spring cloud
一、前言
1.应用分类
1.1单体应用框架
- 复杂性高:整个项目包含的模块非常多、模块的边界模糊,依赖关系不清晰,代码混乱地堆砌到一起,修改 Bug 或新增功能都可能带来隐含的缺陷;
- 技术债务:随着时间的推移、人员的变更,会逐渐形成应用程序的技术债务,而且越积越多,Not broken,dont fix(不坏不修),这在软件开发中非常常见,已使用的系统设计或代码难以被修改,因为应用程序中的其它模块可能会以意料之外的方式在使用它;
- 部署效率低:随着代码的增多,构建和部署的时间也会增多,每次修复 Bug 或新增功能都要重新部署整个应用,全部署的方式耗时长、影响范围大、风险高,这儿使得单体应用上线部署效率很低;
- 可靠性差:某个应用 Bug,可能会导致整个应用崩溃;
- 扩展能力受限:单体应用只能作为一个整体扩展,无法根据业务模块的需要进行伸缩,例如:应用中有的模块是计算密集型的,需要强劲的 Cpu,有的模块是 IO 密集型的,需要更大的内存,由于这些模块都部署在一起,不得不在硬件的选择上做妥协;
- 阻碍技术创新:单体应用往往使用统一的技术平台或方案解决所有问题,团队中的每个人都必须使用相同的语言和技术框架,要想引入新的东西比较困难,例如:一个 Struts2 构建,有 100w 行代码的单体应用,如果想换成 Spring Boot,毫无疑问,切换的成本是非常高的;
1.2分布式服务架构
- 将一个单一应用程序开发为一组小型服务的方法,每个服务运行在自己的进程中,服务间通信采用轻量级通信机制(通常为 HTTP 资源 Api),这些服务通过全自动部署机制独立部署,共用一个集中式的管理,服务可以使用不同语言开发,使用不同的数据存储技术;
- 搜索引擎、电商网站、微博、微信、O2O 平台……凡是涉及到大规模用户、高并发访问的,无一不是分布式,“大系统小做”,对于一个大的复杂系统,首先想到的就是对其分拆,拆成多个子系统,每个子系统自己的存储、Service、接口层,各个子系统独立开发、测试、部署、运维;
- 优点:易于扩展、部署简单、技术异构性、从团队管理角度讲,也可以不同团队用自己熟悉的语言体系,团队之间基于接口进行协作,职责清晰,各司其职;
2、基础理论
2.1分布式和集群
- 集群是多台计算机完成一样的工作,提高效率和安全性,需要考虑一致性的问题;
- 分布式是多台计算机协同完成工作,提高效率和扩展性,需要考虑事务的问题;
2.2 一致性
强一致性、弱一致性、最终一致性;
2.3 ACID:
- 事务的四大特性,原子性、一致性、隔离性、持久性,MySQL 通过 InnoDB 日志和锁来保证事务的强一致性;
2.4 CAP 理论;
- 1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标:Consistency(一致性)、Availability(有效性)、Partition tolerance(分区容错性:单个组件不可用,依然能完成操作,分区容错性是分布式系统的根本);
-
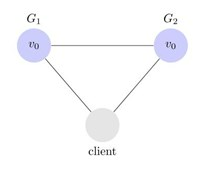
- 在 G1 和 G2 通讯中,有可能无法成功(断电、出错、网络延迟等),有可能此时 Client 已经发起查询操作;
- 在同步服务器时候,需要停掉 G2 的读写操作,无法保证有效性;
- 允许 G2 查询得到未同步之前的数据,无法保证一致性;
-
