datawhale8月组队学习《pandas数据处理与分析》(中)(变形、连接、缺失数据)
文章目录
- 五、变形
- 5.1 长宽表变形
- 5.1 pivot
- 5.2 pivot_table 处理非唯一值
- 5.3 melt(宽表变长表)
- 5.4 wide_to_long
- 5.2 索引的变形
- 5.3 其他变形函数
- 5.3.1 crosstab
- 5.3.2 explode
- 5.3.3 get_dummies
- 5.4 第五章练习
- 5.4.1 美国非法药物数据集
- 5.4.2 特殊的wide_to_long方法
- 六、连接
- 6.1 关系型连接
- 6.1.1 值连接
- 6.1.2 索引连接
- 6.2 方向连接
- 6.2.1 concat
- 6.2 向表中追加序列
- 6.3 类连接操作
- 6.3.1 compare(比较)
- 6.3.2 combine(组合)
- 6.4 第六章练习
- 6.4.1 美国疫情数据集
- 6.4.2 实现join函数
- 第七章、缺失数据
- 7.1 缺失信息的统计
- 7.2 删除缺失值
- 7.2 缺失值的填充和插值
- 7.2.1 利用fillna进行填充
- 7.2.2 interpolate插值填充
- 7.3 Nullable类型( `Int`, `boolean` 和 `string`)
- 7.3.1 缺失记号及其缺陷
- 7.3.2 Nullable类型的性质
- 7.3.3 缺失数据的计算和分组
- 7.4 练习
- 7.4.1 缺失值与类别的相关性检验
- 7.4.2 用回归模型解决分类问题
课程资料《pandas数据处理与分析》、github地址、讲解视频、习题参考答案
pandas官网
五、变形
把某个特征以列的形式存储在表中,那么它就是关于这个特征的长表;如果把特征作为列名,列中的元素是某一其他的相关特征数值,那么这个表是关于这个特征的宽表。下面举例说明:
pd.DataFrame({'Gender':['F','F','M','M'],
'Height':[163, 160, 175, 180]})
| Gender | Height | |
|---|---|---|
| 0 | F | 163 |
| 1 | F | 160 |
| 2 | M | 175 |
| 3 | M | 180 |
pd.DataFrame({'Height: F':[163, 160],
'Height: M':[175, 180]})
| Height: F | Height: M | |
|---|---|---|
| 0 | 163 | 175 |
| 1 | 160 | 180 |
5.1 长宽表变形
5.1 pivot
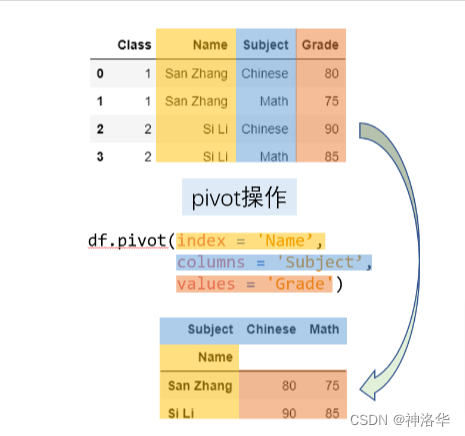
pivot 是一种典型的长表变宽表的函数。对于一个基本的长变宽操作而言,最重要的有三个要素,它们分别对应了 pivot 方法中的 index, columns, values 参数。新生成表的列索引是 columns 对应列的 unique 值,而新表的行索引是 index 对应列的 unique 值,而 values 对应了想要展示的数值列。
首先来看一个例子:下表存储了张三和李四的语文和数学分数,现在想要把语文和数学分数作为列来展示。
import pandas as pd
import numpy as np
df = pd.DataFrame({'Class':[1,1,2,2],
'Name':['San Zhang','San Zhang','Si Li','Si Li'],
'Subject':['Chinese','Math','Chinese','Math'],
'Grade':[80,75,90,85]})
df
| Class | Name | Subject | Grade | |
|---|---|---|---|---|
| 0 | 1 | San Zhang | Chinese | 80 |
| 1 | 1 | San Zhang | Math | 75 |
| 2 | 2 | Si Li | Chinese | 90 |
| 3 | 2 | Si Li | Math | 85 |
在新表中的行列索引对应了唯一的 value ,因此原表中的 index 和 columns 对应两个列的行组合必须唯一,否则会报错。
df.pivot(index='Name', columns='Subject', values='Grade')
| Subject | Chinese | Math |
|---|---|---|
| Name | ||
| San Zhang | 80 | 75 |
| Si Li | 90 | 85 |
从下面的示意图中能够比较容易地理解相应的操作:
pivot 相关的三个参数允许被设置为列表,这也意味着会返回多级索引
df = pd.DataFrame({'Class':[1, 1, 2, 2, 1, 1, 2, 2],
'Name':['San Zhang', 'San Zhang', 'Si Li', 'Si Li',
'San Zhang', 'San Zhang', 'Si Li', 'Si Li'],
'Examination': ['Mid', 'Final', 'Mid', 'Final',
'Mid', 'Final', 'Mid', 'Final'],
'Subject':['Chinese', 'Chinese', 'Chinese', 'Chinese',
'Math', 'Math', 'Math', 'Math'],
'Grade':[80, 75, 85, 65, 90, 85, 92, 88],
'rank':[10, 15, 21, 15, 20, 7, 6, 2]})
df
| Class | Name | Examination | Subject | Grade | rank | |
|---|---|---|---|---|---|---|
| 0 | 1 | San Zhang | Mid | Chinese | 80 | 10 |
| 1 | 1 | San Zhang | Final | Chinese | 75 | 15 |
| 2 | 2 | Si Li | Mid | Chinese | 85 | 21 |
| 3 | 2 | Si Li | Final | Chinese | 65 | 15 |
| 4 | 1 | San Zhang | Mid | Math | 90 | 20 |
| 5 | 1 | San Zhang | Final | Math | 85 | 7 |
| 6 | 2 | Si Li | Mid | Math | 92 | 6 |
| 7 | 2 | Si Li | Final | Math | 88 | 2 |
现在想要把测试类型和科目联合组成的四个类别(期中语文、期末语文、期中数学、期末数学)转到列索引,并且同时统计成绩和排名:
pivot_multi = df.pivot(index = ['Class', 'Name'],
columns = ['Subject','Examination'],
values = ['Grade','rank'])
pivot_multi
| Grade | rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Subject | Chinese | Math | Chinese | Math | |||||
| Examination | Mid | Final | Mid | Final | Mid | Final | Mid | Final | |
| Class | Name | ||||||||
| 1 | San Zhang | 80 | 75 | 90 | 85 | 10 | 15 | 20 | 7 |
| 2 | Si Li | 85 | 65 | 92 | 88 | 21 | 15 | 6 | 2 |
5.2 pivot_table 处理非唯一值
pivot 的使用依赖于唯一性条件,那如果不满足唯一性条件,那么必须通过聚合操作使得相同行列组合对应的多个值变为一个值。例如,张三和李四都参加了两次语文考试和数学考试,按照学院规定,最后的成绩是两次考试分数的平均值,此时就无法通过 pivot 函数来完成。
df = pd.DataFrame({'Name':['San Zhang', 'San Zhang',
'San Zhang', 'San Zhang',
'Si Li', 'Si Li', 'Si Li', 'Si Li'],
'Subject':['Chinese', 'Chinese', 'Math', 'Math',
'Chinese', 'Chinese', 'Math', 'Math'],
'Grade':[80, 90, 100, 90, 70, 80, 85, 95]})
df
| Name | Subject | Grade | |
|---|---|---|---|
| 0 | San Zhang | Chinese | 80 |
| 1 | San Zhang | Chinese | 90 |
| 2 | San Zhang | Math | 100 |
| 3 | San Zhang | Math | 90 |
| 4 | Si Li | Chinese | 70 |
| 5 | Si Li | Chinese | 80 |
| 6 | Si Li | Math | 85 |
| 7 | Si Li | Math | 95 |
pandas 中提供了 pivot_table 来实现,其中的 aggfunc 参数就是使用的聚合函数,表示如何处理非唯一值。 其包含了上一章中介绍的所有合法聚合字符串。
df.pivot_table(index = 'Name',
columns = 'Subject',
values = 'Grade',
aggfunc = 'mean')
| Subject | Chinese | Math |
|---|---|---|
| Name | ||
| San Zhang | 85 | 95 |
| Si Li | 75 | 90 |
此外还可以传入以序列为输入标量为输出的聚合函数来实现自定义操作,上述功能可以等价写出:
df.pivot_table(index = 'Name',
columns = 'Subject',
values = 'Grade',
aggfunc = lambda x:x.mean())
| Subject | Chinese | Math |
|---|---|---|
| Name | ||
| San Zhang | 85 | 95 |
| Si Li | 75 | 90 |
pivot_table 具有边际汇总的功能,可以通过设置 margins=True 来实现,其中边际的聚合方式与 aggfunc 中给出的聚合方法一致。下面就分别统计了语文均分和数学均分、张三均分和李四均分,以及总体所有分数的均分:
df.pivot_table(index = 'Name',
columns = 'Subject',
values = 'Grade',
aggfunc='mean',
margins=True)
| Subject | Chinese | Math | All |
|---|---|---|---|
| Name | |||
| San Zhang | 85 | 95.0 | 90.00 |
| Si Li | 75 | 90.0 | 82.50 |
| All | 80 | 92.5 | 86.25 |
5.3 melt(宽表变长表)
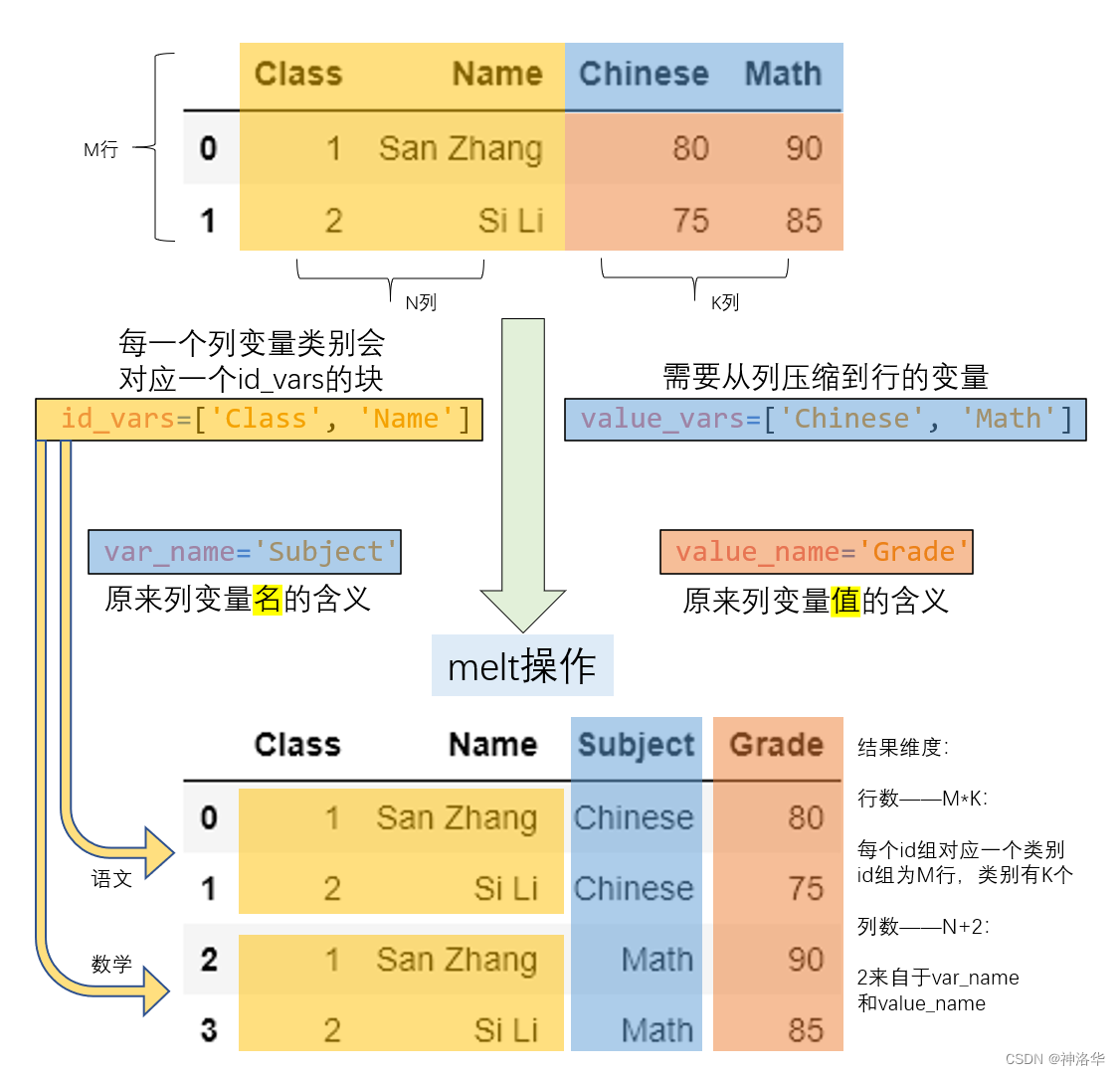
长宽表只是数据呈现方式的差异,但其包含的信息量是等价的,前面提到了利用 pivot 把长表转为宽表,那么就可以通过相应的逆操作把宽表转为长表, melt 函数就起到了这样的作用。在下面的例子中, Subject 以列索引的形式存储,现在想要将其压缩到一个列中。
df = pd.DataFrame({'Class':[1,2],
'Name':['San Zhang', 'Si Li'],
'Chinese':[80, 90],
'Math':[80, 75]})
df
| Class | Name | Chinese | Math | |
|---|---|---|---|---|
| 0 | 1 | San Zhang | 80 | 80 |
| 1 | 2 | Si Li | 90 | 75 |
df_melted = df.melt(id_vars = ['Class', 'Name'],
value_vars = ['Chinese', 'Math'],
var_name = 'Subject',
value_name = 'Grade')
df_melted
| Class | Name | Subject | Grade | |
|---|---|---|---|---|
| 0 | 1 | San Zhang | Chinese | 80 |
| 1 | 2 | Si Li | Chinese | 90 |
| 2 | 1 | San Zhang | Math | 80 |
| 3 | 2 | Si Li | Math | 75 |
转换过程如下:
5.4 wide_to_long
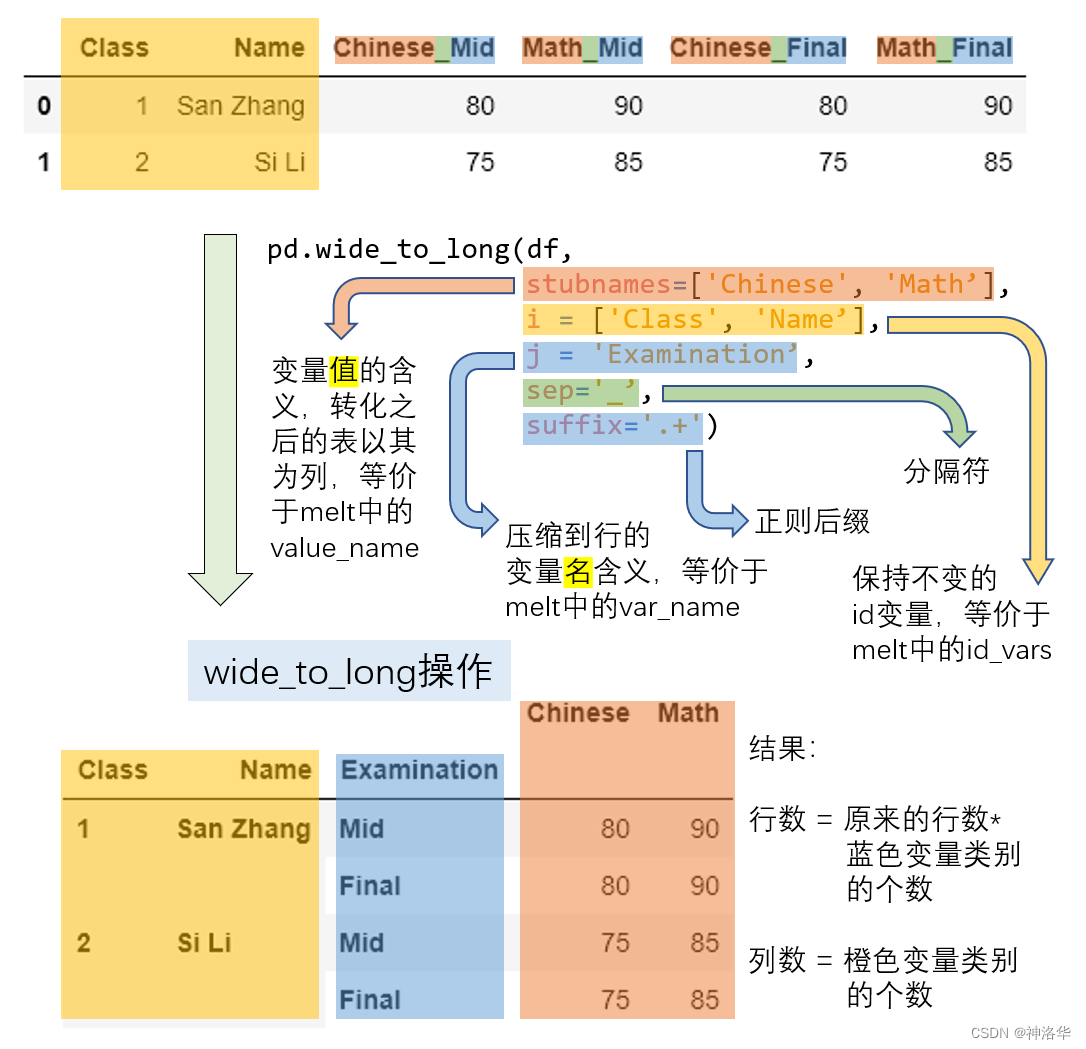
melt 方法中,values_name对应的列元素只能代表同一层次的含义。如果列中包含了交叉类别,比如期中期末的类别和语文数学的类别,那么想要把 values_name 对应的 Grade 扩充为两列分别对应语文分数和数学分数,只把期中期末的信息压缩,这种需求下就要使用 wide_to_long 函数来完成。
df = pd.DataFrame({'Class':[1,2],'Name':['San Zhang', 'Si Li'],
'Chinese_Mid':[80, 75], 'Math_Mid':[90, 85],
'Chinese_Final':[80, 75], 'Math_Final':[90, 85]})
df
| Class | Name | Chinese_Mid | Math_Mid | Chinese_Final | Math_Final | |
|---|---|---|---|---|---|---|
| 0 | 1 | San Zhang | 80 | 90 | 80 | 90 |
| 1 | 2 | Si Li | 75 | 85 | 75 | 85 |
pd.wide_to_long(df,
stubnames=['Chinese', 'Math'], # 要保留的列
i = ['Class', 'Name'], # 原先的索引,依旧保留
j='Examination', # 要转换的列
sep='_',
suffix='.+') # 正则后缀
| Chinese | Math | |||
|---|---|---|---|---|
| Class | Name | Examination | ||
| 1 | San Zhang | Mid | 80 | 90 |
| Final | 80 | 90 | ||
| 2 | Si Li | Mid | 75 | 85 |
| Final | 75 | 85 |
res = pivot_multi.copy()
res
| Grade | rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Subject | Chinese | Math | Chinese | Math | |||||
