【知识图谱】Louvain、LPA等5类经典社区发现算法 Python 实战
一、社区发现概述
根据图论,加权网络表示为𝐺=(𝑉,𝐸,𝑊),未加权网络表示为𝐺=(𝑉,𝐸),其中𝑉和𝐸表示节点和边的集合,𝑊分别表示𝐸相应的权重,以连接的强度或容量为单位。在未加权的网络中,𝑊被视为1。子图𝑔⊆𝐺是保留原始网络结构的图划分。子图的划分遵循预定义(pre-define)的规则,不同的规则可能会导致不同形式的子图。
社区是代表真实社会现象的一种子图。换句话说,社区是一组具有共同特征的人或对象。
社区是网络中节点密集连接的子图,稀疏连接的节点沟通了不同的社区,使用𝐶={𝐶1,𝐶2,⋯,𝐶𝑘}表示将网络𝐺划分为𝑘个社区的集合,其中𝐶𝑖是社区划分的第𝑖个社区。
节点𝑣属于社区𝐶𝑖满足如下条件:社区内部每个节点的内部度大于其外部度。
因此,社区发现的目标是发现网络𝐺中的社区𝐶。
技术交流
目前开通了技术交流,群友已超过3000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友,资料、代码获取也可以加入
方式1、添加微信号:dkl88191,备注:来自CSDN
方式2、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
二、KL社区发现算法
K-L(Kernighan-Lin)算法是一种将已知网络划分为已知大小的两个社区的二分方法,它是一种贪婪算法,它的主要思想是为网络划分定义了一个函数增益Q,Q表示的是社区内部的边数与社区之间的边数之差,根据这个方法找出使增益函数Q的值成为最大值的划分社区的方法。
1、实现策略
该算法的具体策略是,将社区结构中的结点移动到其他的社区结构中或者交换不同社区结构中的结点。从初始解开始搜索,直到从当前的解出发找不到更优的候选解,然后停止。
首先将整个网络的节点随机的或根据网络的现有信息分为两个部分,在两个社团之间考虑所有可能的节点对,试探交换每对节点并计算交换前后的ΔQ,ΔQ=Q交换后-Q交换前,记录ΔQ最大的交换节点对,并将这两个节点互换,记录此时的Q值。
规定每个节点只能交换一次,重复这个过程直至网络中的所有节点都被交换一次为止。需要注意的是不能在Q值发生下降时就停止,因为Q值不是单调增加的,既使某一步交换会使Q值有所下降,但其后的一步交换可能会出现一个更大的Q值。在所有的节点都交换过之后,对应Q值最大的社团结构即被认为是该网络的理想社团结构。

地址:http://eda.ee.ucla.edu/EE201A-04Spring/kl.pdf
2、代码实现:
>>> def draw_spring(G, com):
... pos = nx.spring_layout(G) # 节点的布局为spring型
... NodeId = list(G.nodes())
... node_size = [G.degree(i) ** 1.2 * 90 for i in NodeId] # 节点大小
... plt.figure(figsize=(8, 6)) # 图片大小
... nx.draw(G, pos, with_labels=True, node_size=node_size, node_color='w', node_shape='.')
... color_list = ['pink', 'orange', 'r', 'g', 'b', 'y', 'm', 'gray', 'black', 'c', 'brown']
... for i in range(len(com)):
... nx.draw_networkx_nodes(G, pos, nodelist=com[i], node_color=color_list[i])
... plt.show()
...
