python读取json格式文件大量数据,以及python字典和列表嵌套用法详解
1.Python读取JSON报错:JSONDecodeError:Extra data:line 2 column 1
错误原因:
- JSON数据中数据存在多行,在读取数据时,不能够单单用open(),应利用for循环:
- 可能存在换行符问题导致的
大量数据,里面有多行多列,出现类似标题报错
raise JSONDecodeError(“Extra data”, s, end)
json.decoder.JSONDecodeError: Extra data: line 2 column 1 (char 104)
解决方法:
可以逐行读取,然后再处理成列表
json_data=[]
for line in open('多列表.json', 'r', encoding='utf-8'):
json_data.append(json.loads(line))import json
# 由于文件中有多行,直接读取会出现错误,因此一行一行读取
file = open("papers.json", 'r', encoding='utf-8')
papers = []
for line in file.readlines():
dic = json.loads(line)
papers.append(dic)
print(len(papers))2.python 如何读取列表中字典的value值
list = [{"name": "推荐食谱", "1": "症状", "name1": "浑身忽冷忽热"}, {"name": "绿豆薏米饭"}, {"name": "芝麻"}]
res = [item[key] for item in list for key in item]
print(res)
for item in list:
for key in item:
print(item[key])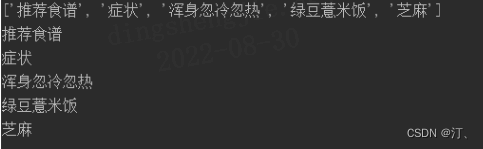
list = [{"name": "推荐食谱", "1": "症状", "name1": "浑身忽冷忽热"}, {"name": "绿豆薏米饭"}, {"name": "芝麻"}]
res = [item[key] for item in list for key in item]
print(res)
for item in list:
for k,v in item.items():
print(k,v)
获取字典的key和value
以迭代的方式,默认情况下,字典迭代的是key,key相当于item里面的[0]位置,value是[1]位置
a.items()key=a.items[0]value=a.items[1]
for item in dict.items():
key = item[0]
value = item[1]打印每一个key
a = {'a':1,'b':2,'c':3}
for item in a.items():
print(item[0])
>>>
a
b
c打印每一个value
a = {'a':1,'b':2,'c':3}
for item in a.items():
print(item[1])
>>>
1
2
3不通过dict.item()这个函数,直接利用默认迭代是key这个特性,可以直接迭代
>>> dict = {'a': 1, 'b': 2, 'c': 3}
>>> for key in dict:
... print(key)
...
a
c
b第二种方式,如果要迭代value,可以用a.values(),这个是找值,找键是a.keys()
a = {'a':1,'b':2,'c':3}
for value in a.values():
print(value)
>>>
1
2
3
for key in a.keys():
print(key)
>>>
a
b
c第三种,如果要同时迭代key和value,可以用for k, v in d.items()。
a = {'a':1,'b':2,'c':3}
for k,v in a.items():
print(k)
print(v)
>>>
a
1
b
2
c
3输出全部的key和value,但不是list格式
a = {'a':1,'b':2,'c':3}
print(a.values())
>>> dict_values([1, 2, 3])
print(a.keys())
>>>dict_keys(['a', 'b', 'c'])如果要变成list列表,转换类型即可
list(a.keys())
>>>['a', 'b', 'c']3.python字典和列表嵌套用法详解
3.1 列表(List)
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
特点就是:可重复,类型可不同
常用方式
创建一个列表,只要把逗号分隔的不同数据项使用方括号括起来即可。如下所示:
list1 = ['apple', 'banana', 2008, 2021]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
### 向list中增加元素
list1.append(3) ## ['apple', 'banana', 2008, 2021, 3]
### 使用extend用来连接list
list1.extend([7, 8]) ##['apple', 'banana', 2008, 2021, 3, 7, 8]
