堆的应用:堆排序及TopK问题
目录
- 前言
- 1. 堆排序
- 1.1 向下还是向上调整
- 1.1.1 向上调整建堆
- 1.1.2 向下调整建堆
- 1.2 两种的调整算法的复杂度
- 1.2.1 向下调整的时间复杂度
- 1.2.2 向上调整的时间复杂度
- 1.3 堆排的实现
- 2. TopK问题
- 2.1 什么是TopK
- 2.2 思路
- 2.3 代码实现
前言
前一篇文章介绍了堆的概念及结构和堆的实现,堆的物理结构是数组实现的,但是要把它的逻辑结构想象成完全二叉树,并且了解到堆的增删数据后还要保持其原来的结构,因此需要采用向上和向下调整算法,最多调整该二叉树的高度(logN )次。
堆的的本质是方便找出次大或者次小的数,因此本文来介绍第一次接触到的时间复杂度为O(N*logN)的排序:堆排,以及利用堆排思想来解决TopK问题。
1. 堆排序
给你一个数组,如何建堆?如果直接实现堆的话,再把数组的数据依次插入堆的话,那么它的空间复杂度就是O(N),是否可以直接操作原数组建堆呢?
1.1 向下还是向上调整
依旧采用小堆
最容易想到的方法就是模拟插入堆,然后依次向上调整。
从数组的第二个元素开始模拟插入堆,因为第一个数据就直接可以看成堆,然后向上调整建堆(模拟插入堆的过程):
1.1.1 向上调整建堆
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
//1. 向上调整
void AdjustUp(int* heap, int child)
{
int father = (child - 1) / 2;
while (child > 0 && heap[father] > heap[child])
{
Swap(&heap[father], &heap[child]);
child = father;
father = (child - 1) / 2;
}
}
void HeapSort(int* heap, int heapSize)
{
for (int i = 1; i < arrSize; ++i)
{
AdjustUp(arr, i);
}
//...排序
}
int main()
{
int arr[] = { 65,100,70,32,60,50 };
int arrSize = sizeof(arr) / 4;
HeapSort(arr, arrSize);
return 0;
}

1.1.2 向下调整建堆
使用向下调整有一个前提:它的左右子树都是大/小堆,然后第一个和最后一个交换,但随机给你的数组并不能满足这个前提。
因此就有人想出了这么一个方法:从倒数第一个非叶子结点(最后一个结点的父亲)开始向下调整,直到根为止,因为叶子结点就它自己,天生就是堆,没有必要调整。
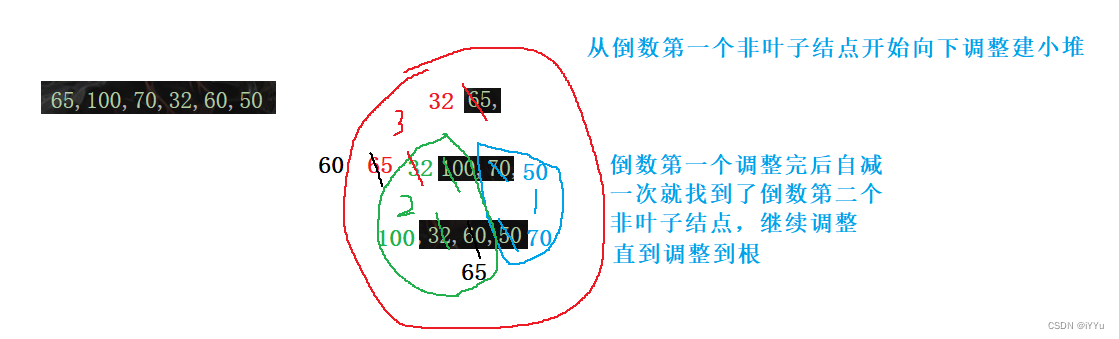
代码实现:
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
//2. 向下调整
void AdjustDown(int* heap, int father, int heapSize)
{
int minchild = father * 2 + 1;
while (minchild < heapSize)
{
if (minchild + 1 < heapSize && heap[minchild] > heap[minchild + 1])
{
++minchild;
}
if (heap[minchild] < heap[father])
{
Swap(&heap[father], &heap[minchild]);
father = minchild;
minchild = father * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* heap, int heapSize)
{
//-1是最后一个结点的位置
//再-1 / 2 就是父亲结点
for (int i = (heapSize- 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(heap, i, heapSize);
}
//...排序
}
int main()
{
int arr[] = { 65,100,70,32,60,50 };
int arrSize = sizeof(arr) / 4;
HeapSort(arr, arrSize);
return 0;
}
以上就是两种建堆的方法,那么哪种方法效率更优呢?
