Linux-Linux内核-进程调度
文章目录
- Linux内核-进程调度
- 一、进程调度的原理
- (1)多任务分类
- (2)进程分类
- (3)优先级
- 二、进程状态
- (1)三状态模型
- (2)进程的切换
- (3)状态字段定义
- (4)ps aux中的stat
- 三、调度器scheduler
- (1)概述
- (2)调度器类的演变
- (4)5个调度器类、6个调度策略(算法)、3个调度实体
- (5)调度器入口
- (6)CFS调度器
- 四、抢占和上下文切换
- (1)上下文切换
- (2)抢占
- 五、与调度相关的系统调用
Linux内核-进程调度
一、进程调度的原理
最大限度的利用处理器时间,只要有可以执行的进程存在,那么就总会有进程正在执行。内核需要提供一种方法,在各个进程之间尽可能公平的去分配CPU时间,并且同时又要考虑不同的任务优先级。
(1)多任务分类
非抢占式任务;
抢占式任务;
Linux系统是抢占式任务系统。CPU时间片(timeslice)还没用完,就将当前运行的进程挂起,运行其他进程,这就是抢占(preemption)。时间片是实际分配到每个可运行进程的使用处理器的时间,很多操作系统采用了动态时间片计算方法,时间片的长短是根据机器的负载情况来动态计算的,而不是一个常数。
(2)进程分类
当涉及有关调度的问题的时候,会对参与调度的进程进行分类。如以下的分类:
【1】IO密集型和CPU密集型

如果只存在这两种类型的进程,那么调度器只需要保证不让CPU受限型长时间运行就可以了。但是,实际上有很多进程不符合上面这两种类型,而是介于中间。比如word之类的办公软件,经常等待着键盘输入(等待IO操作的完成),而且在任意时刻,又可能占用处理器疯狂处理着拼写检查和宏计算。
那么,怎么让调度器在两个矛盾的目标中间寻找一个相对平衡:响应速度和最大系统利用率。不同的系统有着不同的解决策略,有着复杂的调度算法来解决,如linux的CFS算法就能基本解决这个问题(进程数量不会巨大的情况下)。
【2】交互式/批处理/实时
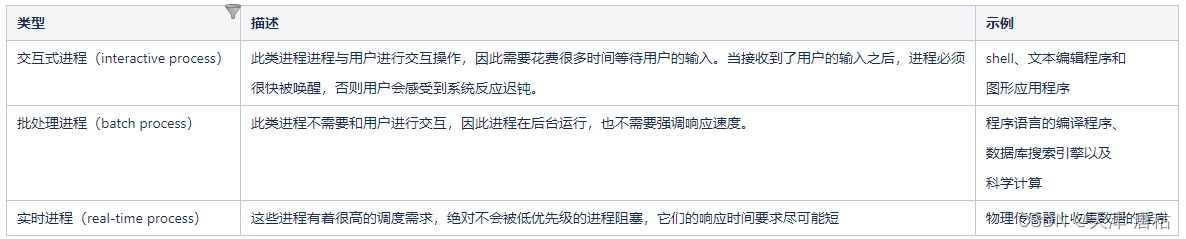
前两个类型统称为普通进程。对于实时进程的调度策略比较简单,因为实时进程的要求是尽可能快的被响应,因此只要基于优先级,根据进程的重要程度赋予不同的优先级,在调度的时候,总是选择优先级高的程序来执行,低优先级的进程是不可能抢占高优先级的进程,因此,FIFO或者Round Robin的调度策略就可以满足实时进程的调度需求。
但是,普通进程的调度策略就较为麻烦了,因为普通进程不会简单的只根据优先级来调度,而是要讲究对CPU的公平占平,否则很容易出现进程饥饿的情况,这种情况下会带给用户系统很卡,反应很慢的用户体验。具体的调度策略,在下面详述。
另外,如果调度的程序中存在实时进程,则实时进程总是在普通进程之前被调度。
(3)优先级
根据进程的重要性和其对处理器的时间需求来对进程进行分级。Linux中采用了两种

这里需要强调一点,nice值(静态优先级)不是PRI(priority,动态优先级),但nice值会影响到进程PRI的变化,起到干预CPU时间分配的作用,但是实际的执行情况是由PRI决定的。PRI是进程的动态优先级指标,PRI越小,优先级越高,进程被执行的可能性越高。NI或者说nice,代表着进程可被执行的优先级修正值,PRI(new)=PRI(old)+nice。这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行。
动态值PRI进程会被内核修改,而静态值NI则是一经设定就不会被内核修改了,直到被用户重新设定。使用ps -l的命令可以看到PRI和NI。
【1】修改将要执行进程的优先级命令——nice
语 法:nice [-n <优先等级>][–help][–version][执行指令]
补充说明:nice指令可以改变程序执行的优先权等级。
