Django视图层模版层全面解析全网最细的教程
文章目录
- 一、网页伪静态
- 二、视图层
- 1.视图函数的返回值问题
- 2.视图函数返回Json格式数据
- 3.Form表单携带文件数据
- 4.FBV与CBV
- 5.CBV源码分析
- 三、模版层
- 1.模版语法传值
- 2.模版语法传值范围
- 3.模版语法过滤器
- 4.模版语法标签(类似于Python流程控制)
- 5.自定义标签函数、过滤器、Inclusion_tag
- 6.模版继承
- 7.模版导入
一、网页伪静态
什么是伪静态网页呢 ?
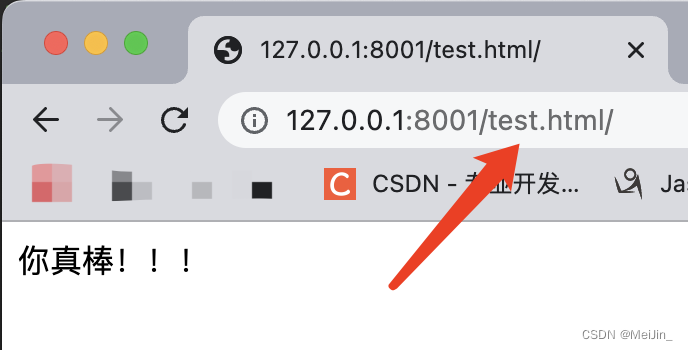
我们之前写的接口后缀都是正常网址(https://blog.csdn.net/MeiJin_)而伪静态后缀像是一个文件(https://blog.csdn.net/MeiJin_.html)
搜索引擎一看到后缀是一个文件会认为是一个具体的文件 就回收录下来 后续不用更改的 被收录的也意味着被查询的概率越大
将动态网页伪装成静态网页 从而提升网页被搜索引擎收录的概率 表现形式就是网址看着想一个具体的文件路径
那我们需要怎样去实现这个操作呢 ?
把路由设置成 Path('index.html', view.index) # 那么访问的时候就需要使用index.html去访问了
二、视图层
1.视图函数的返回值问题
我们都知道视图函数会返回一个值但是我们这种情况呢?
def index(request):
return None
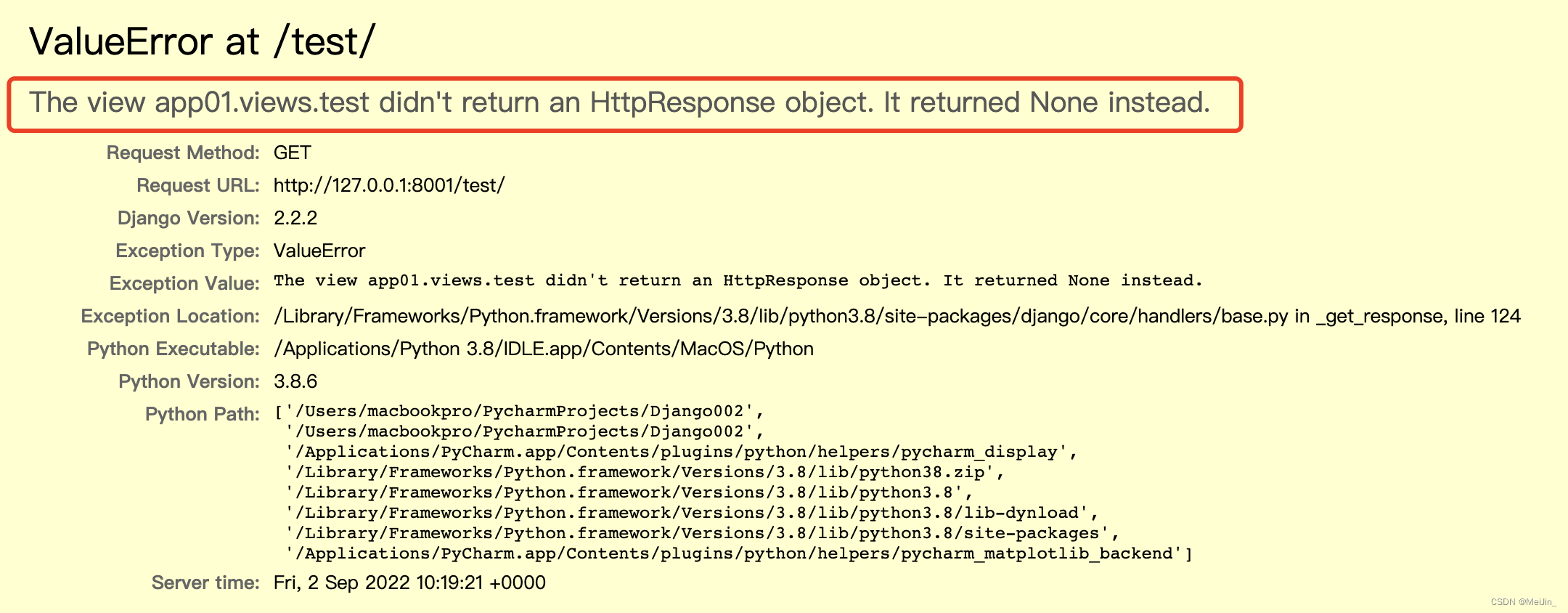
报错信息是ValueError at /index/
The view app01.views.test didn't return an HttpResponse object. It returned None instead.
翻译过来意思就是视图函数必须返回一个HttpResponse对象
但是我们三板斧总共有三个 HttpResponse、render、redirect
我们通过源码去查看这三个都是类 类名加括号产生一个对象 所以返回的都是对象
class HttpResponse(HttpResponseBase):
pass
def render():
return HttpResponse(...)
def redirect(to, *args, permanent=False, **kwargs):
redirect_class = HttpResponsePermanentRedirect if permanent else HttpResponseRedirect
return redirect_class(resolve_url(to, *args, **kwargs))
2.视图函数返回Json格式数据
视图函数返回Json格式的数据怎么操作呢 ?
有两种方法:
1.直接通过json模块
import json
def index(request):
user_dict = {'name':'Like', 'Age':'20','hobby':['篮球','音乐','学习']}
json_str = json.dumps(user_dict,ensure_ascii=False) # 如果数据中有中文会进行编码 如果不想编码需要使用ensure_ascii
return HttpResponse(json_str)
2.使用Django的中JsonResponse 独立于三板斧之外
from django.http import JsonResponse
def index(request):
user_dict = {'name':'Like', 'Age':'20','hobby':['篮球','音乐','学习']}
return JsonResponse(user_dict)
# 但是这个时候也会自动编码中文 这个时候我们不需要 就需要去查看源码了
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
if safe and not isinstance(data, dict):
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
if json_dumps_params is None:
json_dumps_params = {}
kwargs.setdefault('content_type', 'application/json')
data = json.dumps(data, cls=encoder, **json_dumps_params)
super().__init__(content=data, **kwargs)
我们发送的数据都会被data接受 后面的encode没有接受任何参数 再往下看**json_domps_params中的**是干嘛的呢?
