入中随机删除一个区域,这有助于模型关注目标最有区别的部分,但是这也可能会导致信息丢失。 此外,更加先进的CutMix在训练数据集之间剪切和粘贴图片区域,从而极大的提高了模型对抗输入破坏的鲁棒性。 对于目标检测,通常使用多种增强策略如光照扰动,图像镜像和多尺度训练。除此之外,基于CutMix的预训练模型可以在Pascal VOC上实现性能提升,但它并不是专门为目标检测器设计的。本文充分考虑了基于区域定位的目标检测器的特性,并提出了一种新的数据增强方法。
Faster-RCNN及其变体
Faster-RCNN是双阶段目标检测器发展史上的里程碑。它由三个模块组成:一个负责提取特征的骨干网络如AlexNet,VGG,ResNet和RPN等,一个在特征图上生成候选框集合的全卷积网络,一个对候选框区域进行分类回归的网络。
注意,在区域分类和位置回归步骤中是没有共享计算的。而R-FCN提取了空间感知的区域特征,并在分类回归阶段移除了全连接层来共享计算而不会降低性能。Faster-RCNN的另外一个问题是它使用最后一层特征图进行检测,对小目标的检测能力比较差。
因此Lin等提出了特征金字塔网络FPN,它结合了低层特征可以更好的最小目标做预测。本文的方法具有通用性,可以应用于各种双阶段目标检测器。
方法
如Figure2所示,本文提出的方法在RPN和ROI分类器之间应用。使用RPN产生ROI,并以随机的比例混合它们。该比例是根据Beta分布产生的,然后,使用混合样本来训练模型。下面开始详细的描述ROIMIX算法并讨论其背后的原理。
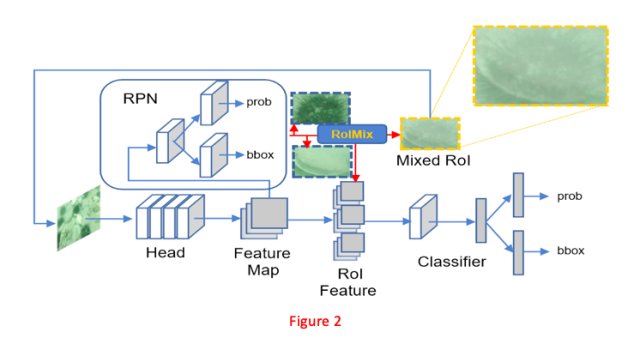
算法
让  x\in R^{H\times W \times C} 和
x\in R^{H\times W \times C} 和  y 代表一个候选框和它的标签。ROIMIX旨在混合两个从多个图像中产生的随机
y 代表一个候选框和它的标签。ROIMIX旨在混合两个从多个图像中产生的随机  RIO(x_i,y_i) 和
RIO(x_i,y_i) 和  (x_i,y_i) 来产生新的候选框
(x_i,y_i) 来产生新的候选框  (\tilde{x}, \tilde{y}) ,ROIs的大小通常不同,所以我们需要将
(\tilde{x}, \tilde{y}) ,ROIs的大小通常不同,所以我们需要将  x_j 缩放到和
x_j 缩放到和  x_{i \cdot} 大小完全一致。产生的训练数据(\tilde{x}, \tilde{y})被用来直接训练检测模型。混合操作的公式定义如下:
x_{i \cdot} 大小完全一致。产生的训练数据(\tilde{x}, \tilde{y})被用来直接训练检测模型。混合操作的公式定义如下:
 \tilde{x} = \lambda' x_i + (1 - \lambda ') x_i, ~~~~\tilde{y} =y_i
\tilde{x} = \lambda' x_i + (1 - \lambda ') x_i, ~~~~\tilde{y} =y_i
其中  \lambda' 是两个候选框的混合系数。不像Mixup算法那样直接从一个参数为
\lambda' 是两个候选框的混合系数。不像Mixup算法那样直接从一个参数为  \alpha 的Beta分布
\alpha 的Beta分布  B
B
中直接采样  \lambda ,