### insert 将单个元素插入到list中
list3.insert(2, 'q') ##['a', 'b', 'q', 'c', 'd']
### 获取列表的长度
print(len(list1)) ## 5
### 遍历list
for name in list1:
print(name)extend(扩展)与append(追加)的看起来类似,但实际上完全不同。
- extend接受一个参数,这个参数总是一个list,并且把这个list中每个元素添加到原list中。
- append接受一个参数,这个参数可以是任何数据类型,并且简单地追加到list的尾部。
3.2字典(dictionary)
字典是另一种可变容器模型,且可存储任意类型对象。
- 键(key)必须是唯一的,可以用数字,字符串或元组充当,而用列表就不行
- 同一个键出现两次,最后出现的会更新前一个的值。
字典的每个键值 key=>value 对用冒号:分割,每个键值对之间用逗号,分割,整个字典包括在花括号 {} 中 ,格式如下所示:
>>> dict = {'a': 1, 'b': 2, 'b': '3'}
>>> print(dict)
{'a': 1, 'b': '3'}
### 访问字典里的值
>>> print(dict['b'])
3
### 更新和添加字典
>>> dict['a'] = 8
>>> dict['c'] = 'cc'
>>> print(dict['a'])
8
>>> print(dict['c'])
cc
### 删除字典元素
>>> del dict['a']
>>> print(dict)
{'b': '3', 'c': 'cc'}
>>> dict.clear() # 清空字典所有条目
>>> del dict # 删除字典3.3组合使用
列表里也能嵌套列表,列表里能嵌套字典
字典里能嵌套字典,字典里也能嵌套列表
这是非常灵活的。
3.3.1 列表嵌套列表
这个用得不多,相对也比较简单,直接看例子:
### 打印输出字符 5
l = [[1,2],[3,4],[[5,6],[7,8]]]
>>> print(l[2][0][0])
5
### 将嵌套列表转为非嵌套列表
>>> a = [[1,2,3],[4,5,6],[7],[8,9]]
>>> for i in a:
... t.extend(i)
...
>>> print(t)
[1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 7, 8, 9]*3.3.2列表嵌套字典
在列表中嵌套字典应该是最常用的方式了,直接举例说明:
li = [{'a': 1}, {'b': 2}, {'c': 3}]
###(1) 循环获取字典里每个键值对:
>>> for i in range(len(li)):
... for k, v in li[i].items():
... print(k, v)
...
a 1
b 2
c 3
###(2) 获取字典里每个键值对(元组数据类型):
>>> for i in range(len(li)):
... for j in li[i].items():
... print(j)
...
('a', 1)
('b', 2)
('c', 3)
### 可以看到第二种获取到的键值对是 元组数据类型。3.3.3字典嵌套字典
字典嵌套字典:字符串作为key,字典作为value:
>>> s={'a':{0:'no',1:{'f':{0: 'no', 1: 'maybe'}}},'b':{}} #构造字典
>>> s['a'][0] # 取值
'no'
>>> s['a'][1]
{'f': {0: 'no', 1: 'maybe'}}
>>> s['a'][1]['f'][1]
'maybe'### 字典嵌套字典
dict = {
'192.168.1.1':{'cpu':'0.23','内存':'16','硬盘':'500'},
'192.168.1.2':{'cpu':'3.22','内存':'64','硬盘':'700'},
'192.168.1.3':{'cpu':'1.99','内存':'32','硬盘':'800'},
}
### for遍历
>>> for k,v in dict.items():
... print('\n',k,end=': ')
... for x,y in v.items():
... print(x,y,end=' ')
...
192.168.1.1: cpu 0.23 内存 16 硬盘 500
192.168.1.2: cpu 3.22 内存 64 硬盘 700
192.168.1.3: cpu 1.99 内存 32 硬盘 8003.3.4 字典嵌套列表
那么如何在字典里嵌套列表呢?
字典嵌套列表:字符串作为key,列表作为value。
### 字典嵌套列表
dict = {
'水果':['苹果','香蕉','橘子'],
'动物':['狮子','老虎','大象'],
'语言':['中文','英文','日语'],
}
### 访问字典里的值
>>> print(dict['水果'])
['苹果', '香蕉', '橘子']
### 访问列表里的值
>>> print(dict['语言'][1])
英文
### 循环打印输出看效果
>>> for k, v in dict.items():
... print('\n', k, end=':')
... for x in v:
... print(x,end=' ')
...
