Rancher 2.6 全新 Logging 快速入门(2)
作者简介
万绍远,CNCF 基金会官方认证 Kubernetes CKA&CKS 工程师,云原生解决方案架构师。对 ceph、Openstack、Kubernetes、prometheus 技术和其他云原生相关技术有较深入的研究。参与设计并实施过多个金融、保险、制造业等多个行业 IaaS 和 PaaS 平台设计和应用云原生改造指导。
概述
本篇为 Rancher 2.6 全新 Logging 快速入门 的后续,为实际生产配置使用手册。主要介绍以下日志收集配置功能:
- 审计日志收集;
- Kubernetes 组件日志收集;
- 运行在 Kubernetes 上的容器应用日志收集;
- Runtime 日志收集;
- Kubernetes 事件收集和节点;
- 节点 Kernel 日志收集。
Rancher 2.6 日志采用了 logging-operator 方式进行日志管理,对应概念如下:
- logging:用于定义一个日志采集端 (FleuntBit) 和传输端 (Fleuntd) 服务的基础配置,在 SUSE Rancher 2.6 版本中,已经由 Rancher 自动化部署完成;
- flow:用于定义一个 namespaces (命名空间)级别的日志过滤、解析和路由等规则;
- clusterflow:用于定义一个集群级别的日志过滤、解析和路由等规则;
- output:用于定义 namespace (命名空间)级别的日志的输出和参数,它只能被同命名空间内的 flow 关联;
- clusteroutput:用于定义集群级别的日志输出和参数,它能把被其他命名空间内的 flow 关联。
Logging 配置使用
ElasticSearch 和 kibana 部署
为了更好地演示效果,这里部署临时的 ElasticSearch 和 kibana 作为演示环境:
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.5.2
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://172.16.1.232:9200 -p 5601:5601 -d kibana:7.5.2
注:将 ELASTICSEARCH_HOSTS 地址修改为实际 ElasticSearch 的地址。
部署完后可通过 http://ip:9200 访问 ElasticSearch,通过 http://ip:5601 访问 Kibana。
启用 Rancher Logging
切换到对应集群,选择 cluster-Tools——>Logging,并勾选自定义 Helm 选项:


systemd Log Path 存储的是系统日志,因为 k3s 和 RKE2 发行版日志都存储在此。因此为了收集此日志,需要进行配置此选项:
要确定目录位置,可在其中一个节点上运行:cat /etc/systemd/journald.conf | grep -E ^\#?Storage | cut -d"=" -f2
- 如果返回 persistent,则应为:
systemdLogPath/var/log/journal - 如果返回 volatile,则应为:
systemdLogPath/run/log/journal - 如果返回 auto,请检查是否存在
/var/log/journal - 如果存在
/var/log/journal,则使用/var/log/journal - 如果不存在
/var/log/journal,则使用/run/log/journal - SLES15 默认为
/run/log/journal
部署前勾选编辑 yaml,进行以下参数修改:
- 修改 loggint-Operator 的默认配置,如 fluentd 和 fluentbit 默认资源限制和容忍规则,将 fluentbit 部署到 Controller 节点用于系统日志收集。
- bufferStorageVolume 为 fluentd 收集 fluentbit 的 log buffer 目录,有分布式文件系统存储,建议存储到分布式文件系统中,修改 storageClassName 为实际分布式存储的 stroageclass 名字。如果没有对应存储,可以修改为
bufferStorageVolume: {}.
