【CSDN创作话题 】丨 竞赛那些事

前言/背景
我参加过的数学建模比赛没拿过奖,我准备大量的参加数学建模比赛,不断的积累经验,虽然我现在很菜,但我就是那种又菜又爱玩的人,输了又能怎么样,我只在乎过程中我学到了什么,当然得奖才是我的动力。我相信在未来我能拿到一个属于自己认可的奖。
大赛简介
我就参加过这一个比赛。

参赛流程
首先,需要一个有能力的队伍,一个可以编程能力,一个可以论文演讲,一个可以数学算法。然后每个人又对其他两个有点了解,这样的队伍我觉得就很舒服。其次,就是三个人都要有激情,不能有负能量,团队要有凝聚力,这样大家在冲刺时,遇到问题时,熬夜时,才不会抱怨,影响大家的热情。最后,这个非常重要,就是比赛前的准备,要准备些什么呢,比如比赛的常用算法代码可以准备一下吧,还有写论文的工具的使用方法,排版等。
参赛经历
我比赛时,没有团队,因为要求要两个人以上才能参加,我就拉了一个人来凑数。所以我一个人在完成编程后,就没有什么时间去写论文了,最后还有很多点都没有写完,就连排版都没有做好,问题是解决了,但论文写不好,都是白扯。
经验心得
团队很重要!团队很重要!团队很重要!
资料分享
下面分享一下数据分析部分内容。
首先是加载数据
略…………
将特征表与标签表聚合拼接
# 聚合数据
df_1 = pd.merge(bhv_train,cust_train)
train = pd.merge(df_1,train_label)
test = pd.merge(bhv_test,cust_test)查看维度
# 样本个数和特征维度
train.shape #(7206, 34)
test.shape #(1655, 34).查看特征名
# 查看特征名
train.columns
test.columns
因为比赛提供的是脱敏数据,所以我们就不知道这些特征具体是什么意思。
# 查看数据集的一些基本信息
train.info()
train.head().T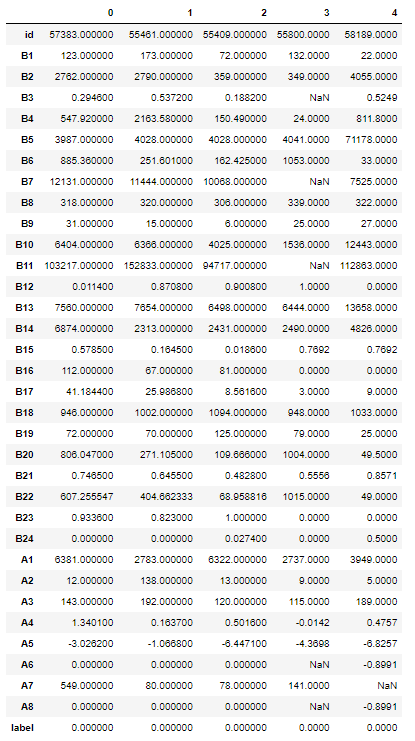
# 查看一下数据的描述性分析
train.describe().T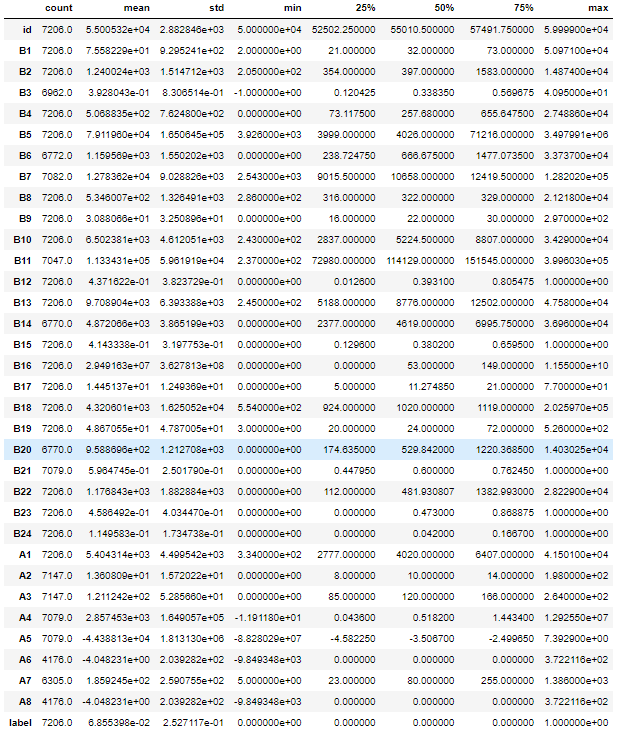
以上可以让我们更了解数据
下面对数据类型分析
# 数值类型
numerical_feature = list(train.select_dtypes(exclude=['object']).columns)
numerical_featurelen(numerical_feature) ## 34
# 连续型变量
serial_feature = []
# 离散型变量
discrete_feature = []
# 单值变量
unique_feature = []
for fea in numerical_feature:
temp = train[fea].nunique()# 返回的是唯一值的个数
if temp == 1:
unique_feature.append(fea)
# 自定义变量的值的取值个数小于10就为离散型变量
elif temp <= 10:
discrete_feature.append(fea)
else:
serial_feature.append(fea)
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
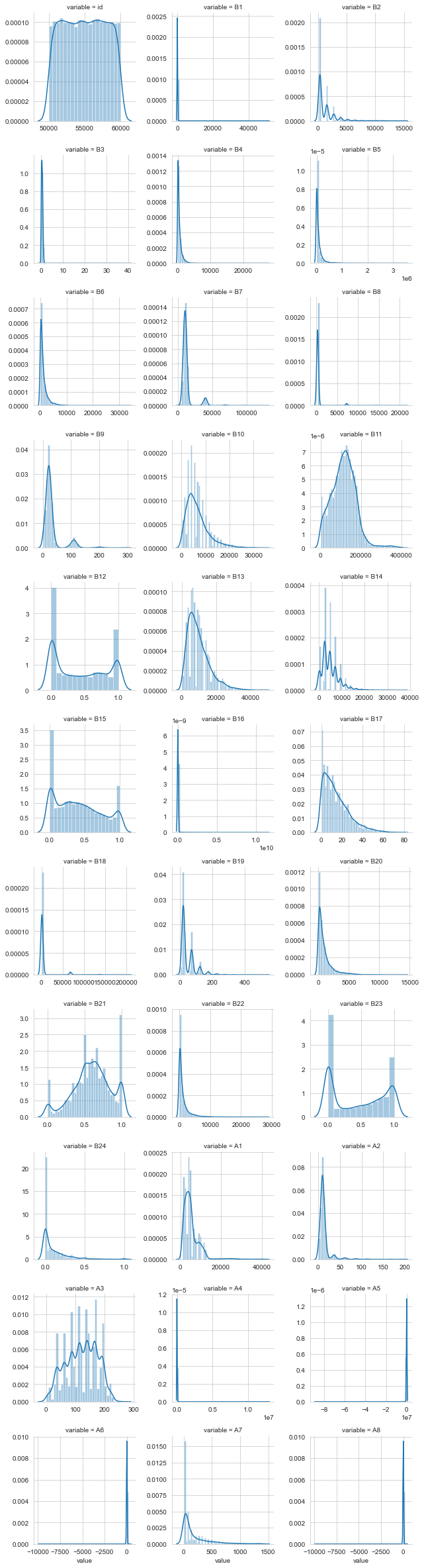
#每个数字特征得分布可视化
f = pd.melt(train, value_vars=serial_feature)
g = sns.FacetGrid(f, col="variable", col_wrap=3, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
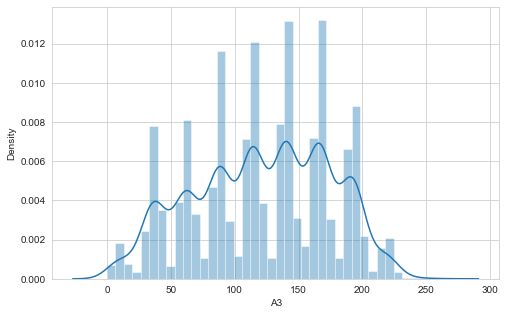
plt.figure(1 , figsize = (8 , 5))
sns.distplot(train.A3,bins=40)
plt.xlabel('A3')
discrete_feature['label']
import seaborn as sns
import matplotlib.pyplot as plt
df_ = train[discrete_feature]# 离散型变量
sns.set_style("whitegrid") # 使用whitegrid主题
fig,axes=plt.subplots(nrows=1,ncols=1,figsize=(8,10))# nrows=4,ncols=2,括号加参数4x2个图
for i, item in enumerate(df_):
plt.subplot(4,2,(i+1))
ax=sns.countplot(item,data = df_,palette="Pastel1")
plt.xlabel(str(item),fontsize=14)
plt.ylabel('Count',fontsize=14)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
#plt.title("Churn by "+ str(item))
i=i+1
plt.tight_layout()
plt.show()

label=train.label
label.value_counts()/len(label)
train_positve = train[train['label'] == 1]
train_negative = train[train['label'] != 1]