| Examination | Mid | Final | Mid | Final | Mid | Final | Mid | Final | |
| Class | Name | ||||||||
| 1 | San Zhang | 80 | 75 | 90 | 85 | 10 | 15 | 20 | 7 |
| 2 | Si Li | 85 | 65 | 92 | 88 | 21 | 15 | 6 | 2 |
res.columns,res.columns.map(lambda x:'_'.join(x))
(MultiIndex([('Grade', 'Chinese', 'Mid'),
('Grade', 'Chinese', 'Final'),
('Grade', 'Math', 'Mid'),
('Grade', 'Math', 'Final'),
( 'rank', 'Chinese', 'Mid'),
( 'rank', 'Chinese', 'Final'),
( 'rank', 'Math', 'Mid'),
( 'rank', 'Math', 'Final')],
names=[None, 'Subject', 'Examination']),
Index(['Grade_Chinese_Mid', 'Grade_Chinese_Final', 'Grade_Math_Mid',
'Grade_Math_Final', 'rank_Chinese_Mid', 'rank_Chinese_Final',
'rank_Math_Mid', 'rank_Math_Final'],
dtype='object'))
res.columns = res.columns.map(lambda x:'_'.join(x))
res = res.reset_index()
res = pd.wide_to_long(res, stubnames=['Grade', 'rank'],
i = ['Class', 'Name'],
j = 'Subject_Examination',
sep = '_',
suffix = '.+')
res
| Grade | rank | |||
|---|---|---|---|---|
| Class | Name | Subject_Examination | ||
| 1 | San Zhang | Chinese_Mid | 80 | 10 |
| Chinese_Final | 75 | 15 | ||
| Math_Mid | 90 | 20 | ||
| Math_Final | 85 | 7 | ||
| 2 | Si Li | Chinese_Mid | 85 | 21 |
| Chinese_Final | 65 | 15 | ||
| Math_Mid | 92 | 6 | ||
| Math_Final | 88 | 2 |
恢复索引,增加两列,其值为Subject_Examination的字符串拆分后的结果
res = res.reset_index() # 恢复原先的索引,也就是res = pivot_multi.copy()
res[['Subject', 'Examination']] = res[
'Subject_Examination'].str.split('_', expand=True)
res
| Class | Name | Subject_Examination | Grade | rank | Subject | Examination | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | San Zhang | Chinese_Mid | 80 | 10 | Chinese | Mid |
| 1 | 1 | San Zhang | Chinese_Final | 75 | 15 | Chinese | Final |
| 2 | 1 | San Zhang | Math_Mid | 90 | 20 | Math | Mid |
| 3 | 1 | San Zhang | Math_Final | 85 | 7 | Math | Final |
| 4 | 2 | Si Li | Chinese_Mid | 85 | 21 | Chinese | Mid |
| 5 | 2 | Si Li | Chinese_Final | 65 | 15 | Chinese | Final |
| 6 | 2 | Si Li | Math_Mid | 92 | 6 | Math | Mid |
| 7 | 2 | Si Li | Math_Final | 88 | 2 | Math | Final |
重新选取并排序需要的列,并对做后的Subject列排序
res = res[['Class', 'Name', 'Examination',
'Subject', 'Grade', 'rank']].sort_values('Subject')
res
| Class | Name | Examination | Subject | Grade | rank | |
|---|---|---|---|---|---|---|
| 0 | 1 | San Zhang | Mid | Chinese | 80 | 10 |
| 1 | 1 | San Zhang | Final | Chinese | 75 | 15 |
| 4 | 2 | Si Li | Mid | Chinese | 85 | 21 |
| 5 | 2 | Si Li | Final | Chinese | 65 | 15 |
| 2 | 1 | San Zhang | Mid | Math | 90 | 20 |
| 3 | 1 | San Zhang | Final | Math | 85 | 7 |
| 6 | 2 | Si Li | Mid | Math | 92 | 6 |
| 7 | 2 | Si Li | Final | Math | 88 | 2 |
5.2 索引的变形
第二章中提到了利用 swaplevel 或者 reorder_levels 进行索引内部的层交换,下面就要讨论 行列索引之间 的交换,由于这种交换带来了 DataFrame 维度上的变化,因此属于变形操作。
和长宽表变形不同,前者是列索引和对应元素值都变化了,而这里只是行列索引变化。
-
unstack 函数的作用是把行索引转为列索引
- 主要参数是移动的层号,默认转化最内层,移动到列索引的最内层,同时支持同时转化多个层:
- 必须保证被转为列索引的行索引层和被保留的行索引层,构成的组合是唯一的
-
stack 的作用就是把列索引的层压入行索引,其用法完全类似
df = pd.DataFrame(np.ones((4,2)),
index = pd.Index([('A', 'cat', 'big'),
('A', 'dog', 'small'),
('B', 'cat', 'big'),
('B', 'dog', 'small')]),
columns=['col_1', 'col_2'])
df
| col_1 | col_2 | |||
|---|---|---|---|---|
| A | cat | big | 1.0 | 1.0 |
| dog | small | 1.0 | 1.0 | |
| B | cat | big | 1.0 | 1.0 |
| dog | small | 1.0 | 1.0 |
df.unstack(0) # 最外层索引A、B转为列索引
| col_1 | col_2 | ||||
|---|---|---|---|---|---|
| A | B | A | B | ||
| cat | big | 1.0 | 1.0 | 1.0 | 1.0 |
| dog | small | 1.0 | 1.0 | 1.0 | 1.0 |
df.unstack([1,2]) # 里面两层索引转为列索引
| col_1 | col_2 | |||
|---|---|---|---|---|
| cat | dog | cat | dog | |
| big | small | big | small | |
| A | 1.0 | 1.0 | 1.0 | 1.0 |
| B | 1.0 | 1.0 | 1.0 | 1.0 |
stack 的作用就是把列索引的层压入行索引
df = pd.DataFrame(np.ones((4,2)),
index = pd.Index([('A', 'cat', 'big'),
('A', 'dog', 'small'),
('B', 'cat', 'big'),
('B', 'dog', 'small')]),
columns=['index_1', 'index_2']).T
df
| A | B | |||
|---|---|---|---|---|
| cat | dog | cat | dog | |
| big | small | big | small | |
| index_1 | 1.0 | 1.0 | 1.0 | 1.0 |
| index_2 | 1.0 | 1.0 | 1.0 | 1.0 |
df.stack(0)
| cat | dog | ||
|---|---|---|---|
| big | small | ||
| index_1 | A | 1.0 | 1.0 |
| B | 1.0 | 1.0 | |
| index_2 | A | 1.0 | 1.0 |
| B | 1.0 | 1.0 |
df.stack([1,2])
| A | B | |||
|---|---|---|---|---|
| index_1 | cat | big | 1.0 | 1.0 |
| dog | small | 1.0 | 1.0 | |
| index_2 | cat | big | 1.0 | 1.0 |
| dog | small | 1.0 | 1.0 |
聚合与变形的关系
在上面介绍的所有函数中,除了带有聚合效果的 pivot_table 以外,所有的函数在变形前后并不会带来 values 个数的改变,只是这些值在呈现的形式上发生了变化。在上一章讨论的分组聚合操作,由于生成了新的行列索引,因此必然也属于某种特殊的变形操作,但由于聚合之后把原来的多个值变为了一个值,因此 values 的个数产生了变化,这也是分组聚合与变形函数的最大区别。
5.3 其他变形函数
5.3.1 crosstab
crosstab 是一个地位尴尬的函数,因为它能实现的所有功能 pivot_table 都能完成。在默认状态下, crosstab 可以统计元素组合出现的频数,即 count 操作
df = pd.read_csv('./input/learn-pd/learn_pandas.csv')
df.head(3)
| School | Grade | Name | Gender | Height | Weight | Transfer | Test_Number | Test_Date | Time_Record | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Shanghai Jiao Tong University | Freshman | Gaopeng Yang | Female | 158.9 | 46.0 | N | 1 | 2019/10/5 | 0:04:34 |
| 1 | Peking University | Freshman | Changqiang You | Male | 166.5 | 70.0 | N | 1 | 2019/9/4 | 0:04:20 |
| 2 | Shanghai Jiao Tong University | Senior | Mei Sun | Male | 188.9 | 89.0 | N | 2 | 2019/9/12 | 0:05:22 |
统计 learn_pandas 数据集中学校和转系情况对应的频数:
pd.crosstab(index = df.School, columns = df.Transfer)
| Transfer | N | Y |
|---|---|---|
| School | ||
| Fudan University | 38 | 1 |
| Peking University | 28 | 2 |
| Shanghai Jiao Tong University | 53 | 0 |
| Tsinghua University | 62 | 4 |
同样,可以利用 pivot_table 进行等价操作,由于这里统计的是组合的频数,因此 values 参数无论传入哪一个列都不会影响最后的结果:
df.pivot_table(index = 'School',
columns = 'Transfer',
values = 'Weight',
aggfunc = 'count')
| Transfer | N | Y |
|---|---|---|
| School | ||
| Fudan University | 38.0 | 1.0 |
| Peking University | 25.0 | 2.0 |
| Shanghai Jiao Tong University | 49.0 | NaN |
| Tsinghua University | 60.0 | 4.0 |
从上面可以看出这两个函数的区别在于, crosstab 的对应位置传入的是具体的序列,而 pivot_table 传入的是被调用表对应的名字,若传入序列对应的值则会报错。
除了默认状态下的 count 统计,所有的聚合字符串和返回标量的自定义函数都是可用的,例如统计对应组合的身高均值:
# 感觉是分组统计啊,写法更简单
pd.crosstab(index = df.School, columns = df.Transfer,
values = df.Height, aggfunc = 'mean')
| Transfer | N | Y |
|---|---|---|
| School | ||
| Fudan University | 162.043750 | 177.20 |
| Peking University | 163.429630 | 162.40 |
| Shanghai Jiao Tong University | 163.953846 | NaN |
| Tsinghua University | 163.253571 | 164.55 |
5.3.2 explode
explode 参数能够对某一列的元素进行纵向的展开,被展开的单元格必须存储 list, tuple, Series, np.ndarray 中的一种类型。
df_ex = pd.DataFrame({'A': [[1, 2],
'my_str',
{1, 2},
pd.Series([3, 4])],
'B': 1})
df_ex
| A | B | |
|---|---|---|
| 0 | [1, 2] | 1 |
| 1 | my_str | 1 |
| 2 | {1, 2} | 1 |
| 3 | 0 3 1 4 dtype: int64 | 1 |
df_ex.explode('A')
| A | B | |
|---|---|---|
| 0 | 1 | 1 |
| 0 | 2 | 1 |
| 1 | my_str | 1 |
| 2 | 1 | 1 |
| 2 | 2 | 1 |
| 3 | 3 | 1 |
| 3 | 4 | 1 |
5.3.3 get_dummies
get_dummies 是用于特征构建的重要函数之一,其作用是把类别特征(object类型)转为独热码的形式。其API为:
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
例如,可对指定列进行get_dummies
筛选出object列
df.select_dtypes(include='object').head(3)
# df.select_dtypes(include='object').head(3) # 获取列名
| School | Grade | Name | Gender | Transfer | Test_Date | Time_Record | |
|---|---|---|---|---|---|---|---|
| 0 | Shanghai Jiao Tong University | Freshman | Gaopeng Yang | Female | N | 2019/10/5 | 0:04:34 |
| 1 | Peking University | Freshman | Changqiang You | Male | N | 2019/9/4 | 0:04:20 |
| 2 | Shanghai Jiao Tong University | Senior | Mei Sun | Male | N | 2019/9/12 | 0:05:22 |
pd.get_dummies(['School','Grade','Gender', 'Transfer'])
| Gender | Grade | School | Transfer | |
|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 1 |
将指定列进行get_dummies 后合并到元数据中
df2=df.copy()
df2=df2.join(pd.get_dummies(df2['School']))
df2.head()
| School | Grade | Name | Gender | Height | Weight | Transfer | Test_Number | Test_Date | Time_Record | Fudan University | Peking University | Shanghai Jiao Tong University | Tsinghua University | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Shanghai Jiao Tong University | Freshman | Gaopeng Yang | Female | 158.9 | 46.0 | N | 1 | 2019/10/5 | 0:04:34 | 0 | 0 | 1 | 0 |
| 1 | Peking University | Freshman | Changqiang You | Male | 166.5 | 70.0 | N | 1 | 2019/9/4 | 0:04:20 | 0 | 1 | 0 | 0 |
| 2 | Shanghai Jiao Tong University | Senior | Mei Sun | Male | 188.9 | 89.0 | N | 2 | 2019/9/12 | 0:05:22 | 0 | 0 | 1 | 0 |
| 3 | Fudan University | Sophomore | Xiaojuan Sun | Female | NaN | 41.0 | N | 2 | 2020/1/3 | 0:04:08 | 1 | 0 | 0 | 0 |
| 4 | Fudan University | Sophomore | Gaojuan You | Male | 174.0 | 74.0 | N | 2 | 2019/11/6 | 0:05:22 | 1 | 0 | 0 | 0 |
5.4 第五章练习
5.4.1 美国非法药物数据集
现有一份关于美国非法药物的数据集,其中 SubstanceName, DrugReports 分别指药物名称和报告数量:
df=pd.read_csv('./input/usa-drugs/drugs.csv')
df
| YYYY | State | COUNTY | SubstanceName | DrugReports | |
|---|---|---|---|---|---|
| 0 | 2010 | VA | ACCOMACK | Propoxyphene | 1 |
| 1 | 2010 | OH | ADAMS | Morphine | 9 |
| 2 | 2010 | PA | ADAMS | Methadone | 2 |
| 3 | 2010 | VA | ALEXANDRIA CITY | Heroin | 5 |
| 4 | 2010 | PA | ALLEGHENY | Hydromorphone | 5 |
| ... | ... | ... | ... | ... | ... |
| 24057 | 2017 | VA | WYTHE | Codeine | 1 |
| 24058 | 2017 | VA | WYTHE | Hydrocodone | 19 |
| 24059 | 2017 | VA | WYTHE | Tramadol | 5 |
| 24060 | 2017 | PA | YORK | ANPP | 1 |
| 24061 | 2017 | VA | YORK | Heroin | 48 |
24062 rows × 5 columns
df.set_index(['State','COUNTY','SubstanceName','YYYY']).sort_index()
| DrugReports | ||||
|---|---|---|---|---|
| State | COUNTY | SubstanceName | YYYY | |
| KY | ADAIR | Buprenorphine | 2011 | 3 |
| 2012 | 5 | |||
| 2013 | 4 | |||
| 2014 | 27 | |||
| 2015 | 5 | |||
| ... | ... | ... | ... | ... |
| WV | WYOMING | Oxycodone | 2010 | 5 |
| 2011 | 4 | |||
| 2012 | 14 | |||
| 2013 | 12 | |||
| 2014 | 5 |
24062 rows × 1 columns
df.groupby(['State','COUNTY','SubstanceName','YYYY']).ngroups # 没有重复的组合啊
24062
- 将数据转为如下的形式:

"""
'State','COUNTY','SubstanceName'三列是保持不变,传入index,columns=['YYYY']。此时为多级索引
通过reset_index()恢复原先索引,原先index名为YYYY,将其重命名为空。
"""
df.pivot(index=['State','COUNTY','SubstanceName'], columns=['YYYY'], values='DrugReports').reset_index().rename_axis(columns={'YYYY':''}).head()
| State | COUNTY | SubstanceName | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | KY | ADAIR | Buprenorphine | NaN | 3.0 | 5.0 | 4.0 | 27.0 | 5.0 | 7.0 | 10.0 |
| 1 | KY | ADAIR | Codeine | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | 1.0 |
| 2 | KY | ADAIR | Fentanyl | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN |
| 3 | KY | ADAIR | Heroin | NaN | NaN | 1.0 | 2.0 | NaN | 1.0 | NaN | 2.0 |
| 4 | KY | ADAIR | Hydrocodone | 6.0 | 9.0 | 10.0 | 10.0 | 9.0 | 7.0 | 11.0 | 3.0 |
- 将第1问中的结果恢复为原表。
df2=df.pivot(index=['State','COUNTY','SubstanceName'], columns=['YYYY'],
values='DrugReports').reset_index().rename_axis(columns={'YYYY':''}) # 这是第一问的结果,赋值为df2
# 使用melt方法将宽表转为长表。注意,列名中的年份不是字符串2010,我加了个str(x)报错了。
df2=df2.melt(id_vars = ['State','COUNTY','SubstanceName'],
value_vars = [x for x in range(2010,2018,1)],
var_name = 'YYYY',
value_name = 'DrugReports')
# 去除NaN的数值,但是此时索引不对,还是49000+行的索引
df=df2[df.columns].dropna()
# 重设索引为df的长度,如果直接用df.rename(index=[x for x in range(df.shape[0])])会报错‘'list' object is not callable’
new_values = iter([x for x in range(df.shape[0])])
df.rename(index=lambda x:next(new_values))
# 经过了排序啊,索引依旧不对
| YYYY | State | COUNTY | SubstanceName | DrugReports | |
|---|---|---|---|---|---|
| 0 | 2010 | KY | ADAIR | Hydrocodone | 6.0 |
| 1 | 2010 | KY | ADAIR | Methadone | 1.0 |
| 2 | 2010 | KY | ALLEN | Hydrocodone | 10.0 |
| 3 | 2010 | KY | ALLEN | Methadone | 4.0 |
| 4 | 2010 | KY | ALLEN | Oxycodone | 15.0 |
| ... | ... | ... | ... | ... | ... |
| 24057 | 2017 | WV | WOOD | Hydrocodone | 8.0 |
| 24058 | 2017 | WV | WOOD | Isobutyryl fentanyl | 3.0 |
| 24059 | 2017 | WV | WOOD | Oxycodone | 1.0 |
| 24060 | 2017 | WV | WOOD | Tramadol | 3.0 |
| 24061 | 2017 | WV | WYOMING | Buprenorphine | 1.0 |
24062 rows × 5 columns
- 按 State 分别统计每年的报告数量总和,其中 State, YYYY 分别为列索引和行索引
要求分别使用 pivot_table 函数与 groupby+unstack 两种不同的策略实现,并体会它们之间的联系。
df.pivot_table(index = ['YYYY'],
columns = 'State',
values = 'DrugReports',
aggfunc = 'sum')
| State | KY | OH | PA | VA | WV |
|---|---|---|---|---|---|
| YYYY | |||||
| 2010 | 10453.0 | 19707.0 | 19814.0 | 8685.0 | 2890.0 |
| 2011 | 10289.0 | 20330.0 | 19987.0 | 6749.0 | 3271.0 |
| 2012 | 10722.0 | 23145.0 | 19959.0 | 7831.0 | 3376.0 |
| 2013 | 11148.0 | 26846.0 | 20409.0 | 11675.0 | 4046.0 |
| 2014 | 11081.0 | 30860.0 | 24904.0 | 9037.0 | 3280.0 |
| 2015 | 9865.0 | 37127.0 | 25651.0 | 8810.0 | 2571.0 |
| 2016 | 9093.0 | 42470.0 | 26164.0 | 10195.0 | 2548.0 |
| 2017 | 9394.0 | 46104.0 | 27894.0 | 10448.0 | 1614.0 |
# 得到的结果是series,将行索引State转为列索引,使用.unstack(0)
df.groupby(['State','YYYY'])['DrugReports'].sum().unstack(0)
| State | KY | OH | PA | VA | WV |
|---|---|---|---|---|---|
| YYYY | |||||
| 2010 | 10453.0 | 19707.0 | 19814.0 | 8685.0 | 2890.0 |
| 2011 | 10289.0 | 20330.0 | 19987.0 | 6749.0 | 3271.0 |
| 2012 | 10722.0 | 23145.0 | 19959.0 | 7831.0 | 3376.0 |
| 2013 | 11148.0 | 26846.0 | 20409.0 | 11675.0 | 4046.0 |
| 2014 | 11081.0 | 30860.0 | 24904.0 | 9037.0 | 3280.0 |
| 2015 | 9865.0 | 37127.0 | 25651.0 | 8810.0 | 2571.0 |
| 2016 | 9093.0 | 42470.0 | 26164.0 | 10195.0 | 2548.0 |
| 2017 | 9394.0 | 46104.0 | 27894.0 | 10448.0 | 1614.0 |
5.4.2 特殊的wide_to_long方法
从功能上看, melt 方法应当属于 wide_to_long 的一种特殊情况,即 stubnames 只有一类。请使用 wide_to_long 生成 melt 一节中的 df_melted 。(提示:对列名增加适当的前缀)
df = pd.DataFrame({'Class':[1,2],
'Name':['San Zhang', 'Si Li'],
'Chinese':[80, 90],
'Math':[80, 75]})
df
| Class | Name | Chinese | Math | |
|---|---|---|---|---|
| 0 | 1 | San Zhang | 80 | 80 |
| 1 | 2 | Si Li | 90 | 75 |
df.melt(id_vars = ['Class', 'Name'],
value_vars = ['Chinese', 'Math'],
var_name = 'Subject',
value_name = 'Grade')
| Class | Name | Subject | Grade | |
