【Python炫技】使用zip函数,帮你写出更为Pythonic的代码!
SOS,今天说到的此zip(),非彼.zip的压缩文件 …
Python中的zip函数
Python中有一个zip()函数,可以用来将可迭代的iterable对象作为参数,吧对象中对应的元素打包成一个个的元组,然后返回由这些元组组成的列表。
在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。
这个函数,在我们日常对多个数组进行合并,或者相同长度的数组遍历时,有很大的帮助。示例:
a = [1, 2, 3]
b = [4, 5, 6]
li = zip(a, b)
print(li) # <zip object at 0x0000017AEEBD6C88>
print(list(li)) # [(1, 4), (2, 5), (3, 6)]
zip函数的妙用
将zip配合enumerate一起使用时,将会更大程度的减少你的代码量。不信你来看看下面这道题
题目要求我们,将a、b数组按照下标进行计算
当下标为奇数时,计算两者对应元素求和,返之计算两者差的绝对值。
并按照index: value的方式逐行打印。
示例:
a = [1, 2, 3, 4, 5]
b = [6, 7, 8, 9, 10]
如果是我们常规的代码,大概我猜应该是这么写吧:
for i in range(len(a)):
if i % 2:
print(f"{i}:{a[i] + b[i]}")
else:
print(f"{i}:{abs(a[i] - b[i])}")
但加入我们使用zip配合enumerate,会让你的代码更加Pythonic:
for i, (x, y) in enumerate(zip(a, b)):
print(f"{i}:{x + y if i % 2 else abs(x - y)}")
这样不仅仅让我们省去了频繁书写 列表[index]的方式,在炫技逼格上也有所提升。
zip函数的弊端
但zip函数也有自己的弊端,如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
虽然有些场景下我们恰好需要这个特性,但多数场景下,我们更期望在长度不满足的情况下,可以去最长的列表,然后将短的列表通过默认值的方式进行补充。
那么该怎么做呢?
python的大佬们其实早为我们准备好了解决方案,只是少有人知而已,它就是:zip_longest。
zip_longest 方法需要从itertools 模块中进行导入,顾名思义zip_longest会去最长的列表,不满足长度的使用None进行补充。
当然,为了增强扩展性,还提供了一个fillvalue的关键字,可以支持我们自定义补充内容。
来一起看看它的使用方法吧:
from itertools import zip_longest
a = [1, 2, 3]
b = [4, 5, 6, 7, 8]
li = zip_longest(a, b)
print(li) # <itertools.zip_longest object at 0x000001ACAA0EA4A8>
print(list(li)) # [(1, 4), (2, 5), (3, 6), (None, 7), (None, 8)]
print(list(zip_longest(a, b, fillvalue='NA')))
# [(1, 4), (2, 5), (3, 6), ('NA', 7), ('NA', 8)]
学习了以上的偏门小技巧,下次装X时,请提前想好炫酷的出场Pose吧!
最后的最后,来列举一个可以使用zip完成的力扣算法题目,顺带还帮大家引申了其他的几种解法哦!
