linux 函数 堆栈
1、关于栈
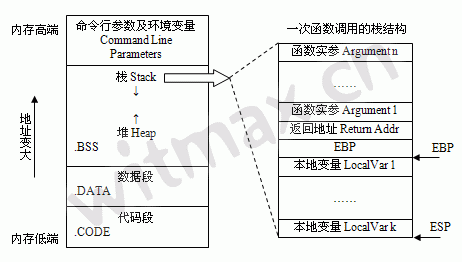
对于程序,编译器会对其分配一段内存,在逻辑上可以分为代码段,数据段,堆,栈
- 代码段:保存程序文本,指令指针EIP就是指向代码段,可读可执行不可写
- 数据段:保存初始化的全局变量和静态变量,可读可写不可执行
- BSS:未初始化的全局变量和静态变量
- 堆(Heap):动态分配内存,向地址增大的方向增长,可读可写可执行
- 栈(Stack):存放局部变量,函数参数,当前状态,函数调用信息等,向地址减小的方向增长,非常非常重要,可读可写可执行。如下图所示:
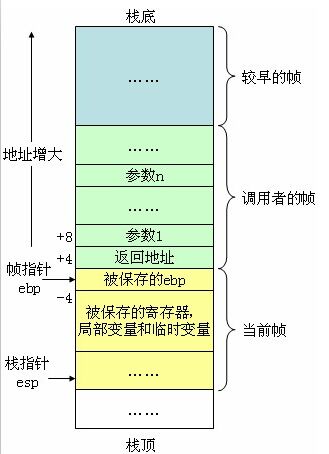
首先必须明确一点也是非常重要的一点,栈是向下生长的,所谓向下生长是指从内存高地址->低地址的路径延伸,那么就很明显了,栈有栈底和栈顶,那么栈顶的地址要比栈底低。对x86体系的CPU而言,其中
—> 寄存器ebp(base pointer )可称为“帧指针”或“基址指针”,其实语意是相同的。
—> 寄存器esp(stack pointer)可称为“ 栈指针”。
要知道的是:
—> ebp 在未受改变之前始终指向栈帧的开始,也就是栈底,所以ebp的用途是在堆栈中寻址用的。
—> esp是会随着数据的入栈和出栈移动的,也就是说,esp始终指向栈顶。
见下图,假设函数A调用函数B,我们称A函数为"调用者",B函数为“被调用者”则函数调用过程可以这么描述:
(1)先将调用者(A)的堆栈的基址(ebp)入栈,以保存之前任务的信息。
(2)然后将调用者(A)的栈顶指针(esp)的值赋给ebp,作为新的基址(即被调用者B的栈底)。
(3)然后在这个基址(被调用者B的栈底)上开辟(一般用sub指令)相应的空间用作被调用者B的栈空间。
(4)函数B返回后,从当前栈帧的ebp即恢复为调用者A的栈顶(esp),使栈顶恢复函数B被调用前的位置;然后调用者A再从恢复后的栈顶可弹出之前的ebp值(可以这么做是因为这个值在函数调用前一步被压入堆栈)。这样,ebp和esp就都恢复了调用函数B前的位置,也就是栈恢复函数B调用前的状态。
这个过程在AT&T汇编中通过两条指令完成,即:
leave
ret
这两条指令更直白点就相当于:
mov %ebp , %esp
pop %ebp
2、简单实例
开发测试环境:
Linux ubuntu 3.11.0-12-generic
gcc版本:gcc version 4.8.1 (Ubuntu/Linaro 4.8.1-10ubuntu8)
下面我们用一段代码说明上述过程:
int bar(int c, int d)
{
int e = c + d;
return e;
}
int foo(int a, int b)
{
return bar(a, b);
}
int main(void)
{
foo(2, 3);
return 0;
}
gcc -g Code.c ,加上-g,那么用objdump -S a.out 反汇编时可以把C代码和汇编代码穿插起来显示,这样C代码和汇编代码的对应关系看得更清楚。反汇编的结果很长,以下只列出我们关心的部分。
080483ed <bar>:
int bar(int c, int d)
{
80483ed: 55 push %ebp
80483ee: 89 e5 mov %esp,%ebp
80483f0: 83 ec 10 sub $0x10,%esp
int e = c + d;
80483f3: 8b 45 0c mov 0xc(%ebp),%eax
80483f6: 8b 55 08 mov 0x8(%ebp),%edx
80483f9: 01 d0 add %edx,%eax
80483fb: 89 45 fc mov %eax,-0x4(%ebp)
return e;
80483fe: 8b 45 fc mov -0x4(%ebp),%eax
}
8048401: c9 leave
8048402: c3 ret
08048403 <foo>:
int foo(int a, int b)
{
8048403: 55 push %ebp
8048404: 89 e5 mov %esp,%ebp
8048406: 83 ec 08 sub $0x8,%esp
return bar(a, b);
8048409: 8b 45 0c mov 0xc(%ebp),%eax
804840c: 89 44 24 04 mov %eax,0x4(%esp)
8048410: 8b 45 08 mov 0x8(%ebp),%eax
8048413: 89 04 24 mov %eax,(%esp)
8048416: e8 d2 ff ff ff call 80483ed <bar>
}
804841b: c9 leave
804841c: c3 ret
0804841d <main>:
int main(void)
{
804841d: 55 push %ebp
804841e: 89 e5 mov %esp,%ebp
8048420: 83 ec 08 sub $0x8,%esp
foo(2, 3);