|---|---|---|---|---|
| 0 | 1 | San Zhang | Chinese | 80 |
| 1 | 2 | Si Li | Chinese | 90 |
| 2 | 1 | San Zhang | Math | 80 |
| 3 | 2 | Si Li | Math | 75 |
df=df.rename(columns={'Chinese':'Grade_Chinese','Math':'Grade_Math'})
df
| Class | Name | Grade_Chinese | Grade_Math | |
|---|---|---|---|---|
| 0 | 1 | San Zhang | 80 | 80 |
| 1 | 2 | Si Li | 90 | 75 |
简单说,就是分隔符将字符串分割为两部分,stubnames传入的部分仍旧作为列特征,剩下的压缩到行,并取其列名为j的值。
# 增加了index索引['Class', 'Name'],使用.reset_index()将其恢复。
pd.wide_to_long(df,
stubnames=['Grade'],
i = ['Class', 'Name'],
j='Subject',
sep='_',
suffix='.+').reset_index()
| Class | Name | Subject | Grade | |
|---|---|---|---|---|
| 0 | 1 | San Zhang | Chinese | 80 |
| 1 | 1 | San Zhang | Math | 80 |
| 2 | 2 | Si Li | Chinese | 90 |
| 3 | 2 | Si Li | Math | 75 |
六、连接
连接的基本概念
把两张相关的表按照某一个或某一组键连接起来是一种常见操作,例如学生期末考试各个科目的成绩表按照姓名 和班级连接成总的成绩表,进行连接汇总。由此可以看出,在关系型连接中,键是十分重要的,往往用on参数表示。
6.1 关系型连接
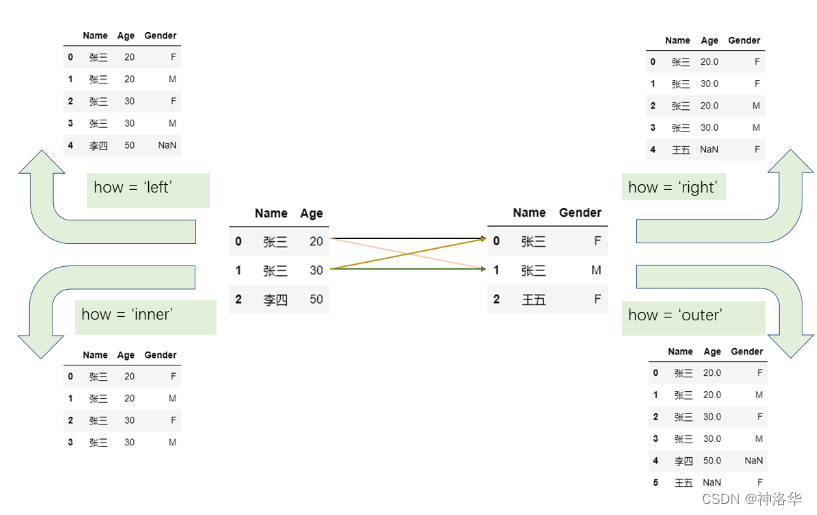
在 pandas 中,关系型连接函数merge和join提供了 how 参数来代表连接形式,分为左连接 left 、右连接 right 、内连接 inner 、外连接 outer ,它们的区别可以用如下示意图表示:
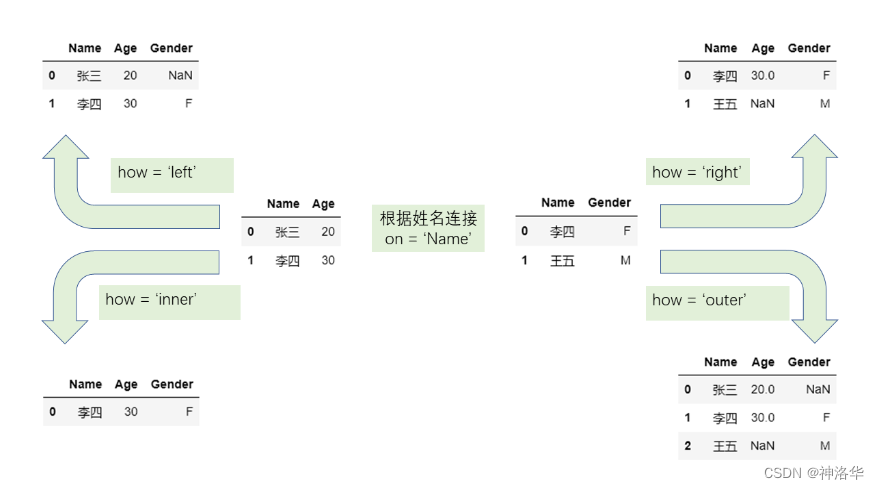
从图中可以看到:
- 左连接即以左表的键为准,如果右表中的键于左表存在,那么就添加到左表,否则则处理为缺失值,右连接类似处理。
- 内连接只负责合并两边同时出现的键
- 外连接则会在内连接的基础上包含只在左边出现以及只在右边出现的值,因此外连接又叫全连接。
那如果出现重复的键应该如何处理?只需把握一个原则:单边出现则根据连接形式进行处理,两边同时出现的值,就以笛卡尔积的方式加入。
关于笛卡尔积可用如下例子说明:设左表中键 张三 出现两次,右表中的 张三 也出现两次,那么逐个进行匹配,最后产生的表必然包含 2*2 个姓名为 张三 的行。下面是一个对应例子的示意图:
6.1.1 值连接
- 在上面示意图中的例子中,两张表根据某一列的值来连接,事实上还可以通过几列值的组合进行连接,这种基于值的连接在 pandas 中可以由 merge 函数实现,例如第一张图的左连接:
df1 = pd.DataFrame({'Name':['San Zhang','Si Li'],
'Age':[20,30]})
df2 = pd.DataFrame({'Name':['Si Li','Wu Wang'],
'Gender':['F','M']})
df1.merge(df2, on='Name', how='left')
| Name | Age | Gender | |
|---|---|---|---|
| 0 | San Zhang | 20 | NaN |
| 1 | Si Li | 30 | F |
- 列名不同的连接:如果两个表中想要连接的列不具备相同的列名,可以通过 left_on 和 right_on 指定:
df1 = pd.DataFrame({'df1_name':['San Zhang','Si Li'],
'Age':[20,30]})
df2 = pd.DataFrame({'df2_name':['Si Li','Wu Wang'],
'Gender':['F','M']})
df1.merge(df2, left_on='df1_name', right_on='df2_name', how='left')
| df1_name | Age | df2_name | Gender | |
|---|---|---|---|---|
| 0 | San Zhang | 20 | NaN | NaN |
| 1 | Si Li | 30 | Si Li | F |
- 连接的列列名重复,那么可以通过 suffixes 参数指定。例如合并考试成绩的时候,第一个表记录了语文成绩,第二个是数学成绩:
df1 = pd.DataFrame({'Name':['San Zhang'],'Grade':[70]})
df2 = pd.DataFrame({'Name':['San Zhang'],'Grade':[80]})
df1.merge(df2, on='Name', how='left', suffixes=['_Chinese','_Math']) # suffixes表示后缀
| Name | Grade_Chinese | Grade_Math | |
|---|---|---|---|
| 0 | San Zhang | 70 | 80 |
- 元素重复:例如两位同学来自不同的班级,但是姓名相同,这种时候就要指定 on 参数为多个列使得正确连接:
df1 = pd.DataFrame({'Name':['San Zhang', 'San Zhang'],
'Age':[20, 21],
'Class':['one', 'two']})
df2 = pd.DataFrame({'Name':['San Zhang', 'San Zhang'],
'Gender':['F', 'M'],
'Class':['two', 'one']})
df1
| Name | Age | Class | |
|---|---|---|---|
| 0 | San Zhang | 20 | one |
| 1 | San Zhang | 21 | two |
df2
| Name | Gender | Class | |
|---|---|---|---|
| 0 | San Zhang | F | two |
| 1 | San Zhang | M | one |
df1.merge(df2, on=['Name', 'Class'], how='left')
| Name | Age | Class | Gender | |
|---|---|---|---|---|
| 0 | San Zhang | 20 | one | M |
| 1 | San Zhang | 21 | two | F |
上面的例子来看,在进行基于唯一性的连接下,如果键不是唯一的,那么结果就会产生问题。实际数据中有几十万到上百万行的进行合并时,如果想要保证唯一性,除了用 duplicated 检查是否重复外, merge 中也提供了 validate 参数来检查连接的唯一性模式。
这里共有三种模式,即一对一连接 1:1 ,一对多连接 1:m ,多对一连接 m:1 连接,第一个是指左右表的键都是唯一的,后面两个分别指左表键唯一和右表键唯一。
6.1.2 索引连接
索引连接,就是把索引当作键,因此这和值连接本质上没有区别, pandas 中利用 join 函数来处理索引连接。
on 参数指索引名,单层索引时省略参数表示按照当前索引连接。除了必须的 on 和 how 之外,可以对重复的列指定左右后缀 lsuffix 和 rsuffix
df1 = pd.DataFrame({'Age':[20,30]},
index=pd.Series(
['San Zhang','Si Li'],name='Name'))
df2 = pd.DataFrame({'Gender':['F','M']},
index=pd.Series(
['Si Li','Wu Wang'],name='Name'))
df1.join(df2, how='left')
| Age | Gender | |
|---|---|---|
| Name | ||
| San Zhang | 20 | NaN |
| Si Li | 30 | F |
列名重复时,指定左右后缀处理:
df1 = pd.DataFrame({'Grade':[70]},
index=pd.Series(['San Zhang'],
name='Name'))
df2 = pd.DataFrame({'Grade':[80]},
index=pd.Series(['San Zhang'],
name='Name'))
df1.join(df2, how='left', lsuffix='_Chinese', rsuffix='_Math')
| Grade_Chinese | Grade_Math | |
|---|---|---|
| Name | ||
| San Zhang | 70 | 80 |
如果想要进行类似于 merge 中以多列为键的操作的时候,join 需要使用多级索引,例如在merge中的最后一个例子可以如下写出:
# df1和df2都是多级索引
df1 = pd.DataFrame({'Age':[20,21]},
index=pd.MultiIndex.from_arrays(
[['San Zhang', 'San Zhang'],['one', 'two']],
names=('Name','Class')))
df2 = pd.DataFrame({'Gender':['F', 'M']},
index=pd.MultiIndex.from_arrays(
[['San Zhang', 'San Zhang'],['two', 'one']],
names=('Name','Class')))
df1.join(df2)
| Age | Gender | ||
|---|---|---|---|
| Name | Class | ||
| San Zhang | one | 20 | M |
| two | 21 | F |
6.2 方向连接
6.2.1 concat
前面介绍了关系型连接,其中最重要的参数是 on 和 how ,但有时候用户并不关心以哪一列为键来合并,只是希望把两个表或者多个表按照纵向或者横向拼接,此时可以用concat 函数来实现。
在 concat 中,最常用的有三个参数,它们是 axis, join, keys ,分别表示拼接方向,连接形式,以及在新表中指示来自于哪一张旧表的名字
默认状态下的 axis=0 ,表示纵向拼接多个表,常常用于多个样本的拼接;而 axis=1 表示横向拼接多个表,常用于多个字段或特征的拼接。
# axis=1横向拼接
df1 = pd.DataFrame({'Name':['San Zhang','Si Li'],
'Age':[20,30]})
df2 = pd.DataFrame({'Grade':[80, 90]})
df3 = pd.DataFrame({'Gender':['M', 'F']})
pd.concat([df1, df2, df3],axis=1)
| Name | Age | Grade | Gender | |
|---|---|---|---|---|
| 0 | San Zhang | 20 | 80 | M |
| 1 | Si Li | 30 | 90 | F |
concat 实际上是关于索引进行连接:
- 纵向拼接会根据列索引对其,默认状态下
join=outer,表示保留所有的列,并将不存在的值设为缺失;join=inner,表示保留两个表都出现过的列。 - 横向拼接则根据行索引对齐,
join参数可以类似设置。
因此,当确认要使用多表进行方向合并时,尤其是横向的合并,可以先用reset_index 方法恢复默认整数索引再进行合并,防止出现由索引的误对齐和重复索引的笛卡尔积带来的错误结果。
keys 参数的使用场景在于多个表合并后,用户仍然想要知道新表中的数据来自于哪个原表,这时可以通过 keys 参数产生多级索引进行标记。例如,第一个表中都是一班的同学,而第二个表中都是二班的同学,可以使用如下方式合并:
df1 = pd.DataFrame({'Name':['San Zhang','Si Li'],
'Age':[20,21]})
df2 = pd.DataFrame({'Name':['Wu Wang'],'Age':[21]})
pd.concat([df1, df2], keys=['one', 'two'])
| Name | Age | ||
|---|---|---|---|
| one | 0 | San Zhang | 20 |
| 1 | Si Li | 21 | |
| two | 0 | Wu Wang | 21 |
6.2 向表中追加序列
利用 concat 可以实现多个表之间的方向拼接,如果想要把一个序列追加到表的行末或者列末,则可以分别使用 append 和 assign 方法。
在 append (追加行)中,如果原表是默认整数序列的索引,那么可以使用 ignore_index=True 对新序列对应的索引自动标号,否则必须对 Series 指定name属性。
df1
| Name | Age | |
|---|---|---|
| 0 | San Zhang | 20 |
| 1 | Si Li | 21 |
s = pd.Series(['Wu Wang', 21], index = df1.columns)
df1.append(s, ignore_index=True)
| Name | Age | |
|---|---|---|
| 0 | San Zhang | 20 |
| 1 | Si Li | 21 |
| 2 | Wu Wang | 21 |
assign 可以追加列,但一般通过 df['new_col'] = ... 的形式就可以等价地添加新列。不过,使用 [] 修改的缺点是它会直接在原表上进行改动,而 assign 返回的是一个临时副本:
s = pd.Series([80, 90])
df1.assign(Grade=s)
| Name | Age | Grade | |
|---|---|---|---|
| 0 | San Zhang | 20 | 80 |
| 1 | Si Li | 21 | 90 |
6.3 类连接操作
除了上述介绍的若干连接函数之外, pandas 中还设计了一些函数能够对两个表进行某些操作,这里把它们统称为类连接操作。
6.3.1 compare(比较)
compare 是在 1.1.0 后引入的新函数,它能够比较两个表或者序列的不同处并将其汇总展示:
df1 = pd.DataFrame({'Name':['San Zhang', 'Si Li', 'Wu Wang'],
'Age':[20, 21 ,21],
'Class':['one', 'two', 'three']})
df2 = pd.DataFrame({'Name':['San Zhang', 'Li Si', 'Wu Wang'],
'Age':[20, 21 ,21],
'Class':['one', 'two', 'Three']})
df1.compare(df2)# 下面的1和2表示行索引
| Name | Class | |||
