Elasticsearch:运用 Python 实现在 Elasticsearch 上的向量搜索
向量搜索在最新的 Elasticsearch 的发布版中有很多新的提高。在我之前的文章:
-
Elasticsearch:使用向量搜索来查询及比较文字 - NLP text embedding
-
Elasticsearch:使用向量搜索来搜索图片及文字
有详细的应用案例介绍。究其本质它使用了向量搜索。它首先把我们想要搜索的字段进行向量化,然后在搜索时再对搜索的词也进行向量化。通过对向量的搜索,我们可以找出最匹配的结果。
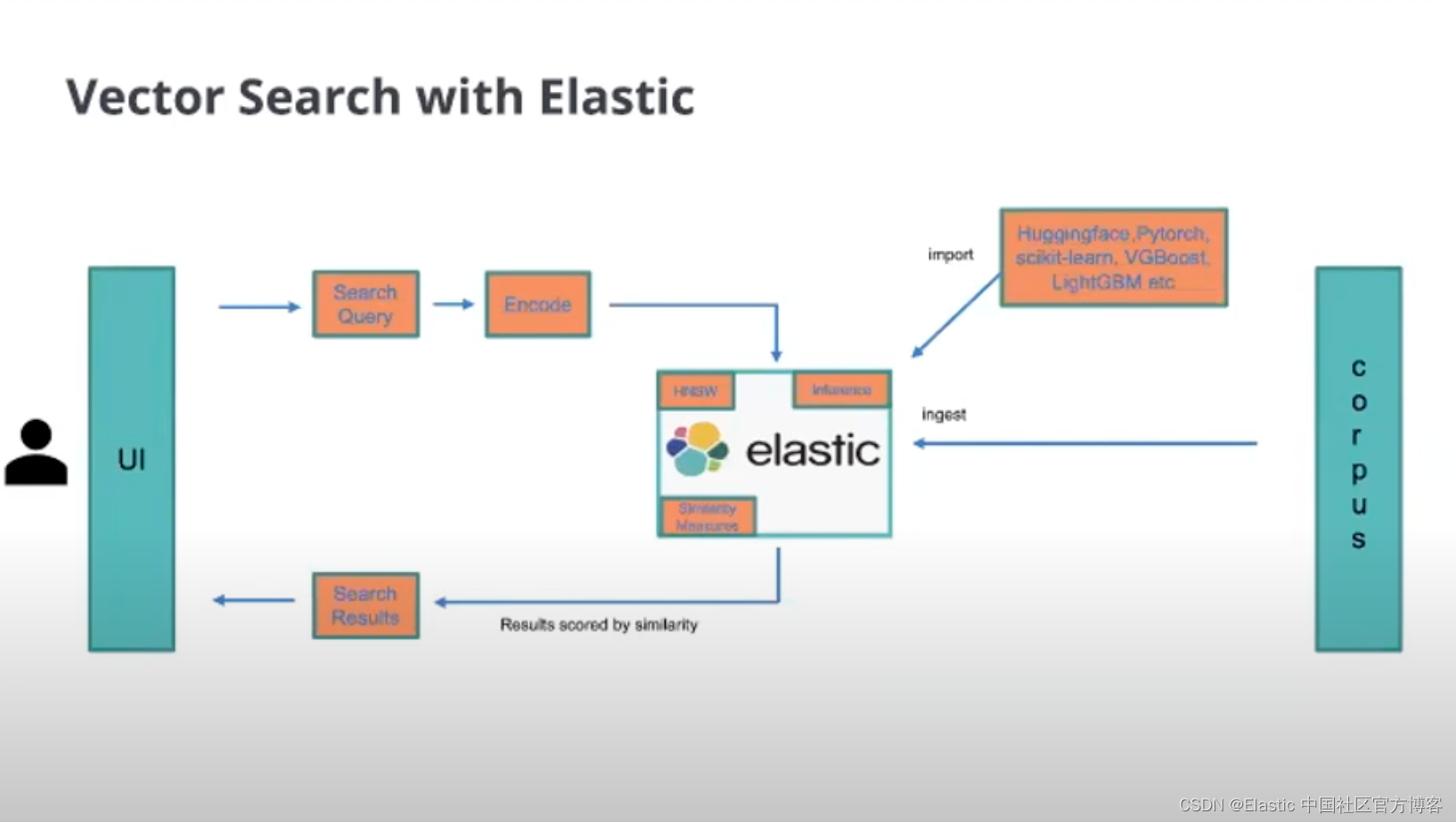
在之前的教程中,我们必须通过购买白金版来通过 eland 来获得上传我们的模型的权限。在今天的展示中,我将使用 Python 来实现对搜索字段的向量化,并在 Python 中实现对字段的向量搜索。
安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elastic Stack,请参考如下的文章来安装 Elasticsearch 及 Kibana:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Elastic:使用 Docker 安装 Elastic Stack 8.0 并开始使用
在今天的展示中,我将使用最新的 Elastic Stack 8.4.0 来进行展示。
Python 安装
我们先在自己的电脑上安装好 Python,并按照如下的命令按照好相应的模块:
pip install -U sentence-transformers
pip install transformers在今天的练习中,我们将使用 sentence-transformers/all-MiniLM-L6-v2 · Hugging Face 模型来实现语义的搜素。这是一个 sentence-transformers 模型:它将句子和段落映射到 384 维密集向量空间,可用于聚类或语义搜索等任务。我可以参考文档来了解更多。
在使用这个模型做我们的搜索之前,我们先来使用几个小的例子来进行展示一下:
快速入手
test.py
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print("length of embeddings: {}, dims: {}".format(len(embeddings), len(embeddings[0])))
print(embeddings)运行上面的代码,我们可以看到如下的输出:

显然它是两个 384 维度的数组数据,也就是向量。在 sentences 中有两个句子,所以就有两个 384 维度的向量输出。
比较两个句子的相似性
句子(文本)被映射,使得具有相似含义的句子在向量空间中接近。 衡量向量空间相似度的一种常用方法是使用余弦相似度。 对于两个句子,可以这样完成:
test.py
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
#Sentences are encoded by calling model.encode()
emb1 = model.encode("This is a red cat with a hat.")
emb2 = model.encode("Have you seen my red cat?")
cos_sim = util.cos_sim(emb1, emb2)
print("Cosine-Similarity:", cos_sim)运行上面的代码:
$ python test.py