14.最长公共前缀
https://leetcode.cn/problems/longest-common-prefix/solution/14-zui-chang-gong-gong-qian-zhui-zhe-cho-uwrm/
难度:简单
题目:
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 “”。
示例:
示例 1:
输入:strs = [“flower”,“flow”,“flight”]
输出:“fl”
示例 2:
输入:strs = [“dog”,“racecar”,“car”]
输出:“”
解释:输入不存在公共前缀。
分析
只要你熟悉zip方法的使用,这种题简直是塞牙缝的…
内置函数zip解题:
使用内置的zip函数进行纵向合并,即可快速解题。
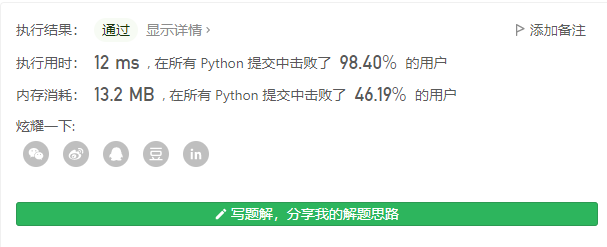
class Solution:
def longestCommonPrefix(self, strs):
ret = ''
for i in zip(*strs):
if len(set(i)) == 1:
ret += i[0]
else:
break
return ret
当然除去简化方法,再提供其他几种思路。
基本的纵向查找
本身通过while 循环和条件判断,无需求最小长度,但这样写起来更为简洁一下。
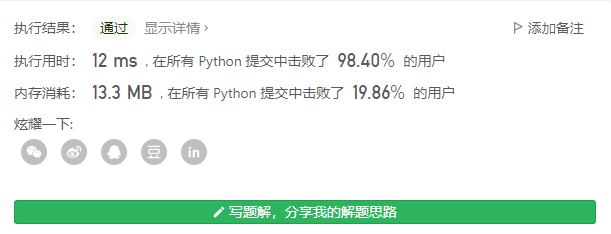
class Solution(object):
def longestCommonPrefix(self, strs):
min_len = min(len(i) for i in strs)
ret = ""
for i in range(min_len):
if len(set(s[i] for s in strs)) > 1:
break
ret += strs[0][i]
return ret
字符串排序
字符串本身按位排序后,只需要针对第一个和最后一个字符串进行比较就能获取最终答案。 相比于纵向查找,看似只比较了第一个和最后一个,但是排序也是消耗时间的…
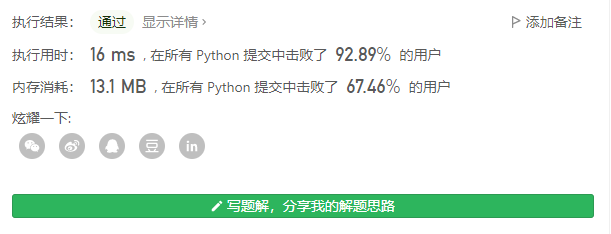
class Solution(object):
def longestCommonPrefix(self, strs):
strs.sort()
lg = min(len(strs[0]), len(strs[-1]))
ret = ""
for i in range(lg):
if strs[0][i] != strs[-1][i]:
break
ret += strs[0][i]
return ret
前缀树(字典树)
其实这道题如果做过前缀树的题目,应该都了解这种解法很符合该题,但大家估计都觉得有些麻烦,所以没写出来吧,在这里提供下前缀树的解题.
- 首先我们将每个单词追加至字典树中,这里要注意,每个单词在结束时需要追加end,下面说为何。
- 执行1后,我们随机取一个单词(默认就拿一个吧)
- 执行search的方法,如果字典树中某个节点额长度大于1,表示在此处遇到了分支,需要终止
- 那么end有什么用?比如[‘a’,‘ab’],如果只比较3的条件,结果就成了"ab",所以需要同时判断是否在该节点出现了某个单词的终止情况。
前缀树的经典题目参照: 208.实现Trie(前缀树)
这里使用字典树看效率就知道了有些过了…
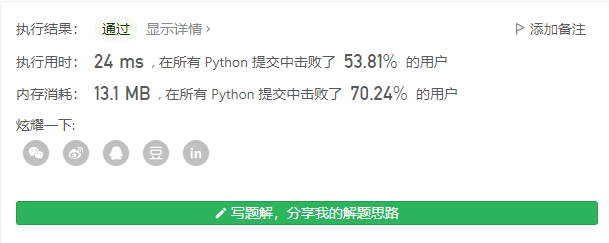
class Trie:
def __init__(self):
self.dic = {}
def insert(self, word):
tmp = self.dic
for w in word:
if w not in tmp:
tmp[w] = {}
tmp = tmp[w]
tmp['end'] = True
def search(self, word):
ret = ''
tmp = self.dic
for w in word:
if len(tmp) > 1 or tmp.get('end'):
return ret
if w in tmp:
ret += w
tmp = tmp[w]
return ret
class Solution(object):
def longestCommonPrefix(self, strs):
trie = Trie()
for s in strs:
trie.insert(s)
return trie.search(strs[0])
欢迎关注我的公_众号: 清风Python,带你每日学习Python算法刷题的同时,了解更多python小知识。
我的个人博客:https://qingfengpython.cn
力扣解题合集:https://github.com/BreezePython/AlgorithmMarkdown