通过划分法优化共识算法-“Scaling Replicated State Machines with Compartmentalization”详解
通过划分法优化共识算法-“Scaling Replicated State Machines with Compartmentalization”详解
- 一、背景
- 二、前提
- 三、实现
- 1. Proxy Leaders
- 2. Acceptor Grids
- 3. More Replicas
- 4. Leaderless Reads
- 5. Batchers
- 6. Unbatchers
- 四、总结
一、背景
目前,为了解决状态机复制算法在各种场景或者机制中的瓶颈,相关从业人员设计了大量状态机复制算法的变体。然而,这些变体在解决一个问题的同时往往会引出新的问题(如ChainPaxos为解决无额外通信的线性读,牺牲了读操作的响应时间),或引入更强的约束(Mencius为打破leader的瓶颈,要求更严格的网络环境,不允许消息的乱序)。论文针对这个问题,提出划分技术,打破了从业人员对MultiPaxos不能scale的观点。划分技术通过较为全面的方式,对SMR算法进行优化,而不明显对其它性能产生额外的牺牲。
论文主要对MultiPaxos划分后进行scaling优化,但需要注意的是,划分是一种思路,并不局限于MultiPaxos,可以推广到其它SMR算法,甚至可以应用到其它领域的算法中。
二、前提
首先,我们需要知道为什么从业者认为MultiPaxos不能scale。这里我们假设系统能容忍f个节点的崩溃故障。
-
为什么增加proposer的数量无法提高系统的性能:在MultiPaxos中,只有leader处理来自客户端的请求,和proposer的数量无直接关联,proposer数量的增加甚至可能会降低leader选举的效率;
-
为什么增加acceptor的数量无法提高系统的性能:增加acceptor会给leader处理消息产生更大的压力(leader需处理更多来自acceptor的消息),而且根据majority,每个acceptor始终都需要处理至少一半的命令,增加acceptor并不能分担其它acceptor的压力;
-
为什么增加replica的数量无法提高系统的性能:增加replica会给leader广播消息产生更大的压力(leader需发送给更多副本learn消息),且每个replica都需要提交且应用所有的命令,所以增加replica并不能分担其它replica的压力。
三、实现
论文主要提供了六种划分MultiPaxos的方式,如下图:

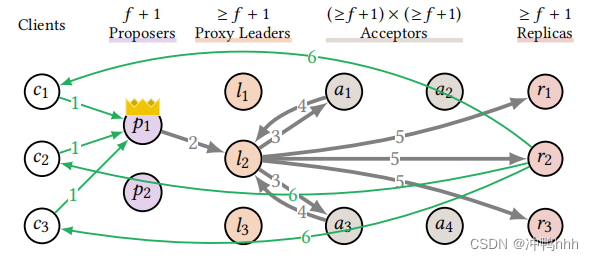
1. Proxy Leaders
众所周知,leader是MultiPaxos的瓶颈之一。在正常流程中,对于客户端提交的一个命令,leader至少需要发送f+1个accept消息给acceptor,接收f+1个来自acceptor
的accepted消息,并发送f+1个learn消息给replica,算上来自客户端的消息,一共需要处理3f+4个消息。而acceptor只需要处理2个消息,replica需要处理1或者2个消息(其中一个replica需要对客户端做出响应)。而且leader需要处理来自客户端的所有请求,这样的计算倾斜使leader很容易成为系统的瓶颈。
MultiPaxos采用唯一的leader的一个好处是,leader拥有global view,可以独断地将客户端发来的命令分配到日志的某一槽上,从而高效地对命令进行排序。如果增加leader的数量,MultiPaxos就会退化为最基础的Paxos流程,副本间需要对命令的排序也达成共识(即Prepare阶段,为某一个日志槽预定所有权),退化为两阶段提交,还可能产生冲突。论文认为leader的主要职责可以被分为排序以及广播,既然排序不能scale,那就scale广播,因此引出了proxy leader的概念。
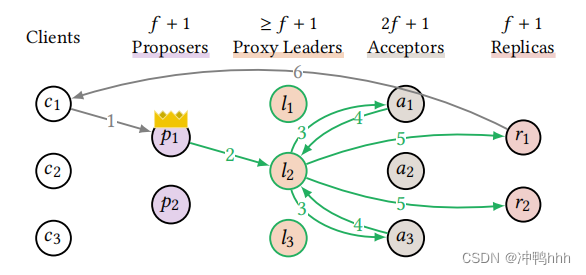