Cosine-Similarity: tensor([[0.6153]])我们可以看到两个句子的相似度是 0.61。这个是语义上的相似。
如果你有一个包含更多句子的列表,你可以使用以下代码示例:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ['A man is eating food.',
'A man is eating a piece of bread.',
'The girl is carrying a baby.',
'A man is riding a horse.',
'A woman is playing violin.',
'Two men pushed carts through the woods.',
'A man is riding a white horse on an enclosed ground.',
'A monkey is playing drums.',
'Someone in a gorilla costume is playing a set of drums.'
]
#Encode all sentences
embeddings = model.encode(sentences)
print(f"length of embeddings: {len(embeddings)}, dims: {len(embeddings[0])}")
#Compute cosine similarity between all pairs
cos_sim = util.cos_sim(embeddings, embeddings)
# print out all of the similarity
print("The similarities are: ")
print(cos_sim)
#Add all pairs to a list with their cosine similarity score
all_sentence_combinations = []
for i in range(len(cos_sim)-1):
for j in range(i+1, len(cos_sim)):
all_sentence_combinations.append([cos_sim[i][j], i, j])
#Sort list by the highest cosine similarity score
all_sentence_combinations = sorted(all_sentence_combinations, key=lambda x: x[0], reverse=True)
print("Top-5 most similar pairs:")
for score, i, j in all_sentence_combinations[0:5]:
print("{} \t {} \t {:.4f}".format(sentences[i], sentences[j], cos_sim[i][j]))运行上面的代码:
 我们可以从上面看出来句子和句子之间的相似性的比较的分数。 在上面的最后把相似性得分最高的5个分别打印出来了。从上面我们可以看出来:
我们可以从上面看出来句子和句子之间的相似性的比较的分数。 在上面的最后把相似性得分最高的5个分别打印出来了。从上面我们可以看出来:
A man is eating food. A man is eating a piece of bread. 0.7553上面的这两个句子的得分最高,从而相似性最好。在上面的比较中,我们使用语义上的比较,而不是对它们进行分词而的出来的结果。
下载数据集
我们在地址 Online Job Postings | Kaggle 下载数据集
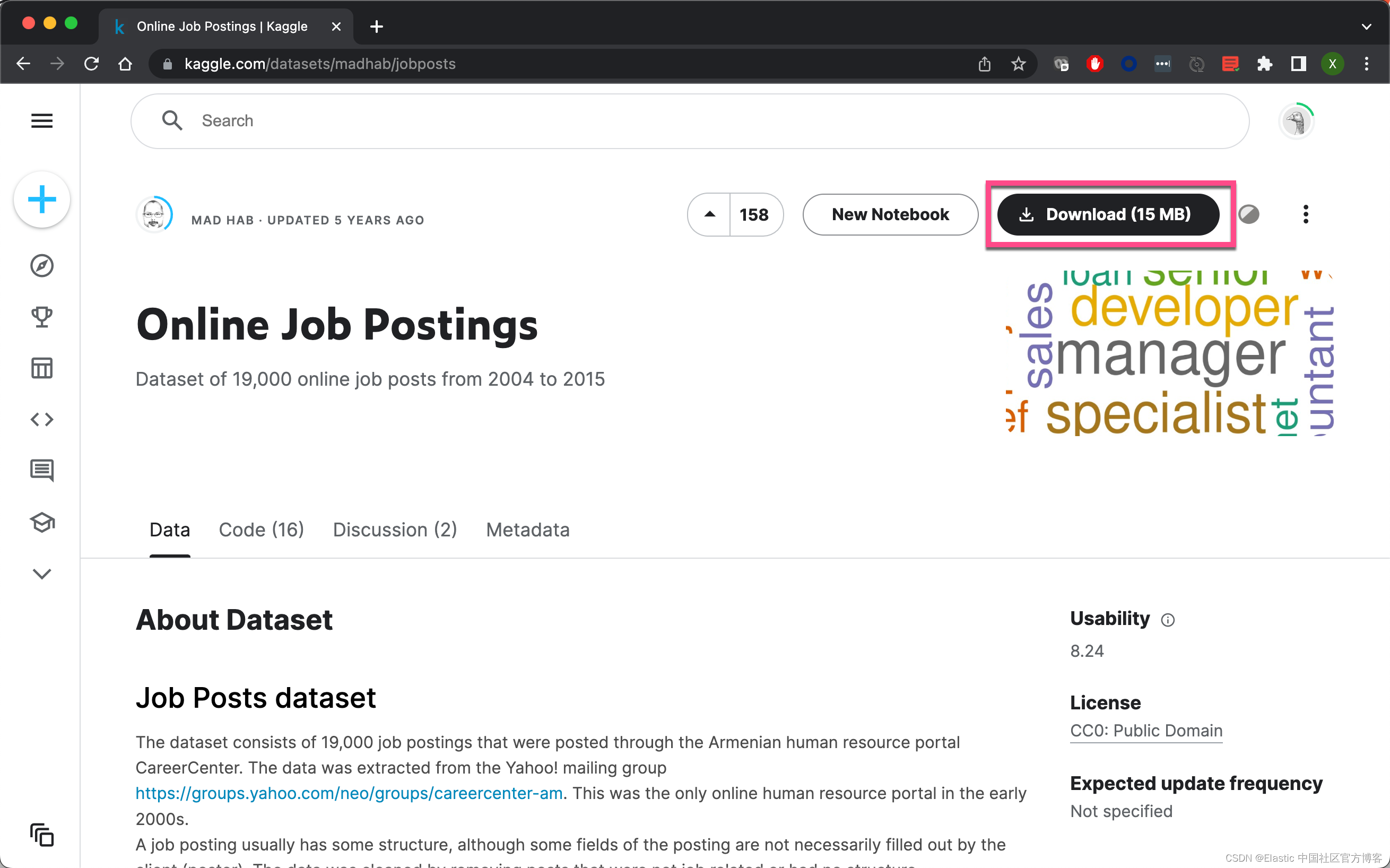