**在这调用一个函数就是 **在实参中起作用 将字典打散成关键词参数 但是现在字典是空的 我们现在把上面的None改成
ensure_ascill = False 也就意味着不走if分支 就回把这个添加到字典中就成了json.dumps(ensure_ascii':False)
这个时候我们就知道了 把他添加一个False不走分支就好了
序列化非字典类型的数据还需要指定safe参数为False
如果没有修改则报错 In order to allow non-dict objects to be serialized set the safe parameter to False.
所以最终解法:
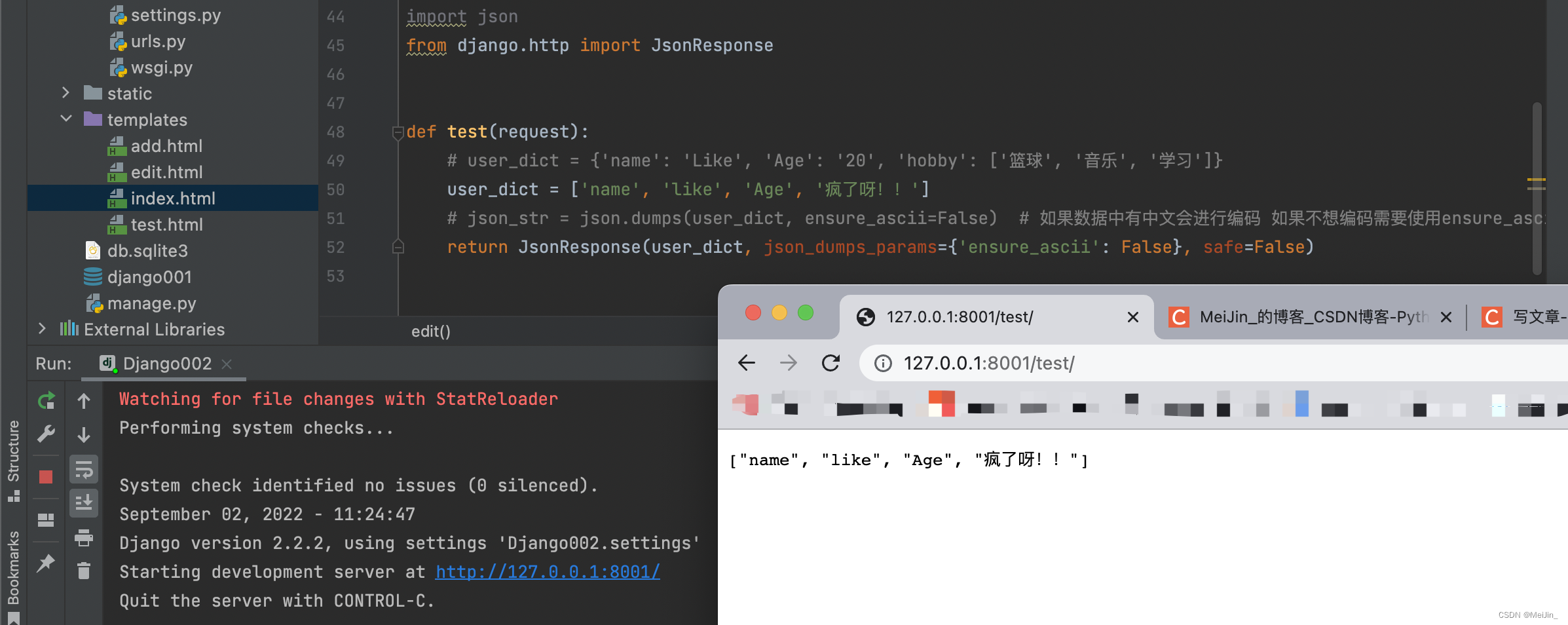
def test(request):
user_dict = {'name': 'Like', 'Age': '20', 'hobby': ['篮球', '音乐', '学习']}
user_dict = ['name', 'like', 'Age', '疯了呀!!']
return JsonResponse(user_dict, json_dumps_params={'ensure_ascii': False}, safe=False)
# 即可兼容中文了 也可以兼容列表了
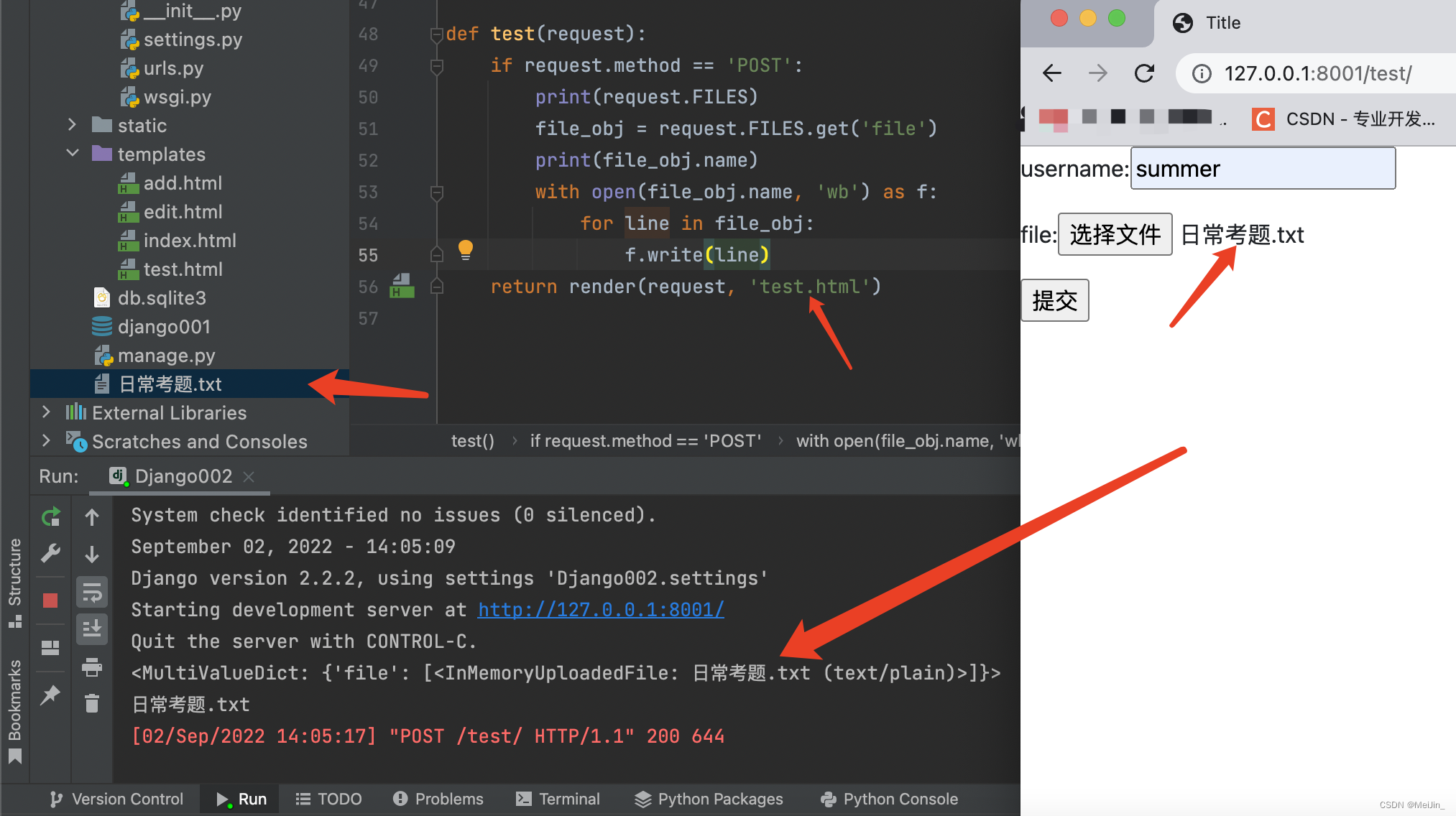
3.Form表单携带文件数据