- 两个分支;
- CP 架构:放弃可用性,追求一致性和分区容错性;
- AP 架构:放弃强一致,追求分区容错性和可用性,这是很多分布式系统设计时的选择;
- BASE 理论:BA(Basic Available 基本可用)、S(Soft State 柔性状态,同一数据的不同副本的状态,不需要实时一致)、E(Eventual Consisstency 最终一致性);
- 酸碱平衡:ACID && BASE 理论平衡,比如交易系统需要强一致性,遵循 ACID,注册成功后发送邮件只需遵循 BASE 理论即可;
3.系统架构
3.1物理相关
- 负载均衡器;
- Linux HA:又称“双机热备”,是两台机器装上同样的系统,配好后通过“心跳线”互相监测,数据存放在共享阵列库中,当主服务器出现问题时,从服务器会接管主服务器上的所有服务;
- 多机房:同城灾备,异地灾备;
3.2 存储
- 存储分类
- Nosql:内存数据库(Redis)、文件型数据库(MongoDB);
- Sql:Mysql、Sql Server、Oracal,会设计到分库分表的几个关键性的问题:切分维度,Join 的处理,分布式事务;
- 读写分离:对传统的单机 Mysql 数据库,读和写是完全同步的,写进去的内容,立马就可以读到,但在高并发情况下,或者读和写并不需要完全同步的情况,就可以分开存储,采用读写分离;
- 缓存:缓存大家都不陌生,遇到性能问题,大家首先想到的就是缓存;
- 重写轻读 VS 重读轻写;
- 重写轻读:本质就是“空间换时间“,你不是计算起来耗时,延迟高吗,那我可以提前计算,然后存储起来,取的时候,直接去取;
- 重读轻写:我们通常对 Mysql 的用法,写的时候,简单,查的时候,做复杂的 Join 计算,返回结果,这样做的好处是容易做到数据的强一致性,不会因为字段冗余,造成数据的不一致,但是性能可能就是问题;
- 冷热分离:比如定期把 Mysql 中的历史数据,同步到 Hive;
3.3 Service
- 负载均衡;
- 分布式事务;
- 并发:通过设计保证系统能够同时并行处理很多请求,垂直扩展(提升单机处理能力)、水平扩展(增加服务器数量,线性扩充系统性能);
- 同步 VS 异步:因为非实时,我们就可以做异步,比如使用消息队列,比如使用后台的 Job,周期性处理某类任务;
- Push vs Pull
- 在所有分布式系统中,都涉及到一个基本问题:节点之间(或者 2 个子系统之间)的状态通知,比如一个节点状态变更了,要通知另外一个节点;
- Pull: 节点 B 周期性的去询问节点 A 的状态;
- Push: 节点 A 状态变了, Push 给节点 B;
- 批量:批量其实也是在线/离线的一种思想,把实时问题,转化为一个批量处理的问题,从而降低对系统吞吐量的压力,比如 Kafka 中的批量发消息,比如广告扣费系统中,把多次点击累积在一起扣费;
- 限流:现在很多电商都会有秒杀活动,秒杀的一个特点就是商品很少,但短时间内流量暴增,服务器完全处理不了这么多请求,那索性不要放那么多人进去;
- 服务熔断与降级:服务降级是系统的最后一道保险,就是当某个服务不可用时,干脆就别让其提供服务了,直接返回一个缺省的结果,虽然这个服务不可用,但它不至于让整个主流程瘫痪,这就可以最大限度的保证核心系统可用;
- 前端
- 动静分离:动态的页面放在 Web服务器上,静态的资源如 Css/Js/Img,直接放到 CDN(内容分发网络)上,这样既提高性能,也极大的降低服务器压力;