参 数:-n<优先等级>或-<优先等级>或–adjustment=<优先等级> 设置欲执行的指令的优先权等级。等级的范围从-20-19,其中-20最高,19最低,只有系统管理者可以设置负数的等级。
【2】调整已经存在进程的nice值——renice
功能说明:调整优先权。
语 法:renice [优先等级][-g <程序群组名称>…][-p <程序识别码>…][-u <用户名称>…]
补充说明:renice指令可重新调整程序执行的优先权等级。预设是以程序识别码指定程序调整其优先权,您亦可以指定程序群组或用户名称调整优先权等级,并修改所有隶属于该程序群组或用户的程序的优先权。等级范围从-20–19,只有系统管理者可以改变其他用户程序的优先权,也仅有系统管理者可以设置负数等级。
参 数:
-g <程序群组名称> 使用程序群组名称,修改所有隶属于该程序群组的程序的优先权。
-p <程序识别码> 改变该程序的优先权等级,此参数为预设值。
-u <用户名称> 指定用户名称,修改所有隶属于该用户的程序的优先权。
【3】使用top命令更改已存在进程的nice
- top
- #进入top后按“r”–>输入进程PID–>输入nice值
二、进程状态
(1)三状态模型
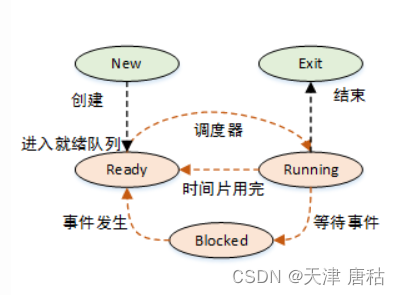
(2)进程的切换
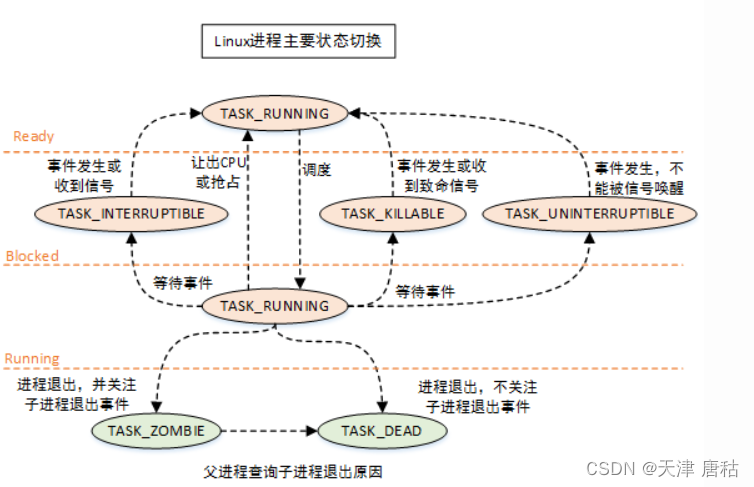
(3)状态字段定义
/* Used in tsk->state: /
#define TASK_RUNNING 0x0000
#define TASK_INTERRUPTIBLE 0x0001
#define TASK_UNINTERRUPTIBLE 0x0002
/ Used in tsk->exit_state: /
#define EXIT_DEAD 0x0010
#define EXIT_ZOMBIE 0x0020
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/ Used in tsk->state again: /
#define TASK_PARKED 0x0040
#define TASK_DEAD 0x0080
#define TASK_WAKEKILL 0x0100
#define TASK_WAKING 0x0200
#define TASK_NOLOAD 0x0400
#define TASK_NEW 0x0800
#define TASK_STATE_MAX 0x1000
/ Convenience macros for the sake of set_current_state: */
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
#define TASK_IDLE (TASK_UNINTERRUPTIBLE | TASK_NOLOAD)
(4)ps aux中的stat
Linux中的ps命令是process status的缩写,是用来列出系统中当前运行进程的命令。Linux上进程存在五种状态:运行、中断、不可中断、僵死、停止;对应的PS工具标识进程有以下的状态码:
D 不可中断睡眠 (通常是在IO操作) 收到信号不唤醒和不可运行, 进程必须等待直到有中断发生
R 正在运行或可运行(在运行队列排队中)
S 可中断睡眠 (休眠中, 受阻, 在等待某个条件的形成或接受到信号)
T 已停止的 进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行
W 正在换页(2.6.内核之前有效)
X 死进程 (未开启)
Z 僵尸进程 进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放BSD风格的
< 高优先级(not nice to other users)
N 低优先级(nice to other users)
