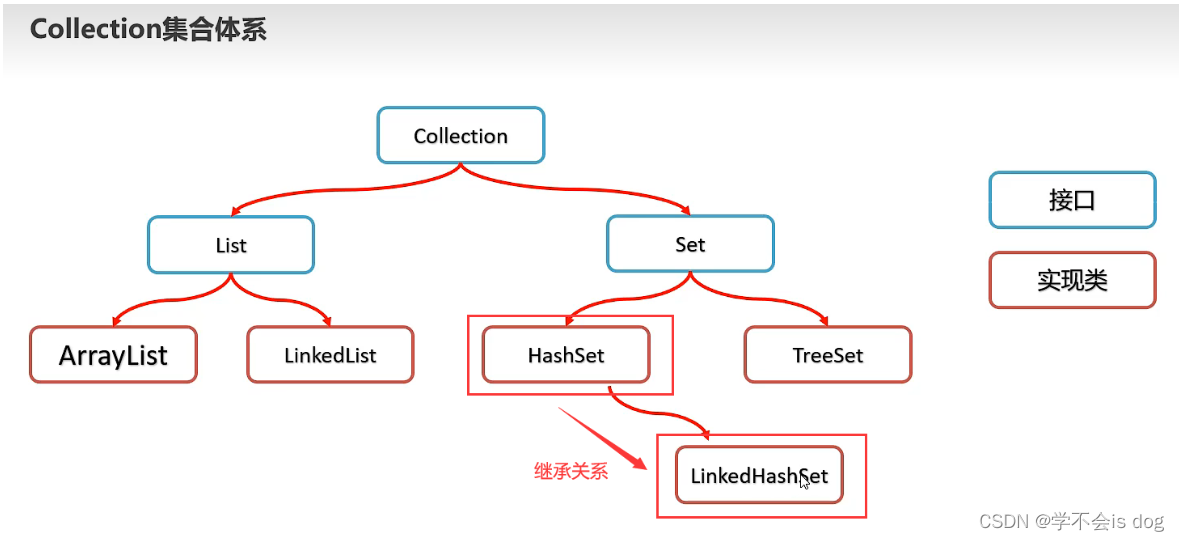
77-Java的Set系列集合、Collection体系的总结
一、本章学习简介
1、Set系列集合
2、Map集合体系
3、今天同学们需要学会什么?
- Set系列集合的特点和底层原理。
- 集合工具类Collections:
- 快速的对集合进行元素的添加,排序等操作。
- 综合案例:
- 把Collection家族的集合应用起来解决一些问题。
- Map集合体系:
- Map体系的集合能解决什么问题,有哪些体系,各自的特点是什么样的?
- 集合的嵌套:
- 开发中集合中的元素可能又是一种集合形式,这种方式很常见,需要认识,并学会对其进行处理。
二、Set系列集合
1、概述
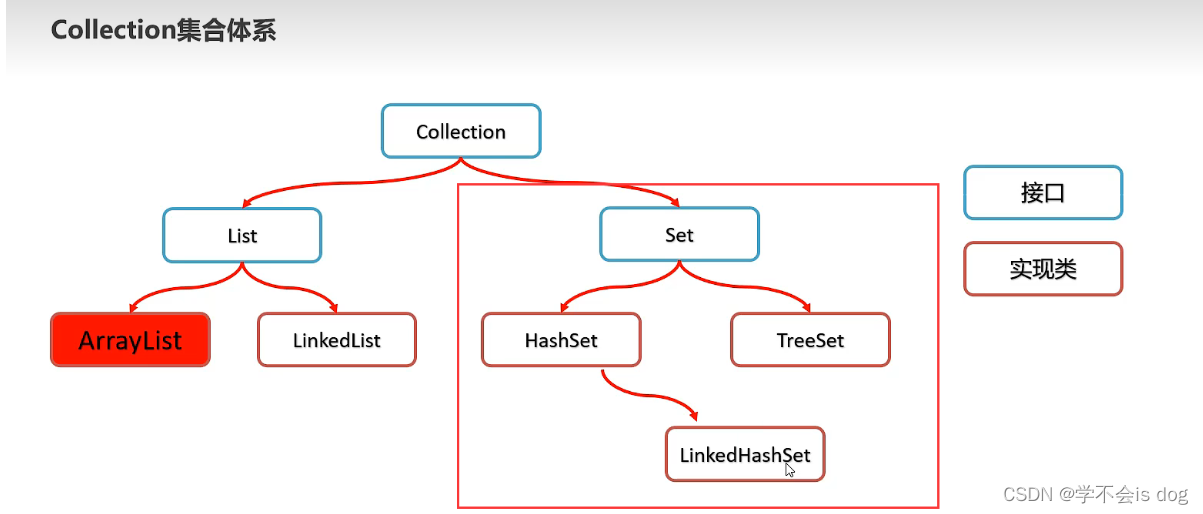
(1)Set系列集合特点