|---|---|---|---|---|
| self | other | self | other | |
| 1 | Si Li | Li Si | NaN | NaN |
| 2 | NaN | NaN | three | Three |
df1
| Name | Age | Class | |
|---|---|---|---|
| 0 | San Zhang | 20 | one |
| 1 | Si Li | 21 | two |
| 2 | Wu Wang | 21 | three |
df2
| Name | Age | Class | |
|---|---|---|---|
| 0 | San Zhang | 20 | one |
| 1 | Li Si | 21 | two |
| 2 | Wu Wang | 21 | Three |
结果中返回了不同值所在的行列,如果相同则会被填充为缺失值 NaN ,其中 other 和 self 分别指代传入的参数表和被调用的表自身。
如果想要完整显示表中所有元素的比较情况,可以设置keep_shape=True:
df1.compare(df2, keep_shape=True)
| Name | Age | Class | ||||
|---|---|---|---|---|---|---|
| self | other | self | other | self | other | |
| 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | Si Li | Li Si | NaN | NaN | NaN | NaN |
| 2 | NaN | NaN | NaN | NaN | three | Three |
6.3.2 combine(组合)
combine是联合的意思,在Pandas中,combine()方法也是一种实现合并的方法。
combine_first()实现合并
在介绍combine()方法前,先介绍比combine()更特殊的combine_first()方法
df1.combine_first(other=df2): 根据DataFrame的行索引和列索引,对比两个DataFrame中相同位置的数据,优先取非空的数据进行合并。
- 如果df1中数据非空,则结果保留df1中的数据
- 如果df1中的数据为空值而df2中数据非空,则结果取df2中的数据
- 如果df1和df2中的数据都为空值,则结果保留df1中的空值(空值有三种: np.nan、None 和 pd.NaT)。
- 都为非空,优先选择df1的数据
- 即使两个DataFrame的形状不相同也不受影响,联合时主要是根据索引来定位数据的位置。
原文链接
df1 = pd.DataFrame({'A':[1,2,np.nan], 'B':[3,np.nan,4], 'C':[5,np.nan,np.nan]},index=[1,2,3])
df2 = pd.DataFrame({'A':[5,6,7], 'B':[7,np.nan,np.nan], 'C':[9,10,np.nan]}, index=[1,2,3])
df1.combine_first(df2)
| A | B | C | |
|---|---|---|---|
| 1 | 1.0 | 3.0 | 5.0 |
| 2 | 2.0 | NaN | 10.0 |
| 3 | 7.0 | 4.0 | NaN |
combine()实现合并
combine(other, func): 对两个DataFrame进行联合操作,实现合并的功能。other参数传入被合并的DataFrame,func参数传入合并的规则函数,两个参数都是必传参数。
func函数的入参是两个Series,分别来自两个DataFrame(将DataFrame按列遍历),返回结果是一个合并之后的Series,在函数中实现合并的规则。
func可以是匿名函数、Python库中定义好的函数、或自定义的函数,要满足两个入参一个返回值,且入参和返回值是数组或Series。
- 两个表的索引都相同,如下面的例子中,使用了匿名函数,合并规则为返回两个DataFrame中非空数据更多的列。原理如下图。
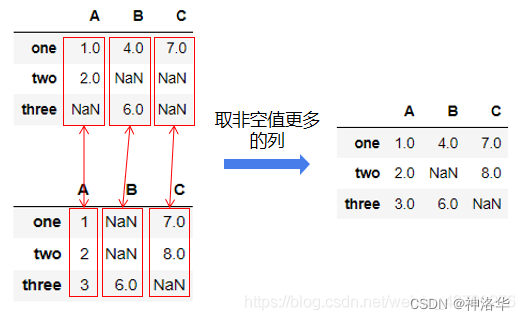
series_count=lambda s1,s2: s1 if s1.count()>=s2.count() else s2
df1.combine(df2,series_count)
| A | B | C | |
|---|---|---|---|
| 1 | 5.0 | 3.0 | 9.0 |
| 2 | 6.0 | NaN | 10.0 |
| 3 | 7.0 | 4.0 | NaN |
- 如果两个表的行索引和列索引不完全相同,则只对行列索引都相同的元素进行处理。下面的例子表示选出对应索引位置较小的元素:
df1 = pd.DataFrame({'A':[1,2], 'B':[3,4], 'C':[5,6]},index=[0,1])
df2 = pd.DataFrame({'B':[5,6], 'C':[7,8], 'D':[9,10]}, index=[1,2])
def choose_min(s1, s2):
s2 = s2.reindex_like(s1)
res = s1.where(s1<s2, s2)
res = res.mask(s1.isna()) # isna表示是否为缺失值,返回布尔序列
return res
df1.combine(df2, choose_min)
| A | B | C | D | |
|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | 4.0 | 6.0 | NaN |
| 2 | NaN | NaN | NaN | NaN |
choose=lambda s1,s2: s1 if s1.all()<=s2.all() else s2
df2.combine(df1,choose)
| A | B | C | D | |
|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | 5.0 | 7.0 | 9.0 |
| 2 | NaN | 6.0 | 8.0 | 10.0 |
- 调用已有函数,比如调用numpy中的函数
fmax()是numpy中实现的函数,用于比较两个数组,返回两个数组中相同索引的最大值,如果其中一个数组的值为空则返回非空的值,如果两个数组的值都为空则返回第一个数组的空值。
df1.combine(df2,np.fmax)
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 1.0 | 3.0 | 5.0 | NaN |
| 1 | 2.0 | 5.0 | 7.0 | 9.0 |
| 2 | NaN | 6.0 | 8.0 | 10.0 |
- 此外,设置 overtwrite 参数为 False 可以保留 被调用表 中未出现在传入的参数表中的列,而不会设置未缺失值:
df1.combine(df2, choose_min, overwrite=False)
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 1.0 | NaN | NaN | NaN |
| 1 | 2.0 | 4.0 | 6.0 | NaN |
| 2 | NaN | NaN | NaN | NaN |
6.4 第六章练习
6.4.1 美国疫情数据集
现有美国4月12日至11月16日的疫情报表(在 /data/us_report 文件夹下),请将 New York 的 Confirmed, Deaths, Recovered, Active 合并为一张表,索引为按如下方法生成的日期字符串序列:
date = pd.date_range('20200412', '20201116').to_series()
date = date.dt.month.astype('string').str.zfill(2
) +'-'+ date.dt.day.astype('string'
).str.zfill(2) +'-'+ '2020'
date = date.tolist()
date[:5]
['04-12-2020', '04-13-2020', '04-14-2020', '04-15-2020', '04-16-2020']
len(date) # 219行日期索引
219
# 遍历整个文件夹,将所有表纵向合并
data_dir='./input/us_report'
import os
df_all=pd.DataFrame()
for i,file in enumerate(os.listdir(data_dir)):
df=pd.read_csv(os.path.join(data_dir,file)) # file为csv文件名
if i ==0:
df_all=df
else:
df_all=pd.concat([df_all, df])
df_all
| Province_State | Country_Region | Last_Update | Lat | Long_ | Confirmed | Deaths | Recovered | Active | FIPS | Incident_Rate | People_Tested | People_Hospitalized | Mortality_Rate | UID | ISO3 | Testing_Rate | Hospitalization_Rate | Total_Test_Results | Case_Fatality_Ratio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Alabama | US | 2020-04-12 23:18:15 | 32.3182 | -86.9023 | 3563 | 93 | NaN | 3470.0 | 1.0 | 75.988020 | 21583.0 | 437.0 | 2.610160 | 84000001.0 | USA | 460.300152 | 12.264945 | NaN | NaN |
| 1 | Alaska | US | 2020-04-12 23:18:15 | 61.3707 | -152.4044 | 272 | 8 | 66.0 | 264.0 | 2.0 | 45.504049 | 8038.0 | 31.0 | 2.941176 | 84000002.0 | USA | 1344.711576 | 11.397059 | NaN | NaN |
| 2 | Arizona | US | 2020-04-12 23:18:15 | 33.7298 | -111.4312 | 3542 | 115 | NaN | 3427.0 | 4.0 | 48.662422 | 42109.0 | NaN | 3.246753 | 84000004.0 | USA | 578.522286 | NaN | NaN | NaN |
| 3 | Arkansas | US | 2020-04-12 23:18:15 | 34.9697 | -92.3731 | 1280 | 27 | 367.0 | 1253.0 | 5.0 | 49.439423 | 19722.0 | 130.0 | 2.109375 | 84000005.0 | USA | 761.753354 | 10.156250 | NaN | NaN |
| 4 | California | US | 2020-04-12 23:18:15 | 36.1162 | -119.6816 | 22795 | 640 | NaN | 22155.0 | 6.0 | 58.137726 | 190328.0 | 5234.0 | 2.812020 | 84000006.0 | USA | 485.423869 | 22.961176 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 53 | Virginia | US | 2020-11-17 05:30:30 | 37.7693 | -78.1700 | 204637 | 3806 | 22362.0 | 178469.0 | 51.0 | 2397.475772 | NaN | NaN | NaN | 84000051.0 | USA | 34422.429380 | NaN | 2938133.0 | 1.859879 |
| 54 | Washington | US | 2020-11-17 05:30:30 | 47.4009 | -121.4905 | 131532 | 2548 | NaN | 128984.0 | 53.0 | 1727.299386 | NaN | NaN | NaN | 84000053.0 | USA | 36482.390495 | NaN | 2778095.0 | 1.937171 |
| 55 | West Virginia | US | 2020-11-17 05:30:30 | 38.4912 | -80.9545 | 34460 | 585 | 23498.0 | 10377.0 | 54.0 | 1922.833339 | NaN | NaN | NaN | 84000054.0 | USA | 52390.289413 | NaN | 938911.0 | 1.697620 |
| 56 | Wisconsin | US | 2020-11-17 05:30:30 | 44.2685 | -89.6165 | 334562 | 2764 | 243841.0 | 87957.0 | 55.0 | 5746.084885 | NaN | NaN | NaN | 84000055.0 | USA | 66871.105795 | NaN | 3893526.0 | 0.826155 |
| 57 | Wyoming | US | 2020-11-17 05:30:30 | 42.7560 | -107.3025 | 23193 | 144 | 12902.0 | 10147.0 | 56.0 | 4007.367488 | NaN | NaN | NaN | 84000056.0 | USA | 26505.160179 | NaN | 153401.0 | 0.620877 |
12720 rows × 20 columns
# 选取需要的列,索引筛选'New York',然后重设索引
result=df_all[['Province_State','Confirmed','Deaths','Recovered','Active']]
new_values = iter(date)
result.set_index('Province_State').loc['New York'].reset_index().rename(index
=lambda x:next(new_values))
| Province_State | Confirmed | Deaths | Recovered | Active | |
|---|---|---|---|---|---|
| 04-12-2020 | New York | 189033 | 9385 | 23887.0 | 179648.0 |
| 04-13-2020 | New York | 195749 | 10058 | 23887.0 | 185691.0 |
| 04-14-2020 | New York | 203020 | 10842 | 23887.0 | 192178.0 |
