一种加权变异的粒子群算法-附代码
一种加权变异的粒子群算法
文章目录
- 一种加权变异的粒子群算法
- 1.粒子群优化算法
- 2. 改进粒子群算法
- 2.1 自适应权重和自适应学习因子
- 2.2 加权变异
- 2.3 高斯扰动
- 3.实验结果
- 4.参考文献
- 5.Matlab代码
- 6.Python代码
摘要:针对粒子群算法易于陷入早熟、收敛速度慢及收敛精度低的问题,提出了加权变异的WVPSO(Weighted Variation Particle Swarm Optimization)粒子群算法。根据自适应惯性权重和自适应学习因子,平衡了全局搜索和局部搜索能力;基于算术交叉的变异和自然选择机制的替换策略,增加了粒子的多样性,提高了算法的收敛精度;最后加入高斯扰动,使粒子产生震荡,更容易跳出局部最优。
1.粒子群优化算法
基础粒子群算法的具体原理参考网络资料
2. 改进粒子群算法
2.1 自适应权重和自适应学习因子
在 PSO 算法迭代的过程中, 权重在算法迭代前期需要让粒子的步长变化更快, 从而让粒子尽可能早地 达到全局最优值所在的区域, 而在算法迭代后期则应该减少步长的变化, 让粒子在该区域内作精准的搜索使 之找到全局最优解。对于学习因子, 在算法迭代前期应该自我学习率占比高, 群体学习率占比低; 随着迭代 不断进行, 自我学习比率要逐步降低, 而群体学习比率则逐渐提高。这样既可以加快算法的收玫速度, 又可 以提高算法的收敛精度。基于上述思想, 本文提出了一种自适应权重和自适应学习因子的方法:
w
=
0.8
×
exp
(
−
2.5
i
t
Max
I
t
)
(3)
w=0.8 \times \exp \left(\frac{-2.5 i t}{\operatorname{Max} I t}\right) \tag{3}
w=0.8×exp(MaxIt−2.5it)(3)
c 1 = c 1up − rand × ( 1 − exp ( − Max I t Max I t − i t ) ) × ( c uup − c 11 ow ) (4) c_{1}=c_{\text {1up }}-\operatorname{rand} \times\left(1-\exp \left(\frac{-\operatorname{Max} I t}{\operatorname{Max} I t-i t}\right)\right) \times\left(c_{\text {uup }}-c_{11 \text { ow }}\right) \tag{4} c1=c1up −rand×(1−exp(MaxIt−it−MaxIt))×(cuup −c11 ow )(4)
c
2
=
c
210
w
+
rand
×
(
1
−
exp
(
−
Max
I
t
Max
I
t
−
i
t
)
)
×
(
c
2
up
−
c
21
ow
)
,
(5)
\begin{gathered} c_{2}=c_{210 w}+\operatorname{rand} \times\left(1-\exp \left(\frac{-\operatorname{Max} I t}{\operatorname{Max} I t-i t}\right)\right) \times\left(c_{2 \text { up }}-c_{21 \text { ow }}\right), \end{gathered} \tag{5}
c2=c210w+rand×(1−exp(MaxIt−it−MaxIt))×(c2 up −c21 ow ),(5)
式 (3) (5) 中, it 和 MaxIt 分别为算法当前的迭代次数和最大的迭代次数; rand 为
0
∼
1
0 \sim 1
0∼1 之间的随机数;
c
1
lup
,
c
11
ov
c_{1 \text { lup }}, c_{11 \text { ov }}
c1 lup ,c11 ov 为自我学习因子的上下界;
c
2
uup
,
c
21
ow
c_{2 \text { uup }}, c_{21 \text { ow }}
c2 uup ,c21 ow 为群体学习因子的上下界。式 (3) 中, 权重
w
w
w 在算法迭代前期尽可能取最大值,从而使算法步长得到更快的变化;随着算法的不断迭代,权重则逐渐减小,以满足算法的自适应权重需求;式(4)在算法进行的过程中是一个递减的函数,式(5)则是一个递增的函数,符合自适应学习因子的思想要求。
2.2 加权变异
由于标准 PSO 算法收敛速度比较慢、迭代后期种群多样性降低, 使得算法最后难以搜索到全局最优值。 对此, 本文加入算术交叉和自然选择策略来提高粒子多样性、增强收玫速度与精度。对于变异粒子的比例, 通过以下方式选择:
[
∣
P
1
∣
,
∣
P
2
∣
,
⋯
,
∣
P
N
∣
]
(6)
\text { [ } \left.\left|P_{1}\right|,\left|P_{2}\right|, \cdots,\left|P_{N}\right|\right] \tag{6}
[ ∣P1∣,∣P2∣,⋯,∣PN∣](6)
将所有粒子适应值的绝对值从小到大按照式 (6) 方式排列, 并按照式(7) 进行分割, 式(7) 如下:
[
∣
P
1
∣
,
∣
P
2
∣
,
⋯
,
∣
P
N
5
∣
,
∣
P
N
5
+
1
∣
,
⋯
,
∣
P
N
2
∣
,
∣
P
N
2
+
1
∣
,
⋯
,
∣
P
4
N
5
∣
,
⋯
,
∣
P
N
∣
]
.
