CogView整体图解
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、总括
二、数据集输入(token)
三、Transformer(GPT)
四、TransformerLayer
五、Self Attention
六、MLP
一、总括
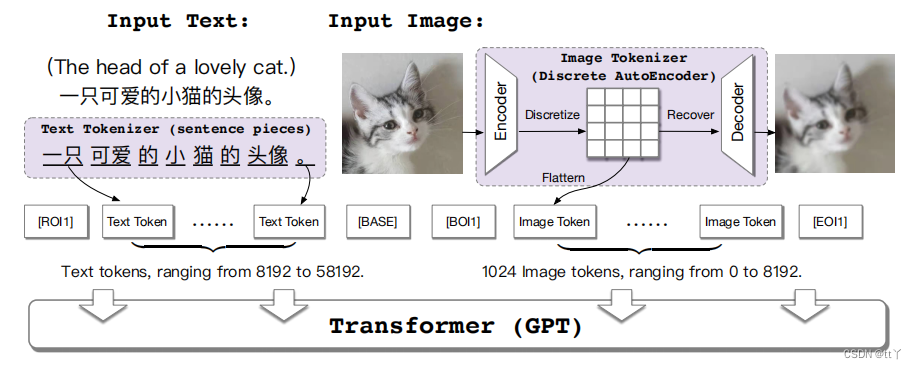
二、数据集输入(token)
1、生成
由cogdata生成二进制数据集(生成token)
cogdata用法:GitHub - Sleepychord/cogdata: A light-weight data management system for large-scale pretraining
2、token
text通过SentencePiece模型生成text token;image通过一个离散化的AE(Auto-Encoder)转换为image token。
token作用在于将text和image变成尽量意义独立的小块,便于后面映射到token空间(类似于词向量的表达阿巴阿巴),而在这里对于image的意义就更大了,因为把一张大的图变成多个小块,减轻了后续网络的计算量。
3、data and label
因为是从左到右预测,比如说第一个token输入得到预测的第二个token再与目标的第二个token进行比对得到loss(所以labels比tokens延后一位)
下面的代码在pretrain_gpt2.py中(其中的labels为比对target;tokens为输入的token数据)
def get_batch(data_iterator, args, timers):#获取该batch的数据
# Items and their type.
keys = ['text', 'loss_mask']
datatype = torch.int64
# Broadcast data.
timers('data loader').start()
if data_iterator is not None:
data = next(data_iterator)
else:
data = None
timers('data loader').stop()
data_b = mpu.broadcast_data(keys, data, datatype)
# Unpack.解压数据
tokens_ = data_b['text'].long()
loss_mask = data_b['loss_mask'].float()#这个loss mask应该是服务于继续训练的那种吧(如果一开始训练应该为None)
labels = tokens_[:, 1:].contiguous()#目标
loss_mask = loss_mask[:, 1:].contiguous()
tokens = tokens_[:, :-1].contiguous()#输入token
#因为是从左到右预测,比如说第一个token输入得到预测的第二个token再与目标的第二个token进行比对得到loss(所以labels比tokens延后一位)
attention_mask = None
# Get the masks and postition ids.获得位置编码,attention mask 和 loss mask
attention_mask, loss_mask, position_ids = get_masks_and_position_ids(
tokens,
loss_mask=loss_mask,
attention_mask=attention_mask,
args=args
)
# Convert转为半精度
if args.fp16:
attention_mask = attention_mask.half()
return tokens, labels, loss_mask, attention_mask, position_ids三、Transformer(GPT)
细节,代码解析等详见CogView中网络结构的总体构建_tt丫的博客-CSDN博客
总括图上的Transformer(GPT)
word embeddings转为词向量;Transformer为主体网络结构:从左到右预测token(前一个token推出下一个token),有多个Tansformer block(layer)组成。
该图中的Transformer又可按下面的细分(不稀疏处理)
细节,代码解析等详见CogView中的Transformer_tt丫的博客-CSDN博客
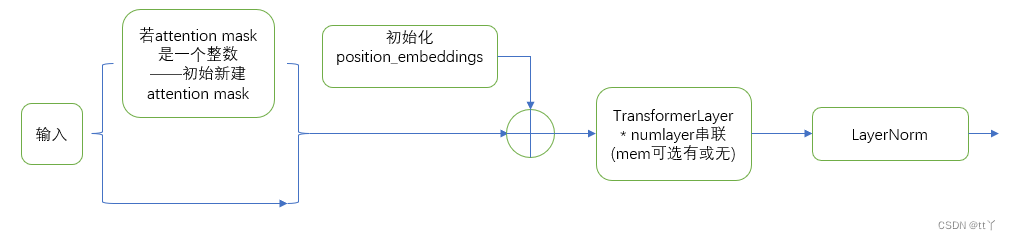
其中单层的TransformerLayer:见四
四、TransformerLayer
细节,代码解析等详见CogView中的单层TransformerLayer_tt丫的博客-CSDN博客

运用了两次残差结构(便于实现非常高复杂度的模型,并且有助于解决梯度消失和梯度爆炸问题),同时还运用了LayerNorm用于维稳。
其中的Self Attention:见五
其中的MLP:见六
五、Self Attention
细节,代码解析等详见CogView中的Self Attention_tt丫的博客-CSDN博客
使网络学习关注某个重要的信息点
这里加入的attention mask是为了从左到右预测而服务的(下三角)

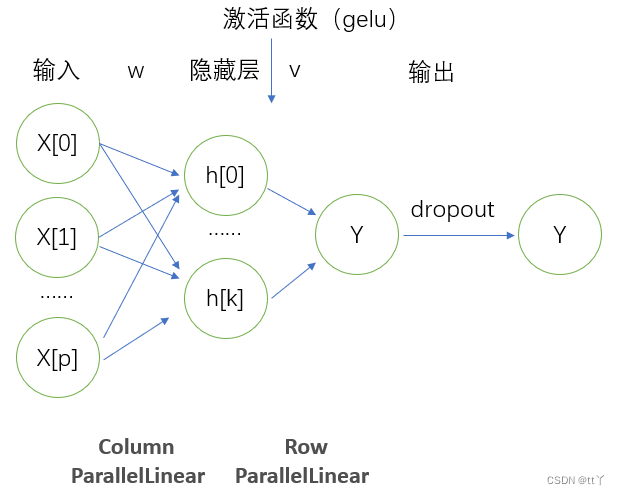
六、MLP
细节,代码解析等详见CogView中的MLP_tt丫的博客-CSDN博客
欢迎大家在评论区进行批评指正,谢谢~