| 04-15-2020 | New York | 214454 | 11617 | 23887.0 | 202837.0 |
| 04-16-2020 | New York | 223691 | 14832 | 23887.0 | 208859.0 |
| ... | ... | ... | ... | ... | ... |
| 11-12-2020 | New York | 545762 | 33975 | 81198.0 | 430589.0 |
| 11-13-2020 | New York | 551163 | 33993 | 81390.0 | 435780.0 |
| 11-14-2020 | New York | 556551 | 34010 | 81585.0 | 440956.0 |
| 11-15-2020 | New York | 560200 | 34032 | 81788.0 | 444380.0 |
| 11-16-2020 | New York | 563690 | 34054 | 81908.0 | 447728.0 |
219 rows × 5 columns
6.4.2 实现join函数
请实现带有 how 参数的 join 函数:
- 假设连接的两表无公共列
- 调用方式为 join(df1, df2, how=“left”)
- 给出测试样例
第七章、缺失数据
7.1 缺失信息的统计
缺失数据可以使用 isna 或 isnull (两个函数没有区别)来查看每个单元格是否缺失,结合 mean 可以计算出每列缺失值的比例:
%pwd
'E:\\数据分析\\joyful-pandas-master'
import pandas as pd
import numpy as np
df = pd.read_csv('data/learn_pandas.csv',
usecols = ['Grade', 'Name', 'Gender', 'Height',
'Weight', 'Transfer'])
df
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 0 | Freshman | Gaopeng Yang | Female | 158.9 | 46.0 | N |
| 1 | Freshman | Changqiang You | Male | 166.5 | 70.0 | N |
| 2 | Senior | Mei Sun | Male | 188.9 | 89.0 | N |
| 3 | Sophomore | Xiaojuan Sun | Female | NaN | 41.0 | N |
| 4 | Sophomore | Gaojuan You | Male | 174.0 | 74.0 | N |
| ... | ... | ... | ... | ... | ... | ... |
| 195 | Junior | Xiaojuan Sun | Female | 153.9 | 46.0 | N |
| 196 | Senior | Li Zhao | Female | 160.9 | 50.0 | N |
| 197 | Senior | Chengqiang Chu | Female | 153.9 | 45.0 | N |
| 198 | Senior | Chengmei Shen | Male | 175.3 | 71.0 | N |
| 199 | Sophomore | Chunpeng Lv | Male | 155.7 | 51.0 | N |
200 rows × 6 columns
df.isna().mean() # 查看缺失的比例
Grade 0.000
Name 0.000
Gender 0.000
Height 0.085
Weight 0.055
Transfer 0.060
dtype: float64
- 筛选单列缺失值
如果想要查看某一列缺失或者非缺失的行,可以利用 Series 上的isna或者notna进行布尔索引。例如,查看身高缺失的行:
df[df.Height.isna()].head()
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 3 | Sophomore | Xiaojuan Sun | Female | NaN | 41.0 | N |
| 12 | Senior | Peng You | Female | NaN | 48.0 | NaN |
| 26 | Junior | Yanli You | Female | NaN | 48.0 | N |
| 36 | Freshman | Xiaojuan Qin | Male | NaN | 79.0 | Y |
| 60 | Freshman | Yanpeng Lv | Male | NaN | 65.0 | N |
- 筛选多列缺失值
如果想要同时对几个列,检索出全部为缺失或者至少有一个缺失或者没有缺失的行,可以使用 isna, notna 和 any, all 的组合。例如,对身高、体重和转系情况这3列分别进行这三种情况的检索:
sub_set = df[['Height', 'Weight', 'Transfer']]
df[sub_set.isna().all(1)] # 全部缺失
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 102 | Junior | Chengli Zhao | Male | NaN | NaN | NaN |
df[sub_set.isna().any(1)].head() # 至少有一个缺失
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 3 | Sophomore | Xiaojuan Sun | Female | NaN | 41.0 | N |
| 9 | Junior | Juan Xu | Female | 164.8 | NaN | N |
| 12 | Senior | Peng You | Female | NaN | 48.0 | NaN |
| 21 | Senior | Xiaopeng Shen | Male | 166.0 | 62.0 | NaN |
| 26 | Junior | Yanli You | Female | NaN | 48.0 | N |
df[sub_set.notna().all(1)].head() # 没有缺失
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 0 | Freshman | Gaopeng Yang | Female | 158.9 | 46.0 | N |
| 1 | Freshman | Changqiang You | Male | 166.5 | 70.0 | N |
| 2 | Senior | Mei Sun | Male | 188.9 | 89.0 | N |
| 4 | Sophomore | Gaojuan You | Male | 174.0 | 74.0 | N |
| 5 | Freshman | Xiaoli Qian | Female | 158.0 | 51.0 | N |
7.2 删除缺失值
pandas 中提供了 dropna函数来删除缺失值。
dropna 的主要参数为:
- axis:轴方向(默认为0,即删除行)
- how:删除方式 ,主要有 any 和 all 两种参数可以选择。
- thresh:删除的非缺失值个数阈值 ( 非缺失值 没有达到这个数量的相应维度会被删除)
- subset:备选的删除子集
# 除身高体重至少有一个缺失的行:
df.dropna(how = 'any', subset = ['Height', 'Weight']).head()
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 0 | Freshman | Gaopeng Yang | Female | 158.9 | 46.0 | N |
| 1 | Freshman | Changqiang You | Male | 166.5 | 70.0 | N |
| 2 | Senior | Mei Sun | Male | 188.9 | 89.0 | N |
| 4 | Sophomore | Gaojuan You | Male | 174.0 | 74.0 | N |
| 5 | Freshman | Xiaoli Qian | Female | 158.0 | 51.0 | N |
df[sub_set.isna().any(1)].count()
Grade 35
Name 35
Gender 35
Height 18
Weight 24
Transfer 23
dtype: int64
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Grade 200 non-null object
1 Name 200 non-null object
2 Gender 200 non-null object
3 Height 183 non-null float64
4 Weight 189 non-null float64
5 Transfer 188 non-null object
dtypes: float64(2), object(4)
memory usage: 9.5+ KB
# 删除超过15个缺失值的列:
df.dropna(axis=1, thresh=df.shape[0]-15).head()
| Grade | Name | Gender | Weight | Transfer | |
|---|---|---|---|---|---|
| 0 | Freshman | Gaopeng Yang | Female | 46.0 | N |
| 1 | Freshman | Changqiang You | Male | 70.0 | N |
| 2 | Senior | Mei Sun | Male | 89.0 | N |
| 3 | Sophomore | Xiaojuan Sun | Female | 41.0 | N |
| 4 | Sophomore | Gaojuan You | Male | 74.0 | N |
7.2 缺失值的填充和插值
7.2.1 利用fillna进行填充
在 fillna 中有三个参数是常用的: value, method, limit 。
- value 为填充值,可以是标量,也可以是索引到元素的字典映射
- method 为填充方法,有用前面的元素填充 ffill 和用后面的元素填充 bfill 两种类型。和value不可同时用
- limit 参数表示连续缺失值的最大填充次数。
下面构造一个简单的 Series 来说明用法:
s = pd.Series([np.nan, 1, np.nan, np.nan, 2, np.nan],
list('aaabcd'))
s.values
array([nan, 1., nan, nan, 2., nan])
s.fillna(method='ffill',limit=1).values # 用前面的值向后填充,连续出现的缺失,最多填充一次
array([nan, 1., 1., nan, 2., 2.])
s.fillna(s.mean()).values # value为标量
array([1.5, 1. , 1.5, 1.5, 2. , 1.5])
有时为了更加合理地填充,需要先进行分组后再操作。例如,根据年级进行身高的均值填充:
df.groupby('Grade')['Height'].transform(
lambda x: x.fillna(x.mean())).head()
0 158.900000
1 166.500000
2 188.900000
3 163.075862
4 174.000000
Name: Height, dtype: float64
对一个序列以如下规则填充缺失值:如果单独出现的缺失值,就用前后均值填充,如果连续出现的缺失值就不填充,即序列[1, NaN, 3, NaN, NaN]填充后为[1, 2, 3, NaN, NaN],请利用 fillna 函数实现。
s = pd.Series([1, np.nan, 3, np.nan, np.nan])
s.fillna(method='ffill',limit=1).values
array([ 1., 1., 3., 3., nan])
7.2.2 interpolate插值填充
在关于 interpolate 函数的 文档 描述中,列举了许多插值法,包括了大量 Scipy 中的方法。由于很多插值方法涉及到比较复杂的数学知识,因此这里只讨论比较常用且简单的三类情况,即线性插值、最近邻插值和索引插值。其API如下:
Series.interpolate(method='linear', axis=0, limit=None, inplace=False, limit_direction=None, limit_area=None, downcast=None, **kwargs)
interpolate 常用参数如下:
method:插值方法。- ‘linear’ 、‘slinar’:线性插值,默认
linear。也就是前后元素的均值。 - ‘index’, ‘values’: 使用索引的实际数值。
- ‘pad’:使用现有值填充 NaN。
- ‘nearest’:最邻近插值法
- ‘linear’ 、‘slinar’:线性插值,默认
axisinplace:是否替换原数据limit_direction:控制填充方向 ,取值为forword(默认)、backward和both。分别代表向前、前后填充和双向双向限制插值填充limit:限制最大连续缺失值插值个数
s = pd.Series([np.nan, np.nan, 1,
np.nan, np.nan, np.nan,
2, np.nan, np.nan])
s.values
array([nan, nan, 1., nan, nan, nan, 2., nan, nan])
- 在默认线性插值法下分别进行 backward 和双向限制插值,同时限制最大连续条数为1:
s.interpolate(limit_direction='backward', limit=1).values
array([ nan, 1. , 1. , nan, nan, 1.75, 2. , nan, nan])
s.interpolate(limit_direction='both', limit=1).values
array([ nan, 1. , 1. , 1.25, nan, 1.75, 2. , 2. , nan])
- 第二种常见的插值是最近邻插补,即缺失值的元素和离它最近的非缺失值元素一样:
s.interpolate('nearest').values
array([nan, nan, 1., 1., 1., 2., 2., nan, nan])
- 索引插值,即根据索引大小进行线性插值。例如,构造不等间距的索引进行演示:
s = pd.Series([0,np.nan,np.nan,100],index=[0,1,20,100])
s
0 0.0
1 NaN
20 NaN
100 100.0
dtype: float64
s.interpolate(method='index').values # 填充结果和索引数值是一样的,前提是最后一个不是NaN
array([ 0., 1., 20., 100.])
