C++----unordered_map unordered_set使用及模拟
unordered_map unordered_set使用及模拟
- 使用
- 模拟
- 结构
- 修改底层bucket_hash
- my_unordered_map
- my_unordered_set
- 注意
使用
unordered_set: 添加链接描述
unordered_map: 添加链接描述
unorderd_multiset:添加链接描述
unorderd_multimap: 添加链接描述
模拟
结构
底层采用bucket_hash,参考:数据结构----哈希(有修改:比如迭代器,仿函数等)
整体结构
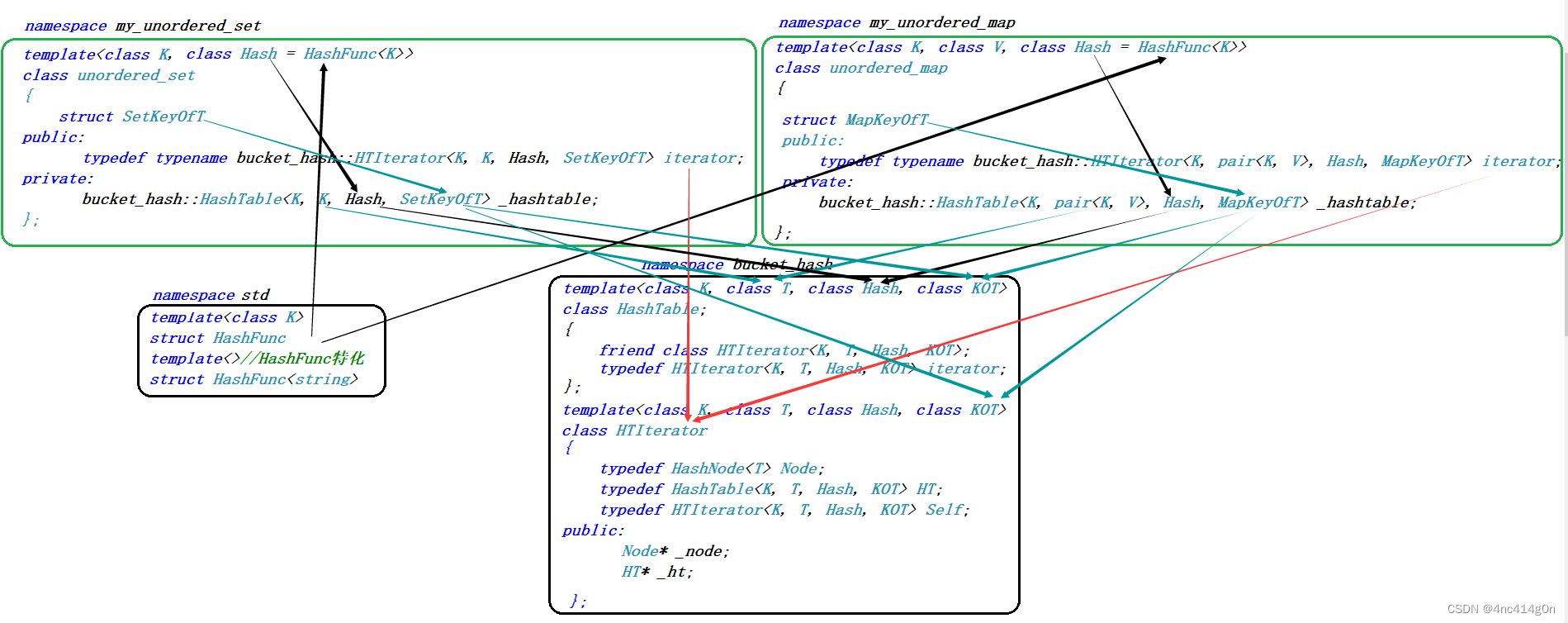
修改底层bucket_hash
对于HashNode:修改模板参数为template<class T>,T即pair<K, V>template<class T> struct HashNode { T _data; HashNode<T>* _next; HashNode(const T& data) :_data(data) ,_next(nullptr) {} };
增加一个HTIterator类:注意hashtable迭代器为单向迭代器 (双向迭代器会导致HashTable使用双链表,浪费空间)
注意:Iterator在STL sgi版中实现构造函数为__hashtable_iterator(node* n, hashtable* tab), 这里借鉴,意味着迭代器类里面要使用HashTable类的对象- 将operator++,!=等重载
设为public成员,方便调用- 对于class HashTable需要加上友元:
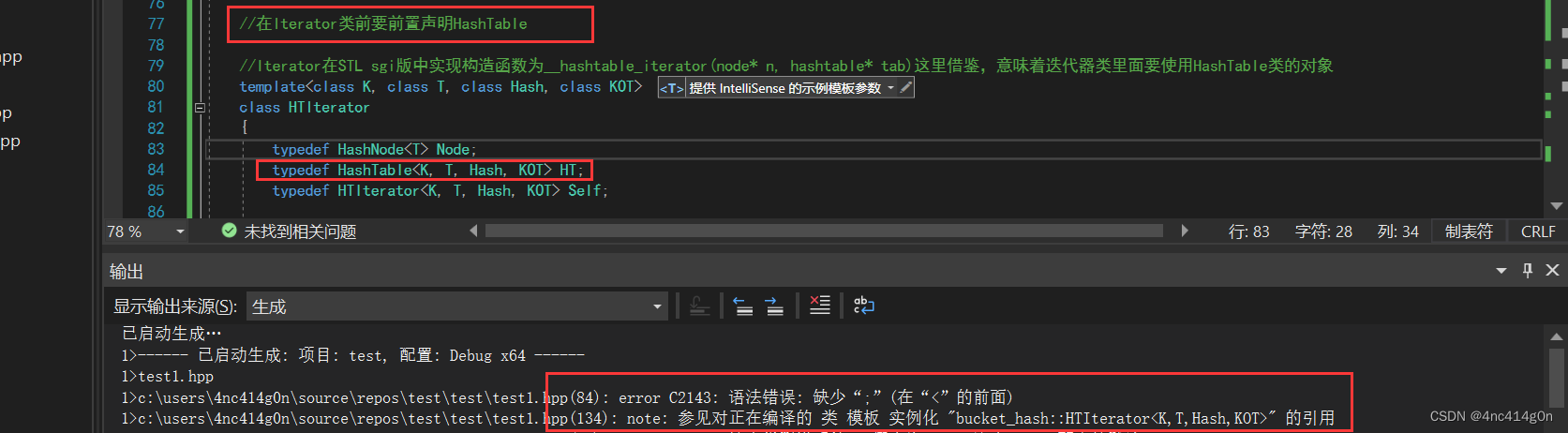
friend class HTIterator<K, T, Hash, KOT>;- 注意要在HTIterator类前面前置声明class HashTable,否则:
template<class K, class T, class Hash, class KOT> class HTIterator { typedef HashNode<T> Node; typedef HashTable<K, T, Hash, KOT> HT; typedef HTIterator<K, T, Hash, KOT> Self; public: Node* _node; HT* _ht; HTIterator(Node* node, HT* ht) :_node(node) ,_ht(ht) {} bool operator!