\lambda ,
 \lambda = B(a,a)
\lambda = B(a,a)
这里给第一个ROI区域  x_i 选择较大系数,即:
x_i 选择较大系数,即:
 \lambda' = \max{(\lambda, 1- \lambda)}
\lambda' = \max{(\lambda, 1- \lambda)}
其中,max代表返回两个参数中的较大者。原因是我们要使用  y_i 当作混合ROI的标签。本方法混合了没有没有标签的ROIs,这类似于传统的数据增强方法。它仅仅影响训练,并在测试过程中保持模型不变。使用这种方法,就可以获得模拟重叠的,遮挡的和模糊的目标的新ROIs。Figure3可视化出了这个方法的过程。
y_i 当作混合ROI的标签。本方法混合了没有没有标签的ROIs,这类似于传统的数据增强方法。它仅仅影响训练,并在测试过程中保持模型不变。使用这种方法,就可以获得模拟重叠的,遮挡的和模糊的目标的新ROIs。Figure3可视化出了这个方法的过程。
最终,使用此方法得到的新ROIs代替了原始的区域建议框。最终通过最小化这些生成样本的原始损失函数来进行训练。代码级别的信息在Algorithm1中展示。

Figure3中x1,x2表示了两个分别包含扇贝和海胆的ROI,而  x_3 表示从训练数据集中截出的有遮挡的样本(海胆位于扇贝上),通过ROIMIX,x1和x2被混合为和 x_3 类似的
x_3 表示从训练数据集中截出的有遮挡的样本(海胆位于扇贝上),通过ROIMIX,x1和x2被混合为和 x_3 类似的  \tilde{x} ,用于模拟遮挡和模糊的情况。
\tilde{x} ,用于模拟遮挡和模糊的情况。
讨论
论文通过ROIMIX来模拟目标的重叠,遮挡,以帮助模型隐式的学习更好的密集目标检测能力。从统计学习理论的角度来看,ROIMIX是两个候选框之间的一个线性插值结果,决策边界可能会变得更平滑而不会急剧过度。具体来说,ROIMIX遵循VRM原理而不是ERM原理,从而使得深度学习模型泛化能力更强。遵循ERM原理训练得模型可以最大程度的减少经验风险,以帮助模型更好的拟合训练数据。定义经验风险  R_{\delta} 为:
R_{\delta} 为:
 R_{\delta}(f) = \frac{1}{n} \sum_{i=1}^{n} l(f(x_i), y_i)
R_{\delta}(f) = \frac{1}{n} \sum_{i=1}^{n} l(f(x_i), y_i)
其中  f 代表将
f 代表将  x 映射到 y 的非线性函数,
x 映射到 y 的非线性函数,  n 代表样本数,
n 代表样本数,  l 代表损失函数用来衡量 x_i 和 y_i
l 代表损失函数用来衡量 x_i 和 y_i
的距离。ROIMIX遵循VRM规则,并生成训练数据的邻近分布。然后就可以用生成的数据 (\tilde{x},\tilde{y}) 来代替原始的训练数据 (x_i,y_i) ,并将期望风险  R_v 近似为:
R_v 近似为:
 R_v(f) = \frac{1}{n} \sum_{i=1}^{n} l(f(\tilde{x}),\tilde{y})
R_v(f) = \frac{1}{n} \sum_{i=1}^{n} l(f(\tilde{x}),\tilde{y})