实际上向上调整的时间复杂度为O(N*logN),而向下调整的时间复杂度为O(N),因此选择第二种方法更优,接下来证明一下两种方法的时间复杂度。
1.2 两种的调整算法的复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果)。
1.2.1 向下调整的时间复杂度
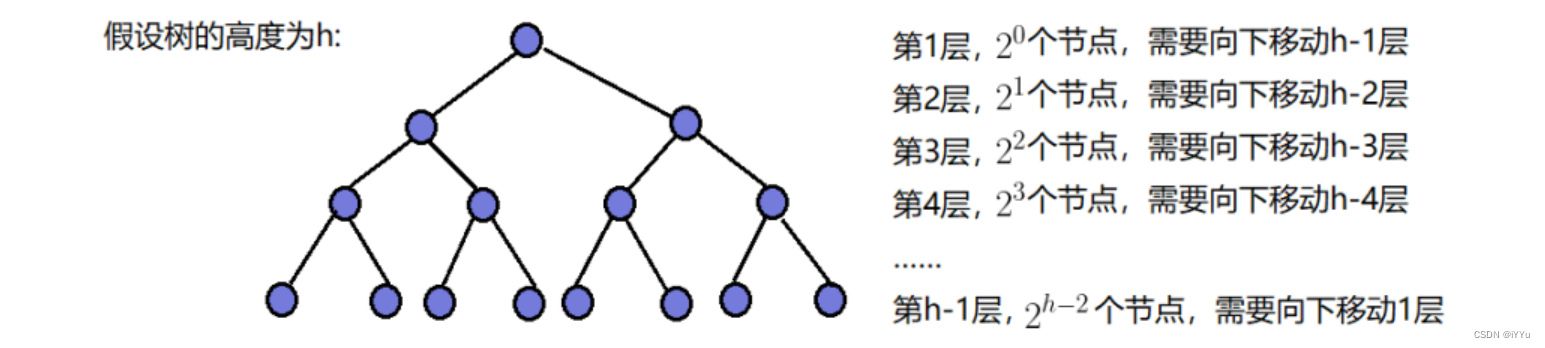
高度为h,结点数量为N的完全二叉树
2 h − 1 = N 2^h-1 = N 2h−1=N
h = l o g 2 ( N + 1 ) h = log_2(N+1) h=log2(N+1)
第h层有2h-1个节点,不需要调整,因为都是叶子结点,从倒数第二层开始调整。
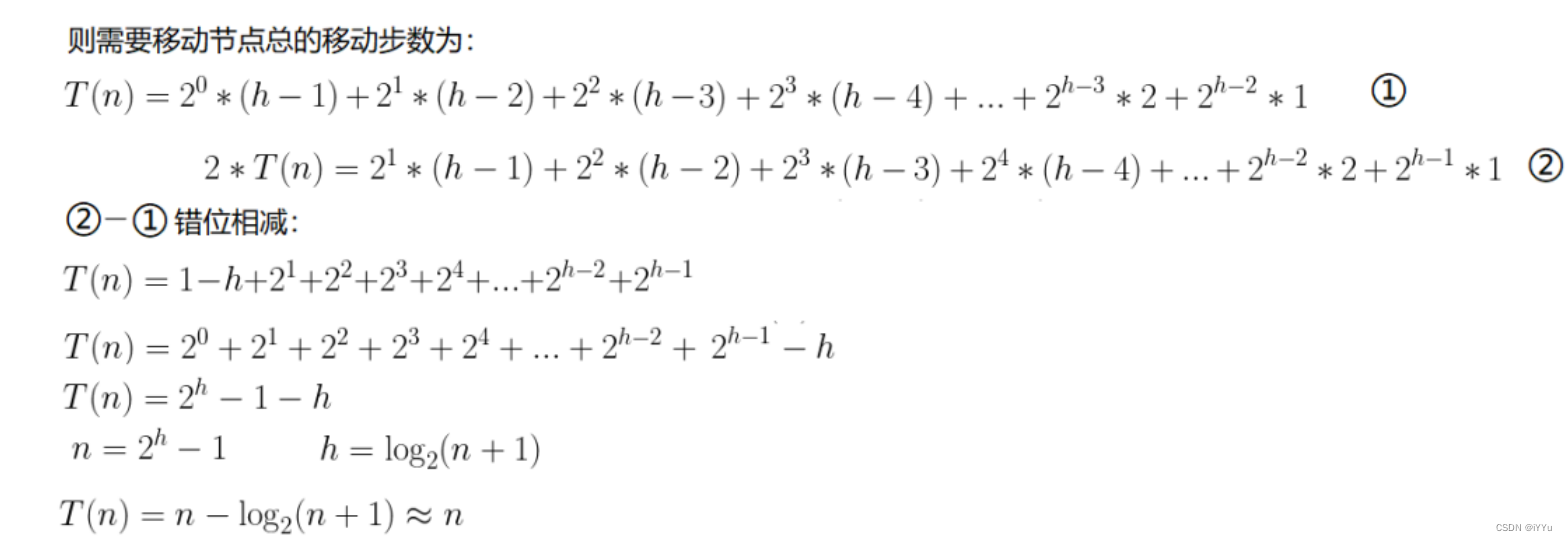
每一层结点个数*这层结点最坏的向下调整次数
向下调整还有一个特点:结点数量越多,那么它调整的次数越少,反正,结点的数量越少,调整的次数就越多
因此:向下调整建堆的时间复杂度为O(N)。
1.2.2 向上调整的时间复杂度
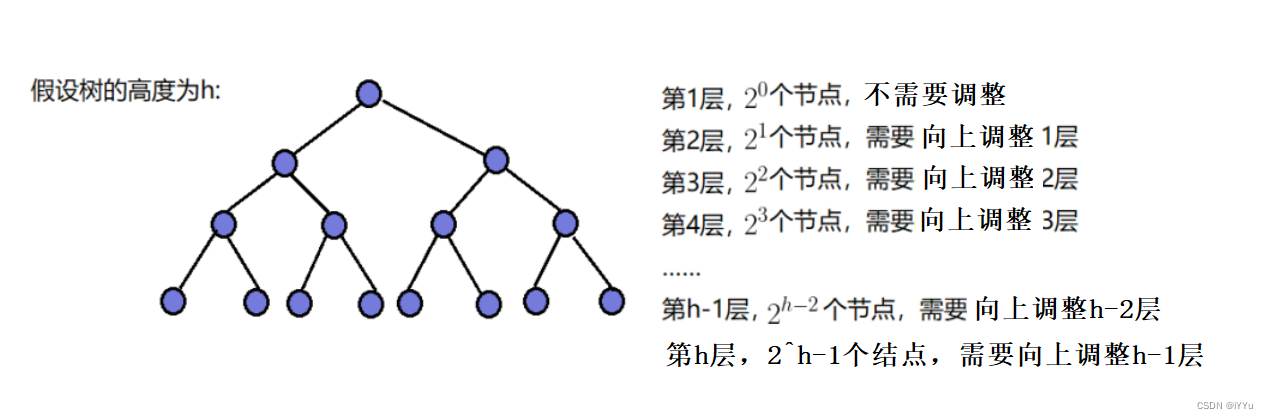