需要有至少f+1个节点承担proxy leader的角色,该角色分担了leader的广播职责,当接收到客户端的请求时,leader只需将该命令分配到一个日志槽上,之后通过轮询等方式将广播的任务分摊到proxy leader上。这样一来,对于一个命令,leader只需要处理两个消息,proxy leader则会均匀地承担3f+4个消息的处理。
很明显,关键路径上leader节点的任务量大大降低,通过增加proxy leader的方式可以将之前leader的广播负载均匀地分摊到多个节点上,因此proxy leader是可以scale的。
2. Acceptor Grids
一般来说,MultiPaxos的Prepare阶段和Accept阶段都需要收到majority(f+1)的acceptor的响应后才能继续进行,即read quorum以及write quorum都为f+1。一般认为,在容忍f个副本故障的系统中增加acceptor的数量并不能提升系统的性能。一是acceptor数量的增加会加剧leader处理消息的压力;二是acceptor数量的增加并不能降低acceptor的压力(在副本数为n的系统中,假设quorum为m(一般m会随着n的增加而等比增加),无论怎么增加acceptor的数量,每个acceptor都至少需要处理m/n的命令)。
假设一个系统的read quorum为r,write quorum为w,我们认为只要满足r + w > n,任意的read quorum和write quorum便有交集,即可保证每一次的读都能读到达成共识的值。当然,我们需要保证w > f以保证数据的一致性。majority为该情况下的一种特例。 然而,这种仅仅以数量或者比例约束quorum的方式,并不能通过增加acceptor的方式提高系统性能。
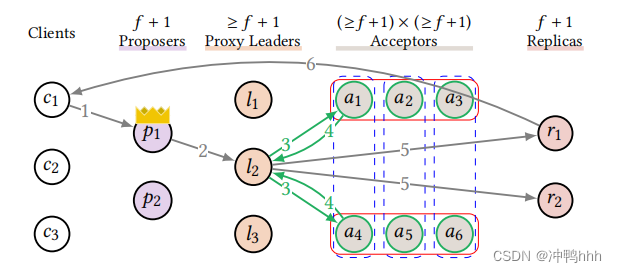
因此,论文采用flexible quorum的方式,将quorum构建成一个r × w的的网格(其中r和w都要大于f),任意列为write quorum,行为read quorum。通过网格中任意行和列都一定相交的特点,保证即使在r + w < n的情况下,任意的read quorum以及write quorum间都有交集。结构如下图所示:
这里感觉有点问题,
r × w中r和w应该是quorum的数量,而不是quorum中节点的数量,为什么还需要大于f?
实际上,
r + w > n通过数理逻辑的方式保证任意的read quorum以及write quorum间都有交集,此时quorum并不一定需要指定副本,只要满足数量即可;而Grid的方式则是通过网格结构的特点保证read quorum以及write quorum间有交集,但是每个quorum都是确定的。
基于网格的结构下,我们可以将新增加的acceptor组成write quorum加入网格中,这样,我们在增加acceptor数量的同时只需要增加read quorum,而不需要增加write quorum。由于每个acceptor至少处理w / n的命令,因此在Acceptor Grids的情况下增加acceptor的数量可以降低acceptor的压力,提高系统性能。
3. More Replicas
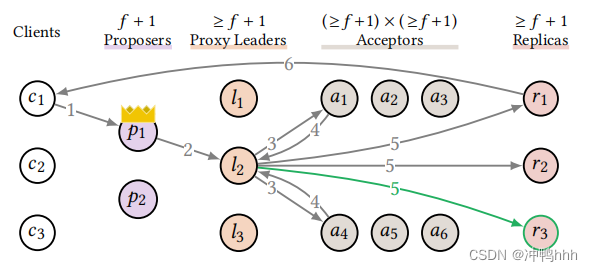
这个优化比较好理解,当replica应用完命令后,会有一个副本负责对客户端做出响应,因此每个replica响应给客户端的次数平均下来为1 / n。虽然增加replica的数量不能降低每个replica应用命令的数量,但是可以减少每个replica响应客户端的次数。
4. Leaderless Reads
MultiPaxos通过一个有序的日志序列保证操作的有序性,为了实现线性写,每个写操作都会被分配到一个日志槽中。实现线性读的关键是读操作能反映一个状态,最简单的实现方式是也将读操作分配到日志槽中并达成共识。然而,读操作并不会改变状态机的状态,通过对读操作分配日志槽并达成共识的方式开销太大,因此论文提出将write path和read path进行划分。