替换以下内容:
fluentbit:
filterKubernetes:
Merge_Log: ''
Merge_Log_Key: ''
Merge_Log_Trim: ''
Merge_Parser: ''
inputTail:
Buffer_Chunk_Size: ''
Buffer_Max_Size: ''
Mem_Buf_Limit: ''
Multiline_Flush: ''
Skip_Long_Lines: ''
resources:
limits:
cpu: 500m
memory: 1024M
requests:
cpu: 50m
memory: 100M
tolerations:
- effect: NoSchedule
key: cattle.io/os
operator: Equal
value: linux
- operator: Exists
fluentd:
bufferStorageVolume:
pvc:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 40Gi
storageClassName: fast
volumeMode: Filesystem
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 15
tcpSocket:
port: 24240
nodeSelector: {}
resources:
limits:
cpu: '2'
memory: 4096M
requests:
cpu: 500m
memory: 100M
tolerations: {}
replicas: 3
fullnameOverride: ''
执行以下命令检查部署是否成功:
kubectl get pod -n cattle-logging-system
NAME READY STATUS RESTARTS AGE
rancher-logging-96b68cc4b-vqxnd 1/1 Running 0 9m54s
rancher-logging-fluentbit-cntgb 1/1 Running 0 69s
rancher-logging-fluentbit-hwmdx 1/1 Running 0 71s
rancher-logging-fluentbit-nw7rw 1/1 Running 0 71s
rancher-logging-fluentd-0 2/2 Running 0 9m34s
rancher-logging-fluentd-1 2/2 Running 0 9m34s
rancher-logging-fluentd-2 2/2 Running 0 9m34s
rancher-logging-fluentd-configcheck-ac2d4553 0/1 Completed 0 9m48s
集群审计日志开启和采集
要在集群所有 Controller 节点上创建审计日志策略,需要在主机创建审计日志策略文件 /etc/kubernetes/audit-policy.yaml,内容如下:
apiVersion: audit.k8s.io/v1
kind: Policy
omitStages:
- "RequestReceived"
rules:
- level: Metadata
添加集群参数,从Cluster-Manager 选择对应的集群 —> edit Config,给 Api-server 添加以下参数:
kube-apiserver-arg:
- audit-log-maxsize=100
- audit-log-maxage=60
- audit-log-maxbackup=10
- audit-policy-file=/etc/kubernetes/audit-policy.yaml
参数解释:
- maxsize:表示日志量多大时进行一次轮转
- maxage:表示保留审计日志多少天
- maxbackup:表示保留审计日志文件多少份
- policy-file:定义审计日志保存策略
添加 apiserver 目录映射参数:
kube-apiserver-extra-mount:
- /etc/kubernetes:/etc/kubernetes
因为 api-server 是 pod 方式启动,为了能加载 auditlog-policy,需要将此目录映射到 api-server pod 中。
完成后,集群会进入自动升级模式。等待升级完成,集群审计日志将存储在/var/lib/rancher/rke2/server/logs/audit.log文件和目录。
Kubernetes 组件日志收集
RKE2 Kubernetes 组件日志都集中在以下 namespace 中,在启动 logging 时,配置日志目录会自动部署采集器进行采集:
应用以下 Yaml 到集群中:
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: test-output
namespace: cattle-logging-system
spec:
elasticsearch:
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
host: 172.16.1.166
port: 9200
scheme: http
reconnect_on_error: true
reload_on_failure: true
reload_connections: false
logstash_format: true
logstash_prefix: k8s-components
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: test
namespace: cattle-logging-system
spec:
globalOutputRefs:
- test-output
match:
- select:
namespaces:
- cattle-monitoring-system
- cattle-system
- kube-system
- ClusterOutput:定义日志发送到哪,这里配置的是 ElasticSearch,根据实际情况,修改 ElasticSearch 的地址;
- Logstash_prefix 定义的是对应的 ElasticSearch 内的 index 名称。建议根据对应集群名称配置;
- Logstash_prefix:定义发送到 ES 后对应的 Index 名称;
- Logstash_format:表示开启 Index 按天自动创建轮转;
- ClusterFlow:用于定义一个集群级别的日志过滤、解析和路由等规则,在这里 labels 与对应的采集 pod 的 label 相关连,这里启动 Hosttailer 后会自动启动收集 pod 和集群层级收集关联;
- GlobalOutputRefs 定义的为上面配置的 ClusterOutput 的名称,表示输出到什么地方。
Kubernetes Application 日志采集
应用以下 Yaml 到集群中:
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: k8s-application-output
namespace: cattle-logging-system
spec:
elasticsearch:
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
host: 172.16.1.166
port: 9200
scheme: http
reconnect_on_error: true