- 其他
- 故障监控:系统监控、链路监控、日志监控;
- 自动预警;
4.数据库分库分表
4.1 数据分片
- 离散式分片:按照数据的某一字段哈希取模后进行分片存储;
- 跨库操作需要由数据分库分表中间件来完成,影响数据的查询效率;
- 当数据存储能力出现瓶颈需要扩容时,离散分片规则需要将所有数据重新进行哈希取模运算,产生数据迁移问题;
- 连续分片:数据按照时间或连续自增主键连续存储;
- 大量的读写往往都集中在最新存储的那一部分数据,会导致热点问题;
4.2 数据库扩展
- 垂直分库:将一个完整的数据库根据业务功能拆分成多个独立的数据库,这些数据库可以运行在不同的服务器上,从而提升数据库整体的数据读写性能;
- 垂直分表:如果一张表的字段非常多,将一张表中不常用的字段拆分到另一张表中,从而保证第一张表中的字段较少,提升查询效率,而另一张表中的数据通过外键与第一张表进行关联;
- 水平分表:如果一张表中的记录数过多(超过 1000 万条记录),那么会对数据库的读写性能产生较大的影响,将一张含有很多记录数的表水平切分,拆分成几张结构相同的表,根据某字段进行哈希取模后均匀地存储在切分表中;
- 水平分库分表:水平数据分片首先将数据表进行水平拆分,然后按照某一分片规则存储在多台数据库服务器上;
- 跨库操作
-
- 跨库 Join 变得非常麻烦,而且基于架构规范,性能,安全性等方面考虑,一般是禁止跨库 Join 的;
- 在业务系统层面,通过多次 SQL 查询,完成数据的组装和拼接;
- 中间件:Cobar(分库)、MyCat;
5.分布式事务
- 目前数据库不支持跨库事务,我们就需要在数据库之上通过某种手段,实现支持跨数据库的事务支持,比如:商品系统、订单系统、支付系统、积分系统、库存系统等,用户下单,2、3、4、5需要在一个事务控制;
5.1 分布式事务协议
- 2PC:两阶段提交协议
- 有一个事务管理器的概念,负责协调多个数据库的事务,事务管理器先问各个数据库你准备好了吗?如果每个数据库都回复 OK,那么就正式提交事务,在各个数据库上执行操作,如果任何其中一个数据库回答 NO,那么就回滚事务;
- PreCommit 阶段
- 节点:协调者 Coordinator、参与者 Cohorts;
- 协调者向所有参与者询问是否可以执行提交操作 Vote;
- 参与者执行询问,Undo 信息和 Redo 信息写入日志;
- 参与者向协调者发起询问,返回“成功”(事务操作成功)或“中止”(事务操作失败);
- DoCommit 阶段
- 协调者获得参与者“同意”时,发出“Commit”请求,参与者完成请求,释放资源,向协调者返回“完成”消息,协调者收到消息后完成事务;
- 协调者获得参与者“中止”消息时,发出“Rollback”请求,参与者完成请求,释放资源;
- 缺点
- 参与者节点事务都是阻塞型的;
- 协调者发生故障,参与者会一直阻塞;
- 第二阶段,在协调者发出“Commit”后,协调者和其中的参与者都宕机,没人知道事务是否提交;
- 协调者获得参与者“同意”时,发出“Commit”请求,参与者完成请求,释放资源,向协调者返回“完成”消息,协调者收到消息后完成事务;
- 3PC:三阶段提交协议
- 在 2PC 的基础上,引入了协调者和参与者的超时机制,并将 Precommit 阶段分成了两个准备阶段;
