mysql des_MySQL · 引擎特性 · InnoDB 文件系统之文件物理结构
综述
从上层的角度来看,InnoDB层的文件,除了redo日志外,基本上具有相当统一的结构,都是固定block大小,普遍使用的btree结构来管理数据。只是针对不同的block的应用场景会分配不同的页类型。通常默认情况下,每个block的大小为 UNIV_PAGE_SIZE,在不做任何配置时值为16kb,你还可以选择在安装实例时指定一个块的block大小。对于压缩表,可以在建表时指定block size,但在内存中表现的解压页依旧为统一的页大小。
从物理文件的分类来看,有日志文件、主系统表空间文件ibdata、undo tablespace文件、临时表空间文件、用户表空间。
由于数据库需要保证数据的完整性,因此在OS系统上封装了自己的文件系统。我们来看一张图,这样也能更好的理解innodb数据库的文件结构
首先看一下页(page)的结构
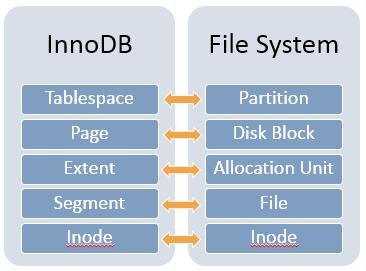
之前有说过,一个表空间文件都是由一个一个16kb的页组成,每个页都有一个32位序号(page number),通常称为偏移量,即离表空间初始位置的偏移量.因为每个页大小为16kb,所以第0个页的偏移量为0,第一个页的偏移量为16384等等.因为32位的最大值为2^32,所以一个表空间的最大值为2^32*16kb=64TB.

1. Checksum为校验和,和磁盘打交道的程序为了保证数据正确性,都必须使用校验和,目的是验证因为磁盘空间损坏导致数据损坏;
2. offset(Page Number)为页的序号,即偏移量;
3. Previous Page和Next Page InnoDB的数据在内存缓冲区是由B+树组织的,而B+树中的每一层的页是由双向链表串起来,因为每个页header有指向上一个和下一个页的指针;这种结构可以提升全表扫描的效率;
4. LSN for last page modification LSN如果不懂,可以查看InnoDB存储引擎这本书,简单说就是用于表示刷新到重做日志数据量,可用于重做日志恢复数据库.
5. Page Type 即页的类型,页的类型决定了这个页其他部分存储的数据,常见的页类型有数据业,undo页,系统页等等;
6. flush LSN 这个值存储了刷新到整个系统任何页的最大LSN值.
7. space id 存储page所在的space id

接下来我们来看一下表空间(Tablespace)的一些基础知识
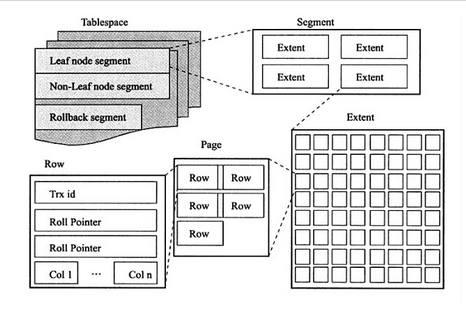
表空间是分段管理的,假如有一个表只有一个主键索引,那么这个表就有两个段,一个是内部节点段,即非叶子节点段,还有一个是叶子段,即存储数据的节点.如果一个表除了主键索引,还有一个辅助索引,那么这个这个表空间有四个段,主键内部节点段,主键叶子节点段,辅助索引内部节点段,辅助索引叶子节点段.InnoDB存储引擎有有一张图很好展示了段,区,页的关系:
当然共享表空间ibdata和用户表空间是不一样的,因为它需要存储更多全局的一些信息,例如doublewrite,undo等等,所以共享表空间拥有更多的段,这里先分析用户表空间.
每个表空间都有一个唯一space id,因为很多地方都需要使用到这个id,例如内存数据刷到磁盘时,需要使用这个space id来寻找表空间文件.InnoDB总有一个"系统空间",即共享表空间,这个表系统表空间的space id始终为0.
表空间结构
一个表空间文件是由一系列的页组成的,页数量最多可达2^32个.为了更好管理页,页又按1MB(64个连续的页)分为组,这个组称为区,InnoDB一般情况下是按区来给段分配空间.
