Kaggle官方·数据科学比赛经验集;百度开源·飞桨图像数据标注高效工具;C++并发编程实践第2版·笔记;前沿论文 | ShowMeAI资讯日报

👀日报合辑 | 📆电子月刊 | 🔔公众号下载资料 | 🍩@韩信子
工具&框架
🚧 『Surge』快速的开源化学图生成器
https://github.com/StructureGenerator/surge
Surge 是一个基于 Nauty 软件包的化学结构生成器。给定分子式后,Surge 可以生成所有的异构体。Surge 作为命令行工具使用时,运行 surge -u XXX 将在0.1秒内生成几十万种异构体。

🚧 『MARLlib』面向研究和行业的通用 MARL 基准
https://github.com/Replicable-MARL/MARLlib
https://sites.google.com/view/marllib
Multi-Agent RLlib(MARLlib)是一个基于 Ray 及其工具包之一 RLlib 的多 Agent 强化学习基准。它为MARL研究界提供了一个统一的平台,用于开发和评估各种多代理环境中的新想法。MARLlib有四个核心特点。
- 收集了大部分被社区广泛认可的现有MARL算法,并将它们统一在一个框架下。
- 提供了一个解决方案,使不同的多代理环境使用相同的接口与代理进行交互。
- 保证了训练和抽样过程的出色效率。
- 提供了训练的结果,包括学习曲线和针对每个任务和算法组合的预训练模型,并有微调的超参数来保证可信度。

🚧 『PaddleLabel』飞桨高效图像数据标注工具
https://github.com/PaddleCV-SIG/PaddleLabel
PaddleLabel 是基于飞桨 PaddlePaddle 各个套件的特性提供的配套标注工具,涵盖分类、检测、分割三种常见的计算机视觉任务的标注能力,具有手动标注和交互式标注相结合的能力。用户可以使用 PaddleLabel 方便快捷的标注自定义数据集,并将导出数据用于飞桨提供的其他套件的训练预测流程中。
整个 PaddleLabel 包括三部分:PaddleLabel-Frontend 是基于 React 和 Ant Design 构建的 PaddleLabel 前端,PaddleLabel-ML 是基于 PaddlePaddle 的自动和交互式标注的机器学习后端。以下分别是图像分类标注、目标检测标注、语义分割标注、实例分割标注的示例。

🚧 『Nucleus model server』与Cortex兼容的Python & TensorFlow模型服务器
https://github.com/cortexlabs/nucleus
Nucleus 是一个用于 TensorFlow 和通用 Python 模型的模型服务器,与 Cortex 集群、Kubernetes 集群和任何其他基于容器的部署平台兼容,也可以通过 docker compose 在本地运行。

🚧 『db2es』同步数据库到数据ES(ElasticSearch)
https://github.com/wangfan002/db2es
db2es是个同步数据库到数据ES的工具,具备下方所述的诸多优点。图片是接口展示 & 主要流程图。
- 对大数据量同步性能更出色,基于id或自增列进行多线程分批同步
- 完全由java语言进行开发,数据清洗更为简单
- 基于Sqlserver日志的CDC增量同步
- 支持同步完毕的邮件和钉钉通知
- 同步基于sql,支持mysql,sqlserver等关系型数据库
- 支持多ES集群

