Hadoop和Spark的对比
Hadoop
Spark
场景
大数据数据集的批处理
迭代计算、流计算
编程范式
Map+Reduce API较低层,适应性差
RDD组成DAG有向无环图,API顶层,方便使用
存储
中间结果在磁盘,延迟大
RDD结果在内存,延迟小
运行方式
Task以进程方式维护,启动任务慢
Task以线程方式维护,启动快
1. 原理比较
Hadoop和Spark都是并行计算,
Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束;
好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,
但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。
Spark的任务称为application,一个SparkContext对应一个application;
application中存在多个job,每触发一次行动算子就会产生一个job;
每个job中有多个stage,stage是shuffle过程中DAGScheduler通过RDD之间的依赖关系划分job而来的,stage数量=宽依赖(shuffle)数量+1 (默认有一个ResultStage);
每个stage里面有多个task,组成taskset,由TaskScheduler分发到各个executor中执行;
executor的生命周期是和application一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存进行计算。
Spark基于线程的方式计算是为了数据共享和提高执行效率,
Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
2. 应用场景
Hadoop MapReduce 其设计初衷是一次性数据计算(一个job中 只有一次map和reduce),并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题(使用磁盘交互,进度非常慢)。
Spark 应运而生,Spark 就是在传统的MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD 计算模型。
Spark将job的结果放到了内存当中,为下一次计算提供了更加便利的处理方式,所以Spark做迭代效率更高。
Hadoop适合处理静态数据,对于迭代式流式数据的处理能力差;
Spark通过在内存中缓存处理的数据,提高了处理流式数据和迭代式数据的性能;
3. 处理速度
Hadoop是磁盘级计算,计算时需要在磁盘中读取数据;其采用的是MapReduce的逻辑,把数据进行切片计算用这种方式来处理大量的离线数据.;
Spark它会在内存中以接近“实时”的时间完成所有的数据分析。Spark的批处理速度比MapReduce快近10倍,【内存中】的数据分析速度则快近100倍。
4. 启动速度
Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop 采用创建新的进程的方式。
5. 中间结果存储
Hadoop中 ,中间结果存放在HDFS中,每次MR都需要刷写-调用
Spark中间结果存放优先存放在内存中,内存不够再存放在磁盘中,不放入HDFS,避免了大量的IO和刷写读取操作;
6. 根本差异
Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
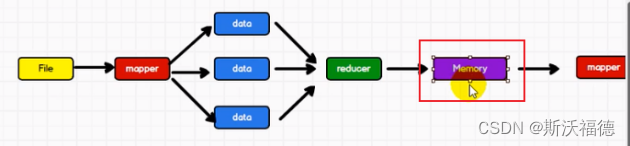
Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间的数据交互都要依赖于磁盘交互
Spark能否代替Hadoop ?
但是Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark 并不能完全替代 MR
参考:https://blog.csdn.net/weixin_42058550/article/details/121951509