\left[\left|P_{1}\right|,\left|P_{2}\right|, \cdots,\left|P_{\frac{N}{5}}\right|,\left|P_{\frac{N}{5}+1}\right|, \cdots,\left|P_{\frac{N}{2}}\right|,\left|P_{\frac{N}{2}+1}\right|, \cdots,\left|P_{\frac{4 N}{5}}\right|, \cdots,\left|P_{N}\right|\right] .
[∣P1∣,∣P2∣,⋯,∣
∣P5N∣
∣,∣
∣P5N+1∣
∣,⋯,∣
∣P2N∣
∣,∣
∣P2N+1∣
∣,⋯,∣
∣P54N∣
∣,⋯,∣PN∣].
将式 (6) 中的适应值分成
ξ
1
,
ξ
2
,
ξ
3
,
ξ
4
\xi_{1}, \xi_{2}, \xi_{3}, \xi_{4}
ξ1,ξ2,ξ3,ξ4 四个部分, 由于粒子群算法存在的随机性, 因此将粒子的适应值分 为好
(
ξ
1
,
ξ
2
)
\left(\xi_{1}, \xi_{2}\right)
(ξ1,ξ2) 与不好
(
ξ
3
,
ξ
4
)
\left(\xi_{3}, \xi_{4}\right)
(ξ3,ξ4) 两个群体。其中
ξ
1
,
ξ
4
\xi_{1}, \xi_{4}
ξ1,ξ4 各占总体的
20
%
;
ξ
2
,
ξ
3
20 \% ; \xi_{2}, \xi_{3}
20%;ξ2,ξ3 各占总体的
30
%
30 \%
30% 。这里使用交叉 操作作用于
ξ
2
,
ξ
3
\xi_{2}, \xi_{3}
ξ2,ξ3, 融合好粒子与差粒子, 不仅能够产生具有多样性的后代, 而且促使差粒子向好粒子移动; 使用自然选择作用于
ξ
1
,
ξ
4
\xi_{1}, \xi_{4}
ξ1,ξ4, 直接将差粒子
ξ
4
\xi_{4}
ξ4 的速度与位置直接替换为好粒子
ξ
1
\xi_{1}
ξ1 的速度与位置, 类似于将整 个种群缩小
20
%
20 \%
20%, 从而大大加快粒子的收敛速度。具体策略如下:
(1)算术交叉: 根据文献 [11] 的交叉公式, 本文改进算术交叉公式如下所示:
x
ξ
3
=
rand
×
x
ξ
2
+
(
1
−
rand
)
×
x
ξ
3
(8)
x_{\xi_{3}} =\text { rand } \times x_{\xi_{2}}+(1-\text { rand }) \times x_{\xi_{3}} \tag{8}
xξ3= rand ×xξ2+(1− rand )×xξ3(8)
v
ξ
3
=
rand
×
v
ξ
2
+
(
1
−
rand
)
×
v
ξ
3
.