- 填充时间索引。有关时间序列的其他话题会在第十章进行讨论,这里举一个简单的例子:
s = pd.Series([0,np.nan,10],
index=pd.to_datetime(['20200101',
'20200102',
'20200111']))
s
2020-01-01 0.0
2020-01-02 NaN
2020-01-11 10.0
dtype: float64
s.interpolate(method='index')
2020-01-01 0.0
2020-01-02 1.0
2020-01-11 10.0
dtype: float64
关于 polynomial和spline插值的注意事项
在 interpolate 中如果选用 polynomial 的插值方法,它内部调用的是 scipy.interpolate.interp1d(,,kind=order) ,这个函数内部调用的是 make_interp_spline 方法,因此其实是样条插值而不是类似于 numpy 中的 polyfit 多项式拟合插值;而当选用 spline 方法时, pandas 调用的是 scipy.interpolate.UnivariateSpline 而不是普通的样条插值。这一部分的文档描述比较混乱,而且这种参数的设计也是不合理的,当使用这两类插值方法时,用户一定要小心谨慎地根据自己的实际需求选取恰当的插值方法。
7.3 Nullable类型( Int, boolean 和 string)
7.3.1 缺失记号及其缺陷
- 在 python中的缺失值用
None表示,该元素除了等于自己本身之外,与其他任何元素不相等。如果你对一个包含 None 的数组进行累计操作,如sum() 或者 min() ,那么通常会出现类型错误。 - 在 numpy 中利用
np.nan来表示缺失值,该元素除了不和其他任何元素相等之外,和自身的比较结果也返回 False 。 - 在时间序列的对象中,pandas 利用
pd.NaT来指代缺失值,它的作用和np.nan是一致的。
- None :Python对象类型的缺失值
由于 None 是一个 Python 对象,所以不能作为任何 NumPy / Pandas 数组类型的缺失值,只能用于 ‘object’ 数组类型
在进行常见的快速操作时,这种类型比其他原生类型数组要消耗更多的资源
vals1 = np.array([1, None, 3, 4])
vals1
array([1, None, 3, 4], dtype=object)
- NaN :数值类型的缺失值
另一种缺失值的标签是 NaN (全称 Not a Number,不是一个数字),是一种按照 IEEE 浮点数标准设计、在任何系统中都兼容的特殊浮点数。你可以把 NaN 看作是一个数据类病毒——它会将与它接触过的数据同化。无论和 NaN 进行何种操作,最终结果都是 NaN。NumPy 也提供了一些特殊的累计函数,它们可以忽略缺失值的影响。
vals2 = np.array([1, np.nan, 3, 4])
vals2.dtype
dtype('float64')
np.nansum(vals2), np.nanmin(vals2), np.nanmax(vals2)
(8.0, 1.0, 4.0)
- Pandas中 NaN 与 None 的差异
虽然 NaN 与 None 各有各的用处,但是 Pandas 把它们看成是可以等价交换的,Pandas 会自动将None转换为NaN:
pd.Series([1, np.nan, 2, None])
0 1.0
1 NaN
2 2.0
3 NaN
dtype: float64
- pandas中的NaT
pd.to_timedelta(['30s', np.nan]) # Timedelta中的NaT
TimedeltaIndex(['0 days 00:00:30', NaT], dtype='timedelta64[ns]', freq=None)
pd.to_datetime(['20200101', np.nan]) # Datetime中的NaT
DatetimeIndex(['2020-01-01', 'NaT'], dtype='datetime64[ns]', freq=None)
为什么要引入 pd.NaT 来表示时间对象中的缺失呢?
- pandas中
object是一种混杂对象类型,如果出现了多个类型的元素同时存储在 Series 中,它的类型就会变成object。而np.nan的本身是一种浮点类型,而如果浮点和时间类型混合存储,如果不设计新的内置缺失类型来处理,就会变成含糊不清的 object 类型,这显然是不希望看到的。 - 由于
np.nan的浮点性质,如果在一个整数的 Series 中出现缺失,那么其类型会转变为float64;而如果在一个布尔类型的序列中出现缺失,那么其类型就会转为object而不是bool。
pd.Series([1, 'two'])
0 1
1 two
dtype: object
pd.Series([1, np.nan]).dtype
dtype('float64')
pd.Series([True, False, np.nan]).dtype
dtype('O')
因此,在进入 1.0.0 版本后, pandas 尝试设计了一种新的缺失类型 pd.NA 以及三种 Nullable 序列类型来应对这些缺陷,它们分别是 Int, boolean 和 string 。
Tips:虽然在对缺失序列或表格的元素进行比较操作的时候, np.nan 的对应位置会返回 False ,但是在使用 equals 函数进行两张表或两个序列的相同性检验时,会自动跳过两侧表都是缺失值的位置,直接返回 True :
s1 = pd.Series([1, np.nan])
s2 = pd.Series([1, 2])
s3 = pd.Series([1, np.nan])
s1 == 1
0 True
1 False
dtype: bool
s1.equals(s3)
True
7.3.2 Nullable类型的性质
从字面意义上看 Nullable 就是可空的,言下之意就是序列类型不受缺失值的影响。例如,在上述三个 Nullable 类型( Int, boolean 和 string)中存储缺失值,都会转为 pandas 内置的 pd.NA。
pd.Series([np.nan, 1], dtype = 'Int64') # "i"是大写的
Out[60]:
0 <NA>
1 1
dtype: Int64
pd.Series([np.nan, True], dtype = 'boolean')
Out[61]:
0 <NA>
1 True
dtype: boolean
pd.Series([np.nan, 'my_str'], dtype = 'string')
Out[62]:
0 <NA>
1 my_str
dtype: string
- 在 Int 的序列中,返回的结果会尽可能地成为 Nullable 的类型:
pd.Series([np.nan, 0], dtype = 'Int64') + 1
Out[63]:
0 <NA>
1 1
dtype: Int64
pd.Series([np.nan, 0], dtype = 'Int64') == 0
Out[64]:
0 <NA>
1 True
dtype: boolean
pd.Series([np.nan, 0], dtype = 'Int64') * 0.5 # 只能是浮点
Out[65]:
0 <NA>
1 0.0
dtype: Float64
- 对于 boolean 类型的序列而言,其和 bool 序列的行为主要有两点区别:
- 带有缺失的布尔列表无法进行索引器中的选择,而 boolean 会把缺失值看作 False :
s = pd.Series(['a', 'b'])
s_bool = pd.Series([True, np.nan])
s_boolean = pd.Series([True, np.nan]).astype('boolean')
# s[s_bool] # 报错
s[s_boolean] # 取出第一行,值为a,0是索引
0 a
dtype: object
- 在进行逻辑运算时, bool 类型在缺失处返回的永远是 False ,而 boolean 会根据逻辑运算是否能确定唯一结果来返回相应的值:
- True | pd.NA 中无论缺失值为什么值,必然返回 True
- False | pd.NA 中的结果会根据缺失值取值的不同而变化,即返回 pd.NA
- False & pd.NA 中无论缺失值为什么值,必然返回 False 。
s_boolean & True
Out[70]:
0 True
1 <NA>
dtype: boolean
s_boolean | True
Out[71]:
0 True
1 True
dtype: boolean
~s_boolean # 取反操作同样是无法唯一地判断缺失结果
Out[72]:
0 False
1 <NA>
- 关于
string类型的具体性质将在下一章文本数据中进行讨论。
一般在实际数据处理时,可以在数据集读入后,先通过 convert_dtypes 转为 Nullable 类型:
df = pd.read_csv('data/learn_pandas.csv')
df = df.convert_dtypes()
df.dtypes
School string
Grade string
Name string
Gender string
Height Float64
Weight Int64
Transfer string
Test_Number Int64
Test_Date string
Time_Record string
dtype: object
7.3.3 缺失数据的计算和分组
- 当调用函数 sum, prod 使用加法和乘法的时候,缺失数据等价于被分别视作0和1,即不改变原来的计算结果。
- 当使用累计函数时,会自动跳过缺失值所处的位置。
- 当进行单个标量运算的时候,除了
np.nan **0 和1 ** np.nan这两种情况为确定的值之外,所有运算结果全为缺失( pd.NA 的行为与此一致 ),并且 np.nan 在比较操作时一定返回 False ,而 pd.NA 返回 pd.NA :
s = pd.Series([2,3,np.nan,4,5])
s.sum()
Out[77]: 14.0
s.prod()
Out[78]: 120.0
s.cumsum()
Out[79]:
0 2.0
1 5.0
2 NaN
3 9.0
4 14.0
dtype: float64
- ·diff·, ·pct_change· 这两个函数虽然功能相似,但是对于缺失的处理不同,前者凡是参与缺失计算的部分全部设为了缺失值,而后者缺失值位置会被设为 0% 的变化率:
- 对于一些函数而言,缺失可以作为一个类别处理,例如在
groupby,get_dummies中可以设置相应的参数来进行增加缺失类别:
df_nan = pd.DataFrame({'category':['a','a','b',np.nan,np.nan],
'value':[1,3,5,7,9]})
df_nan
| category | value | |
|---|---|---|
| 0 | a | 1 |
| 1 | a | 3 |
| 2 | b | 5 |
| 3 | NaN | 7 |
| 4 | NaN | 9 |
df_nan.groupby('category',
dropna=False)['value'].mean() # pandas版本大于1.1.0
category
a 2
b 5
NaN 8
Name: value, dtype: int64
pd.get_dummies(df_nan.category, dummy_na=True)
| a | b | NaN | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | 0 | 0 | 1 |
7.4 练习
7.4.1 缺失值与类别的相关性检验
在数据处理中,含有过多缺失值的列往往会被删除,除非缺失情况与标签强相关。下面有一份关于二分类问题的数据集,其中 X_1, X_2 为特征变量, y 为二分类标签。
df = pd.read_csv('data/missing_chi.csv')
df.head()
| X_1 | X_2 | y | |
|---|---|---|---|
| 0 | NaN | NaN | 0 |
| 1 | NaN | NaN | 0 |
| 2 | NaN | NaN | 0 |
| 3 | 43.0 | NaN | 0 |
| 4 | NaN | NaN | 0 |
df.isna().mean()
X_1 0.855
X_2 0.894
y 0.000
dtype: float64
df.y.value_counts(normalize=True)
0 0.918
1 0.082
Name: y, dtype: float64

简单说是希望数据标签不受缺失值影响,即希望标签实际分布和理论上标签不受缺失值影响的理论值相近,即s->0。
len(df)
1000
from scipy.stats import chi2
def calculate(df,a):
S=0
# 前一个1和0表示特征缺失和不缺失,后一个1,0表示正负样本
df_notnan=df.dropna(how = 'any', subset = [f'X_{a}']) # 删除x1的缺失行
e_01=len(df_notnan.loc[df_notnan.y==1]) # x1特征不缺失正例
e_00=len(df_notnan.loc[df_notnan.y==0]) # x1特征不缺失负例
df_nan=df.set_index(f'X_{a}').loc[np.nan] # 筛选出x1为缺失值的行
e_11=len(df_nan.loc[df_nan.y==1]) # x1特征缺失正例
e_10=len(df_nan.loc[df_nan.y==0]) # x1特征缺失负例
sum1=sum([e_11,e_10,e_01,e_00]) # 其实就是样本总数1000
f_11=(e_11+e_10)*(e_11+e_01)/1000
f_10=(e_11+e_10)*(e_10+e_00)/1000
f_01=(e_01+e_00)*(e_11+e_01)/1000
f_00=(e_01+e_00)*(e_10+e_00)/1000
E=pd.DataFrame([[e_00,e_01],[e_10,e_11]],
index=pd.Index(['不缺失','缺失'],name='E'),
columns=['负例','正例'])
F=pd.DataFrame([[f_00,f_01],[f_10,f_11]],
index=pd.Index(['不缺失','缺失'],name='F'),
columns=['负例','正例'])
#S1=(((E**2).sum() + (F**2).sum()- 2*E@F)/F).sum() # 为啥E@F报错啊,非要转置
for i in [0,1]:
for j in [0,1]:
S+=(E.iloc[i,j]-F.iloc[i,j])**2/F.iloc[i,j]
return E,F,S,chi2.sf(S,1)
# 计算x1和x2的p值,可见x1不相关,可以删掉缺失值;而x2缺失值和标签相关。
# 原来p2是e-166次方,几乎就是0了。
E1,F1,S1,p1=calculate(df,1)
E2,F2,S2,p2=calculate(df,2)
S1,p1,S2,p2
(0.0012965662713972017,
0.9712760884395901,
753.3604636823281,
7.459641265637543e-166)
以下为参考答案:
# 将x1、x2两列的缺失和不缺失地方分别填充为NaN和NotNaN
cat_1 = df.X_1.fillna('NaN').mask(df.X_1.notna()).fillna("NotNaN")
cat_2 = df.X_2.fillna('NaN').mask(df.X_2.notna()).fillna("NotNaN")
# crosstab变形函数,默认状态下,可以统计元素组合出现的频数。
# margins=True时,边界计算每行和每列的和。可以看打印结果就知道啦
df_1 = pd.crosstab(cat_1, df.y, margins=True)
df_2 = pd.crosstab(cat_2, df.y, margins=True)
def compute_S(my_df):
S = []
for i in range(2):
for j in range(2):
E = my_df.iat[i, j]
F = my_df.iat[i, 2]*my_df.iat[2, j]/my_df.iat[2,2]
S.append((E-F)**2/F)
return sum(S) # 最终返回的是上面提到的S值
res1 = compute_S(df_1)
res2 = compute_S(df_2)