- 无序:存取顺序不一致。
- 不重复:可以去除重复。
- 无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素。
(2)Set集合实现类特点
-
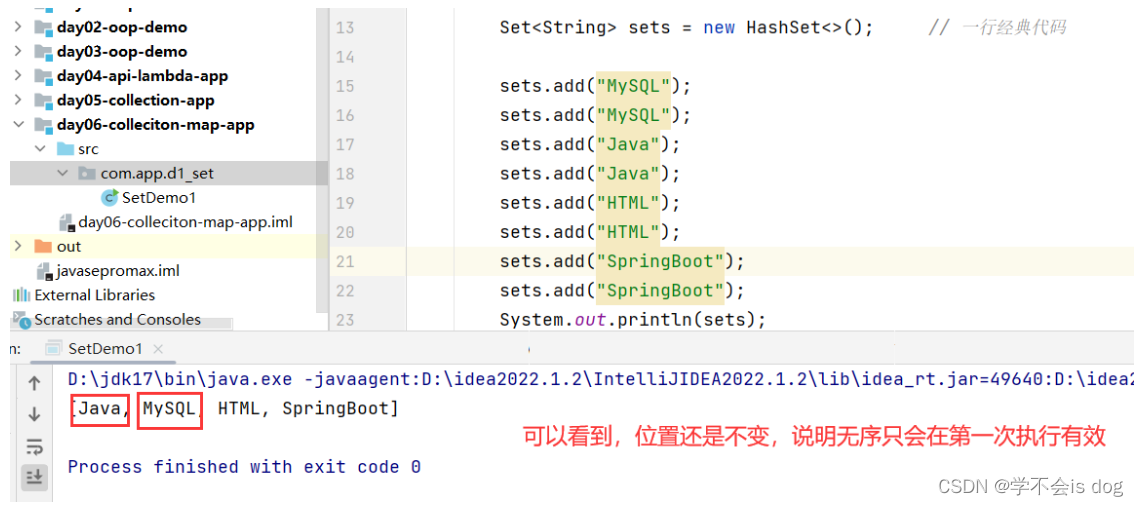
HashSet: 无序、不重复、无索引。

-
第一次执行

-
第二次执行
-
-
LinkedHashSet:
有序、不重复、无索引。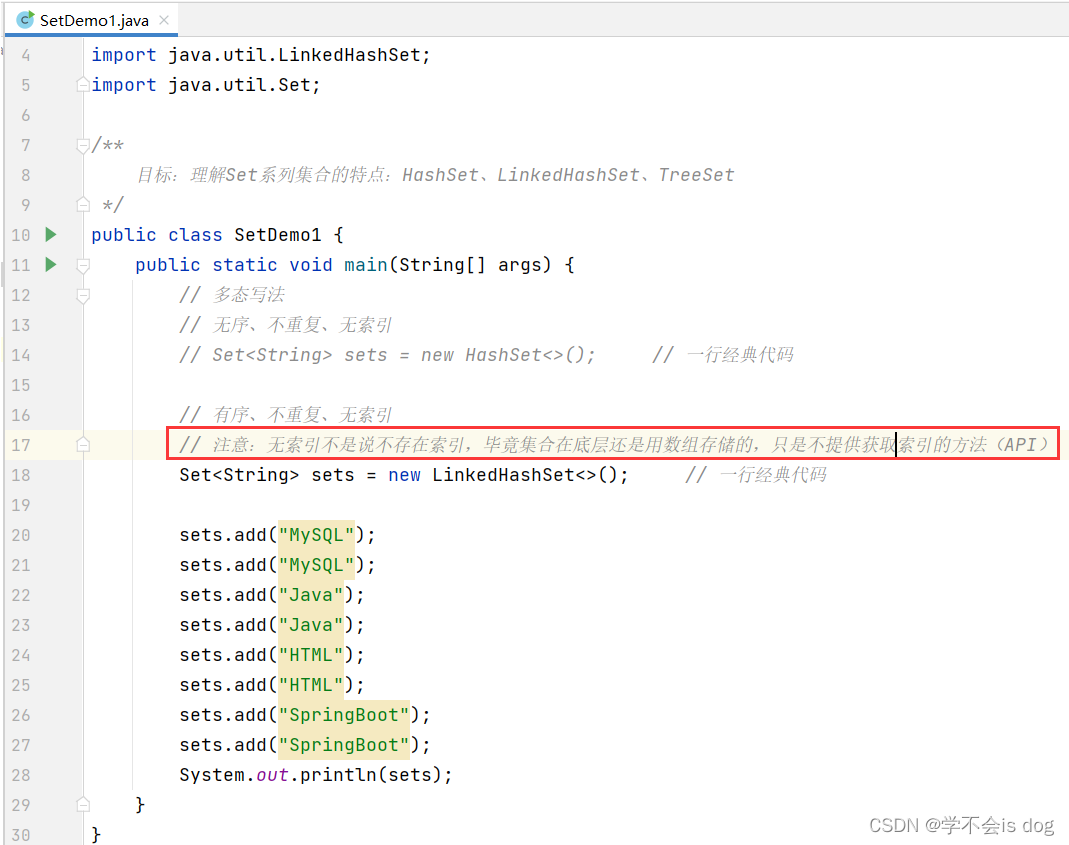
-
执行:
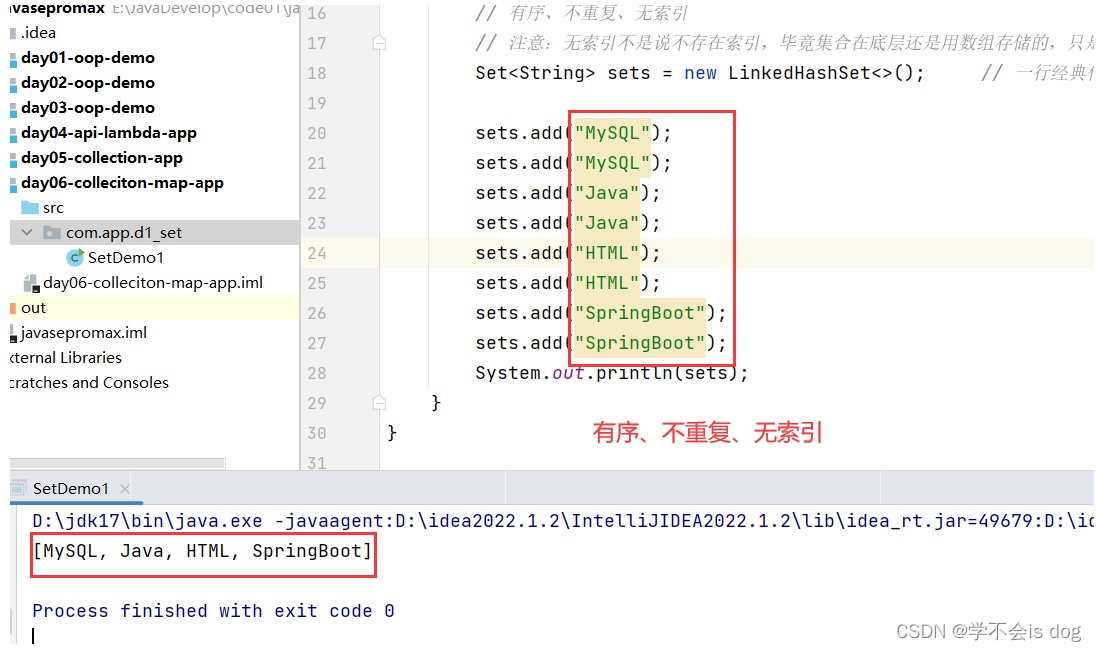
-
- TreeSet:
排序、不重复、无索引。
Set集合的功能上基本上与Collection的API一致。
总结
1、Set系列集合的特点是什么?