我们在后台想接收到文件数据 那么会使用到From表单但是From表单使用之前的方法只会拿到名字 获取不到文件信息 这是因为在Django里面还需要设置一个参数才会有效
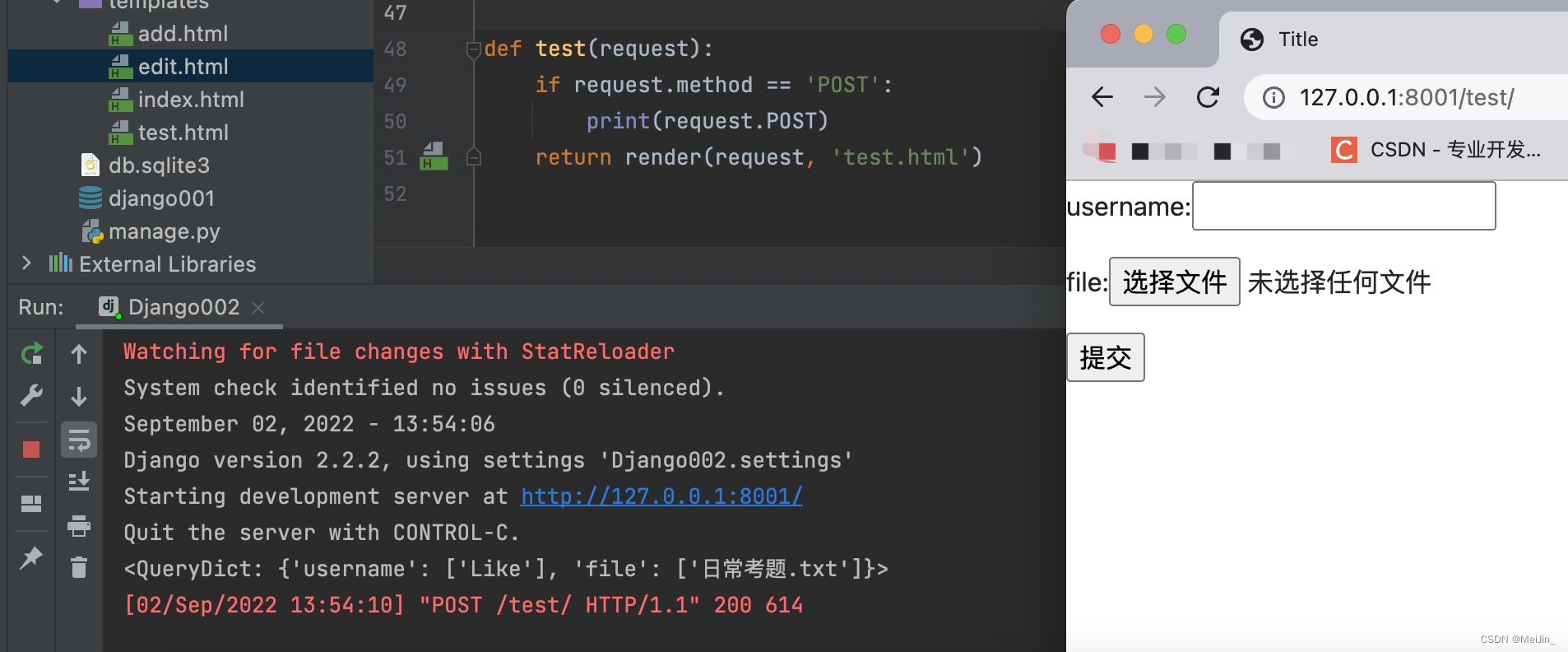
form表单需要具备的条件
1.首先From的method属性值必须是POST发送数据
2.表单必须有属性 enctype="multipart/form-data"
后端获取文件数据的操作
不再是request.post 而是request.FILES
4.FBV与CBV
FBV基于函数视图 现在我们VIEWS里面写的都是函数 这个就是FBV
def index(request):
return HttpResponse()
path('index/', views.index)
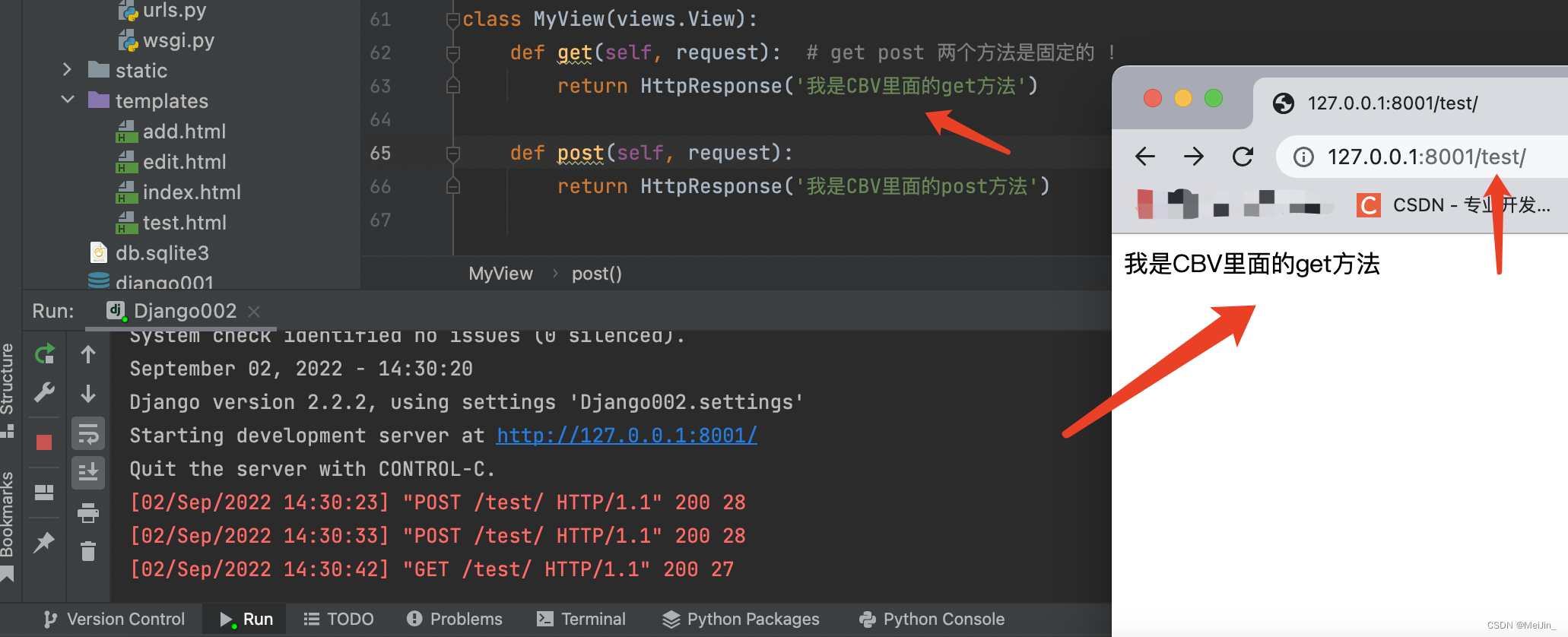
CBV基于类的视图 CBV就是使用类来写了
from django import views
class MyView(views.View):
def get(self, request): # get post 两个方法是固定的 !
return HttpResponse('我是CBV里面的get方法')
def post(self, request):
return HttpResponse('我是CBV里面的post方法')
path(test/', views.MyView.as_view()) # CBV路由匹配 不再是点一个函数名而是一个类名加方法名
当发送一个get请求会自动触发get 发送一个post也会自动触发post