- CanCommit 阶段、PreCommit 阶段、DoCommit 阶段;
5.2 分布式事务模式
- AT:两阶段型,是一种无侵入的分布式事务解决方案,阿里的 Seata 实现了该模式;
- TCC:两阶段型、补偿型;
- Try 阶段:对各个服务的资源做检测以及对资源进行锁定或者预留;
- 这种方案使用较少,因为事务回滚实际上是严重依赖于你自己写代码来回滚;
- Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作;
- Confirm 阶段:在各个服务中执行实际的操作;
- Saga:两阶段、补偿型;
- 每个 Saga 由一系列 sub-transaction Ti 组成
- 和 TCC 相比,Saga 没有“预留”动作,它的 Ti 就是直接提交到库;
- 每个 Ti 都有对应的补偿动作 Ci,补偿动作用于撤销 Ti 造成的结果;
- XA:分布式强一致性的解决方案,性能低而使用较少;
二、分布式框架
1.Dubbo + Zookeeper
以bubbo来调用的
dubbo:阿里程序员,自创,一个技术,
zookeeper:注册中心功能
类似于我们的controller调用service,通过RPC去调用远程接口
1.1RPC
- Remote Procedure Call Protocol,远程过程调用协议,是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议;
- 该协议允许运行于一台计算机的程序调用另一台计算机的程序,通过一个双向的通信连接(Socket 套接字),实现数据的交换;
-
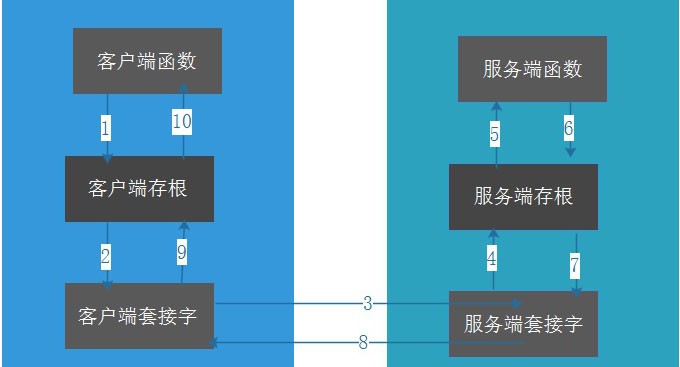
- 关键是创建“客户端存根”,存根就像是代理模式中的代理,生成代理后,代理跟远程服务端通信;
2.spring cloud
Netflix
注册中心,负载均衡器,网关,远程调用。
3.spring cloud Alibaba
使用了spring cloud的组件,另外添加了三大组件:
1.Nacos
2.Sentinel
3.Seata
三、分布式架构

- Provider:生产者,接口提供方;
- Consumer:消费者,调用接口方;
- Registry:注册中心,服务注册与发现;
- Monitor:监控中心,统计服务的调用次数和时间;
- Container:服务运行容器;
- ----------------
- Container 负责启动,加载,运行服务;
- Provider 在启动时,向 Registry 注册自己提供的服务;
- Consumer 在启动时,向 Registry 订阅自己所需的服务;
- Registry 返回 Provider 地址列表给 Consumer,如果有变更,Registry 将基于长连接推送变更数据给 Consumer;
- Consumer 从 Provider 地址列表中,基于软负载均衡算法,选一台 Provider 进行调用,如果调用失败,再选另一台;
- Provider 和 Consumer,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到 Monitor;
四、简介
1.特点
- 官方文档:https://spring.io/projects/spring-cloud;
- 在 Spring Boot 基础之上构建,用于快速构建分布式系统的通用模式的工具集;