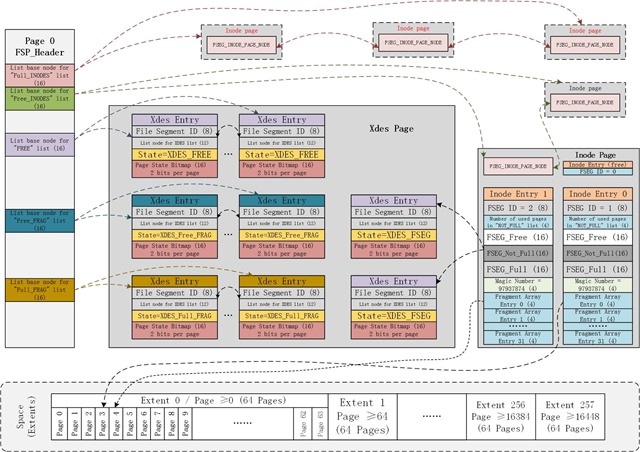
为了管理表空间所有页,区以及表空间自己,Innodb必须使用一些数据结构来跟踪保存页区等信息,下图展示了一个表空间的示意图:
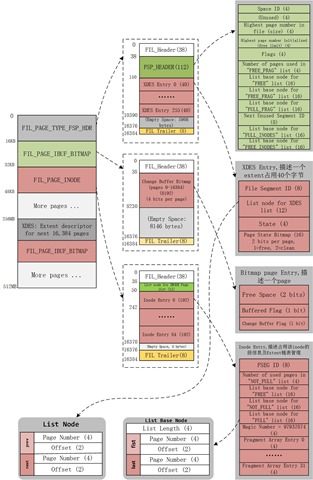
每一个表空间的第一个页为FSP_HDR(file space header)页,这个页保存了FSP header结构,这个结构保存了这个表空间的大小,以及完全没有被使用的extents,fragment的使用情况,以及inode使用情况等等,接下来详细介绍.
第1个页只能保存256个extents,也就是16384个页,256MB.因此每隔16384个页必须分配一个新的页来保存接下来的16384个页的信息,这个页就是XDES页,这个XDES页和第1个页除了FSP_HDR结构置0外(因为第一个page已经包含了base list,所以后面的XDES page 的FSP_HDR结构置0),其他都一样.
第二个页IBUF_BITMAP这个页就是插入缓存bitmap页,用于记录插入缓冲区的一些信息.
第三个页是inode页,该页用一个链表存储表空间中所有段(file segments);之前说段是由若干个extents组成,其实段除了extents之外,还有32个单独分配的"碎片"页组成,因为有些段可能用不到一个区,所以这里主要是为了节省空间.
FSP_HDR PAGE
数据文件的第一个Page类型为FIL_PAGE_TYPE_FSP_HDR,在创建一个新的表空间时进行初始化(fsp_header_init),该page同时用于跟踪随后的256个Extent(约256MB文件大小)的空间管理,所以每隔256MB就要创建一个类似的数据页,类型为FIL_PAGE_TYPE_XDES ,XDES Page除了文件头部外,其他都和FSP_HDR页具有相同的数据结构,可以称之为Extent描述页,每个Extent占用40个字节,一个XDES Page最多描述256个Extent。
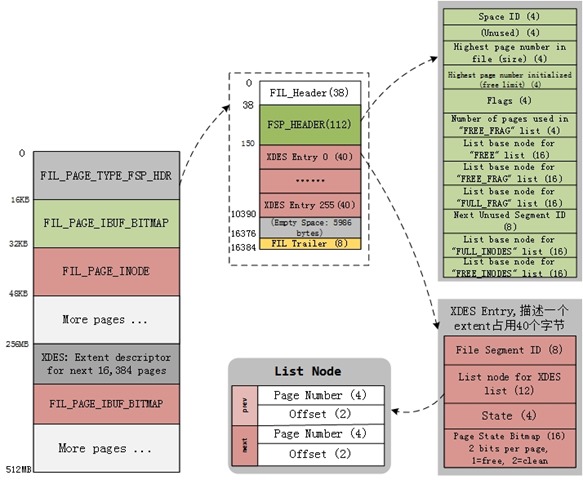
1. fsp_space_id 4 该文件对应的space id
2. fsp_not_used 4 如其名,保留字节,当前未使用
3. fsp_size 4 当前表空间总的PAGE个数,扩展文件时需要更新该值(fsp_try_extend_data_file_with_pages)
4. fsp_free_limit 4 当前尚未初始化的最小Page No。从该Page往后的都尚未加入到表空间的FREE LIST上。
5. fsp_space_flags 4 当前表空间的FLAG信息,见下文
6. fsp_frag_n_used 4 FSP_FREE_FRAG链表上已被使用的Page数,用于快速计算该链表上可用空闲Page数
7. fsp_free 16 当一个Extent中所有page都未被使用时,放到该链表上,可以用于随后的分配
8. fsp_free_frag 16 FREE_FRAG链表的Base Node,通常这样的Extent中的Page可能归属于不同的segment,用于segment frag array page的分配(见下文)
9. fsp_full_frag 16 Extent中所有的page都被使用掉时,会放到该链表上,当有Page从该Extent释放时,则移回FREE_FRAG链表
10. fsp_seg_id 8 当前文件中最大Segment ID + 1,用于段分配时的seg id计数器