CBV会自动根据请求方式的不同匹配类中定义的方法并自动执行
5.CBV源码分析
为什么不同方法来能够触发不同的代码呢 ? 我们一起来看看源码!!!
首先是源码分析入口
path('test/', views.MyView.as_view()) # 类点一个名字相当于一个对象点一个名字并且还加了括号 应该是方法了
1.研究绑定给类as_view的方法 只做了一件事 定义了view方法又给view返回出去了
def as_view(....):
def view(...):
pass
return view
2.所以到此我们就知道了调用方法之后就会产生一个结果viewCBV最终的本质就是
path('test/', views.view) # 最终还是回到FBV一摸一样的形式 只是这个VIew不是我们写的
3.访问test触发view执行
def view(...):
obj = cls() # 现在cls是我们自己定义的类 myView() 产生一个对象
return obj.dispath() # 涉及到对象点名字 一定要确定对象是谁 再确定查找顺序 我们没有写 就要去找dispath发现是view的
4.研究dispatch方法
def dispatch(...): # 判断当前请求方法在不在当前请求方法里面
func_name = getattr(obj,request.method.lower())
func_name(...) # getattr拿到自己的写的对象 找自己有没有请求方法 我们有写则直接执行 这就是CBV
# 这八个请求方法
# http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']

三、模版层
1.模版语法传值
方式1: 指定名称 不浪费资源空间 但是不能传很多
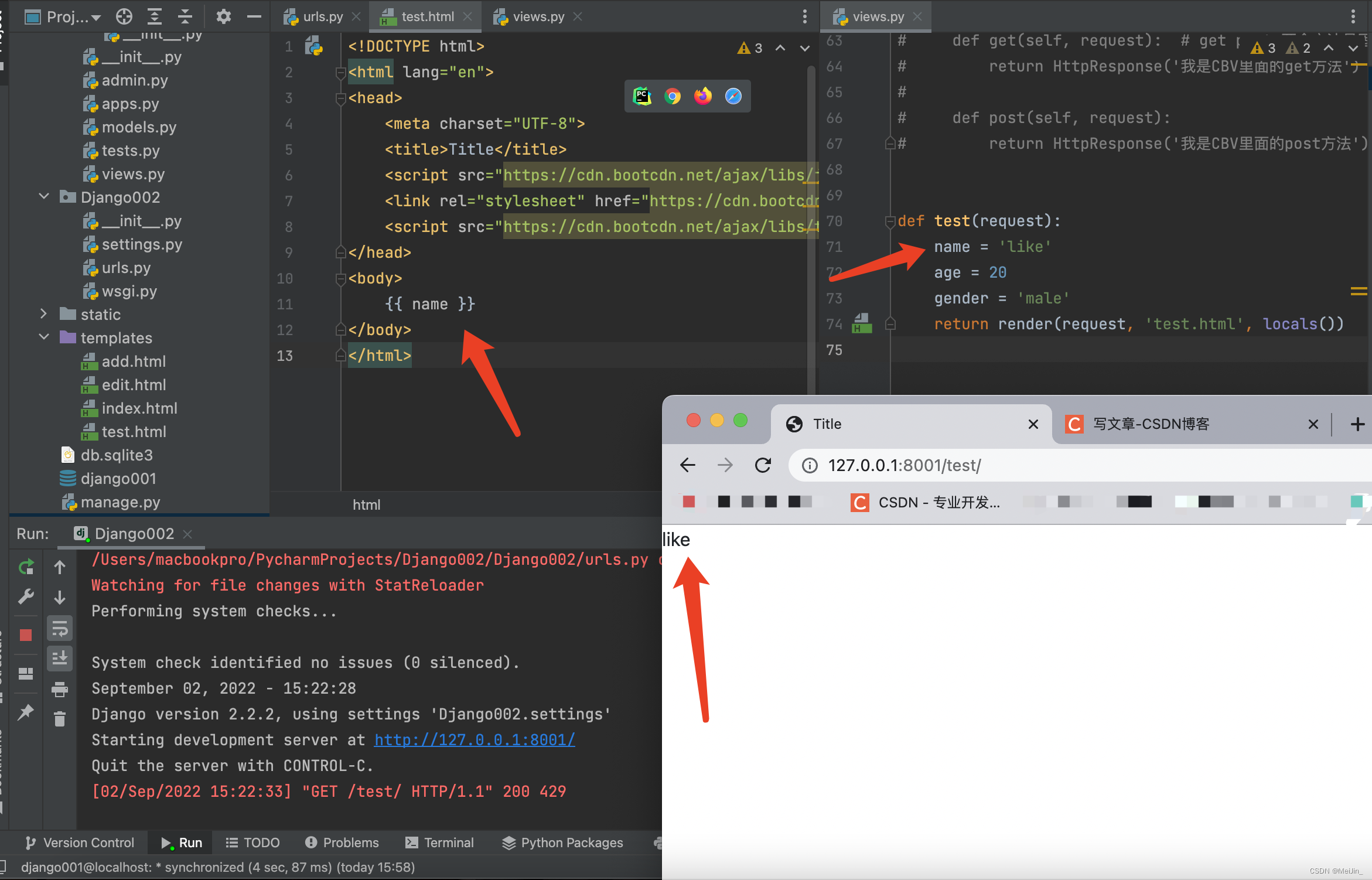
def name(request):
name = 'LIke'
return render(request, 'name.html',{'name':name})
方式2: 关键字locals() 将整个局部名称空间中的名字去全部传入简单快捷 如果很少的话则浪费资源空间
def name(request):
name='LIke' age=20 gender='male'
return render(request, 'name.html', locals()) # 前端页面使用 {{ name }}就可以使用了
2.模版语法传值范围
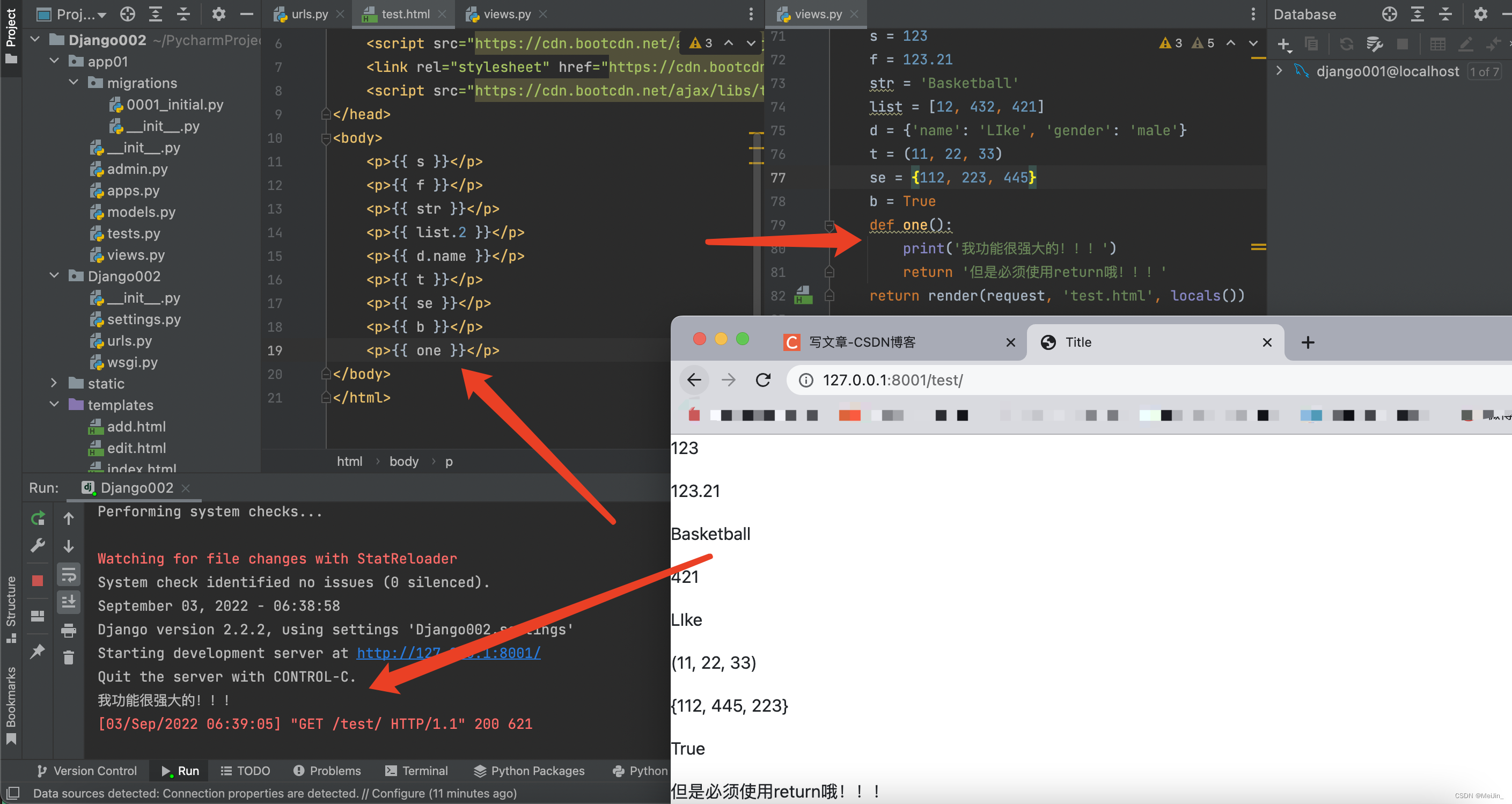
关于模版语法传值的范围是很大的 我们的八大数据类型都可以传值还有函数以及类
1.函数名的传递会自动加括号执行并将返回值展示到页面上 需要写上return返回值才可以返回到页面
注意函数如果有参数则不会执行也不会展示 模板语法不支持有参函数
2.类名的传递也会自动加括号产生对象内存地址并展示到页面上
如果想使用的话可以通过对象句点符的方式点出来
ps:模板语法会判断每一个名字是否可调用 如果可以则调用!!!