- 集大成者,Spring Cloud 包含了微服务架构的方方面面;
- 约定优于配置,基于注解,配置文件少;
- 轻量级组件、开发简便、灵活;
- 项目结构复杂,每一个组件或者每一个服务都需要创建一个项目;
- 部署门槛高,项目部署需要配合 Docker 等容器技术进行集群部署;
2.版本
Maven 中央库搜索 Spring Cloud Dependencies,查看 Spring Cloud 版本;

- Spring Boot 版本以伦敦地铁站命名,对非英语母语国家开发者并不友好,2020 版本变更了命名规则;
Spring Boot 和 Spring Cloud 版本对应关系;
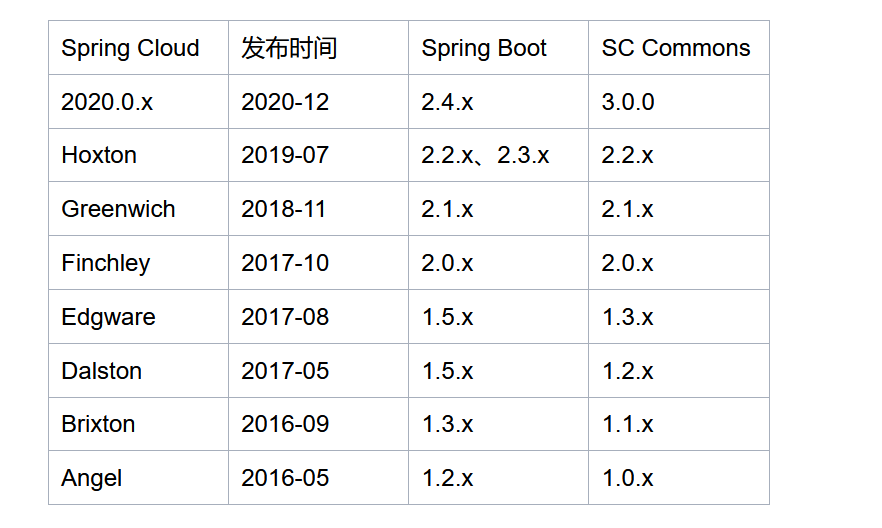
2020 版本变更
- Spring Cloud 一直以来把 Netflix OSS 套件作为其官方默认的一站式解决方案,可是 Netflix 公司在 2018 年前后宣布其核心组件 Hystrix、Ribbon、Zuul、Archaius 等均进入维护状态,迫于无奈,Spring Cloud 做了阻断式升级,发布了 2020 版本;

- Bootstrap 父上下文配置默认不再启动,参见 BootstrapApplicationListener.java,对 BootStrap 做了判断;
- 全新的配置方式,可以使用 spring.config.import 导入其它组件的配置,如:spring.config.import=configserver:xxx,这么做更具模块化,更符合云原生环境的要求;
3.组件
- 注册中心:Netflix Eureka;
- 负载均衡:Netflix Ribbon(2020 版本前)、Spring Cloud Loadbalancer(2020 版本后);
- 熔断器:Netflix Hystrix(2020 版本前)、Resilience4j(2020 版本后);
- 声明式服务调用组件:Feign(最初属 Netflix 公司,后来移交给 OpenFeign 组织);
- 网关:Netflix Zuul(2020 版本前)、Spring Cloud Gateway(2020 版本后);
- 配置中心:Spring Cloud Config;
- 事件、消息总线:Spring Cloud Bus;
- 安全组件:Spring Cloud Security;
五、公共项目搭建
搭建一个spring cloud项目
目标:将之前写的spring boot项目拆解到spring cloud 项目中
一下市搭建分布式项目的步骤:
entity项目问题?
问题1:为什么要创建一个entity项目?
微服务之间涉及到跨模块的beanentity的调用,所以我首先将所有的分布式系统里的bean抽取出来,形成单独的模块,其他微服务以jar包的方式引入
问题2:微服务会不会跨服务调用 bean? 不会
举个栗子
其他模块会不会调用 账户模块 的user 对象? 会
对啊,既然会用到,那么我微服务 B 怎么去调用 微服务 A 里面的 bean?
问题3: 每个微服务就是一个项目? 是的
问题4: 是不是将每个微服务的 bean 抽取出来,形成一个单独的项目,其他微服务只要添加该项目依赖就可以引用到了
问题5: 那以后是不是还要把每一个service之类的都抽出来?
