云边协同下的数据处理模式有何不同?


导读:随着云边协同平台的不断发展,数据处理领域也在悄然发生着变化:一方面,数据的主要来源仍以不断增长的“人”(即用户)为基础,但逐渐向“物”发生转变;另一方面,在数据来源更加丰富的前提下,包括网络通信技术、数据处理方法在内的多方面因素又共同推动着数据处理模式从单机模式、云模式逐渐向边缘模式、云边协同模式发生转变。

作者:韩锐、刘驰
来源:华章计算机
01
数据来源
可以将互联网上的数据来源主要分为以下方面:
1、人
在过去的10~20年,传统互联网以个人计算机端为代表,向移动端方向不断延伸,从基础的电子邮件,快速发展成为具备搜索、社交、购物等一系列生活、生产功能的综合技术体,而这一系列网络应用的发展,推动着不断扩大的用户群体产生越来越多的数据。
如图1-3所示,Cisco预测称2023年互联网用户数量将上升至53亿(2018年仅为39亿),相应的人口比例将上升至60%(2018年仅为51%)。不论是绝对数量还是相对比例,都将发展至很高的水平。
因此,随着互联网用户数量的发展逐渐进入瓶颈,人们自身能够输出的数据的增长速度也逐渐变得缓慢,但每位用户所拥有的设备数量还积存着大量潜能未被释放。
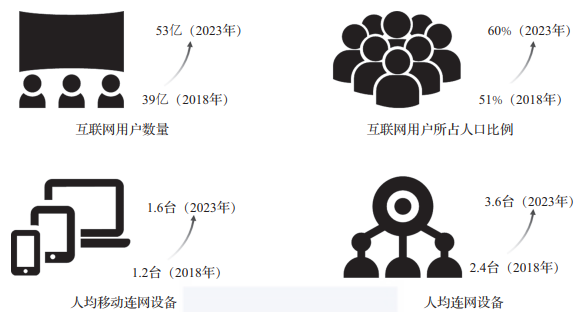
图1 互联网用户及设备飞速增长
2、物
随着移动计算、物联网、工业物联网等新兴技术的涌现,互联网迎来了新的下半场——万物互联。在万物互联时代中,各行各业的物品都能够通过网络进行连接,例如生产制造业中的机床、交通运输业中的机动车辆、医疗健康业中的心率传感器等。这些设备在传统的基础功能之上,具备了网络接入、网络访问等能力,使得人们无须直接接触实体,便能够获取最新的运行状态、传感数据、上下文环境等信息。
对于“物”的发展规模而言,一方面,每位用户所拥有的连网设备数量不断增长,如图1所示,在人口基数逐渐达到瓶颈的前提下,到2023年,人均连网设备仍将达到3.6台;另一方面,全世界范围内的物联网设备整体数量更是达到了惊人地步——Transforma Insights的报告指出,截至2019年年底,物联网设备数量已经达到了76亿,并预计到2030年增长至241亿。
物联网以及工业物联网设备的快速增长,不可避免地带来了海量的数据,不同于传统互联网以人为中心的数据生成,一方面,这类新型数据通常具有更加复杂的特性,同时包含着更加多样化、更高价值的信息;另一方面,数据产生的位置也逐渐从网络中心迁移至网络边缘。这些在网络边缘端产生的数据由于规模巨大、时效性高,难以通过传统的网络基础设施传输至云端数据中心进行统一处理,因此亟待边缘平台发挥地理位置优势。利用云-边-端协同平台的强大支撑,可帮助数据处理应用实现更低成本、更加高效、更高性能的数据挖掘、分析与决策。
02
处理模式
随着计算平台由探索阶段逐渐发展至云阶段,数据处理任务模式也相应地经历着数次变革:
1)单机模式。在互联网技术还未大规模覆盖时,任务处理过程通常以个人计算机、专用服务器等独立的个体进行实现,性能主要受制于机器本身的资源瓶颈。
2)个人计算机-服务器模式。由于网络技术(尤其是宽带技术)的普及,任务处理所需的操作请求、数据内容等信息能够通过LAN、WAN在客户机(例如个人计算机)与服务器之间进行传输,从而使得用户能够利用服务器的大量资源,处理更为复杂的运算。
3)移动计算模式。伴随智能手机、平板计算机等一系列轻薄的便携式设备的出现,移动互联网逐渐成熟,并在越来越多的场景下取代了原有个人计算机的地位。但受限于体积以及无线的特点,这类设备通常无法负担较为复杂的处理任务,需要将它交由数据中心来完成。
如今,物联网、工业物联网应用成为互联网新的爆发点,迅速增长的数据量使得传统的任务处理模式都难以应对,计算平台由逐渐成熟的云阶段开始转向云边协同阶段,探索新的任务处理方法。其中,最为首要的问题便是云、边、设备三端之间如何协同,换言之,这三者之间如何进行交互,才能在保证应用需求的前提下,最大化性能表现(例如运行效率),同时尽可能地降低成本:
1)数据中心。优势在于海量资源可供调配,在计算能力、存储规模等方面难以替代。在智能化服务场景下,能够运行全局性、长周期、大数据训练。
2)边缘节点。作为云平台与用户设备的媒介,边缘平台分布广泛,十分靠近数据产生源,相比用户设备而言具有更多的资源,能够容纳一定规模的数据处理任务,但仍难以达到数据中心的性能水平。
3)智能设备。作为与用户直接交互的产品,它的功能、形状、性质均具有较大差异,但总体而言,计算能力十分有限,且具有较高的动态性、不稳定性。
因此,结合云、边、设备三者的特点,根据在任务处理过程中可能的参与程度进行分级,如图2所示,提出以下4种云-边-端协同模式:
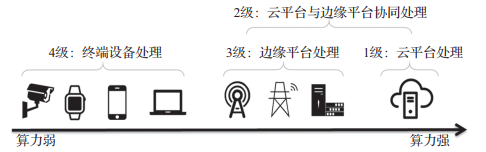
图2 云边端协同模式