水果:苹果 香蕉 橘子
动物:狮子 老虎 大象
语言:中文 英文 日语3.3.5 嵌套什么时候用
比如希望存储年级前100名学生的各科成绩时,由于学生是由成绩进行排名的,列表是有序的数据类型,而字典是无序的数据类型,所以外面会用列表去存储所有的数据。
而对于学生的各科成绩来说,看重的不是有序,而是需要科目和成绩一一对应,这才是最重要的。或者说当我想获取到年纪第十名同学的语文成绩,那么可以直接去获取到列表对应的索引,和字典里对应的key就可以了,这样就能得到相应的value。
至于嵌套中的排序用法
4. 实际案例:列表嵌套字典
数据格式:
{"id": "538f267d2e6fba48b1286fb7f1499fe7", "title": "一种信号的发送方法及基站、用户设备", "assignee": "华为技术有限公司", "abstract": "一种信号的发送方法及基站、用户设备。在一个子帧中为多个用户设备配置的参考信号的符号和数据的符号在子帧中的时域位置关系满足前提一和前提二;前提一为,将每个用户设备的参考信号所需的资源包括在多个参考信号的符号中,前提二为以下条件中的至少一个:将每个用户设备的多个参考信号设置在每个用户设备的数据的符号之前的参考信号的符号中,和/或每个用户设备的数据的符号之后的参考信号的符号中,从而有效地节省了发送参考信号的开销,满足了资源设计的需求;且部分或全部用户设备可在多个参考信号的符号中包含其参考信号,使该用户设备的解调性能得到进一步改善。", "label_id": 0}
{"id": "635a7d4b6358b6ff24a324bb871505db", "title": "一种5G通讯电缆故障监控系统", "assignee": "中铁二十二局集团电气化工程有限公司", "abstract": "本发明公开了一种5G通讯电缆故障监控系统,包括信号采样模块、补偿反馈模块,所述信号采样模块对5G通讯电缆信号采样,信号采样模块连接补偿反馈模块,补偿反馈模块运用三极管Q1、电容C3和电感L2、电容C2组成高频补偿电路展宽信号的通频带,为了进一步保证滤除扰动信号的准确性,避免异常高电平信号击穿电感L3,运用三极管Q4检测运放器AR2输出端信号,将异常高电平信号经电阻R14分压,最后运用运放器AR3同相放大信号,三极管Q5进一步三极管运放器AR3输出信号、三极管Q3发射极信号电位差,运用三极管Q2反馈信号至运放器AR2输出端,对运放器AR3输出信号峰值进一步校准,5G通讯电缆故障监控系统终端能够及时对5G通讯电缆故障及时响应。", "label_id": 0}
代码一:
import json
import pandas as pd
# json_data=[]
# for line in open('test_data.json', 'r', encoding='utf-8'):
# json_data.append(json.loads(line))
# print(json_data)
# 由于文件中有多行,直接读取会出现错误,因此一行一行读取
file = open("test_data.json", 'r', encoding='utf-8')
papers = []
for line in file.readlines():
dic = json.loads(line)
papers.append(dic)
res = [v[key] for v in papers for key in v] #将字典数值放在,一个列表
# print(res)
#读取后不含字典键值
id=[]
case=[]
labels=[]
for v in papers:
id.append(v['id'])
case.append([v['title'],v['assignee'],v['abstract']])
labels.append(v['label_id'])
# print(case)
# print(labels)
final_data=pd.DataFrame(columns = ['id','content','label'])
final_data['id']=id
final_data['content']=case
final_data['label']=labels
final_data.to_csv("output.txt",sep='\t',index=False,index_label=False,header=False)
#合并在一个list中
# for v in papers:
# case=[]
# for key in v:
# print(v[key])
# if key=="title" or key=="assignee" or key=="abstract" :
# case.append(v[key])
# print(case)代码二推荐:
import json
import pandas as pd
json_data=[]
id=[]
content=[]
label=[]
for line in open("test_data.json",'r',encoding='utf8'):
json_data.append(json.loads(line))
# print('这是文件中的json数据:',json_data)
# print('这是读取到文件数据的数据类型:', type(json_data))
for v in json_data:
# print(v)
# 取出特定数据
# print("%s,%s"%(v['id'],v['title']))
id.append(v['id'])
content.append([v['title'],v['assignee'],v['abstract']])
label.append(v['label_id'])
# print(id)
# print(content)
# print(label)
final_data=pd.DataFrame(columns = ['id','content','label'])
final_data['id']=id
final_data['content']=content
final_data['label']=label
print(final_data)输出样式:
0 538f267d2e6fba48b1286fb7f1499fe7 [一种信号的发送方法及基站、用户设备, 华为技术有限公司, 一种信号的发送方法及基站、用户设... 0
1 538f267d2e6fba48b1286fb7f1499fe7 [一种信号的发送方法及基站、用户设备, 华为技术有限公司, 一种信号的发送方法及基站、用户设... 0
2 635a7d4b6358b6ff24a324bb871505db [一种5G通讯电缆故障监控系统, 中铁二十二局集团电气化工程有限公司, 本发明公开了一种5G... 0存在括号进行改进: 改为相加即可:列表list合并的4种方法
方法一:
import json
import pandas as pd
json_data=[]
id=[]
content=[]