8048423: c7 44 24 04 03 00 00 movl $0x3,0x4(%esp)
804842a: 00
804842b: c7 04 24 02 00 00 00 movl $0x2,(%esp)
8048432: e8 cc ff ff ff call 8048403 <foo>
return 0;
8048437: b8 00 00 00 00 mov $0x0,%eax
}
804843c: c9 leave
804843d: c3 ret
整个程序的执行过程是main调用foo,foo调用bar,我们用gdb跟踪程序的执行,直到bar函数中的int e = c + d;语句执行完毕准备返回时,这时在gdb中打印函数栈帧,因为此时栈已经生长到最大。
ZP1015@ubuntu:~/Desktop/c/Machine_Code$ gdb a.out
GNU gdb (GDB) 7.6.1-ubuntu
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i686-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /home/ZP1015/Desktop/c/Machine_Code/a.out...done.
(gdb) start
Temporary breakpoint 1 at 0x8048423: file Code.c, line 14.
Starting program: /home/ZP1015/Desktop/c/Machine_Code/a.out
Temporary breakpoint 1, main () at Code.c:14
14 foo(2, 3);
(gdb) s
foo (a=2, b=3) at Code.c:9
9 return bar(a, b);
(gdb) s
bar (c=2, d=3) at Code.c:3
3 int e = c + d;
(gdb) disas
Dump of assembler code for function bar:
0x080483ed <+0>: push %ebp
0x080483ee <+1>: mov %esp,%ebp
0x080483f0 <+3>: sub $0x10,%esp
=> 0x080483f3 <+6>: mov 0xc(%ebp),%eax
0x080483f6 <+9>: mov 0x8(%ebp),%edx
0x080483f9 <+12>: add %edx,%eax
0x080483fb <+14>: mov %eax,-0x4(%ebp)
0x080483fe <+17>: mov -0x4(%ebp),%eax
0x08048401 <+20>: leave
0x08048402 <+21>: ret
End of assembler dump.
(gdb) si
0x080483f6 3 int e = c + d;
(gdb)
0x080483f9 3 int e = c + d;
(gdb)
0x080483fb 3 int e = c + d;
(gdb)
4 return e;
(gdb)
5 }
(gdb) bt
#0 bar (c=2, d=3) at Code.c:5
#1 0x0804841b in foo (a=2, b=3) at Code.c:9
#2 0x08048437 in main () at Code.c:14
(gdb) info registers
eax 0x5 5
ecx 0xbffff724 -1073744092
edx 0x2 2
ebx 0xb7fc4000 -1208205312
esp 0xbffff658 0xbffff658
ebp 0xbffff668 0xbffff668
esi 0x0 0
edi 0x0 0
eip 0x8048401 0x8048401 <bar+20>
eflags 0x206 [ PF IF ]
cs 0x73 115
ss 0x7b 123
ds 0x7b 123
es 0x7b 123
fs 0x0 0
gs 0x33 51
(gdb) x/20x $esp
0xbffff658: 0x0804a000 0x08048492 0x00000001 0x00000005
0xbffff668: 0xbffff678 0x0804841b 0x00000002 0x00000003
0xbffff678: 0xbffff688 0x08048437 0x00000002 0x00000003
0xbffff688: 0x00000000 0xb7e2d905 0x00000001 0xbffff724
0xbffff698: 0xbffff72c 0xb7fff000 0x0000002a 0x00000000
(gdb)
下面从主函数开始,一步一步分析函数调用过程:
0804841d <main>:
int main(void)
{
804841d: 55 push %ebp
804841e: 89 e5 mov %esp,%ebp
8048420: 83 ec 08 sub $0x8,%esp
foo(2, 3);