>>> import networkx as nx
>>> import matplotlib.pyplot as plt
>>> G = nx.karate_club_graph()
>>> com = list(kernighan_lin_bisection(G))
>>> import matplotlib.pyplot as plt
>>> from networkx.algorithms.community import kernighan_lin_bisection
>>> com = list(kernighan_lin_bisection(G))
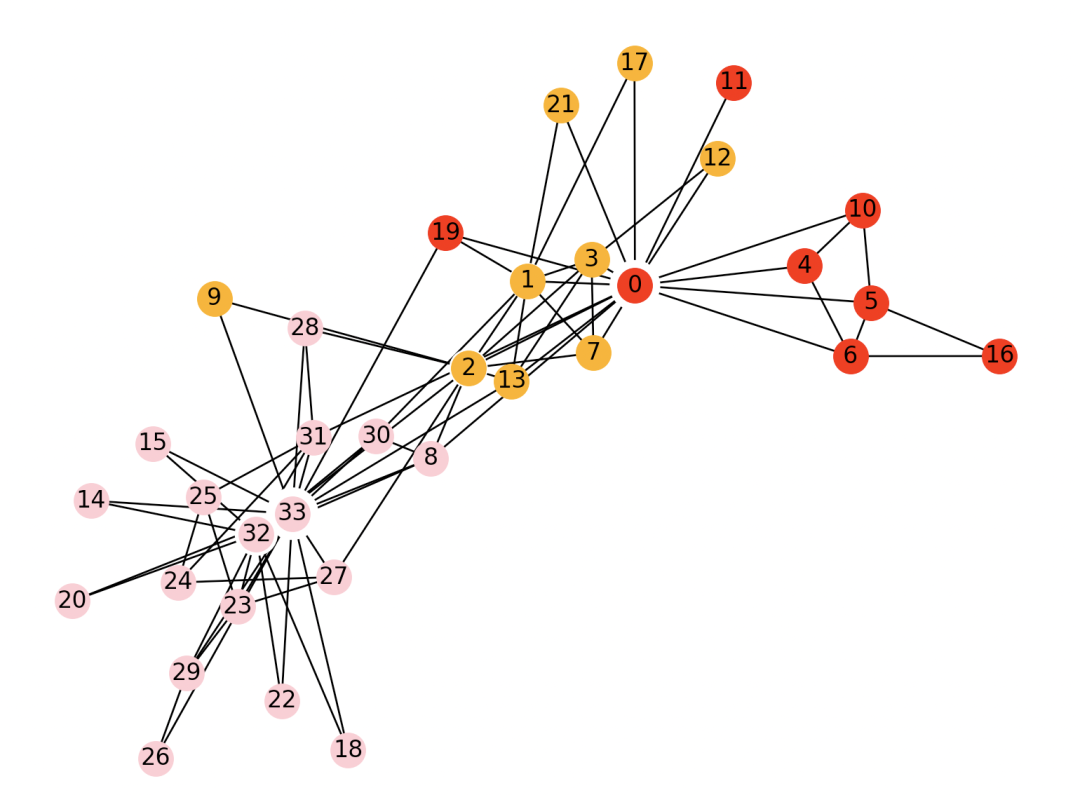
>>> print('社区数量', len(com))
社区数量 2
>>> draw_spring(G, com)
效果: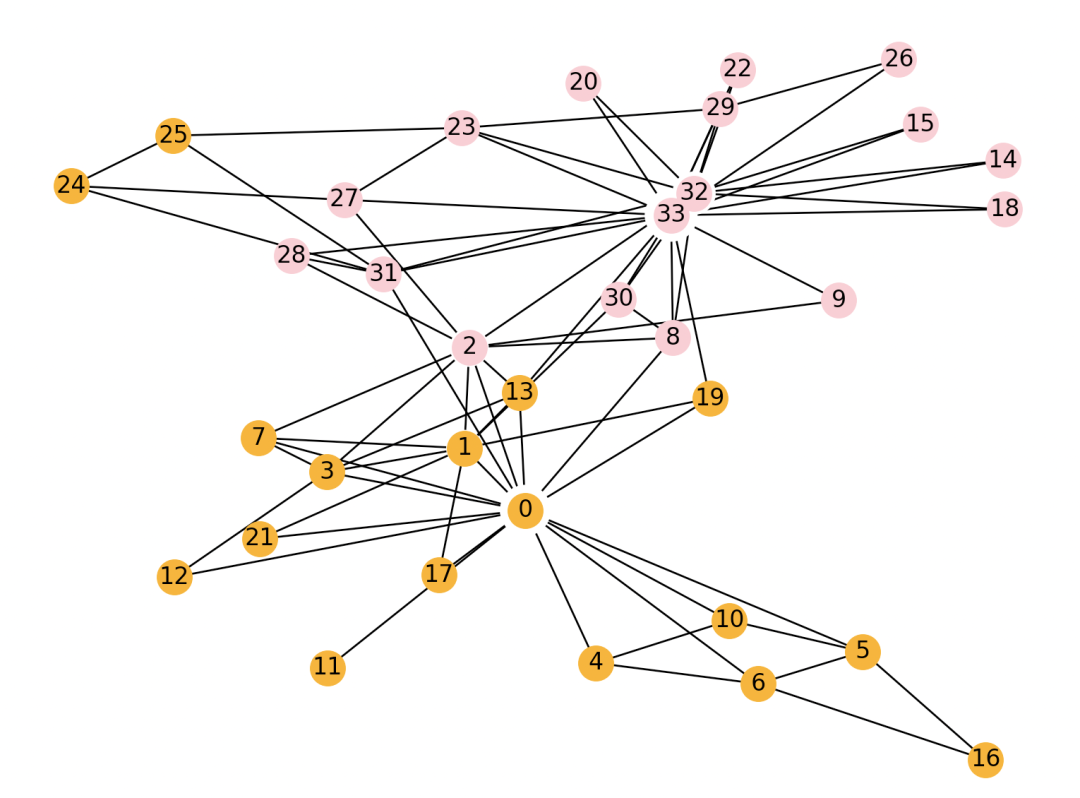
三、Louvain社区发现算法
Louvain算法是一种基于模块度的社区发现算法,其基本思想是网络中节点尝试遍历所有邻居的社区标签,并选择最大化模块度增量的社区标签,在最大化模块度之后,每个社区看成一个新的节点,重复直到模块度不再增大。
 地址:https://arxiv.org/pdf/0803.0476.pdf
地址:https://arxiv.org/pdf/0803.0476.pdf
1、实现策略
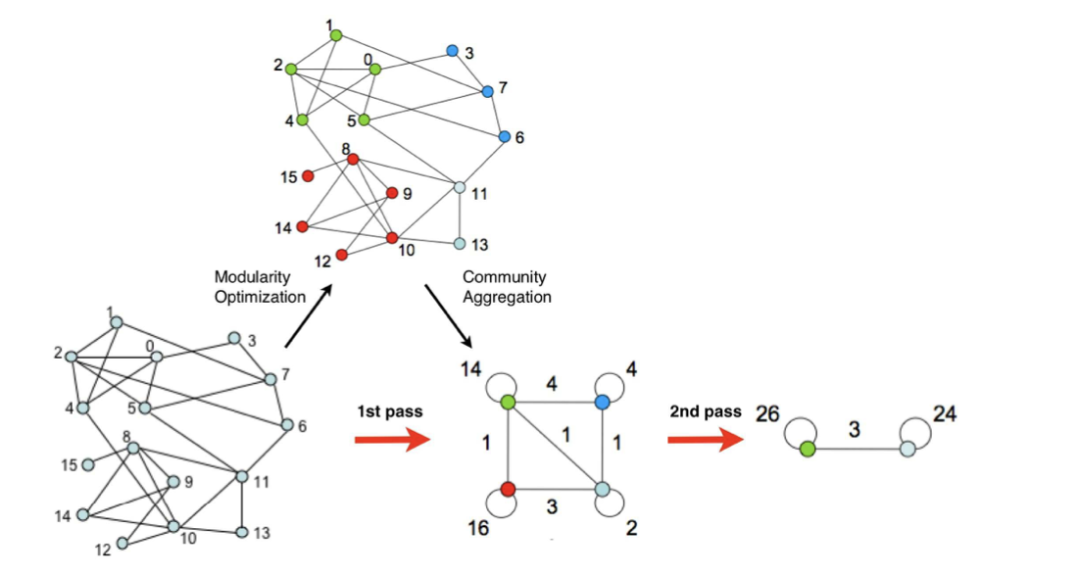
具体实现上,如下图所示,步骤如下:
1)初始时将每个顶点当作一个社区,社区个数与顶点个数相同。