(1)1级
终端设备(例如传感器、监控摄像头)作为数据产生源,直接将原生数据通过网络上传至云平台,完成所有的数据处理、分析等一系列任务,并将结果再次通过网络发送至用户。该模式接近于传统的云计算范式,没有边缘平台的参与,目前已被广泛应用,但面对新型应用的延迟、带宽需求难以满足。
(2)2级
将任务进行切分,将不同的子任务部分卸载至边缘平台或云平台。具体而言,设备根据多样化的策略以及各平台资源的特点,通过LAN或蜂窝网络将部分的数据处理任务传输至边缘节点,将其余的任务部分传输至云端节点,协同完成整体的计算。对于卸载至边缘平台的任务而言,通常是轻量的或是延迟敏感的类型,例如:
1)数据预处理,包括数据清理、完整性检查、敏感信息加密等;
2)数据流实时检测,利用流式计算对持续发生的事件进行监控,并在检出异常后以极低延迟进行决策;
3)模型实时推断,利用云端训练好的模型,进行低延迟的推断任务。
但由于本身资源所限,边缘平台在面对规模庞大的原始模型(例如数百兆甚至数千兆的深度神经网络模型)时,可能无力运行,需要对它进行压缩,使用包括量化降低权重参数精度、结构剪枝、知识蒸馏等技术在内的方案,减小模型体积,加快运行速度。
对于卸载至云平台的任务而言,通常是对计算资源要求极高的复杂性任务,例如神经网络模型训练、大数据分析等。该模式下边缘平台较大程度受限于资源短缺,仅承担一定程度的数据处理任务,因此对云、边两者协同模式下的任务卸载调度提出了更高难度的挑战。
(3)3级
数据处理任务将主要卸载至边缘平台,完成绝大部分的计算任务,包括数据读取、预处理、分析、决策等。此模式下,云平台仅承担全局性的、必要性的任务,例如全局资源管理、边缘平台调度、数据共享以及远距离通信等。该模式要求边缘平台已经较高程度地覆盖了网络边缘范围,且能够为数据处理提供性能(例如延迟、吞吐、稳定性等)、隐私等方面的可靠保障,运行需要较高要求的复杂计算任务,使得设备能够信任并依赖于边缘平台的能力。
(4)4级
设备本身能够承担主要的任务处理。此时,不论是轻量级的异常检测、模型推断、敏感性的数据加密,还是更为复杂的大数据统计、模型训练,都能够运行在设备本身。这不仅要求任务处理技术的攻坚,更要求设备本身(尤其是硬件层面)的突破性进展,以保障在计算、存储、能源(例如电量)等方面为数据处理提供有力支撑。此时,边缘平台将作为区域性的媒介,连接海量的物联网、工业物联网设备,对它进行通信管理、资源调度;同时,云平台作为全局性的媒介,承担广域下的技术支持,包括全局通信、同步、调度等方面。该模式对当前软、硬件的技术发展均提出了极高的挑战,需要研究人员更加深入探索。
需要注意到,1~4级的不同协同模式之间并非具有明确的界限,即便在同一系统中,也可能同时存在跨多级或介于两级之间的处理方案。另一方面,对于诸多复杂的场景,“集中”与“分布”的程度没有限制,云、边、端三者的计算能力如何合适分配也没有定式,需要以上述4种协同模式为基础,根据实际需求,灵活设计实现。
目前,已经出现一些公司初步实现了连接云边的开发框架,能够直接在边缘平台开发机器学习应用,例如微软公司的Azure IoT Edge Runtime。
未来,随着1~4级交互模式的发展,数据处理热点逐渐从网络中心走向网络边缘,这将带来带宽、延迟、能耗等多方面的提升,但如上所述,也同时面临着技术领域更大的挑战。
关于作者:
韩锐,北京理工大学特别研究员,博士生导师。专注于研究面向典型负载(机器学习、深度学习、互联网服务)的云计算系统优化,在 TPDS、TC、TKDE、TSC等领域顶级(重要)期刊和INFOCOM、ICDCS、ICPP、RTSS等会议上发表超过40篇论文,Google学术引用1000 余次。
刘驰,北京理工大学计算机学院副院长,教授,博士生导师。智能信息技术北京市重点实验室主任,国家优秀青年科学基金获得者,国家重点研发计划首席科学家,中国电子学会会士,英国工程技术学会会士,英国计算机学会会士。
本文摘编自《云边协同大数据:技术与应用》,经出版方授权发布。(ISBN:9787111701002)转载请保留文章出处。

推荐语:本书以云边协同技术为主线,首先介绍云计算与边缘计算的发展历程,然后详细介绍云边协同环境下雾计算、边缘计算等与传统云平台相结合而催生的典型云边协同技术及其实际应用场景和案例。

刷刷视频👇

更多精彩回顾
干货 |Java到底能干什么?有哪些实际用途?
书单 | 成为优秀Java开发者,我看了这几本书
上新 |《Core Java》作者亲授视频免费看,学习Java更轻松
资讯 |云原生时代,阿里如何让Java冷启动提速两个数量级?
资讯 | Python迎来31岁生日,蝉联年度编程语言排行榜冠军
干货 |一文带你掌握计算机体系结构核心内容
书讯 | 2月书讯(下)| 新年到,新书到!
书讯 | 2月书讯 (上)| 新年到,新书到!


点击阅读全文