L 页面锁定在内存(实时和定制的IO)
s 一个信息头,包含子进程
l 多线程(使用 CLONE_THREAD,像NPTL的pthreads的那样)
- 在前台进程组
三、调度器scheduler
(1)概述
Linux调度器是以模块的方式提供的,这允许不同类型的进程可以针对型的选择调度算法。调度器类提供不同的调度算法,像CFS就是一个针对普通进程的调度器类(定义在kernel/sched_fair.c中),在Linux中称之为SCHED_NORMAL(在POSIX中称为SCHED_OTHER)。
每个调度器都有一个优先级,内核会选择优先级最高的调度器,然后由该调度器调度进程并执行。
调度器主要解决两个问题:
调度策略,即决定为每个进程分配多少运行时间,何时切换下一个进程,切换哪个进程;上下文切换,即从进程A切换到进程B的时候,要保证进程B的执行环境和上次被挂起的时候完全一致,比如寄存器中的内容,虚拟地址空间的各个数据结构;
(2)调度器类的演变
一开始的调度器是复杂度为O(n)的始调度算法(实际上每次会遍历所有任务,所以复杂度为O(n)), 这个算法的缺点是当内核中有很多任务时,调度器本身就会耗费不少时间,所以,从linux2.5开始引入赫赫有名的O(1)调度器。 现代进程调度器有两个通用的概念: 进程优先级和时间片 ,时间片是指进程运行多少时间,进程创建之后就被赋予一个时间片,优先级更高的进程运行的更频繁,而且往往拥有更多的时间片,这就是 O(1) 调度算法的实质。
很明显,除了让优先级更高的进程可以尽可能抢占之外,O(1) 调度算法还根据优先级来给时间片加权。但是,前面提到,传统的调度算法使用的 绝对的时间长度,这也引起了部分问题,比如有两个不同优先级的进程,一个 nice 值为 0,另一个为 1,那么他们经过加权的时间片长度分别是 100ms 和 95ms,他们的时间片非常接近,但是如果将 nice 值改为 18 和 19,这时他们的时间片变为了 10ms 和 5 ms,这时前者是后者两倍的运行时间,因此,尽管 nice 值只相差 1 但最后的结果却是差别巨大。因此 CFS 完全摒弃时间片的绝对分配,而是分配处理器的使用比重。
CFS调度器Completely Fair Scheduler. 这个也是在2.6内核中引入的,具体为2.6.23,即从此版本开始,内核使用CFS作为它的默认调度器,O(1)调度器被抛弃了, 其实CFS的发展也是经历了很多阶段,最早期的楼梯算法(SD), 后来逐步对SD算法进行改进出RSDL(Rotating Staircase Deadline Scheduler), 这个算法已经是”完全公平”的雏形了, 直至CFS是最终被内核采纳的调度器, 它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越。

(3)Linux的两个调度器
可以用两种方法来激活调度
- 一种是直接的, 比如进程打算睡眠或出于其他原因放弃CPU
- 另一种是通过周期性的机制, 以固定的频率运行, 不时的检测是否有必要
因此当前linux的调度程序由两个调度器组成:主调度器,周期性调度器(两者又统称为通用调度器(generic scheduler)或核心调度器(core scheduler)),并且每个调度器包括两个内容:调度框架(其实质就是两个函数框架)及调度器类。
(4)5个调度器类、6个调度策略(算法)、3个调度实体
【1】调度器类
所谓调度,就是按照某种调度的算法,从进程的就绪队列中选取进程分配CPU,主要是协调对CPU等的资源使用。进程调度的目标是最大限度利用CPU时间。
内核默认提供了5个调度器,Linux内核使用struct sched_class来对调度器进行抽象:
-Stop调度器, stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占;