reload_on_failure: true
reload_connections: false
logstash_format: true
logstash_prefix: k8s-application
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: test
namespace: cattle-logging-system
spec:
globalOutputRefs:
- k8s-application-output
match:
- exclude:
namespaces:
- cattle-monitoring-system
- cattle-system
- cattle-logging-system
- kube-system
- cattle-fleet-system
- select: {}
通过 exclude 将系统组件命名空间排除在外,采集的便是全部应用的标准输出日志。
Runtime 日志采集
应用以下 Yaml 到集群中:
apiVersion: logging-extensions.banzaicloud.io/v1alpha1
kind: HostTailer
metadata:
name: runtimelog-hosttailer
namespace: cattle-logging-system
spec:
fileTailers:
- name: runtime-tail
path: /var/lib/rancher/rke2/agent/containerd/containerd.log
buffer_max_size: 64k #此值一定要修改,不然启动不成功
disabled: false
skip_long_lines: "true"
containerOverrides:
image: www.wanshaoyuan.com/rancher/mirrored-fluent-fluent-bit:1.8.15
workloadOverrides:
tolerations:
- effect: NoSchedule
key: cattle.io/os
operator: Equal
value: linux
- operator: Exists
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: runtimelog-tailer-clusteroutput
namespace: cattle-logging-system
spec:
elasticsearch:
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
reconnect_on_error: true
reload_on_failure: true
reload_connections: false
host: 172.16.1.166
port: 9200
scheme: http
logstash_format: true
logstash_prefix: cluster1-runtimelog-tailer
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: runtimetailer-flow
namespace: cattle-logging-system
spec:
filters:
- tag_normaliser: {}
- parser:
parse:
type: none
match:
- select:
labels:
app.kubernetes.io/instance: runtimelog-hosttailer-host-tailer
globalOutputRefs:
- runtimelog-tailer-clusteroutput
配置审计日志采集
应用以下 Yaml 到集群中:
apiVersion: logging-extensions.banzaicloud.io/v1alpha1
kind: HostTailer
metadata:
name: auditlog-hosttailer
namespace: cattle-logging-system
spec:
fileTailers:
- name: audit-tail
path: /var/lib/rancher/rke2/server/logs/audit.log
buffer_max_size: 64k #此值一定要修改,不然启动不成功
disabled: false
skip_long_lines: "true"
containerOverrides:
image: www.wanshaoyuan.com/rancher/mirrored-fluent-fluent-bit:1.8.15
workloadOverrides:
tolerations:
- effect: NoSchedule
key: cattle.io/os
operator: Equal
value: linux
- operator: Exists
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: auditlog-tailer-clusteroutput
namespace: cattle-logging-system
spec:
elasticsearch:
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
reconnect_on_error: true
reload_on_failure: true
reload_connections: false
host: 172.16.1.166
port: 9200
scheme: http
logstash_format: true
logstash_prefix: cluster1-auditlog-tailer
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: hosttailer-flow
namespace: cattle-logging-system
spec:
filters:
- tag_normaliser: {}
- parser:
parse:
type: json
match:
- select:
labels:
app.kubernetes.io/instance: auditlog-hosttailer-host-tailer
globalOutputRefs:
- auditlog-tailer-clusteroutput
- containerOverrides: 定义的是离线部署的镜像,默认镜像地址为
fluent/fluent-bit:1.8.15; - HostTailer:定义采集的文件,并自动部署 fluent-bit 进行挂载映射;
- ClusterOutput:定义日志发送到哪,这里配置的是 ElasticSearch,根据实际情况,修改 ElasticSearch 的地址,logstash_prefix 定义的是对应的 ElasticSearch 内的 index 名称。建议根据对应集群名称配置;
- Flow:用于定义一个 namespaces (命名空间)级别的日志过滤、解析和路由等规则,在这里 labels 与对应的采集 pod 的 label 相关连,这里启动 hosttailer 后会自动启动收集 pod,它的 label 为
app.kubernetes.io/instance: auditlog-hosttailer-host-tailer; - globalOutputRefs 定义的为上面配置的 ClusterOutput 的名称,表示输出到什么地方。