from scipy.stats import chi2
chi2.sf(res1, 1),chi2.sf(res2, 1)
(0.9712760884395901, 7.459641265637543e-166)
df_1
| y | 0 | 1 | All |
|---|---|---|---|
| X_1 | |||
| NaN | 785 | 70 | 855 |
| NotNaN | 133 | 12 | 145 |
| All | 918 | 82 | 1000 |
结果与 scipy.stats.chi2_contingency 在不使用Yates修正的情况下完全一致:
chi2_contingency函数参考此贴《Python - 列联表的独立性检验(卡方检验)》
结果第一个值为卡方值,第二个值为P值,第三个值为自由度,第四个为与原数据数组同维度的对应理论值
from scipy.stats import chi2_contingency
print(chi2_contingency(pd.crosstab(cat_1, df.y), correction=False)[1])
print(chi2_contingency(pd.crosstab(cat_2, df.y), correction=False)[1])
0.9712760884395901
7.459641265637543e-166
7.4.2 用回归模型解决分类问题
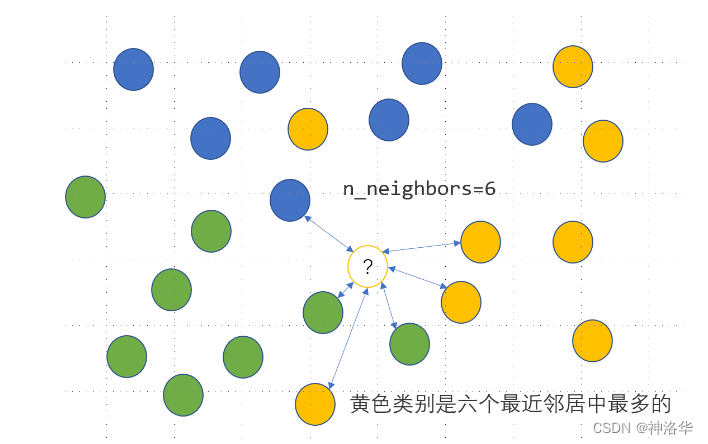
KNN 是一种监督式学习模型,既可以解决回归问题,又可以解决分类问题。对于分类变量,利用 KNN 分类模型可以实现其缺失值的插补,思路是度量缺失样本的特征与所有其他样本特征的距离,当给定了模型参数 n_neighbors=n 时,计算离该样本距离最近的 个样本点中最多的那个类别,并把这个类别作为该样本的缺失预测类别,具体如下图所示,未知的类别被预测为黄色:
上面有色点的特征数据提供如下:
!pip install openpyxl
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: openpyxl in d:\python\lib\site-packages (3.0.7)
Requirement already satisfied: et-xmlfile in d:\python\lib\site-packages (from openpyxl) (1.0.1)
import openpyxl
df = pd.read_excel('data/color.xlsx')
df.head()
| X1 | X2 | Color | |
|---|---|---|---|
| 0 | -2.5 | 2.8 | Blue |
| 1 | -1.5 | 1.8 | Blue |
| 2 | -0.8 | 2.8 | Blue |
| 3 | -0.3 | 0.8 | Blue |
| 4 | 1.1 | 2.1 | Blue |
已知待预测的样本点为 x 1 = 0.8 , x 2 = − 0.2 x_{1}=0.8,x_{2}=-0.2 x1=0.8,x2=−0.2 ,那么预测类别可以如下写出:
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=6)
clf.fit(df.iloc[:,:2].values, df.Color.values) # 前两列为特征,第三列为标签
clf.predict([[0.8, -0.2]])
array(['Yellow'], dtype=object)
- 对于回归问题而言,需要得到的是一个具体的数值,因此预测值由最近的n个样本对应的平均值获得。请把上面的这个分类问题转化为回归问题,仅使用
KNeighborsRegressor来完成上述的KNeighborsClassifier功能。
# df.Color.unique() # array(['Blue', 'Yellow', 'Green'], dtype=object)
#df[df.Color=='Blue'].loc['Color']=0 # 这种写法不好
df.loc[df.Color=='Blue','Color']=0
df.loc[df.Color=='Yellow','Color']=1
df.loc[df.Color=='Green','Color']=2
df.head()
| X1 | X2 | Color | |
|---|---|---|---|
| 0 | -2.5 | 2.8 | 0 |
| 1 | -1.5 | 1.8 | 0 |
| 2 | -0.8 | 2.8 | 0 |
| 3 | -0.3 | 0.8 | 0 |
| 4 | 1.1 | 2.1 | 0 |
from sklearn.neighbors import KNeighborsRegressor
clf = KNeighborsRegressor(n_neighbors=6)
clf.fit(df.iloc[:,:2].values, df.Color.values) # 前两列为特征,第三列为标签
pre=clf.predict([[0.8, -0.2]])
pre=round(pre[0])
pre # 结果四舍五入为1,对应黄色
1
- 请根据第1问中的方法,对 audit 数据集中的
Employment变量进行缺失值插补。
df = pd.read_csv('data/audit.csv')
df.head()
| ID | Age | Employment | Marital | Income | Gender | Hours | |
|---|---|---|---|---|---|---|---|
| 0 | 1004641 | 38 | Private | Unmarried | 81838.00 | Female | 72 |
| 1 | 1010229 | 35 | Private | Absent | 72099.00 | Male | 30 |
| 2 | 1024587 | 32 | Private | Divorced | 154676.74 | Male | 40 |
| 3 | 1038288 | 45 | Private | Married | 27743.82 | Male | 55 |
| 4 | 1044221 | 60 | Private | Married | 7568.23 | Male | 40 |
df.info() # 只有Employment列有100行缺失值
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2000 entries, 0 to 1999
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 2000 non-null int64
1 Age 2000 non-null int64
2 Employment 1900 non-null object
3 Marital 2000 non-null object
4 Income 2000 non-null float64
5 Gender 2000 non-null object
6 Hours 2000 non-null int64
dtypes: float64(1), int64(3), object(3)
memory usage: 109.5+ KB
df.Employment.value_counts() # 查看Employment列类别信息
Private 1411
Consultant 148
PSLocal 119
SelfEmp 79
PSState 72
PSFederal 69
Volunteer 1
Unemployed 1
Name: Employment, dtype: int64
不进行标准化处理最终结果也是一样的
# Marital列和Gender列要转为数值类型才能作为特征传入模型
# 也就是KNeighborsClassifier的所有特征的是数值型,标签也可以不是
def my_fillna(df,Norm):
ls_Ma=list(df.Marital.unique())
ls_Gender=list(df.Gender.unique())
for i,j in enumerate(ls_Ma):
df.loc[df.Marital==j,'Marital']=i
for k,l in enumerate(ls_Gender):
df.loc[df.Gender==l,'Gender']=k
if Norm==True: #是否进行标准化
df[['Age','Income','Hours']]=df[['Age','Income','Hours']].apply(
lambda x:(x-x.min())/(x.max()-x.min()))
else:
df=df
# 缺失的样本作为测试集,其它为训练集
from sklearn.neighbors import KNeighborsClassifier
train_df=df.dropna(how='any',subset=['Employment'])
test_df=df[df.Employment.isna()]
clf = KNeighborsClassifier(n_neighbors=6)
clf.fit(train_df.iloc[:,[1,3,4,5,6]].values, train_df.Employment.values) # 前两列为特征,第三列为标签
pred=clf.predict(test_df.iloc[:,[1,3,4,5,6]].values) # 预测缺失值
df.loc[df.Employment.isna(),'Employment']=list(pred) # 填充缺失值,这里必须写list(pre),否则报错
return pred
pred1=my_fillna(df,True)
df = pd.read_csv('data/audit.csv')
pred2=my_fillna(df,False)
pred1==pred2
array([False, False, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, False, True, True, True, True,
True, True, True, False, True, False, True, True, True,
True, True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
False, True, True, True, False, True, True, True, False,
True, True, True, True, True, True, True, True, True,
True, True, False, False, True, True, True, True, True,
True])
df.info() # 可见都已经填充完毕了
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2000 entries, 0 to 1999
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 2000 non-null int64
1 Age 2000 non-null int64
2 Employment 2000 non-null object
3 Marital 2000 non-null object
4 Income 2000 non-null float64
5 Gender 2000 non-null object
6 Hours 2000 non-null int64
dtypes: float64(1), int64(3), object(3)
memory usage: 109.5+ KB
以下是参考答案:
import pandas as pd
from sklearn.neighbors import KNeighborsRegressor
df = pd.read_csv('data/audit.csv')
res_df = df.copy()
df = pd.concat([pd.get_dummies(df[['Marital', 'Gender']]),
df[['Age','Income','Hours']].apply(
lambda x:(x-x.min())/(x.max()-x.min())), df.Employment],1)
df
| Marital_Absent | Marital_Divorced | Marital_Married | Marital_Married-spouse-absent | Marital_Unmarried | Marital_Widowed | Gender_Female | Gender_Male | Age | Income | Hours | Employment | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0.287671 | 0.168997 | 0.724490 | Private |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.246575 | 0.148735 | 0.295918 | Private |
| 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0.205479 | 0.320539 | 0.397959 | Private |
| 3 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0.383562 | 0.056453 | 0.551020 | Private |
| 4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0.589041 | 0.014477 | 0.397959 | Private |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1995 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0.616438 | 0.048832 | 0.397959 | Private |
| 1996 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0.246575 | 0.118356 | 0.397959 | Consultant |
| 1997 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0.205479 | 0.062267 | 0.438776 | Private |
| 1998 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0.232877 | 0.234715 | 0.448980 | Private |
| 1999 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0.123288 | 0.289972 | 0.346939 | Private |
2000 rows × 12 columns
X_train = df.query('Employment.notna()')# 为啥kaggle上会报错,本地没有
X_test = df.query('Employment.isna()')
df_dummies = pd.get_dummies(X_train.Employment)
stack_list = []
for col in df_dummies.columns:
clf = KNeighborsRegressor(n_neighbors=6)
clf.fit(X_train.iloc[:,:-1].values, df_dummies[col].values)
res = clf.predict(X_test.iloc[:,:-1].values).reshape(-1,1)
stack_list.append(res)
code_res = pd.Series(np.hstack(stack_list).argmax(1))
cat_res = code_res.replace(dict(zip(list(
range(df_dummies.shape[0])),df_dummies.columns)))
res_df.loc[res_df.Employment.isna(), 'Employment'] = cat_res.valuesb
res_df.isna().sum()
ID 0
Age 0
Employment 0
Marital 0
Income 0
Gender 0
Hours 0
dtype: int64