不用啊,我们通过resttemplate调用接口的方式实现微服务接口调用
1、Entity 项目
1.1.简介
在 Spring Cloud 项目中,每个微服务都可能用到的内容,比如 Entity、Util 等,我们将这些内容单独放到一个项目内,成为其余微服务的依赖;
1.2.创建entity
1.创建骨架
创建 Java Maven 项目 java_spring_cloud_entity;


这时骨架就搭建好了,
2.导入依赖
- Pom 添加依赖
<!-- servlet -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
</dependency>
<!-- javax.persistence -->
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>javax.persistence-api</artifactId>
<version>2.2</version>
</dependency>
<!-- Jackson -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>${jackson.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>${jackson.version}</version>
</dependency>
<!-- 序列化 LocalDateTime 等时间类 -->
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
<version>${jackson.version}</version>
</dependency>
<!-- Commons -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>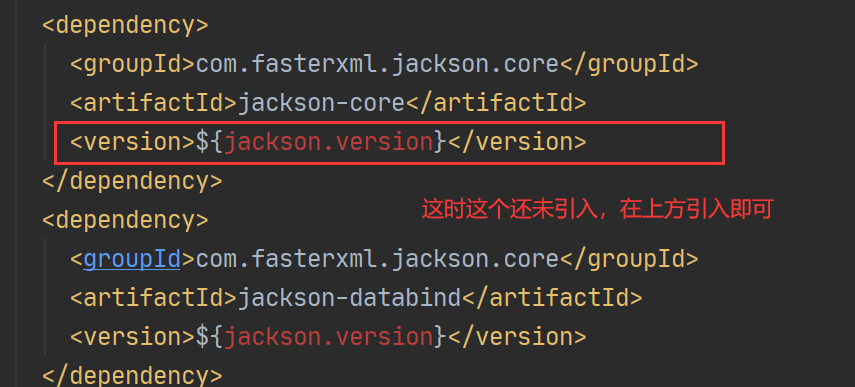
<jackson.version>2.11.3</jackson.version>

3. 包装:将之前项目各个模块中 Entity 移植到该项目;
1.在基础包下创建与之前项目模块各个相同的包名

2.复制之前的entity过来放在对应的包中
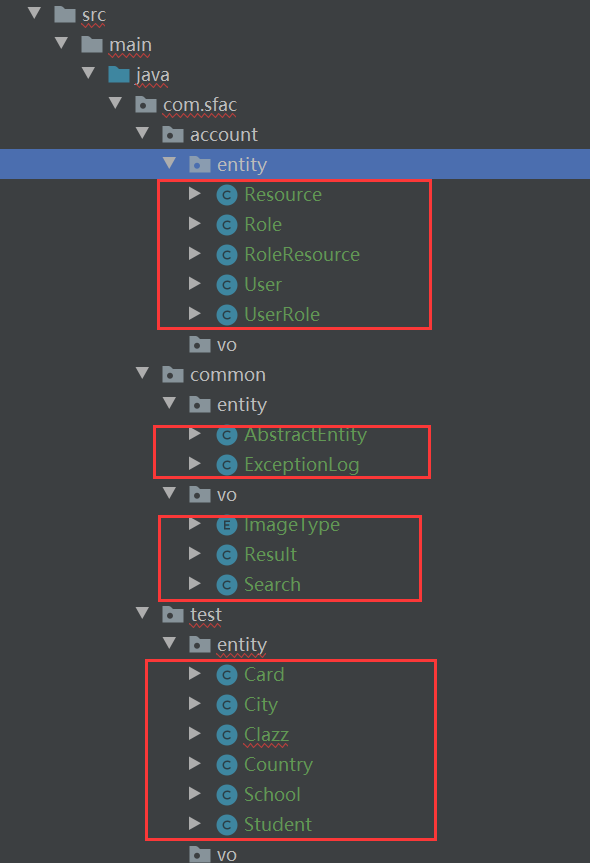
3.复制过来后,需要修改entity中的引用路径

全部修改完后就,没错了,下一步打成jar包

4.打包jar
- Maven 打包项目,在本地仓库生成 Jar;
- 命令:mvn clean install -Dmaven.test.skip=true


这里会出现问题情况:

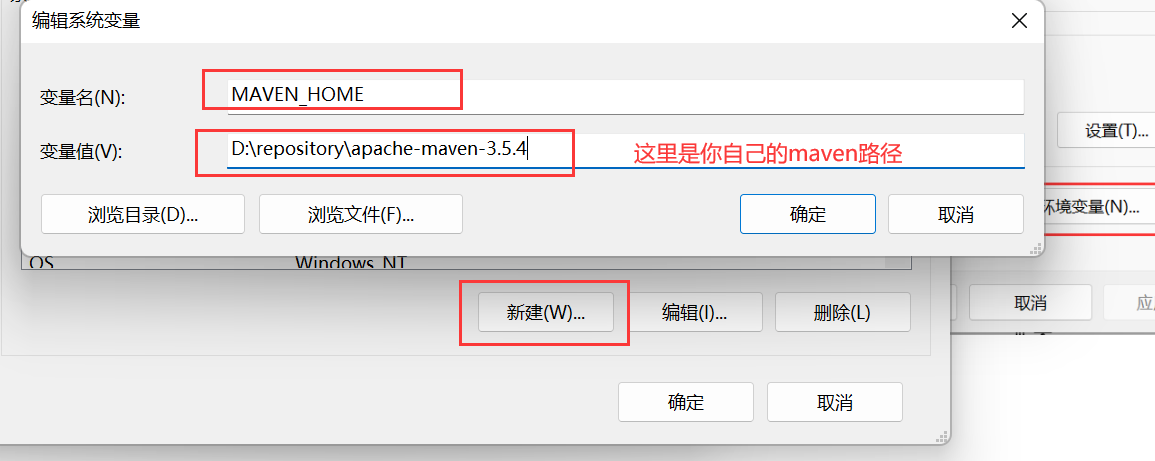
这里是你的maven环境变量没有配置,步骤如下:
- 环境变量
- MAVEN_HOME:D:\Program Files\apache-maven-3.6.3
- Path:%MAVEN_HOME%\bin;
- cmd:mvn --version



这样直接点确定,就好了,然后去测试,打开cmd
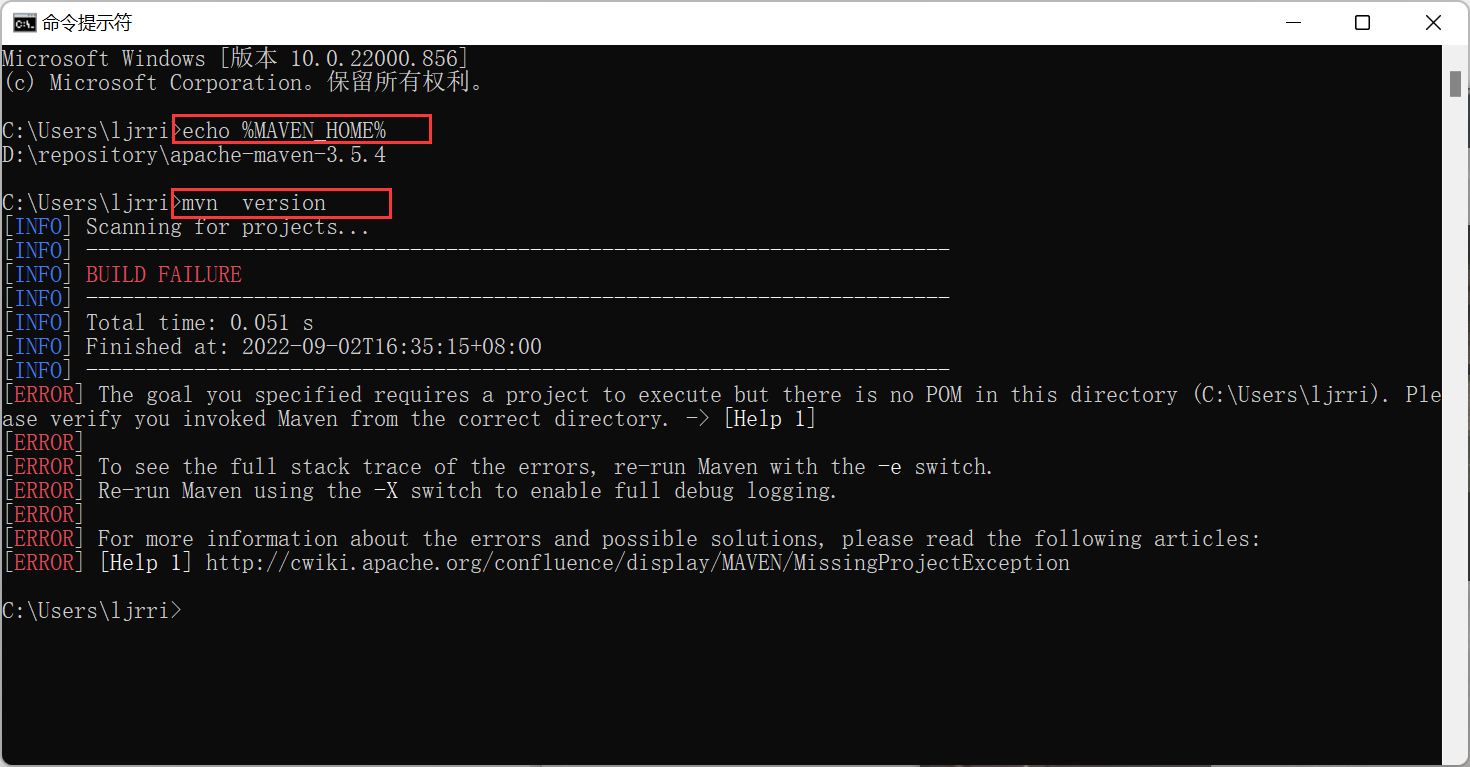
测试结果是正常这样后,就配好了,但是idea还没有感应到,重启idea,然后打开entity项目,重新输入打包命令