label=[]
for line in open("test_data.json",'r',encoding='utf8'):
json_data.append(json.loads(line))
# print('这是文件中的json数据:',json_data)
# print('这是读取到文件数据的数据类型:', type(json_data))
for v in json_data:
# print(v)
# 取出特定数据
# print("%s,%s"%(v['id'],v['title']))
id.append(v['id'])
content.append(v['title']+v['assignee']+v['abstract'])
label.append(v['label_id'])
# print(id)
# print(content)
# print(label)
final_data=pd.DataFrame(columns = ['id','content','label'])
final_data['id']=id
final_data['content']=content
final_data['label']=label
print(final_data)*方法二:
import json
import pandas as pd
# json_data=[]
# for line in open('test_data.json', 'r', encoding='utf-8'):
# json_data.append(json.loads(line))
# print(json_data)
# 由于文件中有多行,直接读取会出现错误,因此一行一行读取
file = open("test_data.json", 'r', encoding='utf-8')
papers = []
for line in file.readlines():
dic = json.loads(line)
papers.append(dic)
res = [v[key] for v in papers for key in v] #将字典数值放在,一个列表
# print(res)
#读取后不含字典键值
id=[]
case=[]
labels=[]
for v in papers:
id.append(v['id'])
case.append(v['title']+v['assignee']+v['abstract'])
labels.append(v['label_id'])
# print(case)
# print(labels)
final_data=pd.DataFrame(columns = ['id','content','label'])
final_data['id']=id
final_data['content']=case
final_data['label']=labels
final_data.to_csv("train_input.txt",sep='\t',index=False,index_label=False,header=False)
print("数据导出")
#合并在一个list中
# for v in papers:
# case=[]
# for key in v:
# print(v[key])
# if key=="title" or key=="assignee" or key=="abstract" :
# case.append(v[key])
# print(case)
5. 补充列表list合并的4种方法
5.1两个列表合并
总结:
第一种方法思路清晰,就是运算符的重载
第二种方法比较简洁,但会覆盖原始list
第三种方法功能强大,可以将一个列表插入另一个列表的任意位置
第四种方法直接把一个元素,整个放入到另一个列表中
方法1:直接使用“+”合并列表
alist = [1,2,3]
blist = ['www','pythontab.com']
clist = alist + blist
dlist = blist + alist
print(clist)
print(dlist)
[1, 2, 3, 'www', 'pythontab.com']方法2:使用extend方法
alist = [1,2,3]
blist = ['www','pythontab.com']
alist.extend(blist)
print(alist)注意:使用extend方法会直接修改list数据,extend方法的返回值为None,所以直接打印alist
方法3:使用切片
alist = [1,2,3]
blist = ['www','pythontab.com']
alist[len(alist):len(alist)] = blist
print(alist)注意:len(alist)表示要将blist插入alist中的位置,例如
alist = [1,2,3]
blist = ['www','pythontab.com']
alist[1:1] = blist
print(alist)
[1,'www','pythontab.com',2,3]方法4:使用append方法
a.append(b)将b看成list一个元素和a合并成一个新的list,它和前面的方法的输出结果不同
alist = [1,2,3]
blist = ['www','pythontab.com']
alist.append(blist)
print(alist)
[1, 2, 3, ['www', 'pythontab.com']]5.2 python 中如何把嵌套的列表合并成一个列表?
参考链接:
python 中如何把嵌套的列表合并成一个列表?_起不好名字就不起了的博客-CSDN博客_python列表套列表变成一个列表
5.3 python-实用的函数-将多个列表合并为一个
抓数据的的时候把数据存在了多个列表里,做数据清洗的时候需要将多个列表中的元素合并为一个列表
# 将多个列表合并为一个列表
def get_sublist_all_elements(input_lst):
out_lst = []
for item in input_lst:
out_lst.extend(item)
return out_lst
a = ["455","4343","4535"]
b = ["fdsfs","fdsfsfs"]
c = [a,b]
print(c)
print(get_sublist_all_elements(c))[['455', '4343', '4535'], ['fdsfs', 'fdsfsfs']]
['455', '4343', '4535', 'fdsfs', 'fdsfsfs']PS: extend实例
aList = [123, 'xyz', 'zara', 'abc', 123];
bList = [2009, 'manni'];
aList.extend(bList)
输出:
[123, 'xyz', 'zara', 'abc', 123, 2009, 'manni']