Event 收集
应用以下 Yaml 到集群中:
apiVersion: logging-extensions.banzaicloud.io/v1alpha1
kind: EventTailer
metadata:
name: rancher
spec:
controlNamespace: cattle-logging-system
containerOverrides:
image: www.wanshaoyuan.com/rancher/eventrouter:v0.1.0
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: event-tailer-clusteroutput
namespace: cattle-logging-system
spec:
elasticsearch:
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
reconnect_on_error: true
reload_on_failure: true
reload_connections: false
host: 172.16.1.166
port: 9200
scheme: http
logstash_format: true
logstash_prefix: kubernetes-event-tailer
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: rancher-event-tailer-flow
namespace: cattle-logging-system
spec:
filters:
- tag_normaliser: {}
- parser:
parse:
type: json
globalOutputRefs:
- event-tailer-clusteroutput
match:
- select:
labels:
app.kubernetes.io/name: event-tailer
- EventTailer:设置 Event 收集,会启动一个 rancher-event-tailer statefulset,内网部署需要修改镜像地址为内网仓库。默认镜像地址为
banzaicloud/eventrouter:v0.1.0; - ClusterOutput:定义日志发送到哪,这里配置的是 ElasticSearch,根据实际情况,修改 ElasticSearch 的地址,logstash_prefix 定义的是对应的 ElasticSearch 内的 index 名称,建议根据对应集群名称配置;
- labels:关联的是 rancher-event-tailer 这个 statefulset 的 label。
节点 Kernel 日志收集
应用以下 Yaml 到集群中:
---
apiVersion: logging-extensions.banzaicloud.io/v1alpha1
kind: HostTailer
metadata:
name: rancher-host-file-tailer
namespace: cattle-logging-system
spec:
fileTailers:
- name: system-messages
path: /var/log/messages
buffer_max_size: 64k
disabled: false
skip_long_lines: "true"
containerOverrides:
image: www.wanshaoyuan.com/rancher/mirrored-fluent-fluent-bit:1.8.15
workloadOverrides:
tolerations:
- effect: NoSchedule
key: cattle.io/os
operator: Equal
value: linux
- operator: Exists
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: host-files-clusteroutput
namespace: cattle-logging-system
spec:
elasticsearch:
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
reconnect_on_error: true
reload_on_failure: true
reload_connections: false
host: 172.16.1.166
port: 9200
scheme: http
logstash_format: true
logstash_prefix: cluster_os_logs
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: rancher-host-files-flow
namespace: cattle-logging-system
spec:
filters:
- tag_normaliser: {}
- record_modifier:
records:
- host: ${record.dig('kubernetes', 'host')}
whitelist_keys: host,message
globalOutputRefs:
- host-files-clusteroutput
match:
- select:
labels:
app.kubernetes.io/instance: rancher-host-file-tailer-host-tailer
在 ElasticSearch 中检查是否创建出对应的 index,并且检查全部 index:
curl http://172.16.1.166:9200/_cat/indices
yellow open k8s-components-2022.06.02 hg9OQTQEQsKLNwn3Kf_jdA 1 1 85231 0 32.4mb 32.4mb
yellow open cluster_os_logs-2022.06.02 zARda8N1R9OpZRX-cZIS1g 1 1 3666 0 738.9kb 738.9kb
yellow open k8s-application-2022.06.02 x0XxNvmmQQurdWDn4IL2gA 1 1 433 0 232.5kb 232.5kb
yellow open cluster1-auditlog-tailer-2022.06.02 qrAzHadxTeWQXF-E8B1VEQ 1 1 1686458 0 761.2mb 761.2mb
yellow open cluster1-runtimelog-tailer-2022.06.02 0DQp0at8TzOGSt911wnocw 1 1 1545 0 469.2kb 469.2kb
yellow open kubernetes-event-tailer-2022.06.02 L80_wp6iRQy2d0DGmiSxhA 1 1 1169 0 1.1mb 1.1mb
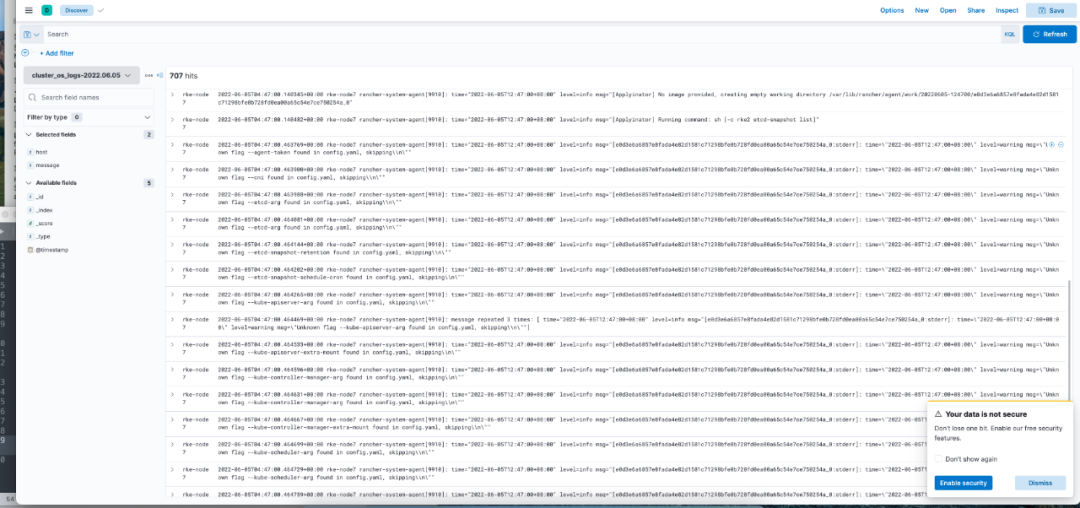
在 kibana 中查看 index 中日志信息:
总结
相比于 Rancher 2.6 之前的版本, Logging-operator 的引入大大增强了灵活性和功能性,可以非常灵活地配置各类参数和想收集的日志信息;但与之对应的是,使用门槛比 2.6 之前版本的有所提高。希望本篇文章可以帮助你加深对 Rancher Logging 的理解。