因此训练过程已经变成最大幅度的减少期望风险 R_v 。在每一个轮次中,ROIMIX都会生成不同的邻近训练数据。以这种方式,模型的鲁棒性变得更高。

实验
在URPC 2018上的实验结果
论文在URPC 2018上对这个方法进行了全面的评估。该数据集包含2901张训练图像和800张测试图像,涵盖4个目标类别,包括海参,海胆,扇贝和海星。
论文选择在ImageNet上预训练的ResNet-101作为骨干网络,并从每张图像中提取128个ROI特征。并对Faster-RCNN使用默认的超参数,评估方法使用平均精度(mAP)。在URPC 2018的实验中,将Beta分布的超参数a设置为0.1。
 实验结果如Table1所示,从表中可以看到Max操作分别带来了2.06%和1.8%的Map值提升,这说明了等式(3)的重要性。其次,在比较GT框和ROIs混合的效果时发现,混合ROIs比混合GT对性能的改善贡献更大。此外,论文还评估了图像之间进行交互的重要性。“SingleRoIMix”指的是在单个图像上选择和混合ROIs,而论文提出的方法是混合一个批次中多张图像的ROIs。Table1中的第2行和第5行显示,和单个图像混合相比,在多个图像之间混合ROIs可以提升0.41%Map值。
实验结果如Table1所示,从表中可以看到Max操作分别带来了2.06%和1.8%的Map值提升,这说明了等式(3)的重要性。其次,在比较GT框和ROIs混合的效果时发现,混合ROIs比混合GT对性能的改善贡献更大。此外,论文还评估了图像之间进行交互的重要性。“SingleRoIMix”指的是在单个图像上选择和混合ROIs,而论文提出的方法是混合一个批次中多张图像的ROIs。Table1中的第2行和第5行显示,和单个图像混合相比,在多个图像之间混合ROIs可以提升0.41%Map值。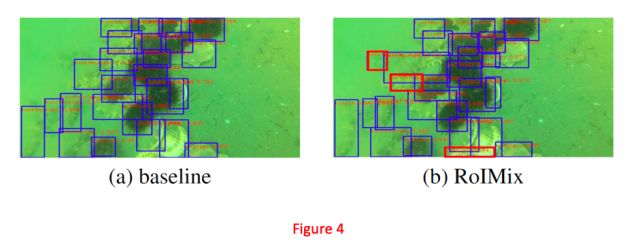
Figure4可视化了Baseline(Faster-RCNN)和本论文提出的方法的检测结果。在Figure4(b)中标记了3个红色框,其中两个是模糊和重叠的海参,另一个是不完整的扇贝。BaseLine模型无法检测到三个红色框中的目标,而论文中的方法可以成功检测。这说明此方法对模糊,重叠的目标有更好的检测能力。
在PASCAL VOC上的实验
论文还在PASCAL VOC数据集(07+12)上评估了此方法的表现。该模型在VOC 2007 Trainval和VOC 2012 Trainval的联合训练集上进行了训练,并在VOC 2007的测试集上进行测试。这个实验使用和4.1节完全一样的设置,并根据经验将Beta分布的超参数a设为0.01。
论文指出,这应该是第一份有关混合样本数据增强目标检测的报告。并将此方法的实验结果和Faster-RCNN作比较来评估ROIMIX的性能。结果如Table2所示。
 可以看到,这种方法比BaseLine提高了0.8%个Map值,同时也可以看到ROIMIX在VOC上的提升比URPC上的提升少。一个可能的原因是URPC中存在更多重叠,被遮挡和模糊的对象,这可以通过本文提出的方法解决,因此提升更大。
可以看到,这种方法比BaseLine提高了0.8%个Map值,同时也可以看到ROIMIX在VOC上的提升比URPC上的提升少。一个可能的原因是URPC中存在更多重叠,被遮挡和模糊的对象,这可以通过本文提出的方法解决,因此提升更大。
稳定性和鲁棒性