3.模版语法过滤器
模版语法其实在页面上也有像Python一样内置方法 模版语法也提供了 就是为了操作数据 可以看成Python内置函数
模版语法 {{ 变量名| 语法方法 }}
{% 变量名| 语法方法 %}
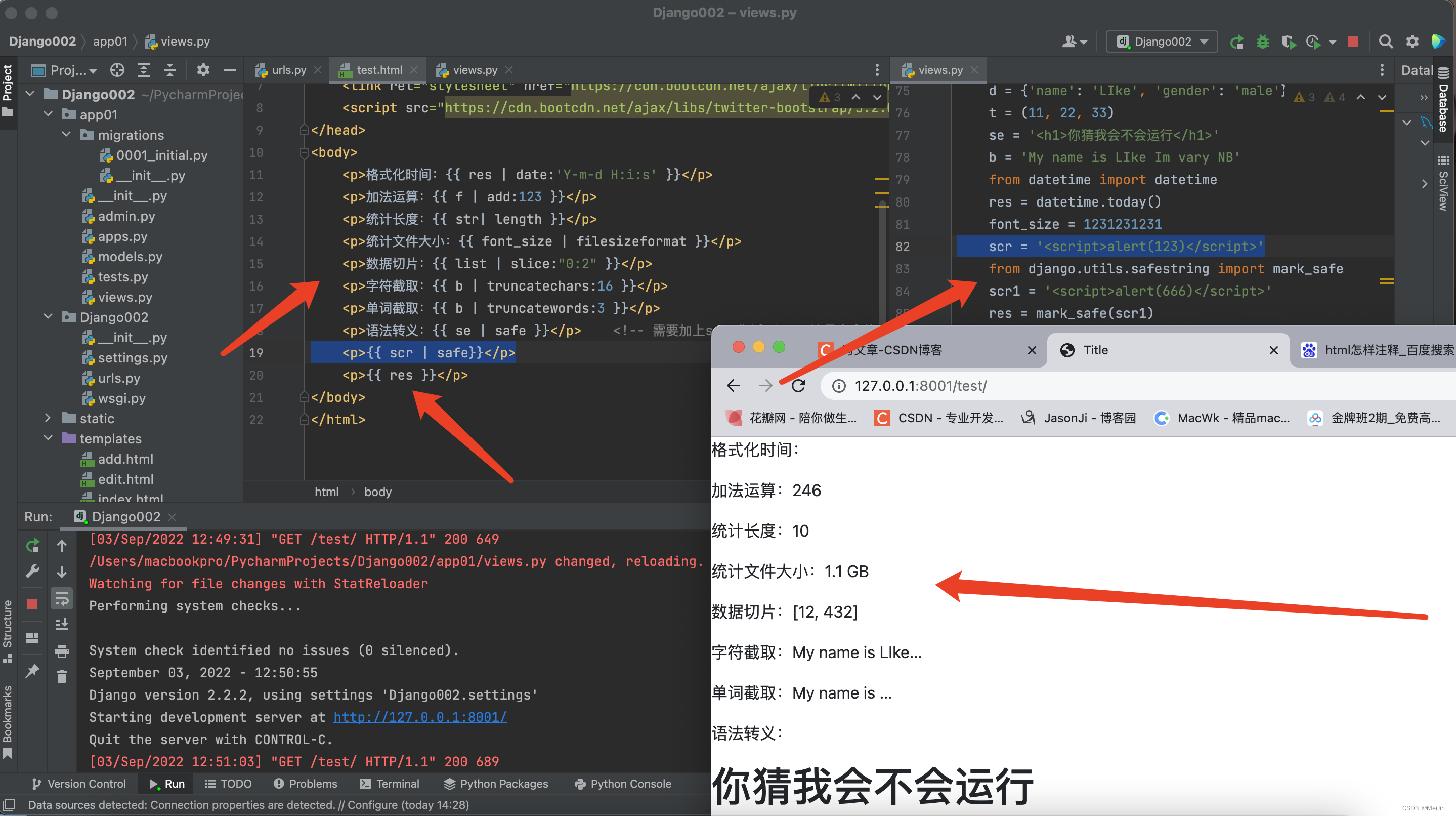
<p>格式化时间:{{ res | date:'Y-m-d H:i:s' }}</p>
<p>加法运算:{{ f | add:123 }}</p>
<p>统计长度:{{ str| length }}</p>
<p>统计文件大小:{{ font_size | filesizeformat }}</p>
<p>数据切片:{{ list | slice:"0:2" }}</p>
<p>字符截取:{{ b | truncatechars:16 }}</p>
<p>单词截取:{{ b | truncatewords:3 }}</p>
<p>语法转义:{{ se | safe }}</p> <!-- 需要加上safe告诉Django这是安全的直接运行 -->
<p>{{ scr | safe}}</p> # 运行html
<p>{{ res }}</p> # 运行script
有时候html页面上的数据不一定非要在html页面上编写了 也可以后端写好传入
from django.utils.safestring import mark_safe # 导入模块
scr1 = '<script>alert(666)</script>' # 通过后台写好 前端直接使用 查看下图
res = mark_safe(scr1)
4.模版语法标签(类似于Python流程控制)
if elif else
{% if 条件 %} 条件一般是模板语法传过来的数据 直接写名字使用即可
条件成立执行的代码
{% elif 条件1 %}
条件1成立执行的代码