-Deadline调度器, dl_sched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行;
-RT调度器, rt_sched_class:实时调度器,为每个优先级维护一个队列;
-CFS调度器, cfs_sched_class:完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念;
-IDLE-Task调度器, idle_sched_class:空闲调度器,每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程;
【2】调度算法
Linux内核提供了一些调度策略供用户程序来选择调度器,其中Stop调度器和IDLE-Task调度器,仅由内核使用,用户无法进行选择:
-SCHED_DEADLINE:限期进程调度策略,使task选择Deadline调度器来调度运行;
-SCHED_RR:实时进程调度策略,时间片轮转,进程用完时间片后加入优先级对应运行队列的尾部,把CPU让给同优先级的其他进程;
-SCHED_FIFO:实时进程调度策略,先进先出调度没有时间片,没有更高优先级的情况下,只能等待主动让出CPU;
-SCHED_NORMAL:普通进程调度策略,使task选择CFS调度器来调度运行;
-SCHED_BATCH:普通进程调度策略,批量处理,使task选择CFS调度器来调度运行;
-SCHED_IDLE:普通进程调度策略,使task以最低优先级选择CFS调度器来调度运行;
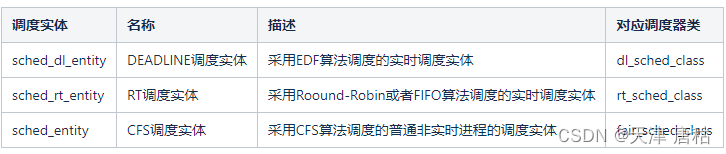
【3】调度实体
调度器不限于调度进程, 还可以调度更大的实体, 比如实现组调度: 可用的CPUI时间首先在一半的进程组(比如, 所有进程按照所有者分组)之间分配, 接下来分配的时间再在组内进行二次分配.
linux中针对当前可调度的实时和非实时进程, 定义了类型为seched_entity的3个调度实体
(5)调度器入口
进程调度的统一入口是__schedule函数,它会选择一个最高优先级的调度类,每个调度类都有自己的可运行队列,然后可以知道下一个运行的进程。__schedule函数(源代码 | kernel/sched/core.c | v4.19 )。
pick_next_task主要功能是从发生调度的CPU运行队列中选择最高优先级的进程。系统中的调度顺序为:实时进程→普通进程→空闲进程。(rt_sched_class → fair_sched_class → idle_sched_class )
(6)CFS调度器
【1】原理
CFS 的出发点基于一个简单的理念: 进程调度的效果应该如同系统具备一个理想中的完美多任务处理器 。在这种系统中,每个进程将获得 1/n 的处理器时间(如果有 n 个进程)。比如我们有两个可运行进程,先运行其中一个 5ms,然后再运行另外一个进程 5ms,如果进程切换够快,那么在 10ms 内仿佛可以同时运行两个进程而且各自使用了处理器一半的能力。
当然这并不现实,首先一个处理器无法真正的同时运行多个任务,而且进程间切换是有损耗的,也无法做到无限快的切换,CFS 采用了折中的做法:让每个进程运行一段时间、循环轮转、选择运行最少的进程作为下一个运行进程,而不再采用分配给每个进程时间片的做法。 CFS 在所有可以运行的进程总数基础上计算出一个进程应该运行多久,而不是依靠 nice 值来计算时间片(nice 值只影响比重而不是绝对值)。
每个进程都按其权重在全部可运行进程中所占比例的 “时间片” 来运行,为了准确的计算时间片,CFS 为完美多任务中的无限小调度周期的近似值设定了一个目标,称为:目标延迟。越小的调度周期带来越好的交互性,同时也越接近完美的多任务(但同时需要更多的切换开销)。举例我们将目标延迟定位 20ms,那么如果有两个同优先级的进程,那么每个进程在被抢占前只能运行 10ms,而如果有 5 个这样的任务,那每个任务只能允许 4ms。