- 无序、不重复、无索引。
2、Set集合的实现类特点是什么?
- HashSet无序、不重复、无索引。
- LinkedHashSet
有序、不重复、无索引。 - TreeSet
排序、不重复、无索引。
2、HashSet元素无序的底层原理:哈希表
(1)HashSet底层原理
- HashSet集合底层采取
哈希表存储的数据。 哈希表是一种对于增删改查数据性能都较好的结构。
(2)哈希表的组成
-
JDK8之前的,底层使用
数组+链表组成。 -
JDK8开始后,底层采用
数组+链表+红黑树组成。
在了解哈希表之前需要先理解哈希值的概念。
(3)哈希值
- 是JDK根据对象的
地址,按照某种规则算出来的int类型的数值。
(4)Object类的API
| 方法 | 说明 |
|---|---|
| public int hashCode() | 返回对象的哈希值 |
(5)对象的哈希值特点
-
同一个对象多次调用
hashCode()方法返回的哈希值是相同的。(因为是同一个对象地址) -
默认情况下,不同对象的哈希值是不相同的。(因为每个对象的地址是不一样的)
package com.app.d2_set_hashcode; /** 目标:学会获取对象的哈希值 */ public class setDemo1 { public static void main(String[] args) { // 获取哈希值:hashCode()方法 Student s1 = new Student(); System.out.println(s1.hashCode()); System.out.println(s1.hashCode()); Animal a1 = new Animal(); System.out.println(a1.hashCode()); System.out.println(a1.hashCode()); System.out.println("----------------------"); String name = "abcde"; System.out.println(name.hashCode()); System.out.println(name.hashCode()); String name2 = "abcde"; System.out.println(name2.hashCode()); System.out.println(name2.hashCode()); String name3 = "张飞"; System.out.println(name3.hashCode()); System.out.println(name3.hashCode()); } }2003749087 2003749087 990368553 990368553 ---------------------- 92599395 92599395 92599395 92599395 794046 794046 Process finished with exit code 0
(6)HashSet1.7版本原理解析:数组+链表+(结合哈希算法)
- 创建一个默认长度为16到的数组,数组名为table。
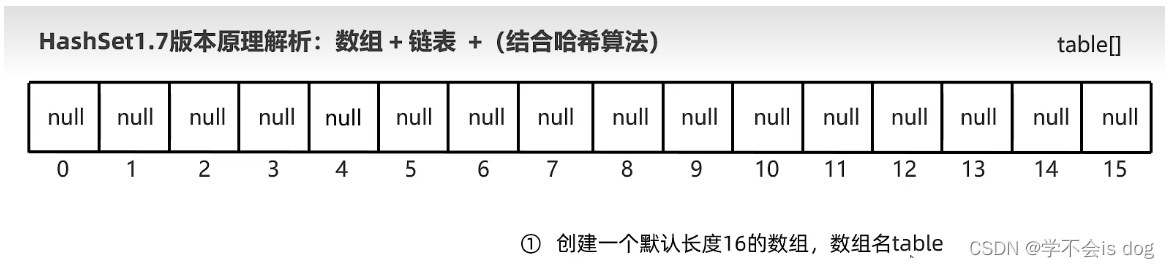
- 假如第一个元素的哈希值是163,对数组的长度16求余,余数为3。
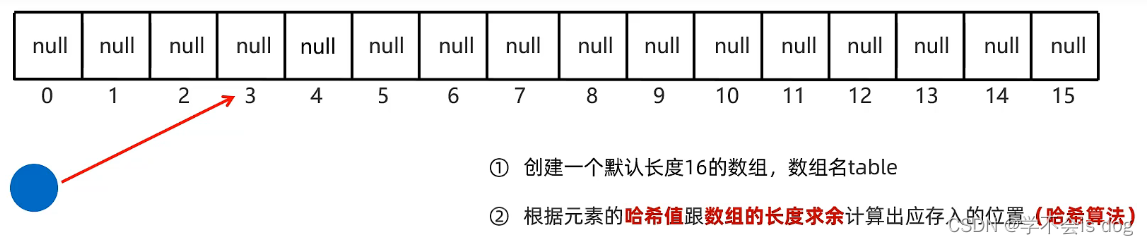
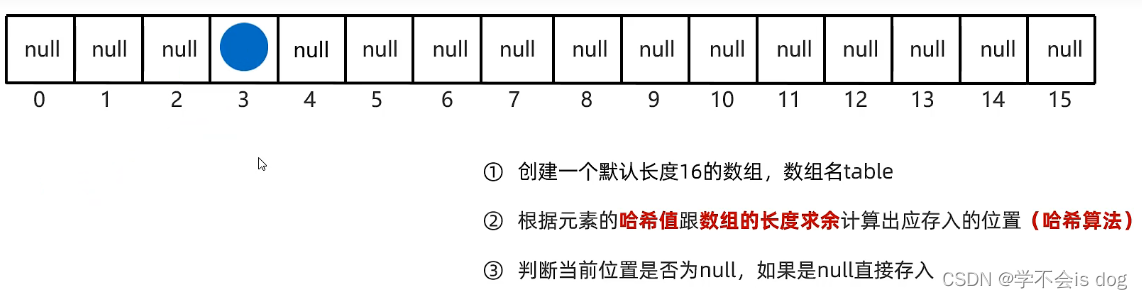
- 计算出来,存入与计算结果相应的位置