(9)
\begin{aligned} v_{\xi_{3}} &=\text { rand } \times v_{\xi_{2}}+(1-\text { rand }) \times v_{\xi_{3}} . \end{aligned} \tag{9}
vξ3= rand ×vξ2+(1− rand )×vξ3.(9)
x
ξ
2
,
x
ξ
3
x_{\xi 2}, x_{\xi 3}
xξ2,xξ3 为式 (7) 中
ξ
2
,
ξ
3
\xi_{2}, \xi_{3}
ξ2,ξ3 处的粒子位置;
v
ξ
2
,
v
ξ
3
v_{\xi 2}, v_{\xi 3}
vξ2,vξ3 为式 (7) 中
ξ
2
,
ξ
3
\xi_{2}, \xi_{3}
ξ2,ξ3 处的粒子速度; rand 为
0
∼
1
0 \sim 1
0∼1 之间的随机数。
(2)自然选择: 通过选择好的粒子来替换差的粒子, 增加粒子的收敛速度, 具体方式如下:
{
x
ξ
4
=
x
ξ
1
v
ξ
4
=
v
ξ
1
.
,
(10)
\left\{\begin{array}{l} x_{\xi_{4}}=x_{\xi_{1}} \\ v_{\xi_{4}}=v_{\xi_{1}} . \end{array},\right. \tag{10}
{xξ4=xξ1vξ4=vξ1.,(10)
x
ξ
1
,
x
ξ
4
x_{\xi 1}, x_{\xi^{4}}
xξ1,xξ4 为式 (7) 中
ξ
1
,
ξ
4
\xi_{1}, \xi_{4}
ξ1,ξ4 处的粒子位置;
v
ξ
1
,
v
ξ
4
v_{\xi 1}, v_{\xi 4}
vξ1,vξ4 为式 (7) 中
ξ
1
,
ξ
4
\xi_{1}, \xi_{4}
ξ1,ξ4 处的粒子速度。
2.3 高斯扰动
随着算法的迭代,当全局最优值所在的区域远离当前种群的最优值时,粒子容易向错误的方向学习,此时粒子将极易陷入早熟。为了让算法跳出局部最优,在后期迭代时加入高斯扰动。如果当前适应值经过几次迭代后不再发生变化,则判断算法陷入早熟,这时加入高斯扰动,让粒子震荡,使其摆脱局部最优,因此在迭代初期加入高斯扰动策略。
WVPSO 算法流程如下所示:
Step1 随机初始化粒子的位置和速度, 设定相关参数;
Step2 根据式 (3) (5) 计算惯性权重
w
w
w, 学习因子
c
1
c_{1}
c1 和
c
2
c_{2}
c2;
Step3 计算粒子群的适应值, 根据适应值的绝对值从小到大按照式 (6) 方式排列, 并使用式 (7) 分割;
Step4 使用算术交叉式 (8) (9) 和自然选择式 (10) 策略将分割后的粒子进行重新替换;
Step5 根据式 (1) (2) 更新粒子速度和位置, 更新每个粒子历史最优位置 pbest 和群体最优值 gbest。 判断是否陷入早熟,如果陷入早熟则加入高斯扰动;
Step6 若满足终止条件, 则输出最优值, 否则转入步骤 (2), 进入下一次寻优。
3.实验结果
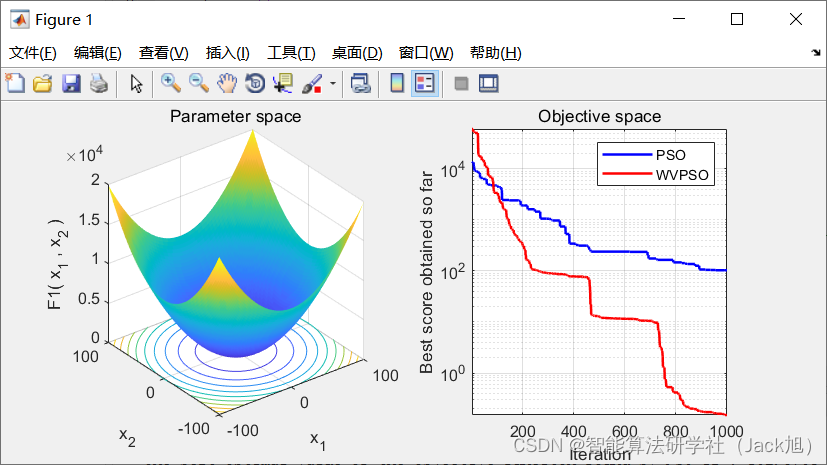
4.参考文献
[1]徐灯,傅晶,王文丰,章香,韩龙哲,方宗华,董健华.一种加权变异的粒子群算法[J].南昌工程学院学报,2021,40(01):51-56+82.