知乎上关于‘深度学习调参技巧’讨论
作者:杨军
链接:https://www.zhihu.com/question/25097993/answer/127374415
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.zhihu.com/question/25097993/answer/127374415
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


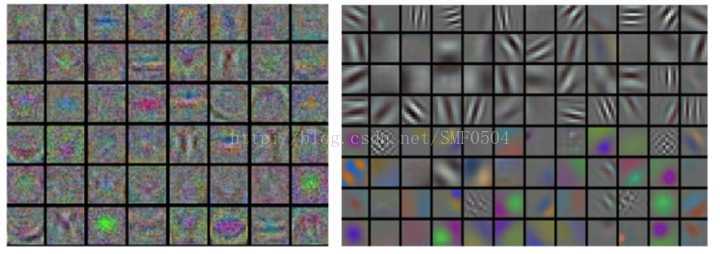
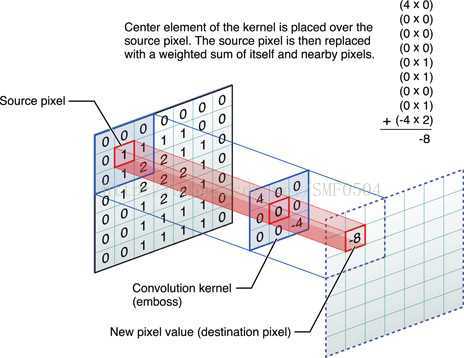