f, ax = plt.subplots(len(numerical_feature),2,figsize = (10,80))
for i,col in enumerate(numerical_feature):
sns.distplot(train_positve[col],ax = ax[i,0],color = "blue")
ax[i,0].set_title("positive")
sns.distplot(train_negative[col],ax = ax[i,1],color = 'red')
ax[i,1].set_title("negative")
plt.subplots_adjust(hspace = 1)
缺失值查看
# 去掉标签
# X_missing = train.drop(['label'],axis=1)
X_missing =test
# 查看缺失情况
missing = X_missing.isna().sum()
missing = pd.DataFrame(data={'特征': missing.index,'缺失值个数':missing.values})
#通过~取反,选取不包含数字0的行
missing = missing[~missing['缺失值个数'].isin([0])]
# 缺失比例
missing['缺失比例'] = missing['缺失值个数']/X_missing.shape[0]
missing.to_csv("2455.csv")# 可视化
s=(train.isnull().sum()/len(train)).plot.bar(figsize = (20,6),color=['#d6ecf0','#a3d900','#88ada6','#ffb3a7','#cca4e3','#a1afc9'])
# 可以看到,所有的特征缺失值都在10%以内,这里考虑全部保留。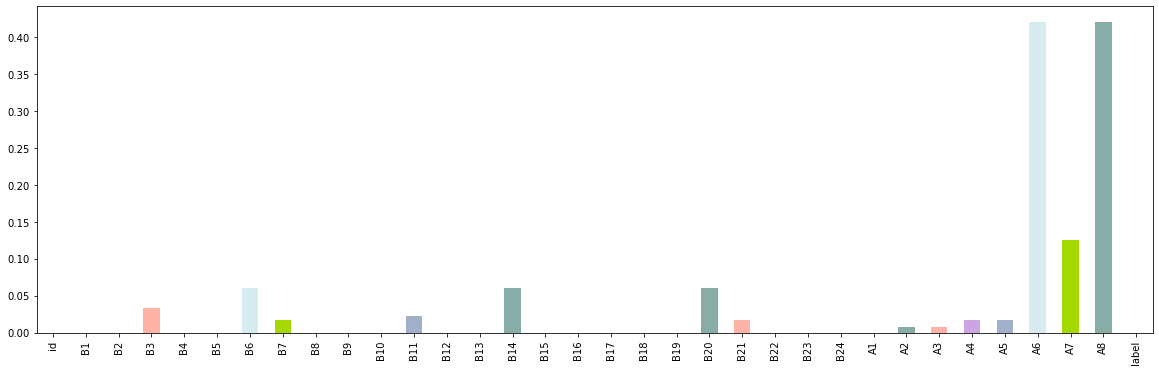
异常值处理
# 数值类型
numerical_feature = list(train.select_dtypes(exclude=['object']).columns)
def find_outliers_by_3segama(data,fea):
data_std = np.std(data[fea])
data_mean = np.mean(data[fea])
outliers_cut_off = data_std * 3
lower_rule = data_mean - outliers_cut_off
upper_rule = data_mean + outliers_cut_off
data[fea+'_outliers'] = data[fea].apply(lambda x:str('异常值') if x > upper_rule or x < lower_rule else '正常值')