8048423: c7 44 24 04 03 00 00 movl $0x3,0x4(%esp)
804842a: 00
804842b: c7 04 24 02 00 00 00 movl $0x2,(%esp)
8048432: e8 cc ff ff ff call 8048403 <foo>
要调用函数foo先要把参数准备好,第二个参数保存在esp+4指向的内存位置,第一个参数保存在esp指向的内存位置,可见参数是从右向左依次压栈的。然后执行call指令,这个指令有两个作用:
- foo函数调用完之后要返回到call的下一条指令继续执行,所以把call的下一条指令的地址0x8048437压栈,同时把esp的值减4
- 修改程序计数器eip,跳转到foo函数的开头执行。
int foo(int a, int b)
{
8048403: 55 push %ebp
8048404: 89 e5 mov %esp,%ebp
8048406: 83 ec 08 sub $0x8,%esp
return bar(a, b);
8048409: 8b 45 0c mov 0xc(%ebp),%eax
804840c: 89 44 24 04 mov %eax,0x4(%esp)
8048410: 8b 45 08 mov 0x8(%ebp),%eax
8048413: 89 04 24 mov %eax,(%esp)
8048416: e8 d2 ff ff ff call 80483ed <bar>
push %ebp指令把ebp寄存器的值压栈,同时把esp的值减4。这两条指令合起来是把原来ebp的值保存在栈上,然后又给ebp赋了新值。在每个函数的栈帧中,ebp指向栈底,而esp指向栈顶,在函数执行过程中esp随着压栈和出栈操作随时变化,而ebp是不动的,函数的参数和局部变量都是通过ebp的值加上一个偏移量来访问,例如foo函数的参数a和b分别通过ebp+8和ebp+12来访问。所以下面的指令把参数a和b再次压栈,为调用bar函数做准备,然后把返回地址压栈,调用bar函数:
080483ed <bar>:
int bar(int c, int d)
{
80483ed: 55 push %ebp
80483ee: 89 e5 mov %esp,%ebp
80483f0: 83 ec 10 sub $0x10,%esp
int e = c + d;
80483f3: 8b 45 0c mov 0xc(%ebp),%eax
80483f6: 8b 55 08 mov 0x8(%ebp),%edx
80483f9: 01 d0 add %edx,%eax
80483fb: 89 45 fc mov %eax,-0x4(%ebp)
return e;
80483fe: 8b 45 fc mov -0x4(%ebp),%eax
}
8048401: c9 leave
8048402: c3 ret
08048403 <foo>:
这次又把foo函数的ebp压栈保存,然后给ebp赋了新值,指向bar函数栈帧的栈底,通过ebp+8和ebp+12分别可以访问参数c和d。bar函数还有一个局部变量e,可以通过ebp-4来访问。所以后面几条指令的意思是把参数c和d取出来存在寄存器中做加法,计算结果保存在eax寄存器中,再把eax寄存器存回局部变量e的内存单元。bar函数有一个int型的返回值,这个返回值是通过eax寄存器传递的,所以首先把e的值读到eax寄存器中,然后执行leave指令,最后是ret指令。
在gdb中可以用bt命令和frame命令查看每层栈帧上的参数和局部变量,现在可以解释它的工作原理了:如果我当前在bar函数中,我可以通过ebp找到bar函数的参数和局部变量,也可以找到foo函数的ebp保存在栈上的值,有了foo函数的ebp,又可以找到它的参数和局部变量,也可以找到main函数的ebp保存在栈上的值,因此各层函数栈帧通过保存在栈上的ebp的值串起来了。
地址0x804841b处是foo函数的返回指令:
}
804841b: c9 leave
804841c: c3 ret
重复同样的过程,又返回到了main函数。
return 0;
8048437: b8 00 00 00 00 mov $0x0,%eax
}
804843c: c9 leave
804843d: c3 ret
整个函数执行完毕。
函数调用和返回过程中的需要注意这些规则:
- 参数压栈传递,并且是从右向左依次压栈。
- ebp总是指向当前栈帧的栈底。
- 返回值通过eax寄存器传递。
局部变量申请栈空间时的入栈顺序
在没有溢出保护机制下的编译时,我们可以发现,所有的局部变量入栈的顺序(准确来说是系统为局部变量申请内存中栈空间的顺序)是正向的,即哪个变量先申明哪个变量就先得到空间,
也就是说,编译器给变量空间的申请是直接按照变量申请顺序执行的。
在有溢出保护机制下的编译时,情况有了顺序上的变化,对于每一种类型的变量来说,栈空间申请的顺序都与源代码中相反,即哪个变量在源代码中先出现则后申请空间;而对不同的变量来说,申请的顺序也不同,有例子可以看出,int型总是在char的buf型之后申请,不管源代码中的顺序如何(这应该来源于编译器在进行溢出保护时设下的规定)。
推荐博文:
c函数调用过程原理及函数栈帧分析