论文分析了ROIMIX对训练稳定的目标检测器的影响。并将ROIMIX训期间的平均精度(mAP)和BaseLine进行了比较,论文在Figure5中可视化了Pascal VOC数据集和URPC数据集的结果。
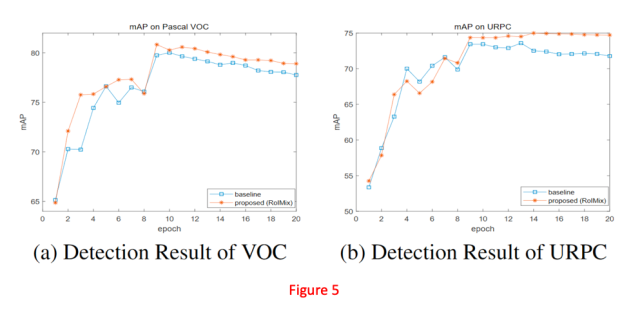 首先,论文观察到在两个训练集中训练结束时,ROIMIX的mAP值均比基准线高得多,在mAP达到最高点之后,随着训练轮次的增加,BaseLine开始面临过拟合。
首先,论文观察到在两个训练集中训练结束时,ROIMIX的mAP值均比基准线高得多,在mAP达到最高点之后,随着训练轮次的增加,BaseLine开始面临过拟合。
另一方面,ROIMIX方法在Pascal VOC中平稳下降,并且在较大幅度上保持其Map曲线优于BaseLine。在URPC数据集中,ROIMIX在达到mAP的最高点后随着时间的增加趋于稳定。此外ROIMIX和BaseLine方法在训练期间最大的mAP差别达到2.04%。结果表明ROIMIX生成的各种邻近训练数据可以减小过拟合的风险,提高训练过程的稳定性。
此外,论文通过应用5种类型的人工噪声样本(高斯噪声,泊松噪声,盐噪声,胡椒噪声和椒盐噪声)来评估模型的鲁棒性。
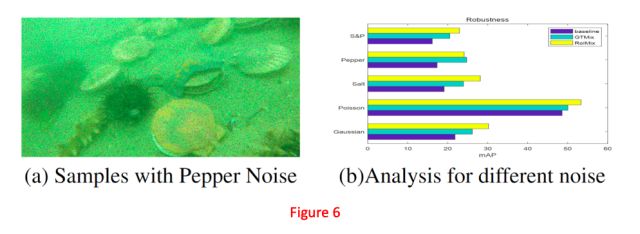 Figure6(a)可视化了带有胡椒噪声的样本。论文使用在ImageNet预训练的ResNet-101做骨干网络,其设置与4.1节中的设置相同。然后评估每种类型噪声样本使用BaseLine,GTMix和RoIMix得到的结果,并在Figure6(b)中可视化。在这5种类型的噪声中,ROIMIX和BaseLine之间的最大性能差异为9.05%个mAP值。直方图表示这种方法对噪声的鲁棒能力更强。
Figure6(a)可视化了带有胡椒噪声的样本。论文使用在ImageNet预训练的ResNet-101做骨干网络,其设置与4.1节中的设置相同。然后评估每种类型噪声样本使用BaseLine,GTMix和RoIMix得到的结果,并在Figure6(b)中可视化。在这5种类型的噪声中,ROIMIX和BaseLine之间的最大性能差异为9.05%个mAP值。直方图表示这种方法对噪声的鲁棒能力更强。
 除了人工噪声,论文还探索了对测试图像应用高斯模糊后来对模糊目标进行检测的情况。结果如Table3所示,可以看到使用ROIMIX后性能提高了0.7%个mAP。这些实验进一步说明,ROIMIX具有更好的鲁棒性。
除了人工噪声,论文还探索了对测试图像应用高斯模糊后来对模糊目标进行检测的情况。结果如Table3所示,可以看到使用ROIMIX后性能提高了0.7%个mAP。这些实验进一步说明,ROIMIX具有更好的鲁棒性。
结论
这篇论文提出了ROIMIX用于水下目标检测的方法。这应该是在多幅图像之间进行ROIs融合以生成不同训练样本的第一项工作。ROIMIX旨在模拟重叠,遮挡,和模糊的目标,从而帮助模型隐式地学习检测水下目标的能力。实验表明,本文提出的方法可以将URPC的性能提高1.18%mAP,将Pascal VOC的性能提高0.8%mAP。此外,ROIMIX具有更高的稳定性和鲁棒性。ROIMIX被作者应用在URPC 2019目标检测大赛中并获得冠军。
重磅!CVer-目标检测交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!