-
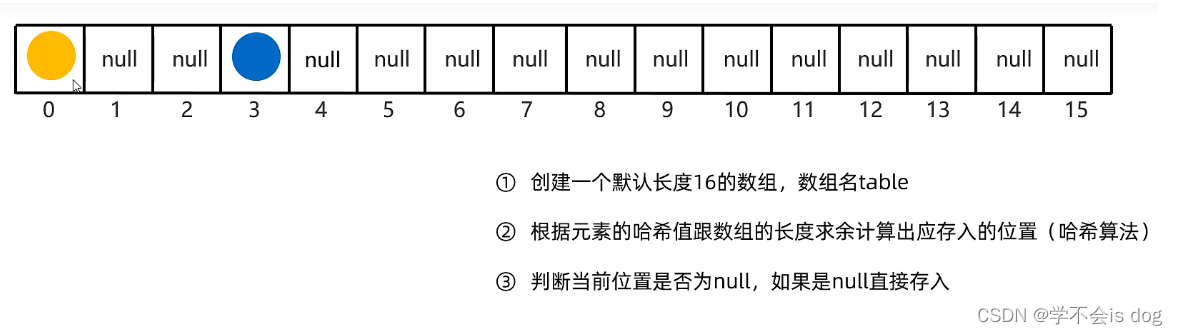
假如第二个元素的哈希值是160,对数组长度16求余,余数为0。因此这个元素存入0的位置,这就是它无序的原因。
-
假如第三个元素的哈希值对数组长度求余的结果也是3,刚好3位置不为null,表示有元素,则底层会调用equals方法比较,一样,就不存,不一样,就存。。


-
如果再来一个元素

-
结论:
- 哈希表是一种对于增删改查数据性能都较好的结构。
(7)JDK8开始后HashSet原理解析
-
底层结构:哈希表(
数组、链表、红黑树的结合体) -
当挂在元素下面的数据过多时,查询性能降低,从JDK8开始后,当
链表长度超过8的时候,自动转换为红黑树。
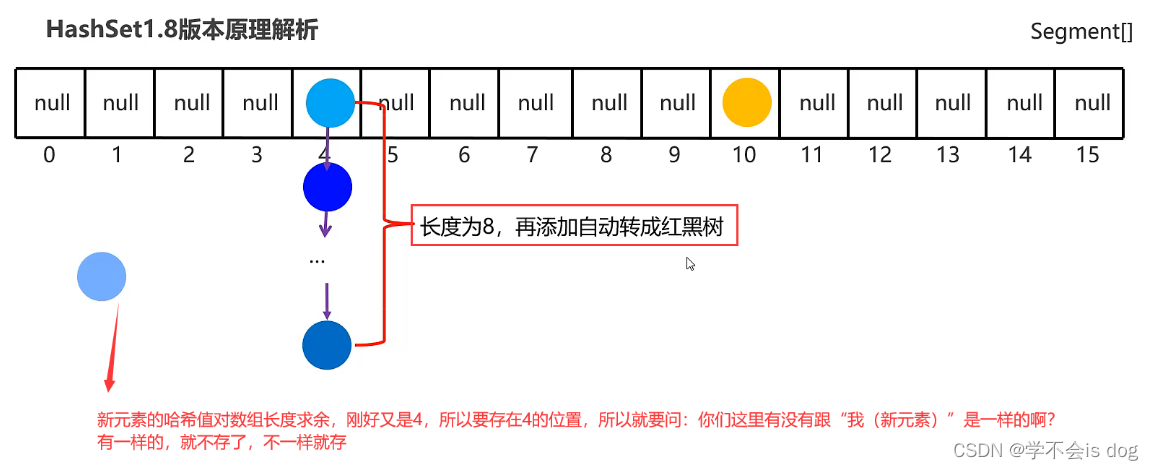
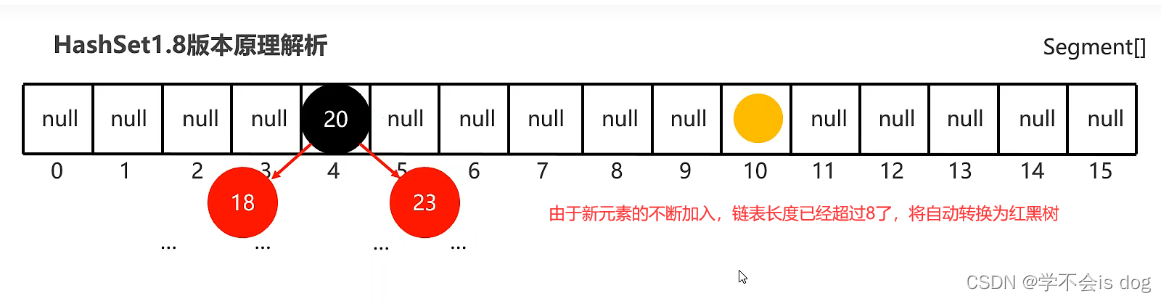
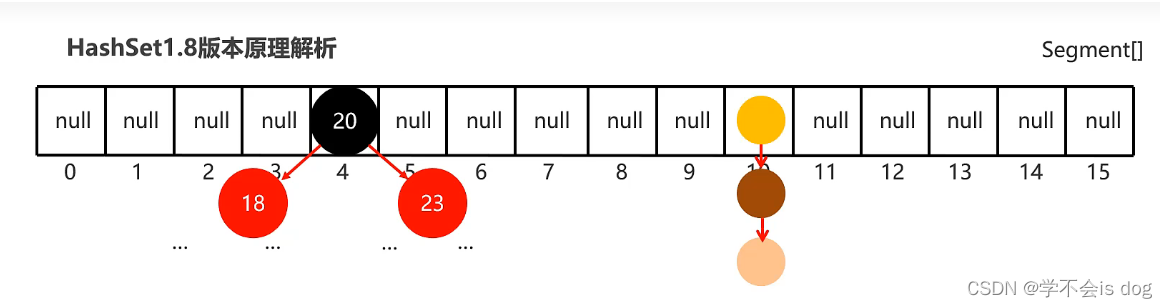
结论:
- JDK8开始后,哈希表对于红黑树的引入进一步提高了操作数据的性能。
总结
1、Set集合的底层原理是什么样的?
- JDK8之前的,哈希表:底层使用
数组+链表组成。 - JDK8开始后,哈希表:底层使用
数组+链表+红黑树组成。
2、哈希表的详细流程如何?
- 2-1、创建一个默认长度为16,默认加载因为0.75的数组,数组名table;
- 2-2、根据元素的哈希值跟数组的长度计算出应存入的位置;
- 2-3、判断当前位置是否为null,如果是null直接存入,如果不是,表示有元素,则调用equals方法比较属性值,如果一样,则不存,如果不一样,则存入数组;
- 2-4、当数组存满到16*0.75=12时,就自动扩容,每次扩容原先的两倍。
3、HashSet元素去重复的底层原理
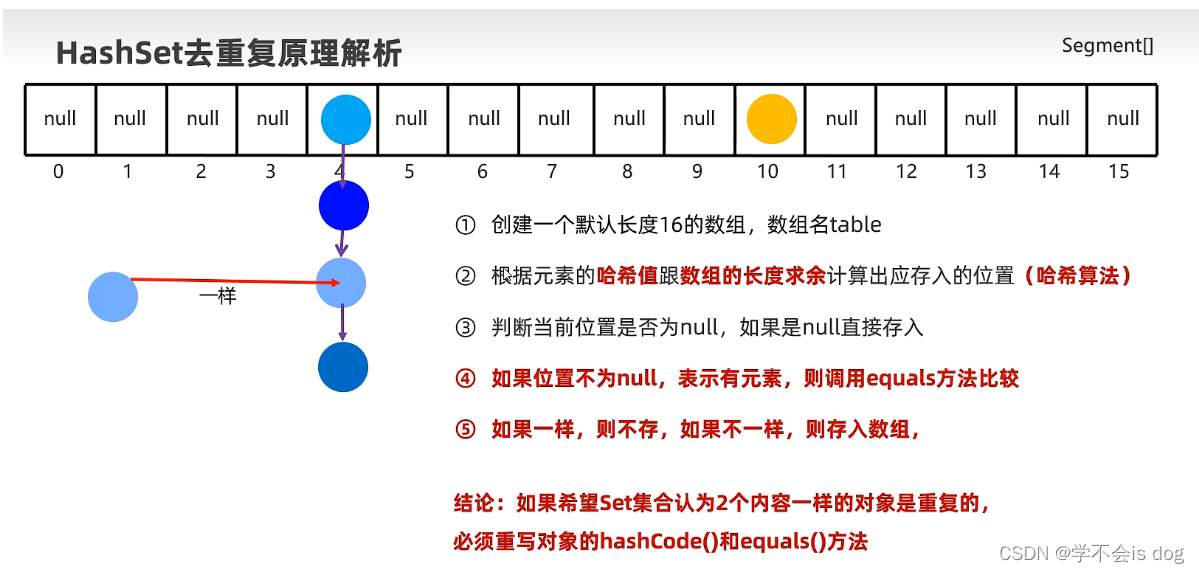
(1)案例导学:Set集合去重复
-
需求:
- 创建一个存储学生对象的集合,存储多个学生对象,使用程序实现在控制台遍历该集合,要求:学生对象的成员变量值相同,我们就认为是同一个对象。
-
分析:
- 1、定义用于封装学生信息的学生类
- 2、创建HashSet集合对象,用于存储学生对象
- 3、创建学生对象,添加到集合中
- 4、在学生类中重写hashCode()和equals(),IDEA自动生成即可
- 5、使用foreach遍历集合
package com.app.d3_set_test; import java.util.Objects; /** 1、定义用于封装学生信息的学生类 */ public class Student { /** 学生属性:姓名、性别、年龄 */ private String name; private char sex; private int age; /** 4、在学生类中重写hashCode()和equals(),IDEA自动生成即可 去掉集合中重复的对象 */ @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return sex == student.sex && age == student.age && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(name, sex, age); } /** 重写toString方法,格式化输出 */ @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", sex=" + sex + ", age=" + age + '}'; } /** 提供无参、有参构造器 */ public Student() { } public Student(String name, char sex, int age) { this.name = name; this.sex = sex; this.age = age; } /** 提供成套的getter、setter方法,暴露其属性的取值和赋值 */ public String getName() { return name; } public void setName(String name) { this.name = name; } public char getSex() { return sex; } public void setSex(char sex) { this.sex = sex; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }package com.app.d3_set_test; import java.util.HashSet; import java.util.Set; /** 目标:通过案例导学,理解Set集合去重复元素的原理 */ public class Test { public static void main(String[] args) { // 多态写法 Set<Student> students = new HashSet<>(); // 一行经典代码 // 3、创建学生对象,添加到集合中 students.add(new Student("黄渤", '男', 34)); students.add(new Student("黄渤", '男', 34)); students.add(new Student("沈腾", '男', 36)); students.add(new Student("沈腾", '男', 36)); students.add(new Student("贾玲", '女', 33)); students.add(new Student("马丽", '女', 37)); // 5、使用foreach遍历集合 for (Student student : students) { System.out.println(student); } } }Student{name='马丽', sex=女, age=37} Student{name='贾玲', sex=女, age=33} Student{name='沈腾', sex=男, age=36} Student{name='黄渤', sex=男, age=34} Process finished with exit code 0
总结
1、如果希望Set集合认为2个内容相同的对象是重复的应该如何?
- 在对象类中重写hashCode()和equals()方法。
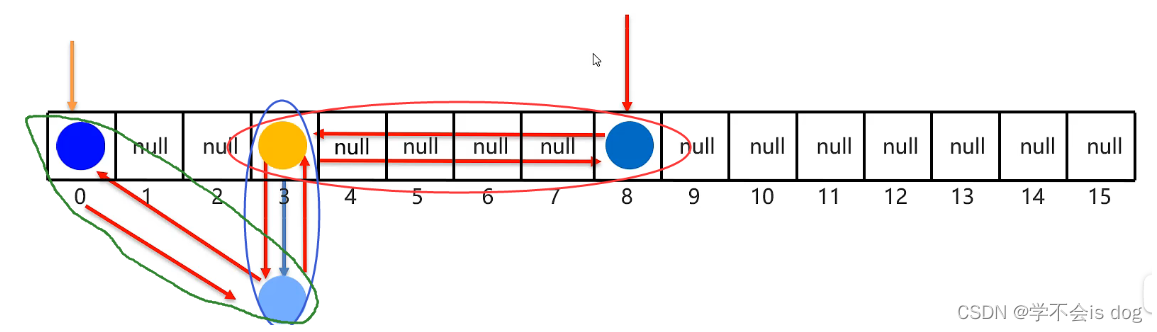
4、实现类:LinkedHashSet
(1)概述和特点
-
有序、不重复、无索引。 -
这里的有序指的是保证存储和取出的元素顺序一致。
-
原理:底层数据结构依然是哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序。
总结
1、LinkedHashSet集合的特点和原理是什么样的?
- 有序、不重复、无索引。
- 底层基于哈希表,使用双链表记录添加顺序。