=(const Self& s) const { return (_node != s._node); } T& operator*() { return _node->_data; } T* operator->() { return &_node->_data; } Self operator++()//注意:HashTable的迭代器是单向迭代器,只有++ { if (_node->_next)//链表迭代 { _node = _node->_next; } else//迭代桶 { Hash hash; KOT kot; size_t index = hash(kot(_node->_data)) % _ht->_tables.size(); index++; _node = nullptr;//防止走到_tables末尾仍无有效桶 while (index < _ht->_tables.size()) { if (_ht->_tables[index]) { _node = _ht->_tables[index]; break; } else { index++; } } } return *this; } };
对于class HashTable:修改模板参数V为T,T标识pair<K, V>
注意:在成员函数中:所有计算index的地方都要使用hash(kot(cur->_data))或hash(kot(key))统一进行转换为数字:hash是HashFunc kot是KeyOfT (对于MapKeyOfT是提取K,对于SetKeyOfT直接返回K)- 库里的insert返回值为pair<iterator, bool>,修改即可
template<class K, class T, class Hash, class KOT> class HashTable { typedef HashNode<T> Node; friend class HTIterator<K, T, Hash, KOT>; public: typedef HTIterator<K, T, Hash, KOT> iterator; iterator begin() { for (auto& e : _tables) { if (e) return iterator(e, this); } return iterator(nullptr, this); } iterator end() { return iterator(nullptr, this); } ~HashTable()//析构函数中处理每个桶的链表 { for (auto& e : _tables) { Node* cur = e; while (cur) { Node* next = cur->_next; delete cur; cur = next; } e = nullptr; } _n = 0; } bool Erase(const K& key) { if (_tables.size() == 0) return false; //注意这里不是双向链表不能借用Find() Hash hash; KOT kot; size_t index = hash(key) % _tables.size(); Node* prev = nullptr;//需要一个prev记录cur上一个位置,防止删除要删的时cur Node* cur = _tables[index]; while (cur) { if (kot(cur->_data) == key) { if (prev == nullptr) _tables[index] = cur->_next; else prev->_next = cur->_next; delete cur;//释放cur指针 _n--; return true; } else { prev = cur; cur = cur->_next; } } return false; } Node* Find(const K& key) { //防止除零错误 if (_tables.size() == 0) return nullptr; Hash hash; KOT kot; size_t index = hash(key) % _tables.size(); Node* cur = _tables[index]; while (cur) { if (kot(cur->_data) == key) return cur; else cur = cur->_next; } return nullptr; } pair<iterator, bool> Insert(const T& data) { //哈希桶控制负载因子负载因子为1时 进行扩容 //库里面的unordered_map::load_factor可以查看负载因子,unordered_map::max_load_factor查看最大负载因子 if (_tables.size()==0 || _n == _tables.size()) { //size_t newsize = (_tables.size() == 0) ? 10 : _tables.size() * 2; //unordered_map::bucket_count查看桶的数量 size_t newsize = Getnextprime(_tables.size());//使用除留余数法,最好模一个素数(没有明确规定,vs版本下就没有) vector<Node*> newtables(newsize, nullptr); for (auto& e : _tables) { Node* cur = e; while (cur) { Node* next = cur->_next;//下面要更改cur->_next这里记录一下 Hash hash; KOT kot; size_t index = hash(kot(cur->_data)) % newtables.size(); //头插 cur->_next = newtables[index]; newtables[index] = cur; cur = next; } e = nullptr;//注意,原来的_tables处e仍指向原来指针,应置空 } newtables.swap(_tables);//现代写法 } //插入逻辑 Hash hash; KOT kot; size_t index = hash(kot(data)) % _tables.size(); Node* cur = _tables[index]; while (cur) { if (kot((cur->_data)) == kot(data)) return