与向下调整相反,向上调整的特点是:结点越少,调整次数越少,反之结点越多,调整次数越多。
所以说相比较向下调整而言,向上调整的效率不太高,因为最后一层结点就占了所有结点的一半(每层的结点个数是上一层的二倍)。
公式可以大致推导为:
T
(
n
)
=
2
1
∗
1
+
2
2
∗
2
+
2
3
∗
3....
+
2
(
h
−
2
)
∗
(
h
−
2
)
+
2
(
h
−
1
)
∗
(
h
−
1
)
T(n) = 2^1*1 + 2^2 * 2 + 2^3 * 3....+ 2^{(h-2)}*(h-2) + 2^{(h-1)}*(h-1)
T(n)=21∗1+22∗2+23∗3....+2(h−2)∗(h−2)+2(h−1)∗(h−1)
精确算用上面的错位相减法可以得到准确的时间复杂度,这里只大概的算一下复杂度。
大概算下来最后一层的复杂度就是N*logN了。
到这里不难发现向上调整不好的点就在这,最后一层占了一半的节点,并且每一个都要调整h-1次,效率太低,而向下调整最后一层结点都不参与调整,并且结点越多调整次数越少,所以建堆尽量都要使用向下调整建堆。
1.3 堆排的实现
了解了两种调整的基本情况后,接下来开始建堆,这时又出现两个问题:
- 升序建大堆还是小堆?