5、实现类:TreeSet
(1)概述和特点
- 不重复、无索引、
可排序。 - 可排序:按照元素的大小默认升序(有小有大)排序。
- 原理:底层基于
红黑树的数据结构实现排序的,增删改查性能都较好。
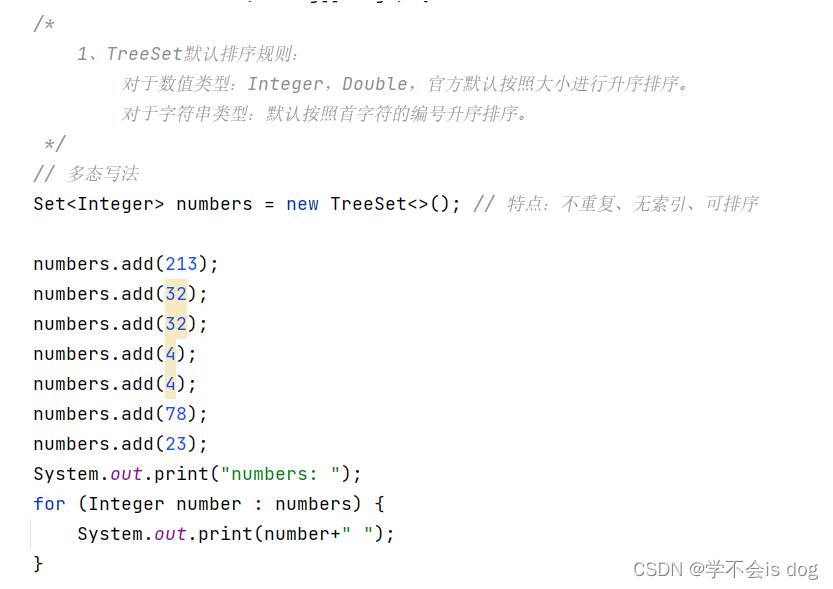
(2)默认排序规则
-
对于数值类型:Integer,Double,官方默认按照大小进行升序排序。

-
对于字符串类型:默认按照首字符的编号升序排序。


-
对于自定义类型(Student、Teacher…):TreeSet是无法直接排序的。


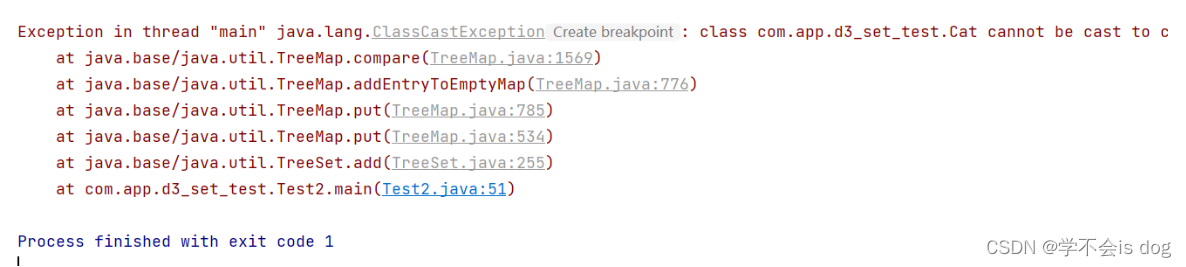
结论:
- 想要使用TreeSet存储自定义类型, 需要自己制定排序规则。
(3)自定义排序规则
-
TreeSet集合存储对象的时候有2种方式可以设计自定义比较规则。
-
方式一:让自定义的类(如学生类、老师类等)
实现Comparable接口重写里面的compareTo方法 来自定义比较规则 。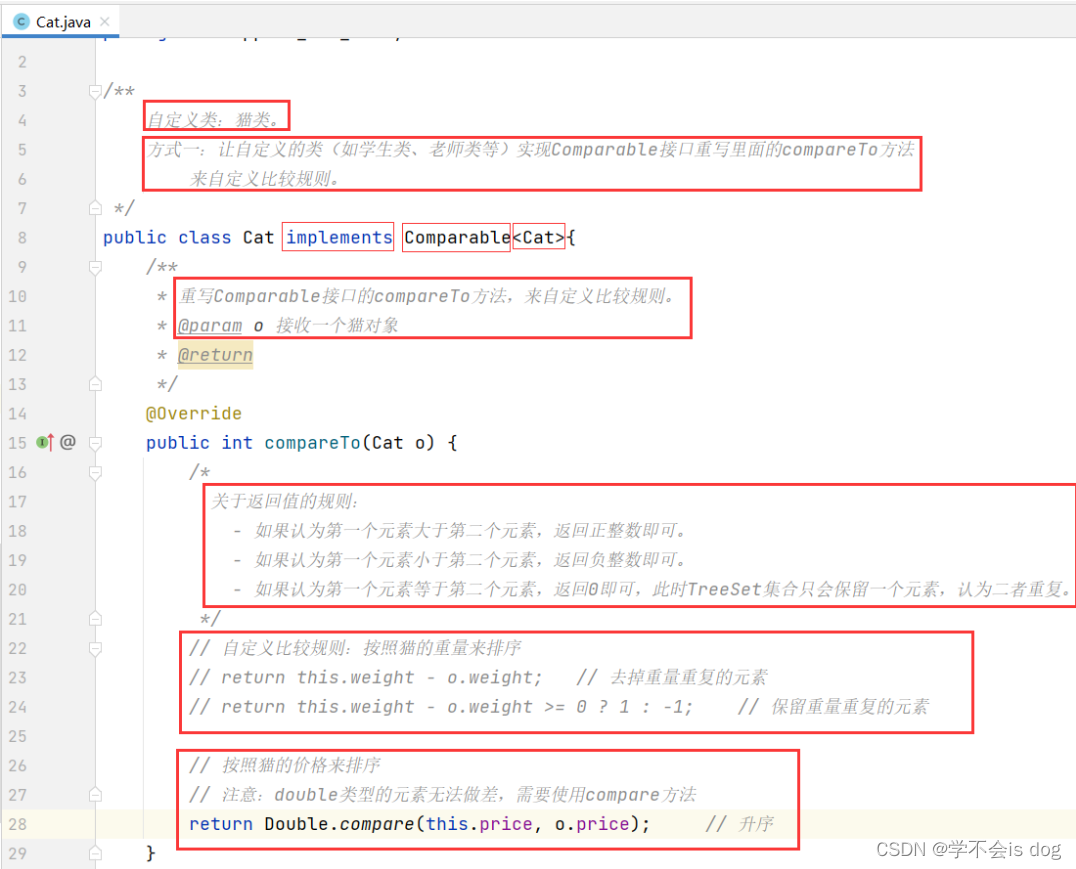
-
方式二:TreeSet集合有参构造器,可以设置
Comparable接口对应的比较器对象,来自定义比较规则。
-
(4)两种方式中,关于返回值的规则:
- 如果认为第一个元素大于第二个元素,返回正整数即可。
- 如果认为第一个元素小于第二个元素,返回负整数即可。
- 如果认为第一个元素等于第二个元素,返回0即可,此时TreeSet集合只会保留一个元素,认为二者重复。
注意:如果TreeSet集合存储的对象有实现比较规则,集合也自带比较器,默认使用集合自带的比较器排序。
package com.app.d3_set_test;
/**
自定义类:猫类。
方式一:让自定义的类(如学生类、老师类等)实现Comparable接口重写里面的compareTo方法
来自定义比较规则。
*/
public class Cat implements Comparable<Cat>{
/**
* 重写Comparable接口的compareTo方法,来自定义比较规则。
* @param o 接收一个猫对象
* @return
*/
@Override
public int compareTo(Cat o) {
/*
关于返回值的规则:
- 如果认为第一个元素大于第二个元素,返回正整数即可。
- 如果认为第一个元素小于第二个元素,返回负整数即可。
- 如果认为第一个元素等于第二个元素,返回0即可,此时TreeSet集合只会保留一个元素,认为二者重复。
*/
// 自定义比较规则:按照猫的重量来排序
return this.weight - o.weight; // 去掉重量重复的元素
// return this.weight - o.weight >= 0 ? 1 : -1; // 保留重量重复的元素
// 按照猫的价格来排序
// 注意:double类型的元素无法做差,需要使用compare方法
// return Double.compare(this.price, o.price); // 升序
}
/**
猫的属性:昵称、毛色、价格、重量
*/
private String name;
private String color;
private double price;
private int weight;
public Cat(){
}
public Cat(String name, String color, double price, int weight) {