11. fsp_seg_inodes_full 16 已被完全用满的Inode Page链表
12. fsp_seg_inode_free 16 至少存在一个空闲Inode Entry的Inode Page被放到该链表上
除了上述描述信息外,其他部分的数据结构和XDES PAGE(FIL_PAGE_TYPE_XDES)都是相同的,使用连续数组的方式,每个XDES PAGE最多存储256个XDES Entry,每个Entry占用40个字节,描述64个Page(即一个Extent)。格式如下:
XDES Entry
1. xdes_id 8 如果该Extent归属某个segment的话,则记录其ID
2. xdes_flst_node 12(FLST_NODE_SIZE) 维持Extent链表的双向指针节点
3. xdes_state 4 该Extent的状态信息,包括:XDES_FREE,XDES_FREE_FRAG,XDES_FULL_FRAG,XDES_FSEG,详解见下文
4. xdes_bitmap 16 总共16*8= 128个bit,用2个bit表示Extent中的一个page,一个bit表示该page是否是空闲的(XDES_FREE_BIT),另一个保留位,尚未使用(XDES_CLEAN_BIT)
XDES_STATE 表示该Extent的四种不同状态:
1. xdes_free(1) 存在于FREE链表上
2. xdes_free_frag(2) 存在于FREE_FRAG链表上
3. xdes_full_frag(3) 存在于FULL_FRAG链表上
4. xdes_fseg(4) 该Extent归属于ID为XDES_ID记录的值的SEGMENT。
通过XDES_STATE信息,我们只需要一个FLIST_NODE节点就可以维护每个Extent的信息,是处于全局表空间的链表上,还是某个btree segment的链表上。
IBUF BITMAP PAGE
第2个page类型为FIL_PAGE_IBUF_BITMAP,主要用于跟踪随后的每个page的change buffer信息,使用4个bit来描述每个page的change buffer信息。
1. IBUF_BITMAP_FREE 2 使用2个bit来描述page的空闲空间范围:0(0 bytes)、1(512 bytes)、2(1024 bytes)、3(2048 bytes)
2. IBUF_BITMAP_BUFFERED 1 是否有ibuf操作缓存
3. IBUF_BITMAP_IBUF 1 该Page本身是否是Ibuf Btree的节点
由于bitmap page的空间有限,同样每隔256个Extent Page之后,也会在XDES PAGE之后创建一个ibuf bitmap page
INODE PAGE
数据文件的第3个page的类型为FIL_PAGE_INODE,这个页拥有许多的INODE项.每个INODE entries描述了一个段(FSEG),并且用于管理数据文件中的segement,每个索引占用2个segment,分别用于管理叶子节点(leaf)和非叶子节点(no leaf);每个inode页可以存储FSP_SEG_INODES_PER_PAGE(默认为85)个记录,所以一个INODE页最多可以保存42个索引信息(一个索引使用两个段)。如果表空间有超过42个索引,则必须再分配一个INODE页.下面可以解释在FSP_HDR结构中出现的两个关于INODE的链表。