划分后,写操作的执行与之前一样,但读操作采用Paxos Quorum Reads(PQR)的方式进行。在进行读操作时,客户端首先向一个read quorum发送PreRead消息,acceptor接收到该消息后会将自己已经投过票的最大的日志槽的索引wi响应给客户端,客户端选取最大的wi作为i。然后向任意replica发送Read(x, i)消息,当replica日志槽中第i个命令应用后,对x进行读取并响应给客户端。如下图:
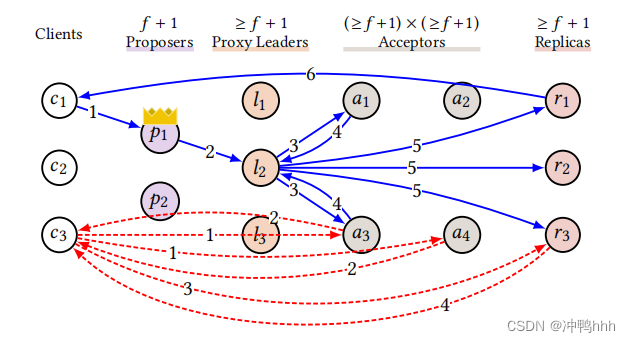
这里的逻辑比较清晰,最开始发送
PreRead消息给read quorum是为了获取整个系统中最新的日志槽i,然后便可以将该读操作挂载到该日志槽上,此时该读操作可以反映日志槽i对应的状态而不需要自己占一个槽。因此实现线性读。
此时,增加read quorum的数量(注意不是read quorum中节点的数量),可以在读密集的系统(如:Chubby(写操作小于1%)、Spanner(写操作小于0.3%))中将PreRead消息负载到更多的read quorum中从而分摊压力。
5. Batchers
将命令分批处理是提高系统吞吐量的一个有效手段,客户端发送请求给leader时,leader会对请求进行积攒,当达到一定数量或超时后统一发送给acceptor进行处理,如果batch的大小为10,那么系统整体可以减少十倍的消息数量。如下图:
需要注意,replica需要响应给参与该batch的所有客户端
主链路中leader后的角色都可以享受到这种优化带来的好处(降低每个命令需要处理的消息数),但leader却被赋予了分批的职责,此时加重了leader的负担。
此时leader的职责主要有batching以及给batch排序。如同proxy leader时的思路,论文将这两个职责进行切分,引入Batcher角色,由Batcher对请求进行batching,达到阈值后发送给leader对batch进行排序,其它流程不变。如下图:

显然Batcher之间是并行工作的,所以增加其数量能有效降低其压力。
对于读操作也类似,首先通过Batcher对读请求进行batching,然后统一对batch进行PreRead,这样一个batch中的读请求都会挂载到同一个日志槽上。
6. Unbatchers
由于replica需要响应参与某batch的所有客户端,这就导致如果batch的大小为n,那么replica在响应时就需要一次发送n条消息。这导致replica可能成为瓶颈。
在引入Batch后,replica除了应用命令进行状态转换之外,还需要进行batch响应。论文将这两个职责进行拆分,引入Unbatcher角色。此时relica只需应用命令,将响应发送给unbatcher,然后由unbatcher对客户端进行响应。如下图:
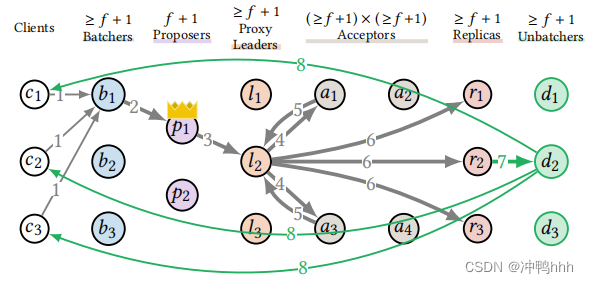
unbatcher的工作是并行的,因此增加其数量可以有效降低其负担。
四、总结
论文采用了划分的方式从不同维度对MultiPaxos的瓶颈进行优化,使其支持scale。同时,优化路线是层层递进的,逐渐消除可能新产生的瓶颈,但这也导致单独讨论其中一种优化意义相对不那么大。
MultiPaxos中leader的瓶颈太过明显,在一般情况下,leader限制了其它角色的能力,仅仅消除leader的瓶颈便可以较好地提升系统的吞吐量。同样的,在没有解决leader瓶颈的前提下,使用其它优化可能并不会有很好的效果。
当然,最终leader和replica还是可能成为瓶颈。因为leader的排序以及replica的状态转移一定会出现在执行的关键路径中,而为了保持排序的独断性,我们无法通过scale的方式对排序进行优化(当然可以增加sequencer的数量,但需要对命令的排序额外达成共识)。同样,为了保证数据的完整性,无法通过增加replica的方式分摊replica状态转移的负担,每个replica都需要完整应用所有的命令。