this.name = name;
this.color = color;
this.price = price;
this.weight = weight;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
@Override
public String toString() {
return "Cat{" +
"name='" + name + '\'' +
", color='" + color + '\'' +
", price=" + price +
", weight=" + weight +
'}';
}
}
package com.app.d3_set_test;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
目标:理解TreeSet集合对于有值特性的数据如何进行排序的。
学会对自定义类型的对象进行制定自定义比较规则来进行排序。
*/
public class Test2 {
public static void main(String[] args) {
/*
1、TreeSet默认排序规则:
对于数值类型:Integer,Double,官方默认按照大小进行升序排序。
对于字符串类型:默认按照首字符的编号升序排序。
*/
// 多态写法
Set<Integer> numbers = new TreeSet<>(); // 特点:不重复、无索引、可排序
numbers.add(213);
numbers.add(32);
numbers.add(32);
numbers.add(4);
numbers.add(4);
numbers.add(78);
numbers.add(23);
System.out.print("numbers: ");
for (Integer number : numbers) {
System.out.print(number+" ");
}
System.out.println();
Set<String> codes = new TreeSet<>();
codes.add("Java");
codes.add("Java");
codes.add("About");
codes.add("About");
codes.add("age");
codes.add("马楼");
codes.add("Double");
System.out.print("codes: ");
for (String code : codes) {
System.out.print(code+" ");
}
System.out.println("\n----------------------------------------");
// 对于自定义类型(Student、Teacher...):TreeSet是无法直接排序的。
// Set<Cat> cats = new TreeSet<>();
/*
方式二:TreeSet集合有参构造器,可以设置Comparable接口对应的比较器对象,来自定义比较规则。
注意:如果TreeSet集合存储的对象有实现比较规则,集合也自带比较器,默认使用集合自带的比较器排序
*/
/*Set<Cat> cats = new TreeSet<>(new Comparator<Cat>() {
@Override
public int compare(Cat o1, Cat o2) {
// 按照重量升序
// return o1.getWeight() - o2.getWeight(); // 去掉重量重复的元素