1. FREE_INODES:一系列INODE页,这些INODE页至少有一个可用的INODE entry.
2. FULL_INODES:一些列INODE页,这些INODE页所有INODE entry已使用;在独立表中的,只有表的索引超过42个,FULL_INODES才会有一个元素.
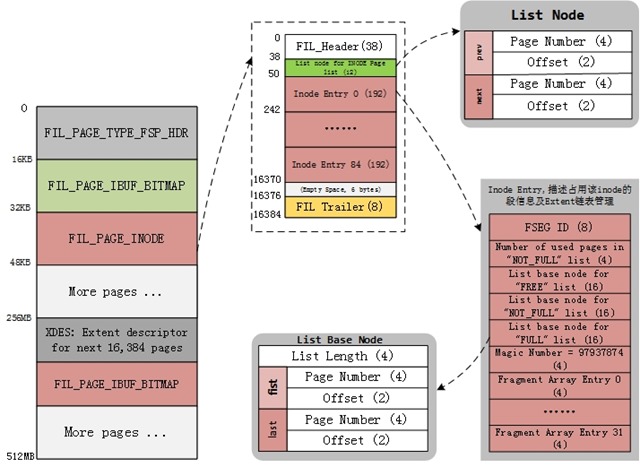
1. FSEG_INODE_PAGE_NODE 12 INODE页的链表节点,记录前后Inode Page的位置,BaseNode记录在头Page的FSP_SEG_INODES_FULL或者FSP_SEG_INODES_FREE字段。
每个Inode Entry的结构
1. fseg_id 8 该Inode归属的Segment ID,若值为0表示该slot未被使用
2. fseg_not_full_n_used 8 FSEG_NOT_FULL链表上被使用的Page数量
3. fseg_free 16 完全没有被使用并分配给该Segment的Extent链表
4. fseg_not_full 16 至少有一个page分配给当前Segment的Extent链表,全部用完时,转移到FSEG_FULL上,全部释放时,则归还给当前表空间FSP_FREE链表
5. fseg_full 16 分配给当前segment且Page完全使用完的Extent链表
6. fseg_magic_n 4 Magic Number
7. fseg_frag_arr 0 4 属于该Segment的独立Page。总是先从全局分配独立的Page,当填满32个数组项时,就在每次分配时都分配一个完整的Extent,并在XDES PAGE中将其Segment ID设置为当前值
其实这三个页都是管理页
首先介绍基于文件的一个基础结构,即文件链表。为了管理Page,Extent这些数据块,在文件中记录了许多的节点以维持具有某些特征的链表,例如在在文件头维护的inode page链表,空闲、用满以及碎片化的Extent链表等等。
在InnoDB里链表头称为FLST_BASE_NODE,大小为FLST_BASE_NODE_SIZE(16个字节)。BASE NODE维护了链表的头指针和末尾指针,每个节点称为FLST_NODE,大小为FLST_NODE_SIZE(12个字节)。相关结构描述如下:

FLST_PREV 6 指向当前节点的前一个节点
FLST_NEXT 6 指向当前节点的下一个节点
list_base_node
FLST_LEN 4 存储链表的长度
FLST_FIRST 6 指向链表的第一个节点
FLST_LAST 6 指向链表的最后一个节点
FSP_HDR PAGE通过5个文件链表管理着整个表空间List base node for "FREE" list、List base node for "FREE_FRAG" list (16)、List base node for "FULL_FRAG" list (16)
List base node for "FULL_INODES" list (16)、List base node for "FREE_INODES" list (16);通过XDES Entry管理每一个页的具体情况。
INODE PAGE也是通过文件链表管理着segment的。
INDEX PAGE
ibd文件中真正构建起用户数据的结构是BTREE,在你创建一个表时,已经基于显式或隐式定义的主键构建了一个btree,其叶子节点上记录了行的全部列数据(加上事务id列及回滚段指针列);如果你在表上创建了二级索引,其叶子节点存储了键值加上聚集索引键值
每个btree使用两个Segment来管理数据页,一个管理叶子节点,一个管理非叶子节点,每个segment在inode page中存在一个记录项,在btree的root page中记录了两个segment信息。
当我们需要打开一张表时,需要从ibdata的数据词典表中load元数据信息,其中SYS_INDEXES系统表中记录了表,索引,及索引根页对应的page no(DICT_FLD__SYS_INDEXES__PAGE_NO),进而找到btree根page,就可以对整个用户数据btree进行操作。