2)依次将每个顶点与之相邻顶点合并在一起,计算它们最大的模块度增益是否大于0,如果大于0,就将该结点放入模块度增量最大的相邻结点所在社区。
其中,模块度用来衡量一个社区的质量,公式第一如下。
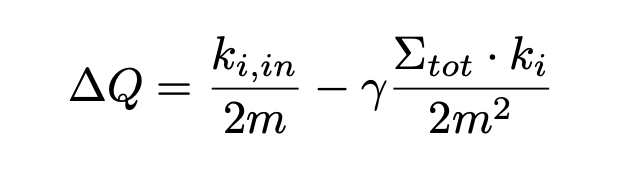
3)迭代第二步,直至算法稳定,即所有顶点所属社区不再变化。
4)将各个社区所有节点压缩成为一个结点,社区内点的权重转化为新结点环的权重,社区间权重转化为新****结点边的权重。
5)重复步骤1-3,直至算法稳定。
2、代码实现:
>>> import networkx as nx
>>> import matplotlib.pyplot as plt
>>> G = nx.karate_club_graph()
>>> com = list(kernighan_lin_bisection(G))
>>> import matplotlib.pyplot as plt
>>> from networkx.algorithms.community import louvain_communities
>>> com = list(louvain_communities(G))
>>> print('社区数量', len(com))
社区数量 4
>>> draw_spring(G, com)
3、效果:
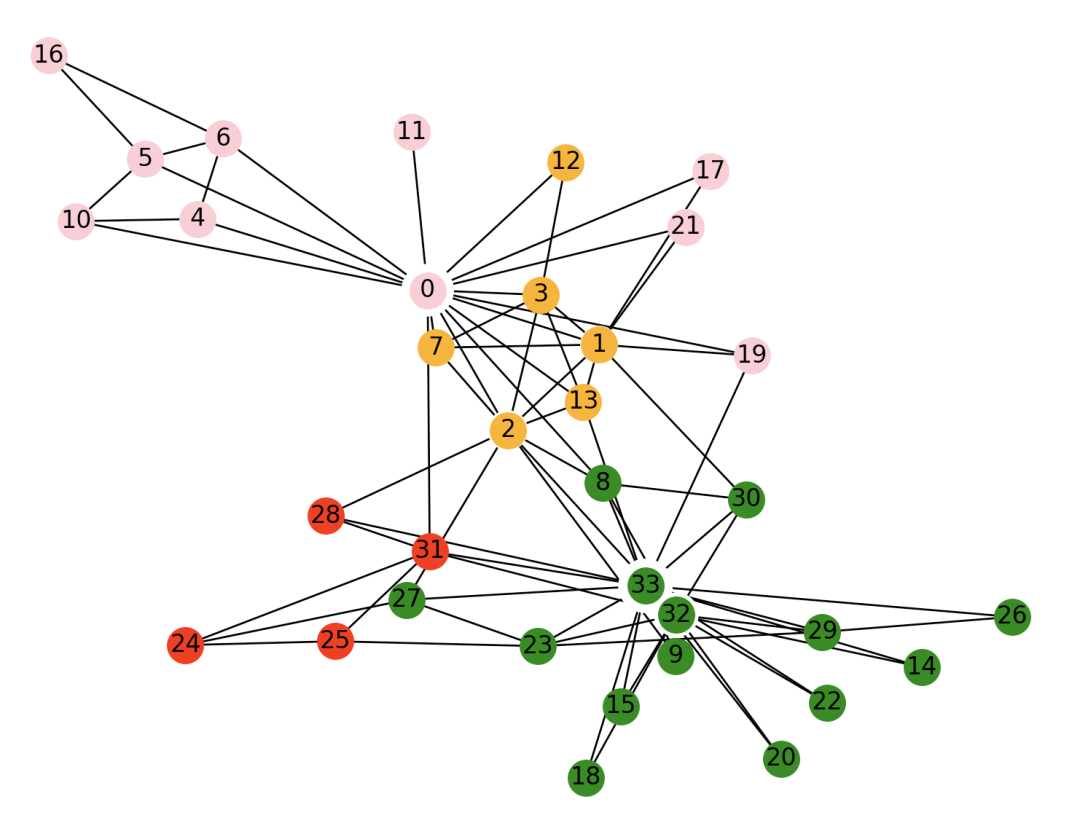
四、标签传播社区发现算法
LPA全称label propagation algorithm,即标签传递算法,是一种图聚类算法,常用在社交网络中,用于发现潜在的社区,是一种基于标签传播的局部社区划分。对于网络中的每一个节点,在初始阶段,Label Propagation算法对于每一个节点都会初始化一个唯一的一个标签。