博文&分享
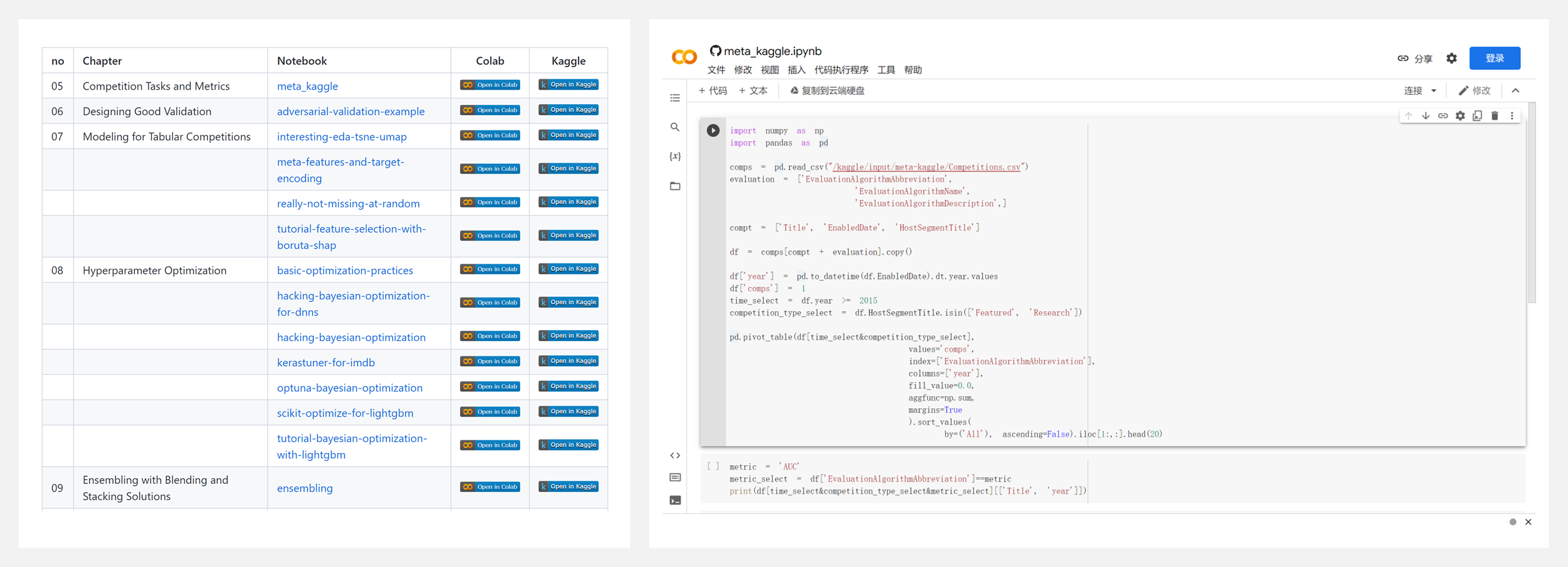
👍 『The Kaggle Book』Kaggle 数据分析与机器学习经验汇总(附超全代码) 1.4k Star
https://github.com/PacktPublishing/The-Kaggle-Book
Kaggle 作为知名的数据科学竞赛平台,吸引了世界各地数百万数据爱好者参与其中。参加 Kaggle 比赛,可以提高数据分析技能、与社区其他成员建立联系、并获得宝贵经验与职业发展助力。
本书由两位 Kaggle 大佬合著,并采访了 31 位 Kaggle大牛。书中汇集了比赛&数据科学项目所需的技术和技能,传授千锤百炼的建模策略和独家技巧,以及基于图像数据、表格数据、文本数据和强化学习来处理任务的通用技术,并掌握如何设计更好的验证方案并更轻松地使用不同的评估指标。

本书适合 Kaggle 用户和数据分析师/科学家,需要对数据科学主题和 Python 有基本的了解,并希望在 Kaggle 比赛中获得更好的成绩,或者在大厂求职成功。书籍所有代码都可在 Colab 或 Kaggle 查看和运行。
👍 『Cpp Concurrency in Action 2ed』C++并发编程实践第2版·笔记
https://github.com/downdemo/Cpp-Concurrency-in-Action-2ed
https://downdemo.github.io/Cpp-Concurrency-in-Action-2ed/
Anthony Williams写了《C++并发编程实践第2版》一书,这本书在 2012 年出版了第1版 ,并在 2019 年 2 月出版了第二版,本篇为其对应的笔记,覆盖线程支持库的基本用法和并发编程的设计思想与实践方法,原书作者介绍了C++17 标准库并行算法,笔记作者补充了 C++20 相关特性。

数据&资源
🔥 『FSL-Mate』少样本学习(FSL)资源集合
https://github.com/tata1661/FSL-Mate
FSL-Mate 少样本学习 (FSL) 的资源集合,目前由两部分组成:
- FewShotPapers:跟踪 FSL 研究进展的论文列表
- PaddleFSL : 基于 PaddlePaddle 的 FSL python 库