但是,上面这个例子中,如果进程数目非常多,比如超过 20 个,那么每个进程获得运行时间还不到 1ms,甚至可能小于进程切换所消耗的时间。当然,Linux 为了避免这种事情发生,设定了一个底线,被称为最小粒度(一般默认 1ms)。因此,只能说 CFS 在进程数目不巨大的情况下比较公平(一般系统中也就运行几百个进程,这种规模下 CFS 还是非常公平的)。而对于不同优先级的进程中,CFS 也是表现良好,比如目标延迟依然为 20ms,这两个进程一个 nice 为 0,另一个为 5,那么后者的权重将是前者的 1/3,即两个进程分别获得了 15ms(20 * 2/3) 和 5ms(20 * 1/3) 的处理器时间。而如果两个进程的 nice 值分别为 10 和 15,因为权重关系没有改变,因此两个进程依然分别获得 15ms 和 5ms 的处理器时间。所以,nice 值 不再影响调度决策,只有相对值才会影响处理器时间的分配比例。
在 CFS 下,任何进程所获得的处理器时间是由它自己和其他所有可运行进程 nice 值的相对差值决定的。nice 值由算数加权变为了几何加权,正是将时间片的绝对值变为了使用比,使得在多进程环境下有了更低的调度延迟。
【2】CFS的实现
相关的代码在 kernel/sched_fair.c 中,我们的关注点主要下面四个地方:
- 运行时间的记录
- 选择投入运行的进程
- 调度器的选择
- 睡眠与唤醒
<1>运行时间的记录
CFS 的核心在于 CPU 的使用比,那么对于进程的运行时间的记录非常重要。多数 Unix 系统,分配一个绝对时间的时间片给进程,当每次系统时钟节拍发生时,时间片都会被减少一个节拍周期。每当一个进程的时间片被减少到 0,就会被尚未减少到 0 的进程抢占。
但 CFS 并没有绝对的时间片,但它依然需要对每个进程的运行时间记账,以确保每个进程只在公平分配给它的处理器运行时间内运行。而记账的信息会保存其结构体指针 se (在进程的 task_struct 中)。
在结构体中,有一个重要的成员变量 vruntime,即是记录了该进程的总运行时间(花在运行上的时间和),而且这个时间经过了加权(优先级、机器负载等因素)。虚拟时间是以 ns 为单位的,因此 vruntime 和系统定时器节拍不再相关。
内核通过定时调用 update_curr() 函数(定义在 kernel/sched_fair.c)来更新进程的 vruntime,该函数计算了当前进程的执行时间,并将调用 __update_curr() 获得根据机器负载(可运行的进程总数)对运行时间加权后的值,然后将该值与原有的 vruntime 相加获得新的 vruntime。update_curr函数是由系统定时器周期性调用的,无论进程在哪种状态。
<2>进程的选择
在进程选择方面,CFS调度算法核心是选择最小vruntime的任务,CFS是通过红黑树来组织可运行进程队列,并利用其迅速找到最小的vruntime值的进程(红黑树最左侧的叶子节点)。

<3>调度器的选择
正如前面讲到的,内核支持多种调度器,而 CFS 只不过是其中一种。进程调度的主要入口点是定义在 kernel/sched.c 下的函数 schedule(),它完成的事情就是选择一个进程,并将其投入运行,而它的逻辑非常简单:
- 调用 pick_next_task() 获得一个 task
- 将这个 task 投入运行而真正和调度器相关的逻辑在 pick_next_task() 中,pick_next_task() 做了下面的事情:
- 按照调度类的优先级遍历
- 只有该调度类下有可运行进程,立马返回
pick_next_task() 为 CFS 做了一个简单的优化,如果所有的可运行任务都在 CFS 调度器下,就不再遍历其他调度类,而是不停的从 CFS 调度器里拿任务。
<4>睡眠与唤醒