5.找到jar包,在target下面
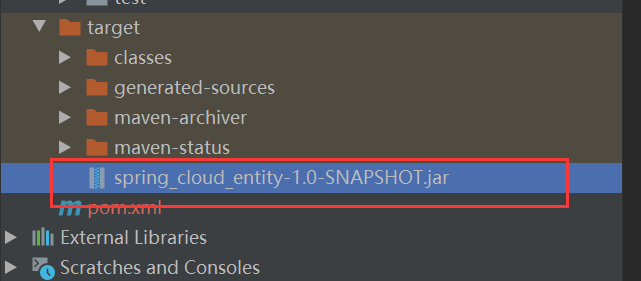
这样就打好了,然后就可以把你的项目上传到远程仓库里面了
2.创建注册中心
2.1Netflix Eureka
简介

- Spring Cloud 提供了多种注册中心的支持,如:Eureka、Consul、ZooKeeper 等,Netflix Eureka 本身是一个基于 REST 的服务,包含两个组件:Eureka Server 和 Eureka Client;
- Eureka Server 提供服务注册服务,各个节点启动后,会在 Eureka Server 中进行注册,这样 Eureka Server 的服务注册表将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到;
- Eureka Server 之间通过复制的方式完成数据的同步,Eureka 还提供了客户端缓存机制,即使所有的 Eureka Server 都挂掉,客户端依然可以利用缓存中的信息消费其他服务的 API;
- Eureka Client:生产者或消费者;
- 在应用启动后,Eureka Client 将会向 Eureka Server 发送心跳,默认周期为 30 秒,如果 Eureka Server 在多个心跳周期内(默认 90 秒)没有接收到某个节点的心跳,Eureka Server 将会进入自我保护机制;
3.写微服务,生产者和消费者
4.微服务之间相互调用,resttemplate,openfeign
5.给微服务添加集群,引入负载均衡器组件
6.引入熔断器组件
cap理论:分区容错性