下载后我们解压缩后,文件名为:data job posts.csv。它的每个文档的 jobpost 如下:

如上所示,显然它是一个非常长的一个文字描述。在搜索的时候,我们可以通过把这个字段按照 text 的方式写入,并对它进行分词。通过正常的搜索手段来对它进行搜索。我们也可以把这个字段按照 dense_vector 字段的方法来进行写入。在写入的时候,我们需要调用模型把这个字段进行向量化,并把最终的向量写入到 Elasticsearch 中。
在进行下面的操作之前,我们首先来创建如下的一个索引:
PUT posting
{
"mappings": {
"properties": {
"vector": {
"type": "dense_vector",
"dims": 384,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"index": false
}
}
},
"company": {
"type": "keyword",
"index": false
},
"location": {
"type": "keyword",
"index": false
},
"salary": {
"type": "keyword",
"index": false
},
"job_description": {
"type": "keyword",
"index": false
}
}
}
}如上所示,我们的 vector 字段是一个 dense_vector 字段。
使用 Python 写入数据并进行搜索
接下来,我们使用 Python 把下载数据的向量写入到 Elasticsearch 中,并对它的数据进行搜索。如果你还不知道如何通过 Python 把数据写入到 Elasticsearch 中,请参考我的文章 “Elasticsearch:使用最新的 Python client 8.0 来创建索引并搜索”。我们创建如下的文件:
semantics_search.py
import pandas as pd
import numpy as np
import json
import os
import uuid
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
import elasticsearch
from elasticsearch import Elasticsearch
from elasticsearch import helpers
from tqdm.auto import tqdm
tqdm.pandas()
df = pd.read_csv("data job posts.csv")
class Tokenizer(object):
def __init__(self):
self.model = SentenceTransformer('all-MiniLM-L6-v2')
def get_token(self, documents):
sentences = [documents]
sentence_embeddings = self.model.encode(sentences)
encod_np_array = np.array(sentence_embeddings)
encod_list = encod_np_array.tolist()
return encod_list[0]
token_instance = Tokenizer()
df = df.head(5000)
df = df.dropna(how='all')
length = len(list(df['Title'].unique()))
print(f"length = {length}")