return data
data_train = train.copy()
for fea in numerical_feature:
data_train = find_outliers_by_3segama(data_train,fea)
print(data_train[fea+'_outliers'].value_counts())
print(data_train.groupby(fea+'_outliers')['label'].sum())
print('*'*10)
# 检索异常值
fig,ax=plt.subplots(figsize=(15,5))
train.boxplot()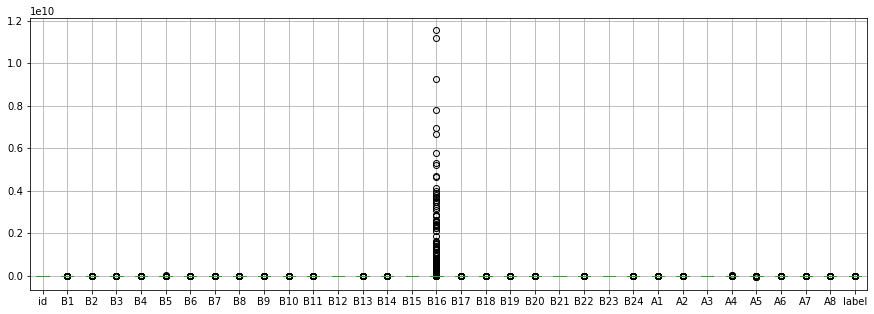
#使用拉依达准则(3σ准则)
import numpy as np
import pandas as pd
#设置需读取文件的路径
data =train
# 记录方差大于3倍的值
#shape[0]记录行数,shape[1]记录列数
sigmayb = [0]*data.shape[0]
for i in range(1,data.shape[1]):
print("处理第"+str(i)+"行")
# 循环 每一列
lie = data.iloc[:, i].to_numpy()
print(lie)
mea = np.mean(lie)
s = np.std(lie, ddof=1)
# 计算每一列 均值 mea 标准差 s
print("均值和标准差分别为:"+str(mea)+" "+str(s))
#统计大于三倍方差的行
for t in range(1,data.shape[0]):
if (abs(lie[t]-mea) > 3*s):
print(">3sigma"+" "+str(t)+" "+str(i))
#将异常值置空
if i != 33:
data.iloc[t,i]= np.nan
# 将处理后的数据存储到原文件中
train=data
数据相关关系
f, ax = plt.subplots(1,1, figsize = (20,20))
cor = train[numerical_feature].corr()
sns.heatmap(cor, annot = True, linewidth = 0.2, linecolor = "white", ax = ax, fmt =".1g" )
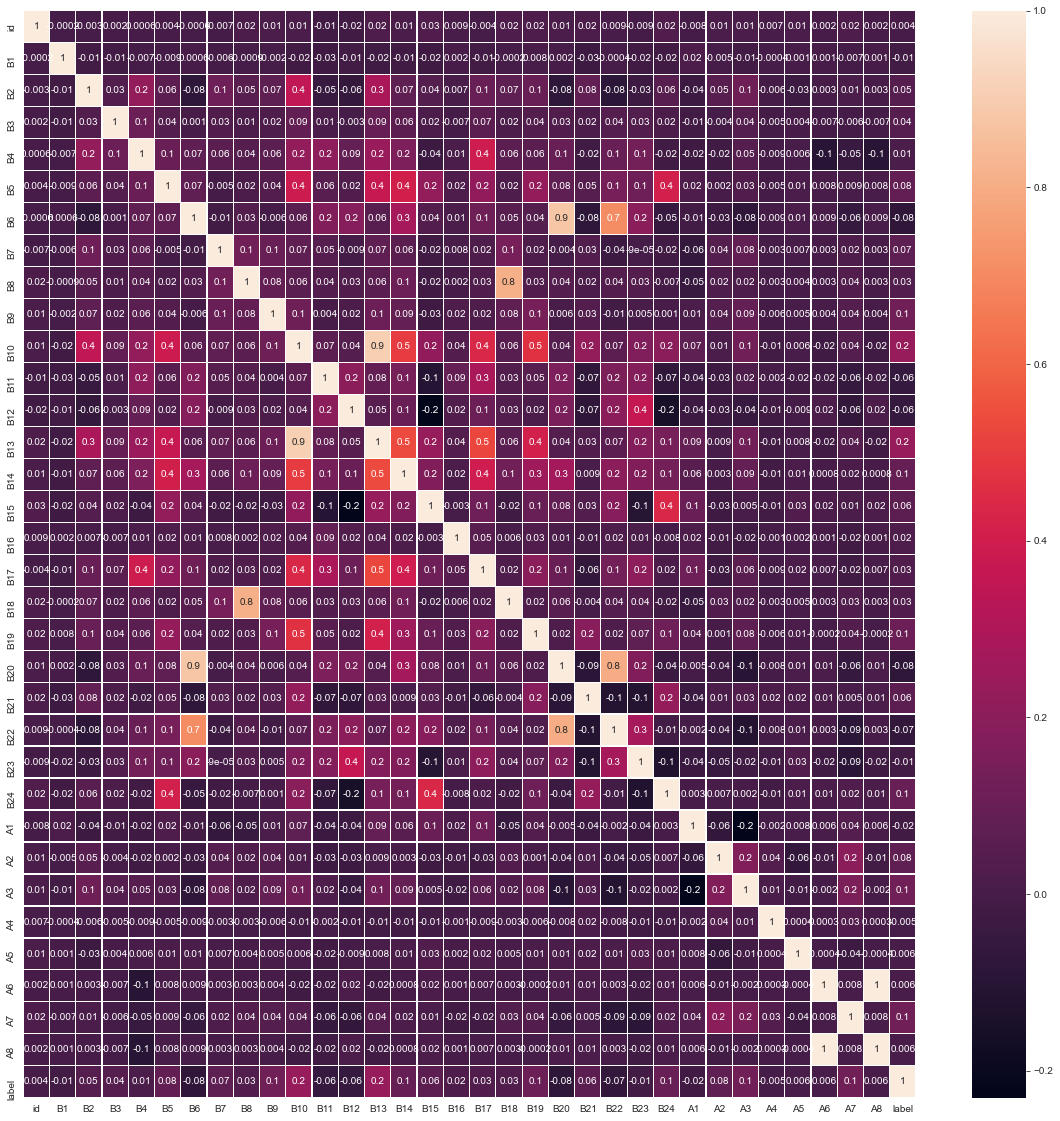
#查看变量与标签的相关性
train.corr()["label"].sort_values()
以上就是数据分析EDA的一些部分过程分享。
具体分析就不说了,只能分享操作。