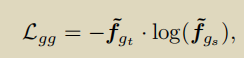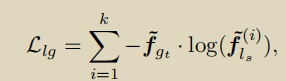Self-supervised Video Transformer 阅读
目录
- 1.介绍
- 2.SVT
- 2.1 SVT结构
- 2.2 自监督训练
- Motion Correspondences
- Cross-View Correspondences
- 2.3 SVT loss
1.介绍
本文是针对video transformer进行自监督训练,从一个给定的视频中,创建具有不同空间大小和帧率的局部和全局时空视图,自监督的目标是寻找相同视频的不同视图特征之间的匹配。 Self-supervised Video Transformer(SVT),使用相似性目标训练师生模型,该目标通过时空注意力匹配沿时空维度的表示。
本文贡献如下:
- 提出一种新的自监督训练方式,利用全局和局部时空视图之间的时空关系来进行自监督训练。
- SVT中的自监督是通过联合motion和crossview的关系进行学习。通过学习motion关系(全局到全局时空视图匹配)和crossview关系(局部到全局时空视图匹配)来建模上下文信息。
- 模型的一个特性是可以进行slow-fast训练,使用动态位置编码处理可变帧率的输入。
2.SVT
此部分介绍SVT的自监督训练方法,和以往的对比学习不同,此方法从同一视频中获得不同时空特征的片段进行的。避免了负样本挖掘和记忆存储库。具体是通过损失函数使得两个不同的片段之间学习,使用师生网络,让教师网络作为学生网络的学习目标,使得学生网络学习到突出特征。
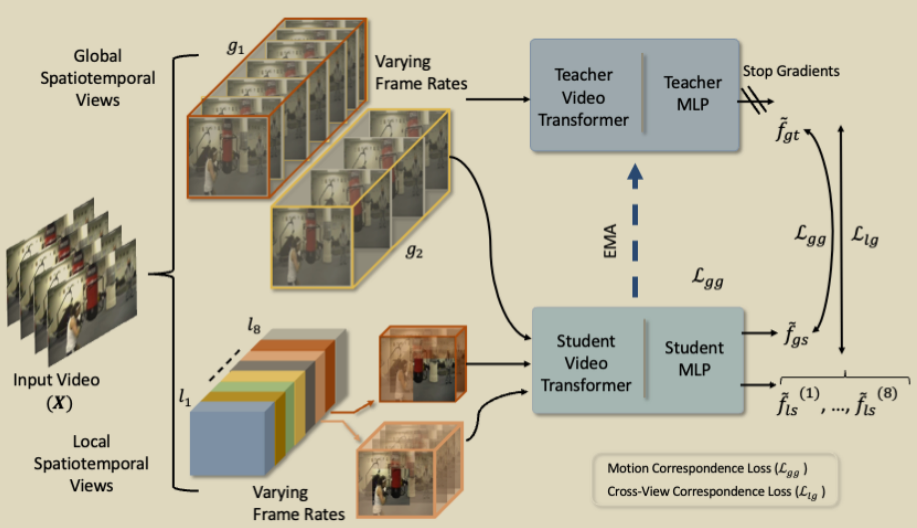
2.1 SVT结构
给定一个视频 X = {xt}Nt=1 ,N为视频的帧数,从其中采样得到视频片段,H,W,T分别为视频的高,宽,时间维度。以此种方法从中采样,生成两种类型的片段,global(g)和 local(l)的时空视图。g和l 都是X的子集,
g = {x’t}Kgt=1 ,l = {x’t}Klt=1 , |Kl| ≤ |Kg|。
对于global view,从原始视频沿时间轴的90%中采样,得到两个global view ,g1和g2,分别对应低帧率(T=8)和高帧率(T=16),空间维度为224 * 224。
对于local view,从原始视频沿时间轴的12.5%和空间范围40%中采样,得到八个local view,(l1,…,l8),他们的空间维度固定为96*96,时间T∈{2,4,8,16}。
SVT包含12个encoder模块,所有采样得到的视频片段(C * T * H * W)都要经过这些模块。在transformer中,训练阶段会把H=W=224,T=16的片段分割为很多patch,224 * 224的一帧会被分割为14 * 14个大小为 16 * 16的patch,因此就是得到空间196,时间16的token,最后每个token嵌入后就是768维的向量。在SVT的末尾使用MLP,最后的输出为 f .
2.2 自监督训练
通过在师生模型的特征空间中预测具有不同时空特征的不同视频片段,以自我监督的方式训练SVT。使用简单的路由策略,在师生模型随机选择传递不同的视图。教师模型处理一个global view ,产生一个特征向量 fgt ,学生模型处理global view 和 local view ,得到 fgs 和 flsi (i=1,…,8) 。通过反向传播更新学生模型的参数,教师模型的更新为学生模型的指数移动平均线(EMA)。
Motion Correspondences
视频的一个特征是帧率。改变帧率可以改变视频的动作上下文(例如,缓慢行走和快速行走),同时控制微妙的动作。预测在高帧率下捕获的细微运动将迫使模型从低帧率输入中学习与运动相关的上下文信息。
对于两个global view ,g1 (T = 8) and g2 (T = 16) ,得到了两个特征向量 fgt(1) , fgt(2) 。这两个global view 同样经过学生模型得到fgs(1) , fgs(2) ,学生模型得到的要和教师模型得到的求loss。同样地,local view经过学生模型得到fls(1) ,…, fls(8) ,全部与教师模型得到的 fgt(1) , fgt(2) 求loss。
Cross-View Correspondences
通过学习Cross-View Correspondences(CVC)来模拟跨时空变化的关系。将学生模型得到的 flsi (i=1,…,8) 与教师模型(fgt)处理的全局时空视图表示进行匹配,来学习CVC。
2.3 SVT loss
上面已经说过了,将学生模型的输出与教师模型的输出求loss。通过全局到全局视图来学习运动,而局部到全局视图来学习交叉视图对应。
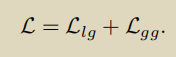
Llg是local view和global view的loss, Lgg是global view和global view的loss 。
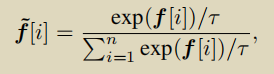
原本的输出 f 要经过一个softmax,f˜∈ Rn 。