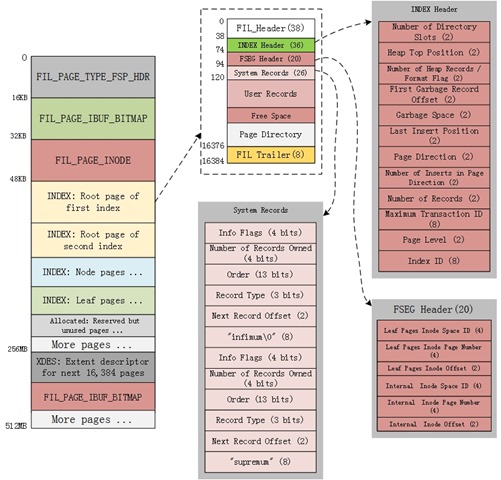
Index Header
紧随FIL_PAGE_DATA之后的是索引信息,这部分信息是索引页独有的。
1. page_n_dir_slots 2 Page directory中的slot个数 (见下文关于Page directory的描述)
2. page_heap_top 2 指向当前Page内已使用的空间的末尾便宜位置,即free space的开始位置
3. page_n_heap 2 Page内所有记录个数,包含用户记录,系统记录以及标记删除的记录,同时当第一个bit设置为1时,表示这个page内是以Compact格式存储的
4. page_free 2 指向标记删除的记录链表的第一个记录
5. page_garbage 2 被删除的记录链表上占用的总的字节数,属于可回收的垃圾碎片空间
6. page_last_insert 2 指向最近一次插入的记录偏移量,主要用于优化顺序插入操作
7. page_direction 2 用于指示当前记录的插入顺序以及是否正在进行顺序插入,每次插入时,PAGE_LAST_INSERT会和当前记录进行比较,以确认插入方向,据此进行插入优化
8. page_n_direction 2 当前以相同方向的顺序插入记录个数
9. page_n_recs 2 Page上有效的未被标记删除的用户记录个数
10. page_max_trx_id 8 最近一次修改该page记录的事务ID,主要用于辅助判断二级索引记录的可见性。
11. page_level 2 该Page所在的btree level,根节点的level最大,叶子节点的level为0
12. page_index_id 8 该Page归属的索引ID
Segment Info
随后20个字节描述段信息,仅在Btree的root Page中被设置,其他Page都是未使用的。
1. page_btr_seg_leaf 10(FSEG_HEADER_SIZE) leaf segment在inode page中的位置
2. page_btf_seg_top 10(FSEG_HEADER_SIZE) non-leaf segment在inode page中的位置
10个字节的inode信息包括:
1. fseg_hdr_space 4 描述该segment的inode page所在的space id (目前的实现来看,感觉有点多余…)
2. fseg_hdr_page_no 4 描述该segment的inode page的page no
3. fseg_hdr_offset 2 inode page内的页内偏移量
通过上述信息,我们可以找到对应segment在inode page中的描述项,进而可以操作整个segment。
System Records
Compact的系统记录存储方式为:
1. rec_n_new_extra_tytes 5 固定值,
2. page_new_infimum 8 “infimum\0”
3. rec_n_new_extra_bytes 5 固定值,
4. page_new_supremum 8 “supremum”,这里不带字符0
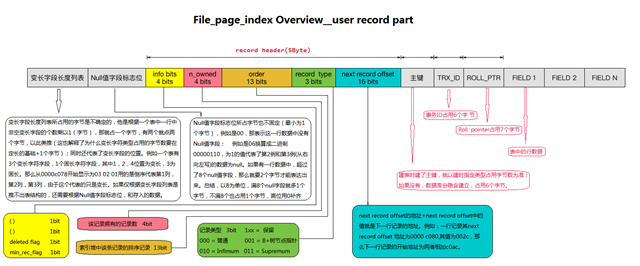
5个字节包Info Flags (4 bits)、Number of Records Owned (4 bits)、Order (13 bits)、Record Type (3 bits)、Next Record Offset (2),其中Next Record Offset本身的地址加上其值,为下一条记录的开始地址。
User Records
在系统记录之后就是真正的用户记录了
根据不同的类型,用户记录可以是非叶子节点的Node指针信息,也可以是只包含有效数据的叶子节点记录
每个记录都存在rec header