df['vector'] = df['jobpost'].progress_apply(token_instance.get_token)
elk_data = df.to_dict("records")
es = Elasticsearch("https://elastic:-PU2n08Btnelw1=3XNio@localhost:9200",
ca_certs="/Users/liuxg/elastic0/elasticsearch-8.4.0/config/certs/http_ca.crt",
verify_certs=True)
es.ping()
for x in elk_data:
try:
_={
"title": x.get("Title", ""),
"company": x.get("Company", ""),
"location": x.get("Location", ""),
"salary": x.get("Salary", ""),
"vector": x.get("vector", ""),
"job_description": x.get("JobDescription", ""),
}
es.index(index = 'posting', document =_)
except Exception as e:pass
INPUT = input("Enter the Input Query: ")
token_vector = token_instance.get_token(INPUT)
# print(token_vector)
res = es.knn_search(index = 'posting', source = [ "title", "job_description" ],
knn = {
"field": "vector",
"k": 5,
"num_candidates": 10,
"query_vector": token_vector
})
title = [x['_source'] for x in res['hits']['hits']]
for item in title:
print(item)在上面的代码中,请注意:
- 你需要根据自己的配置修改 https://elastic:-PU2n08Btnelw1=3XNio@localhost:9200 里的用户名及密码
- 你需要把 /Users/liuxg/elastic0/elasticsearch-8.4.0/config/certs/http_ca.crt 替换为自己的证书路径
- 你需要把解压缩后的文件 data job posts.csv 置于当前运行的目录下
- 在本次练习中使用了前面的 5000 个文档,你可以使用随机的方法抽取其中的一部分文档,或者使用全部的文档
运行上面的代码,我们可以看到如下的结果:
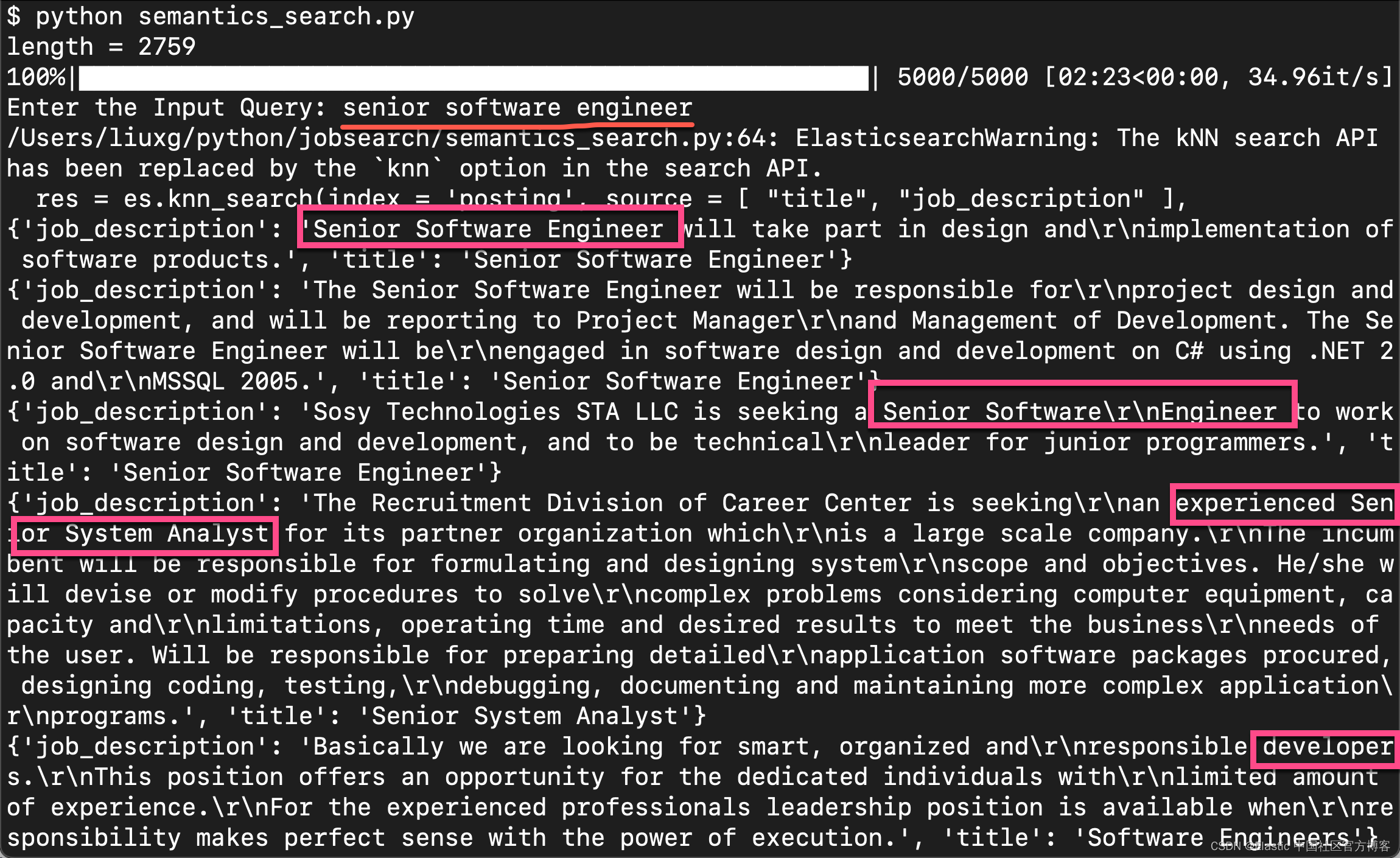
当我们输入 senior software engineers 时。我们可以看到上面的搜索结果。显然它是和我们的结果是匹配的。
我们可以接着做更多的搜索,不过,这次,我们在之前已经写入 posting 索引了,所以,我们不必要再进行写入了。直接搜索就好了。我们修改上面的应用如下:
semantics_search.py
import pandas as pd
import numpy as np
import json
import os
import uuid
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
import elasticsearch
from elasticsearch import Elasticsearch