🔥 『Awesome Graph & SSL-based Recommendation』基于图/自监督学习的推荐相关资源大列表
https://github.com/juyongjiang/awesome-graph-self-supervised-learning-based-recommendation

研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.08.16 『计算机视觉』 Style Your Hair: Latent Optimization for Pose-Invariant Hairstyle Transfer via Local-Style-Aware Hair Alignment
- 2022.08.12 『自然语言处理』Mining Legal Arguments in Court Decisions
- 2022.07.08 『个性化联邦学习』pFL-Bench: A Comprehensive Benchmark for Personalized Federated Learning
- 2022.08.17 『计算机视觉』Incremental 3D Scene Completion for Safe and Efficient Exploration Mapping and Planning
⚡ 论文:Style Your Hair: Latent Optimization for Pose-Invariant Hairstyle Transfer via Local-Style-Aware Hair Alignment
论文时间:16 Aug 2022
领域任务:计算机视觉
论文地址:https://arxiv.org/abs/2208.07765
代码实现:https://github.com/taeu/style-your-hair
论文作者:Taewoo Kim, Chaeyeon Chung, Yoonseo Kim, Sunghyun Park, Kangyeol Kim, Jaegul Choo
论文简介:Editing hairstyle is unique and challenging due to the complexity and delicacy of hairstyle./由于发型的复杂性和微妙性,编辑发型是独特而具有挑战性的。
论文摘要:由于发型的复杂性和微妙性,编辑发型是独特的和具有挑战性的。尽管最近的方法大大改善了头发的细节,但当源图像的姿势与目标头发图像的姿势有很大不同时,这些模型往往会产生不理想的输出,从而限制了它们在现实世界的应用。HairFIT,一个姿势不变的发型转移模型,缓解了这一限制,但在保留精致的头发纹理方面仍然显示出不尽人意的质量。为了解决这些限制,我们提出了一个高性能的姿势不变的发型转移模型,该模型配备了潜在的优化和一个新提出的局部风格匹配损失。在StyleGAN2潜伏空间中,我们首先探索目标头发的姿势对齐潜伏代码,并基于局部风格匹配保留了详细的纹理。然后,我们的模型考虑到对齐的目标头发,对源头的遮挡进行涂抹,并混合这两幅图像以产生最终输出。实验结果表明,我们的模型在较大的姿势差异下转移发型和保留局部发型纹理方面具有优势。



⚡ 论文:Mining Legal Arguments in Court Decisions
论文时间:12 Aug 2022
领域任务:Argument Mining, Natural Language Processing,自然语言处理
论文地址:https://arxiv.org/abs/2208.06178
代码实现:https://github.com/trusthlt/mining-legal-arguments
论文作者:Ivan Habernal, Daniel Faber, Nicola Recchia, Sebastian Bretthauer, Iryna Gurevych, Indra Spiecker genannt Döhmann, Christoph Burchard
论文简介:Identifying, classifying, and analyzing arguments in legal discourse has been a prominent area of research since the inception of the argument mining field./识别、分类和分析法律话语中的论点,自论证挖掘领域成立以来一直是一个突出的研究领域。
论文摘要:自论证挖掘领域成立以来,识别、分类和分析法律话语中的论据一直是一个突出的研究领域。然而,在自然语言处理(NLP)研究者对法庭裁决中的论点进行建模和注释的方式与法律专家理解和分析法律论证的方式之间存在着重大差异。计算方法通常将论据简化为一般的前提和主张,而法律研究中的论据通常表现出丰富的类型,这对于深入了解特定的案件和一般的法律应用非常重要。我们解决了这个问题,并为推动该领域的发展做出了一些实质性的贡献。首先,我们为欧洲人权法院(ECHR)诉讼程序中的法律论据设计了一个新的注释方案,该方案深深植根于法律论证研究的理论和实践。其次,我们汇编并注释了373个法院判决的大型语料库(230万个标记和15000个注释的论证跨度)。最后,我们训练了一个论证挖掘模型,该模型在法律NLP领域的表现超过了最先进的模型,并提供了一个全面的基于专家的评估。所有的数据集和源代码都可以在 https://github.com/trusthlt/mining-legal-arguments 获取,在开放的法律许可下使用。