- 降序建大堆还是小堆?
结论:升序建大堆,降序建小堆。
如果升序建小堆的话,堆顶是最小的元素,那如何选出次小的元素呢?再次建堆选次小的话,建堆的时间复杂度是O(N),选一个次小的建一次堆,那么排序的时间复杂度就是N2了,堆的优势就不在了。
而用大堆就可以很好的解决这个问题,这里要用到删除堆顶的思想。堆顶是最大的元素,把堆顶和最后一个元素交换,再把前N-1个元素看作是一个堆(交换后左右子树依然是大堆),然后把堆顶元素进行向下调整选出次大的,后面依次重复这个步骤就完成了堆排序。
代码实现:
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
//向下调整
void AdjustDown(int* heap, int father, int heapSize)
{
int minchild = father * 2 + 1;
while (minchild < heapSize)
{
if (minchild + 1 < heapSize && heap[minchild] < heap[minchild + 1])
{
++minchild;
}
if (heap[minchild] > heap[father])
{
Swap(&heap[father], &heap[minchild]);
father = minchild;
minchild = father * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* heap, int heapSize)
{
//建大堆
//-1是最后一个结点的位置
//再-1 / 2 就是父亲结点
for (int i = (heapSize - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(heap, i, heapSize);
}
int i = 1;
while (i < heapSize)
{
//把第一个和最后一个交换,然后把前n-i个看成一个堆继续向下调整
Swap(&heap[0], &heap[heapSize - i]);
AdjustDown(heap, 0, heapSize - i);
++i;
}
}
int main()
{
int arr[] = { 27,15,19,18,28,34,65,49,25,37 };
int arrSize = sizeof(arr) / 4;
HeapSort(arr, arrSize);
for (int i = 0; i < arrSize; ++i)
{
printf("%d ", arr[i]);
}
return 0;
}
以上就是整个堆排序的内容了。
2. TopK问题
2.1 什么是TopK
TOP-K问题:即求出一组数据中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
2.2 思路
- 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆 - 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
2.3 代码实现
#include <time.h>
void TopK(const char* fileName, int k)
{
//以读的方式打开文件
FILE* fout = fopen(fileName, "r");
if (!fout)
{
perror("fopen fail");
exit(-1);
}
//创建k个数的小堆
int* minHeap = (int*)malloc(sizeof(int) * k);
if (!minHeap)
{
perror("fopen fail");
exit(-1);
}
//先把文件中前k个数塞进数组中
for (int i = 0; i < k; ++i)
{
fscanf(fout, "%d", minHeap + i);
}
//向下调整建堆,此时建的小堆
for (int i = (k - 2) / 2; i >= 0; --i)
{
AdjustDown(minHeap, i, k);
}
//假设此时的堆中元素就是前k大的数,堆顶就是第k大
//再把后N-k个数依次与堆顶的元素进行比较
//比堆顶的数大就进堆
//读到文件末尾时,堆里存放的就是前k大的数
int val = 0;
while (fscanf(fout, "%d", &val) != -1)
{
if (val > minHeap[0])
{
minHeap[0] = val;
AdjustDown(minHeap, 0, k);
}
}
}
void createDataFile(const char* fileName, int N)
{
//调用时间戳
srand((unsigned)time(NULL));
//以写的方式打开文件
FILE* fin = fopen(fileName, "w");
if (!fin)
{
perror("fopen fail");
exit(-1);
}
//随机生成10000个数
for (int i = 0; i < N; ++i)
{
fprintf(fin, "%d\n", rand() % 10000);
}
fclose(fin);
}
int main()
{
const char* fileName = "data.txt";
int N = 10000;
int k = 6;
//创建文件,随机生成10000个数
createDataFile(fileName, N);
//选出前k个大的数
TopK(fileName, k);
return 0;
}
复杂度分析:建了k个数的堆,并且要比较后N-K个数,因此时间复杂度最坏为K + log*(N-K),大概为O(N),空间复杂度为O(K),只用了k个额外空间。
本篇完