from elasticsearch import helpers
# from tqdm.auto import tqdm
# tqdm.pandas()
# df = pd.read_csv("data job posts.csv")
class Tokenizer(object):
def __init__(self):
self.model = SentenceTransformer('all-MiniLM-L6-v2')
def get_token(self, documents):
sentences = [documents]
sentence_embeddings = self.model.encode(sentences)
encod_np_array = np.array(sentence_embeddings)
encod_list = encod_np_array.tolist()
return encod_list[0]
token_instance = Tokenizer()
# df = df.head(5000)
# df = df.dropna(how='all')
# length = len(list(df['Title'].unique()))
# print(f"length = {length}")
# df['vector'] = df['jobpost'].progress_apply(token_instance.get_token)
# elk_data = df.to_dict("records")
es = Elasticsearch("https://elastic:-PU2n08Btnelw1=3XNio@localhost:9200",
ca_certs="/Users/liuxg/elastic0/elasticsearch-8.4.0/config/certs/http_ca.crt",
verify_certs=True)
es.ping()
# for x in elk_data:
# try:
# _={
# "title": x.get("Title", ""),
# "company": x.get("Company", ""),
# "location": x.get("Location", ""),
# "salary": x.get("Salary", ""),
# "vector": x.get("vector", ""),
# "job_description": x.get("JobDescription", ""),
# }
# es.index(index = 'posting', document =_)
# except Exception as e:pass
INPUT = input("Enter the Input Query: ")
token_vector = token_instance.get_token(INPUT)
res = es.knn_search(index = 'posting', source = [ "title", "job_description" ],
knn = {
"field": "vector",
"k": 5,
"num_candidates": 10,
"query_vector": token_vector
})
title = [x['_source'] for x in res['hits']['hits']]
for item in title:
print(item)运行上面的代码:

在上面,我们输入一个完整的句子 I am looking for a senior account。搜索的结果和我们想要的还说蛮相近的。