休眠(阻塞)的进程处于一个特殊不可执行的状态,阻塞的原因可能很多,比如等待一个信号,或者等待用户键盘的输入等,无论哪种,内核的操作是相同的:进程把自己标记为休眠状态,从可执行红黑树中移除并放入等待队列,然后调用 schedule() 选择和执行一个其他进程。休眠有两种进程状态:TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE,无论哪种状态,休眠的进程都在同一个等待队列上。
等待队列 是由等待某些事件发生的进程组成的简单链表,当与等待队列相关的事件发生时,队列上的进程会被唤醒,为了避免产生竞争条件,休眠和唤醒的实现不能有批量。但如果简单的实现,有可能导致在判定条件为真后,进程却开始了休眠,那么就会使进程无限期地休眠下去,因此进程按以下处理加入等待队列:
1.调用宏 DEFINE_WAIT() 创建一个等待队列的项
2.调用 add_wait_queue() 把自己加入到队列中
3.调用 prepare_to_wait() 将进程的状态变为 TASK_INTERRUPTIBLE 或 TASK_UNINTERRUPTIBLE
4.如果状态被设置的是 TASK_INTERRUPTIBLE 则信号唤醒(伪唤醒),以检查并处理信号
5.唤醒之后检查等待条件是否为真,是则跳出循环,否则再次调用 schedule() 并一直重复
6.跳出循环(条件满足)后,进程将自己设置为 TASK_RUNNING 并调用 finish_wait() 方法把自己移除等待队列,唤醒操作通过 wake_up() 完成,它会唤醒指定的等待队列上的所有进程,wake_up() 的主要逻辑在调用的 try_to_wake_up() 中:
7.将进程设置为 TASK_RUNNING
8.调用 enqueue_task() 将此进程放入红黑树中
9.如果唤醒的进程比当前执行的进程优先级高则立马抢占
10.设置 need_resched 标记(标记是否触发重新调度)
不过如上面提到的,因为有伪唤醒,所以进程被唤醒不一定都是因为等待的条件达成。
四、抢占和上下文切换
(1)上下文切换
上下文切换指的是一个可执行进程切换到另一个可执行进程。上下文切换函数context_switch() 定义在 kernel/sched.c,他基本完成了两件事情:
- 调用 switch_mm() 把虚拟内存从上一个进程映射切换到新进程中
- 调用 switch_to() 从上一个进程处理器状态切换到新进程的处理器状态(包含栈信息、寄存器信息等)
(2)抢占
内核即将返回用户空间的时候,如果 need_resched 被标记,则会导致 schedule() 被调用,此时就会发生用户抢占。因为从内核返回到用户空间的进程知道自己是安全的,它既可以继续执行,也可以选择一个新进程去执行,所以无论是系统调用后还是中断后,进程都可以检查 need_resched 被标记,来判断是否需要重新调用 schedule()。总之,一般用户抢占发生在:
- 从系统调用返回用户空间
- 从中断处理程序返回用户空间
因为 Linux 完整的支持内核抢占,所以只要调度是安全的(没有持有锁),内核就可以在任何时间抢占正在执行的任务。Linux 的锁的判断是通过计数实现的,在 thread_info 中引入了 preempt_count 来记录持有的锁,当该值为 0 的时候,则该进程是安全的,而恰好该新进程设置了 need_resched 标记,那么当前进程可以被抢占。
如果内核中的进程被阻塞了,或显式调用了 schedule(),则内核会发生显式的抢占。显式的抢占从来都是受支持的,因为如果一个函数显式的调用 schedule(),说明它自己是清楚可以被安全的抢占。
内核的抢占一般发生在: - 中断处理程序正在执行,且返回内核空间之前
- 内核代码再一次具有可抢占性的时候
- 如果内核中的任务显式调用 schedule() 的时候
- 内核中的任务阻塞时
五、与调度相关的系统调用
Linux提供了一个系统调用族,用于管理与调度程序的相关参数。这些系统调用可以用来操作和处理进程优先级、调度策略及处理器绑定,同时还提供了显式地将处理器交给其他进程的机制。