{% else %}
条件都不成立执行的代码
{% endif %}
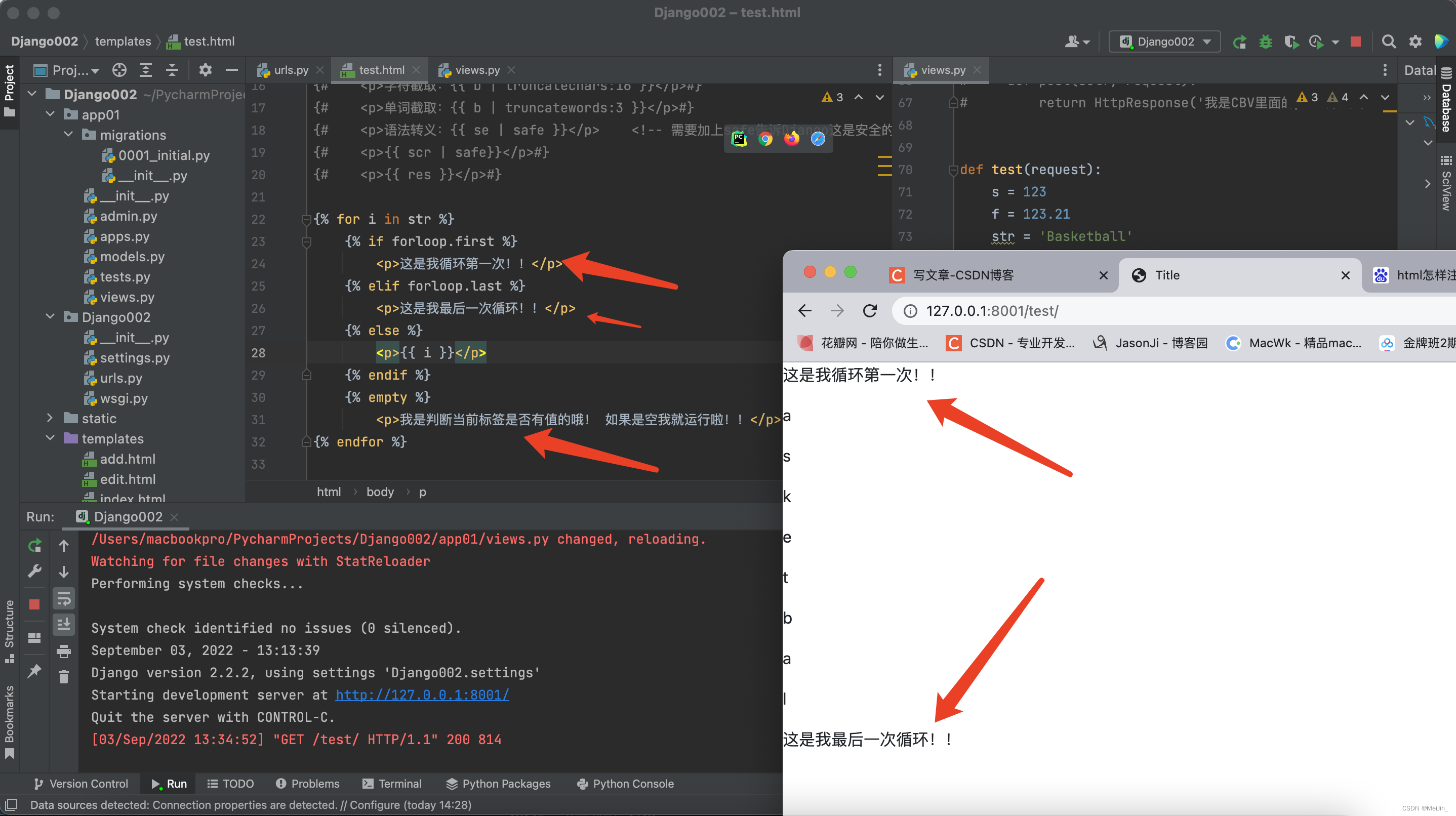
for循环(html页面输入for Tab后面会自动补全)需要用到一个关键字 forloop 用来记录循环第几次的
{% for i in str %}
{% if forloop.first %}
<p>这是我循环第一次!!</p>
{% elif forloop.last %}
<p>这是我最后一次循环!!</p>
{% else %}
<p>{{ i }}</p>
{% endif %}
{% empty %}
<p>我是判断当前标签是否有值的哦! 如果是空我就运行啦!!</p>
{% endfor %}
5.自定义标签函数、过滤器、Inclusion_tag
如果想自定义 必须先做以下三件事
1.在应用下创建一个名为templatetags文件夹
2.在该文件夹创建任意名称的py文件
3.在该py文件内编写自定义相关代码
from django.template import Library
register = Library() # 这两行代码在py文件中固定格式
自定义过滤器
@register.filter(name='myfilter') # 过滤器最多最多只能有两个参数 不能有三个
def my_add(a, b):
return a + b
自定义标签函数 # 可以穿任意个数参数
@register.simple_tag(name='mt')
def func(a, b, c, d):
return a + b + c + d
自定义inclusion_tag
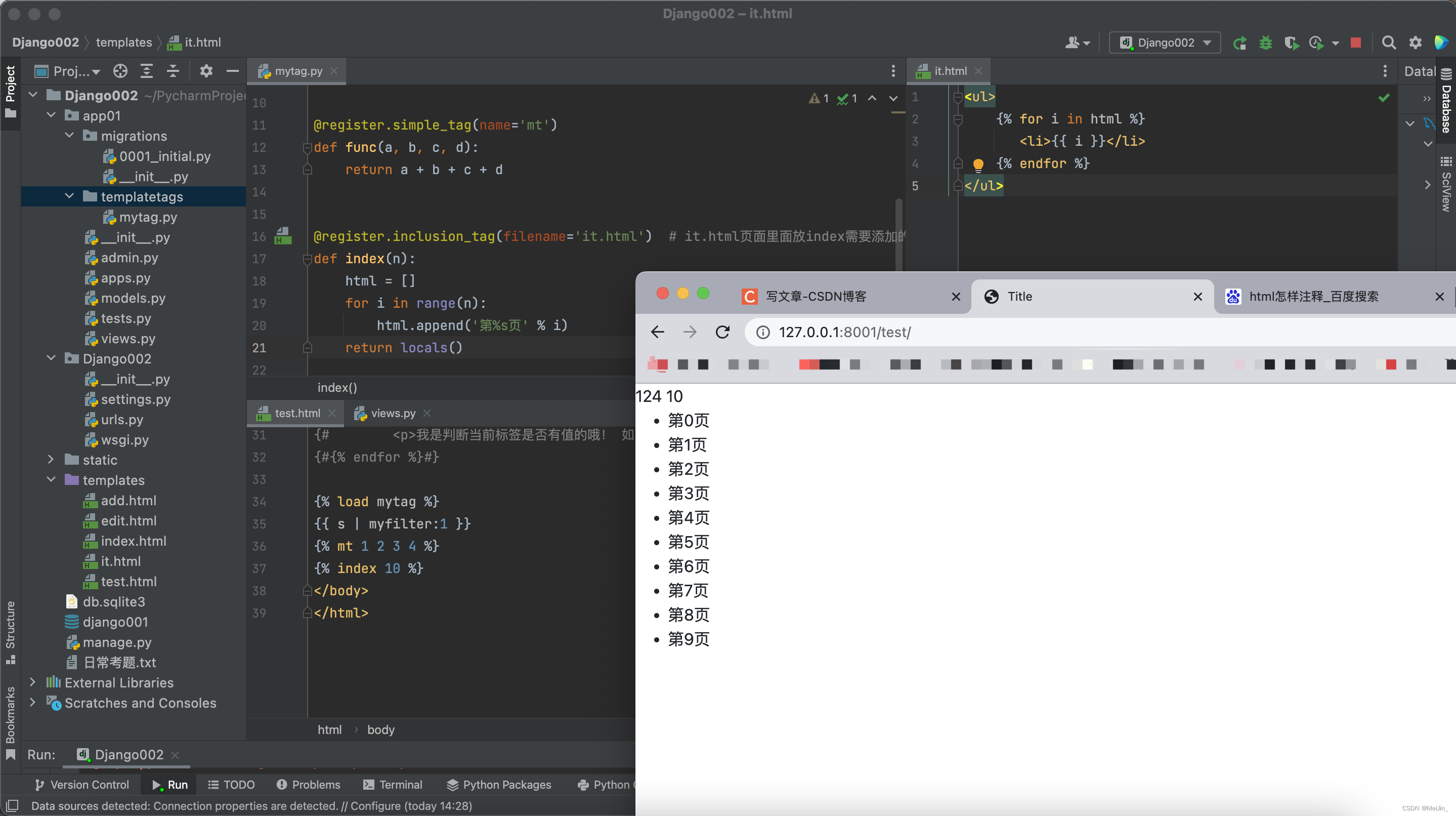
@register.inclusion_tag(filename='it.html') # it.html页面里面放index需要添加的内容样式 需要自己创建it.html