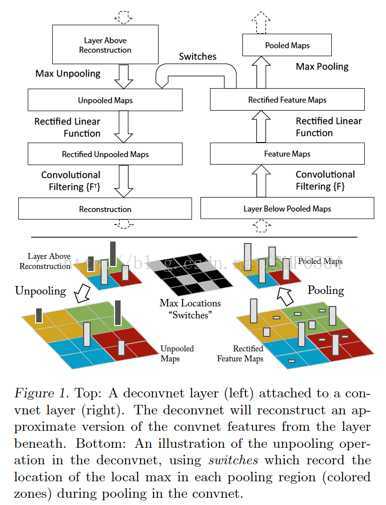


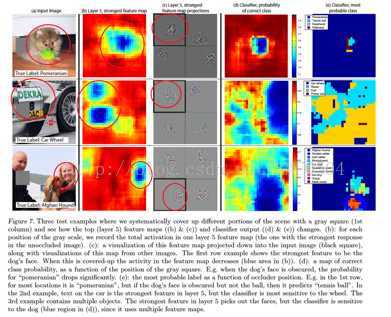
编辑于 2016-10-19
作者:Captain Jack
链接:https://www.zhihu.com/question/25097993/answer/127472322
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.zhihu.com/question/25097993/answer/127472322
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
编辑于 2016-10-20
作者:罗浩.ZJU
链接:https://www.zhihu.com/question/25097993/answer/136222606
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
看到几个图,对于优化函数的比较有很直观的帮助,其中adadelta可以近似的认为adam,果然和我平时实验的结果一致,通常adam优化函数的性能是不错的
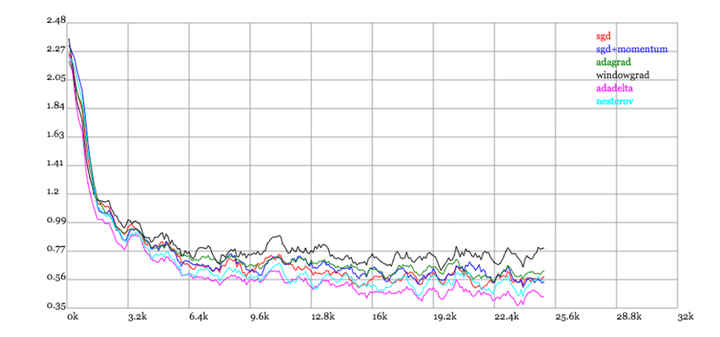
http://img.blog.csdn.net/20160824161755284
http://img.blog.csdn.net/20160824161815758
作者:匿名用户
链接:https://www.zhihu.com/question/25097993/answer/37525469
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.zhihu.com/question/25097993/answer/136222606
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
根据我平时使用的经验,记住几个关键词就可以
Relu,batchnorm,dropout,adam ,微步幅
前面几个比较好理解,relu 是一个很万能的激活函数,可以很好的防止梯度弥散问题,当然最后一层的激活函数千万慎用relu,如果是连续的用identify(还是叫identity ,记不清了),分类的用softmax ,拟合回归的话我最后一层也经常不用激活函数,直接wx +b就行
batchnorm也是大杀器,可以大大加快训练速度和模型性能
Dropout 也是防止过拟合的大杀器,如果不知道怎么设比例的话,就直接设置为0.5,即一半一半,但是测试的时候记得把dropout关掉
Adam 优化函数应该是收敛非常快的一个优化函数,不过有人说sgd +momentum 速度慢一点但是性能好,但是我用的没感觉性能好
微步幅是只卷积步幅选择2,然后模板数量逐层翻倍,就是越来越小但越来越厚,反卷积的话对称反过来,这样每次卷积图像就缩小了一半,下采样和池化都可以不加,我一直不加的
以上是我平时调参的一些经验,可供参考,我平时用这些方法基本上在一两百次迭代就可以达到百分之八十的性能了,所以除了刷结果不需要训练那么久
大半夜手机码字好艰难 o(╥﹏╥)o
----------------------------------------------------------------补充几个图--------------------------------------------------------看到几个图,对于优化函数的比较有很直观的帮助,其中adadelta可以近似的认为adam,果然和我平时实验的结果一致,通常adam优化函数的性能是不错的
http://img.blog.csdn.net/20160824161755284
http://img.blog.csdn.net/20160824161815758
编辑于 2015-01-19
作者:匿名用户
链接:https://www.zhihu.com/question/25097993/answer/37525469
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:陈旭展
链接:https://www.zhihu.com/question/25097993/answer/161393876
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.zhihu.com/question/25097993/answer/161393876
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
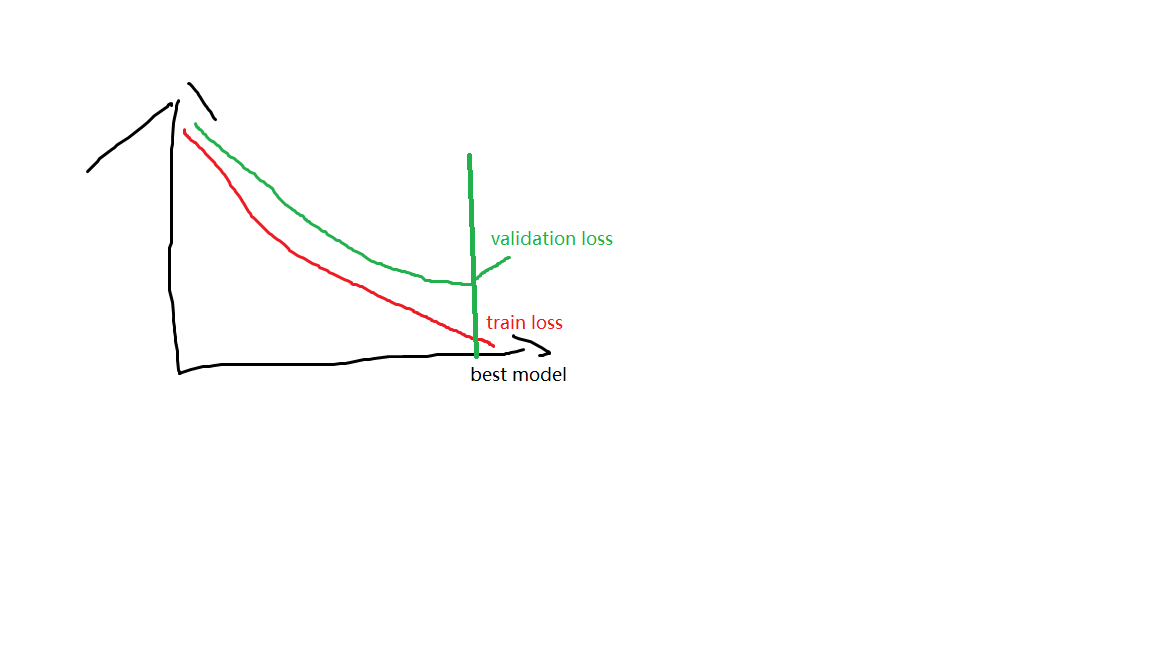
编辑于 2017-04-27
作者:陈旭展
链接:https://www.zhihu.com/question/25097993/answer/161393876
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.zhihu.com/question/25097993/answer/161393876
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
编辑于 2017-04-27