⚡ 论文:pFL-Bench: A Comprehensive Benchmark for Personalized Federated Learning
论文时间:8 Jun 2022
领域任务:Fairness, Personalized Federated Learning,公平,个性化联邦学习
论文地址:https://arxiv.org/abs/2206.03655
代码实现:https://github.com/alibaba/federatedscope
论文作者:Daoyuan Chen, Dawei Gao, Weirui Kuang, Yaliang Li, Bolin Ding
论文简介:Personalized Federated Learning (pFL), which utilizes and deploys distinct local models, has gained increasing attention in recent years due to its success in handling the statistical heterogeneity of FL clients./个性化的联合学习(pFL),利用和部署不同的本地模型,由于其在处理FL客户的统计异质性方面的成功,近年来获得了越来越多的关注。
论文摘要:个性化联合学习(pFL),利用和部署不同的本地模型,由于其在处理FL客户的统计异质性方面的成功,近年来获得了越来越多的关注。然而,对不同的pFL方法进行标准化评估和系统分析仍然是一个挑战。首先,高度不同的数据集、FL模拟设置和pFL实现阻碍了对pFL方法的快速和公平比较。其次,在各种实际情况下,如新客户的普及和资源有限的客户参与,pFL方法的有效性和稳健性都没有得到充分的探索。最后,目前的pFL文献在采用的评估和消融协议方面存在分歧。为了应对这些挑战,我们提出了第一个全面的pFL基准,pFL-Bench,以促进快速、可重复、标准化和彻底的pFL评估。该基准包含10多个不同应用领域的数据集,具有统一的数据分区和现实的异构设置;一个模块化和易于扩展的pFL代码库,具有20多个有竞争力的pFL基线实现;以及在容器化环境下对通用性、公平性、系统开销和收敛性的系统评估。我们强调了最先进的pFL方法的优点和潜力,并希望pFL-Bench能够进一步促进pFL的研究和广泛的应用,否则由于缺乏专门的基准而难以实现。该代码发布在 https://github.com/alibaba/FederatedScope/tree/master/benchmark/pFL-Bench


⚡ 论文:Incremental 3D Scene Completion for Safe and Efficient Exploration Mapping and Planning
论文时间:17 Aug 2022
领域任务:Efficient Exploration,计算机视觉
论文地址:https://arxiv.org/abs/2208.08307
代码实现:https://github.com/ethz-asl/ssc_exploration
论文作者:Lukas Schmid, Mansoor Nasir Cheema, Victor Reijgwart, Roland Siegwart, Federico Tombari, Cesar Cadena
论文简介:We further present an informative path planning method, leveraging the capabilities of our mapping approach and a novel scene-completion-aware information gain./我们进一步提出了一种信息性的路径规划方法,利用我们的映射方法的能力和一种新的场景完成意识的信息增益。
论文摘要:未知环境的探索是机器人学的一个基本问题,也是自主系统众多应用中的一个重要组成部分。探索未知环境的一个主要挑战是,机器人必须利用每个时间步骤的有限信息进行规划。虽然目前的大多数方法是依靠启发式方法和假设来规划基于这些部分观察的路径,但我们提出了一种新的方法,通过利用三维场景的完成,将深度学习整合到探索中,以实现知情、安全和可解释的探索制图和规划。我们的方法,SC-Explorer,使用一个新的增量融合机制和一个新提出的分层多层映射方法将场景完成结合起来,以保证机器人的安全和效率。我们进一步提出了一种信息性的路径规划方法,利用我们的映射方法的能力和一种新的场景完成意识的信息增益。虽然我们的方法是普遍适用的,但我们在微型飞行器(MAV)的使用案例中对其进行了评估。我们在仅使用移动硬件的高保真模拟实验中彻底研究了每个组件,并表明我们的方法与基线相比,可以将环境的覆盖率提高73%,而地图的精确度却降低得很少。即使场景完成度不包括在最终的地图中,我们也表明它们可以被用来指导机器人选择更有信息量的路径,使机器人的传感器对场景的测量速度加快了35%。我们将我们的方法作为开放源码提供。




我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