def index(n):
html = []
for i in range(n):
html.append('第%s页'%i)
return locals()
it.html里面的内容:
<ul>
{% for i in html %}
<li>{{ i }}</li>
{% endfor %}
</ul>
三个方法调用方式
{% load mytag %} # 加载自定义的标签
{{ i | myfilter:1 }}
{% mt 1 2 3 4 %}
{% index 10 %} # 可以通过传参产生几个标签
6.模版继承
{% extends 'html文件名' %} # 新建一个页面 第一行写入继承代码
{% block 名字 %} # 可以通过这个方式定位到页面的位置
模板内容 # 这个地方填写新的代码
{% endblock %}
{% block 名字 %}
子板内容
{% endblock %}
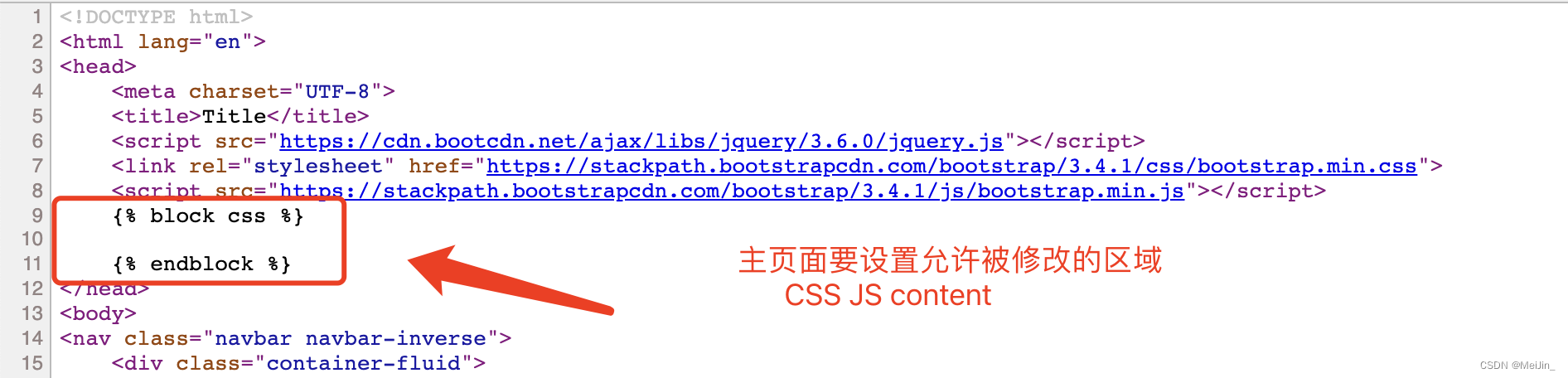
一般情况下母板中至少应该有三个区域使得扩展性更高!!!
css content js
{% block css %}
{% endblock %}
{% block content %}
{% endblock %}
{% block js %}
{% endblock %}
'''子板中还可以使用母板的内容 {{ block.super }} 让他使用之前原主页的内容'''
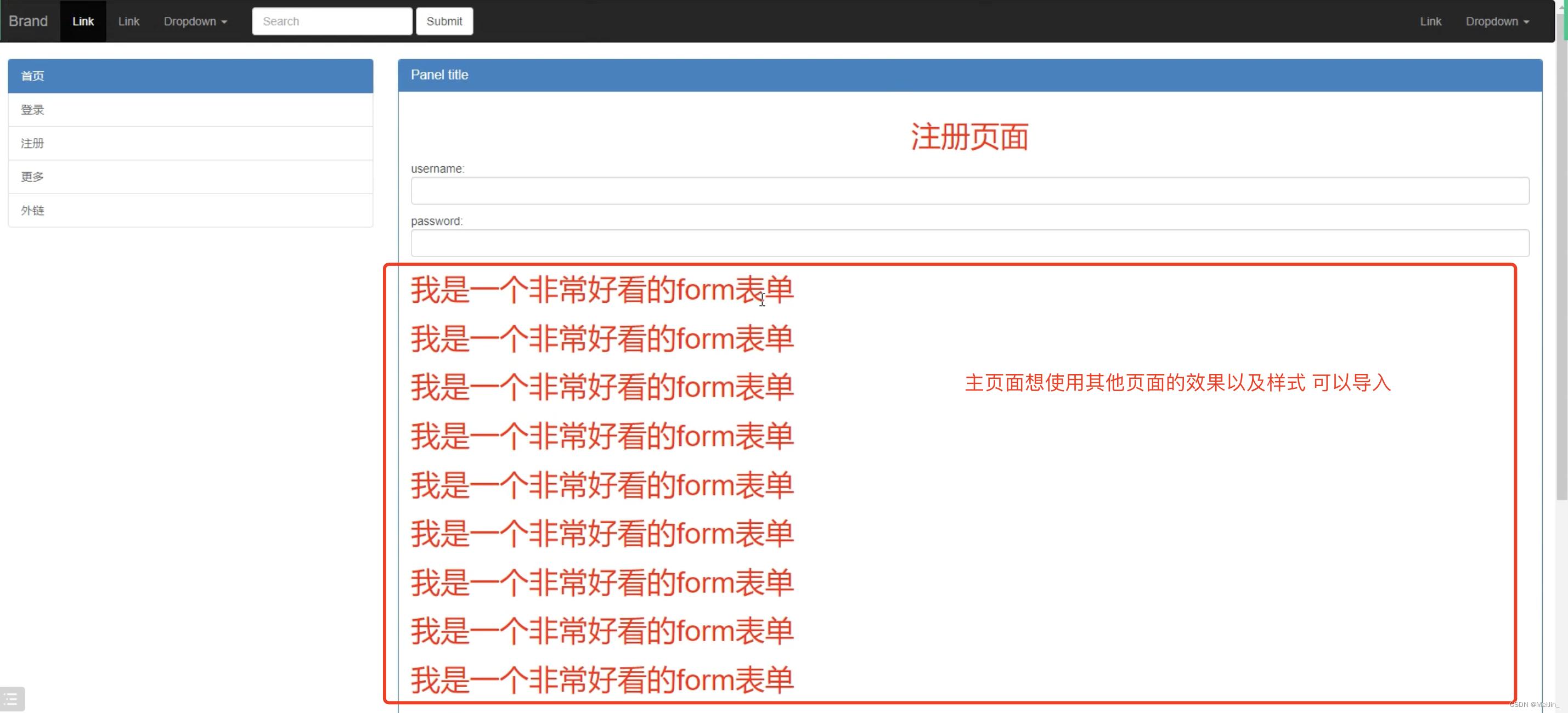
7.模版导入
将html页面的某个部分当做模块的形式导入使用
{% include '网页名称.html' %}
技术小白记录学习过程,有错误或不解的地方请指出,如果这篇文章对你有所帮助请
点点赞收藏+关注谢谢支持 !!!