数仓架构演进
数仓 1.0 ,2.0
1.Lambda架构
Lambda将数据处理流分为在线分析和离线分析两条不同的处理路径,两条路径互相独立,互不影响。
离线分析处理T+1数据,使用Hive/Spark处理大数据量,不可变数据,数据一般存储在HDFS等系统上。如果遇到数据更新,需要overwrite整张表或整个分区,成本比较高。
在线分析处理实时数据,使用Flink/Spark Streaming处理流式数据,分析处理秒级或分钟级流式数据,数据保存在Kafka或定期(分钟级)保存到HDFS中。
该套方案存在以下缺点:
同一套指标可能需要开发两份代码来进行在线分析和离线分析,维护复杂。
数据应用查询指标时可能需要同时查询离线数据和在线数据,开发复杂。
同时部署批处理和流式计算两套引擎,运维复杂。
数据更新需要overwrite整张表或分区,成本高。
2.Kappa架构
随着在线分析业务越来越多,Lambda架构的弊端就越来越明显,增加一个指标需要在线离线分别开发,维护困难,离线指标可能和在线指标对不齐,部署复杂,组件繁多。于是Kappa架构应运而生。
Kappa架构使用一套架构处理在线数据和离线数据,使用同一套引擎同时处理在线和离线数据,数据存储在消息队列上。
Kappa架构也有一定的局限:
流式计算引擎批处理能力较弱,处理大数据量性能较弱。
数据存储使用消息队列,消息队列对数据存储有有效性限制,历史数据无法回溯。
数据时序可能乱序,可能对部分在时序要求方面比较严格的应用造成数据错误。
数据应用需要从消息队列中取数,需要开发适配接口,开发复杂。
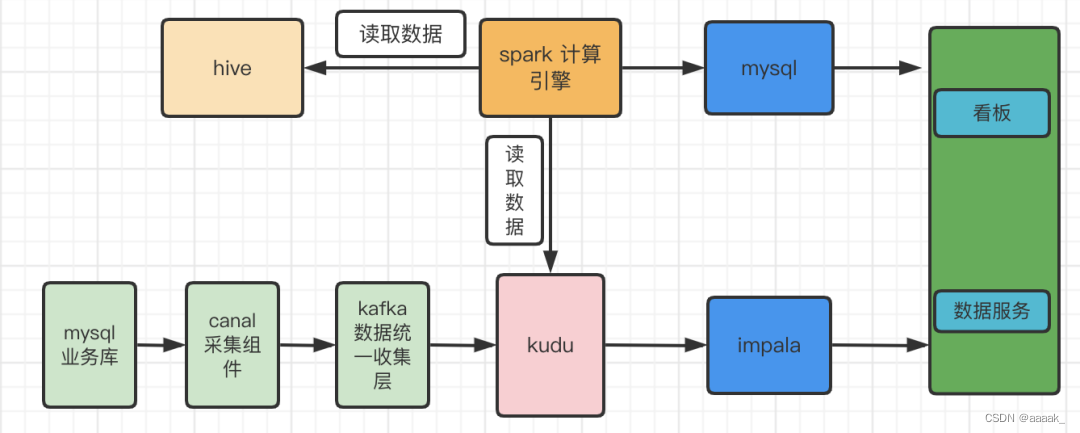
离线处理
典型应用如数据清理,特点是处理数据量大,耗时长。
核心组件选择为:
MapReduce + Hive,或者Spark + Spark SQL。
数据流动为:
流式数据/文件/数据库 -> flume/第三方ETL -> HDFS -> Yarn -> Spark -> Spark SQL -> 数据仓库;
或者
流式数据/文件/数据库 -> flume/第三方ETL -> HDFS-> Yarn -> MapReduce -> Hive -> 数据仓库 (较老)
实时流处理
典型应用如银行实时风控,特点是响应要求实时,数据不落盘(硬盘)。
核心组件选择:
Flink,或者Spark Streaming。 某些情况需要缓存数据时使用Kafka组件,处理完结果可以放在redis(内存数据库)中暂时存储,供上层应用使用。
数据流动为:
实时流/实时文件/数据库 -> flume/第三方ETL -> Kafka -> Flink/Spark Streaming -> redis/Kafka -> 实时应用
注意,这里不会使用HDFS,因为数据不落盘。
实时检索
典型应用如查询一个人的购买记录,特点是响应基本实时(1s),但是不支持负责查询。
核心组件选择:
ES/Hbase/Solr。
数据流动为:
流式数据/文件/数据库 -> flume/第三方ETL -> HDFS -> Yarn -> ES/Hbase/Solr -> 检索。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WSZq1yYe-1662111756805)(/images/1/293/2.png)]](https://img-blog.csdnimg.cn/e0c2031c49c14227b9bcaf389ff5d739.png)
数仓3.0
计算引擎做到了批流一体的统一,就可以做到SQL统一
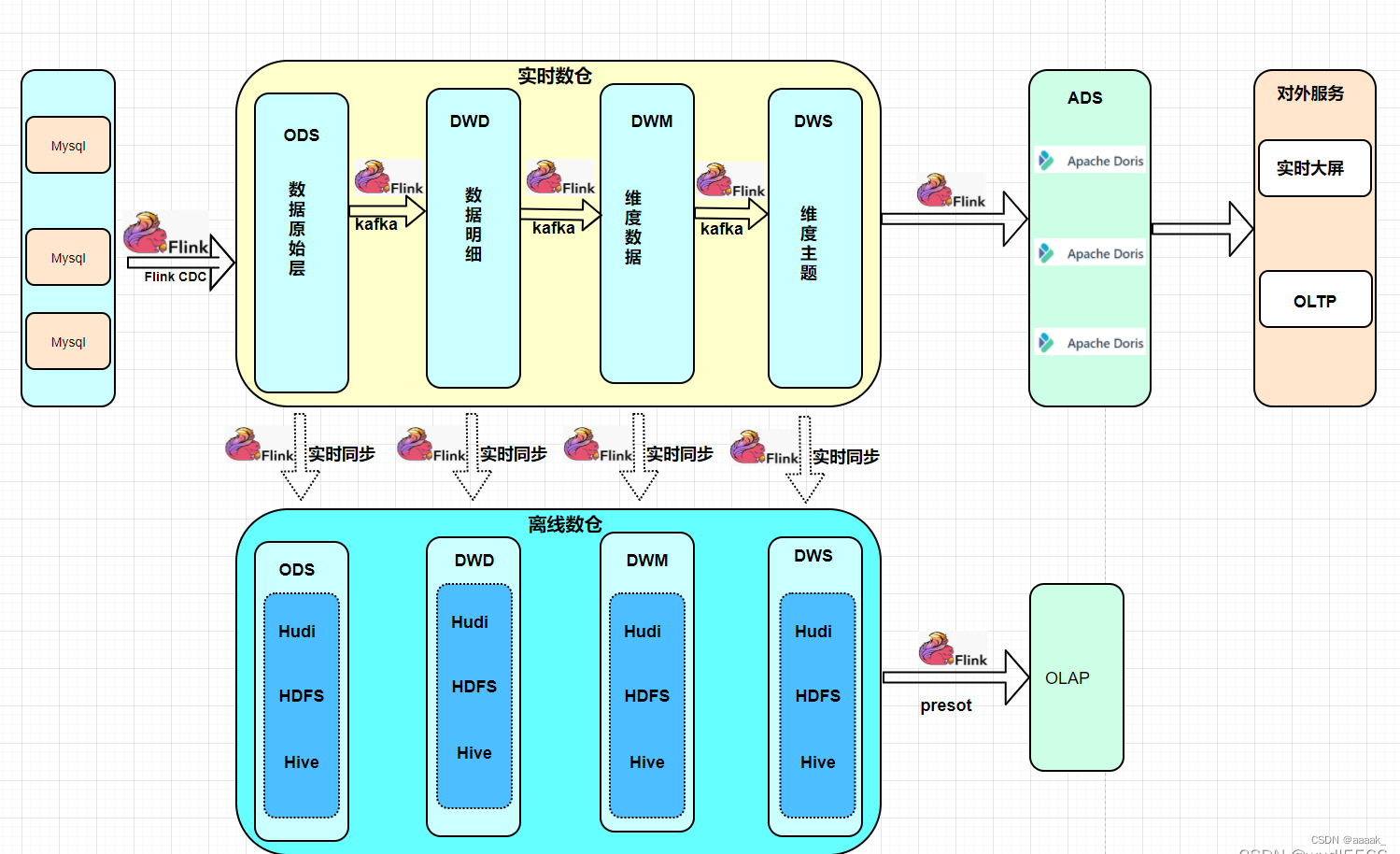
1 基于数据湖的实时数仓
针对Lambda架构和Kappa架构的缺陷,业界基于数据湖开发了Iceberg, Hudi, DeltaLake这些数据湖技术,使得数仓支持ACID, Update/Delete,数据Time Travel, Schema Evolution等特性,使得数仓的时效性从小时级提升到分钟级,数据更新也支持部分更新,大大提高了数据更新的性能。兼具流式计算的实时性和批计算的吞吐量,支持的是近实时的场景。
以上方案中其中基于数据湖的应用最广,但数据湖模式无法支撑更高的秒级实时性,也无法直接对外提供数据服务,需要搭建其他的数据服务组件,系统较为复杂。基于此背景下,部分业务开始使用Doris来承接,业务数据分析师需要对Doris与数据湖中的数据进行联邦分析。
实时流/实时文件/数据库 -> Flink/Spark Streaming -> cdc -> Hudi/Iceberg -> Doris/ClickHouse/StarRocks/Presto/Apache Kylin