// return o1.getWeight() - o2.getWeight() >= 0 ? 1 : -1; // 保留重量重复的元素
// return o2.getWeight() - o1.getWeight(); // 按照重量降序
// return Double.compare(o1.getPrice(), o2.getPrice()); // 按照价格升序
return Double.compare(o2.getPrice(), o1.getPrice()); // 按照价格降序
}
});*/
// 简化:lambda表达式写法
Set<Cat> cats = new TreeSet<>( (o1, o2) -> Double.compare(o2.getPrice(), o1.getPrice()) );
cats.add(new Cat("胖球", "花白色", 899.9, 40));
cats.add(new Cat("咪咪", "白色", 666.5, 40));
cats.add(new Cat("小黑", "黑色", 899.8, 25));
cats.add(new Cat("虾皮", "黄色", 566.9, 33));
System.out.println("cats: ");
for (Cat cat : cats) {
System.out.println(cat);
}
}
}
numbers: 4 23 32 78 213
codes: About Double Java age 马楼
----------------------------------------
cats:
Cat{name='胖球', color='花白色', price=899.9, weight=40}
Cat{name='小黑', color='黑色', price=899.8, weight=25}
Cat{name='咪咪', color='白色', price=666.5, weight=40}
Cat{name='虾皮', color='黄色', price=566.9, weight=33}
Process finished with exit code 0
总结
1、TreeSet集合的特点是什么样的?
- 可排序、不重复、无索引。
- 底层基于红黑树实现排序,增删改查性能较好。
2、TreeSet集合自定义排序规则有几种方式?
- 两种(二选一即可,优先第二种):
- 自定义的类实现Comparable接口,重写compareTo方法自定义比较规则。
- 集合自定义Comparator比较器对象,重写compare方法自定义比较规则。
- 注意:如果TreeSet集合存储的对象有实现比较规则,集合也自带比较器,默认使用集合自带的比较器排序。
三、Collection体系的特点、使用场景总结
1、如果希望元素可以重复,又有索引,索引查询要快,用什么集合?
- 用ArrayList集合,基于数组的(用的最多)。
2、如果希望元素可以重复,又有索引,增删首尾操作快,用什么集合?
- 用LinkedList集合,基于链表的。
3、如果希望增删改查都快,但是元素不重复、无序、无索引,用什么集合?
- HashSet集合,基于哈希表的。
4、如果希望增删改查都快,但是元素不重复、有序、无索引,用什么集合?
- LinkedHashSet集合,基于哈希表和双链表的。
5、如果要对对象进行排序,用什么集合?
- TreeSet集合,基于红黑树。后续也可以用List集合实现排序。