make_pair(iterator(cur,this),false); else { cur = cur->_next; } } //采用头插更方便(尾插也可以) Node* newnode = new Node(data); newnode->_next = _tables[index]; _tables[index] = newnode; _n++; return make_pair(iterator(_tables[index],this),true); } private: vector<Node*> _tables; size_t _n;//存储的有效数据 };
my_unordered_map
对于unordered_map类:KOT的原型:MapKeyOfT仿函数
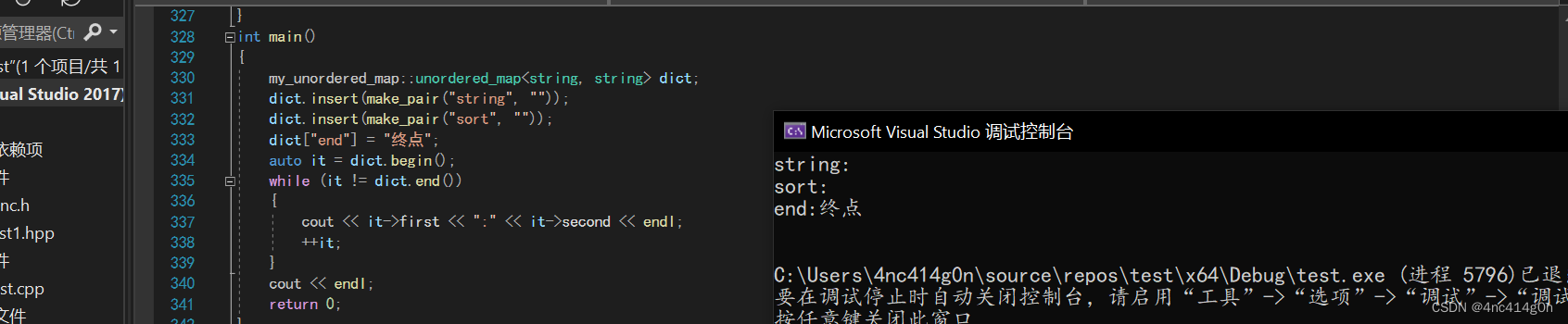
template<class K, class V, class Hash = HashFunc<K>> class unordered_map { //参考Map和Set的MapKeyOfT struct MapKeyOfT { //pair里的K都加了const const K& operator()(const pair<K, V>& kv) const { return kv.first; } }; private: bucket_hash::HashTable<K, pair<K, V>, Hash, MapKeyOfT> _hashtable; };成员函数end(),begin(),insert等直接复用HashTable中的即可
- 加上
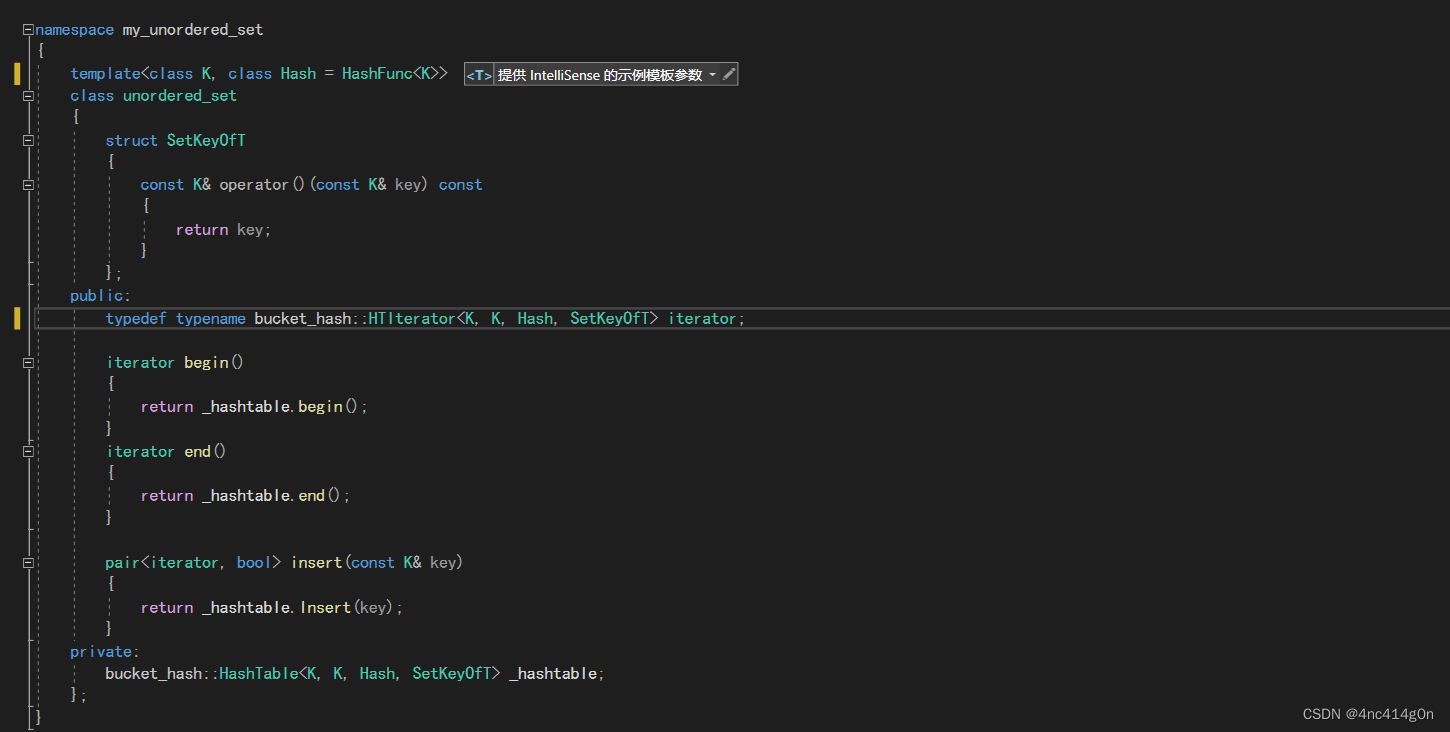
typedef typename bucket_hash::HTIterator<K, K, Hash, SetKeyOfT> iterator;
注意:C++语言默认情况下,假定通过作用域运算符访问的名字不是类型,所以当我们要访问的是类型时候,必须显示的告诉编译器这是一个类型,通过关键字typename来实现这一点- 这里省略了一些:
typedef typename bucket_hash::HTIterator<K, K, Hash, SetKeyOfT> iterator; iterator begin() { return _hashtable.begin(); } iterator end() { return _hashtable.end(); } V& operator[](const K& key) { pair<iterator, bool> ret = insert(make_pair(key, V())); return ret.first->second; } pair<iterator, bool> insert(const pair<K, V>& kv) { return _hashtable.Insert(kv); }测试:
my_unordered_set
unordered_set同理:
注意
bucket_hasn中的链表超过8个改用红黑树存储(红黑树用于处理极端情况)