每一次迭代都会根据与自己相连的节点所属的标签改变自己的标签,更改的原则是选择与其相连的节点中所属标签最多的社区标签为自己的社区标签,这就是标签传播的含义,随着社区标签不断传播。最终,连接紧密的节点将有共同的标签
1、实现策略
LPA认为每个结点的标签应该和其大多数邻居的标签相同,将一个节点的邻居节点的标签中数量最多的标签作为该节点自身的标签(bagging思想)。给每个节点添加标签(label)以代表它所属的社区,并通过标签的“传播”形成同一个“社区”内部拥有同一个“标签”。
标签传播算法(LPA)的做法如下:
第一步: 为所有节点指定一个唯一的标签;
第二步: 逐轮刷新所有节点的标签,直到达到收敛要求为止。对于每一轮刷新,节点标签刷新的规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一 时,随机选一个。
2、代码实现:
>>> import networkx as nx
>>> import matplotlib.pyplot as plt
>>> G = nx.karate_club_graph()
>>> com = list(kernighan_lin_bisection(G))
>>> import matplotlib.pyplot as plt
>>> from networkx.algorithms.community import label_propagation_communities
>>> com = list(label_propagation_communities(G))
>>> print('社区数量', len(com))
社区数量 3
>>> draw_spring(G, com)
3、效果
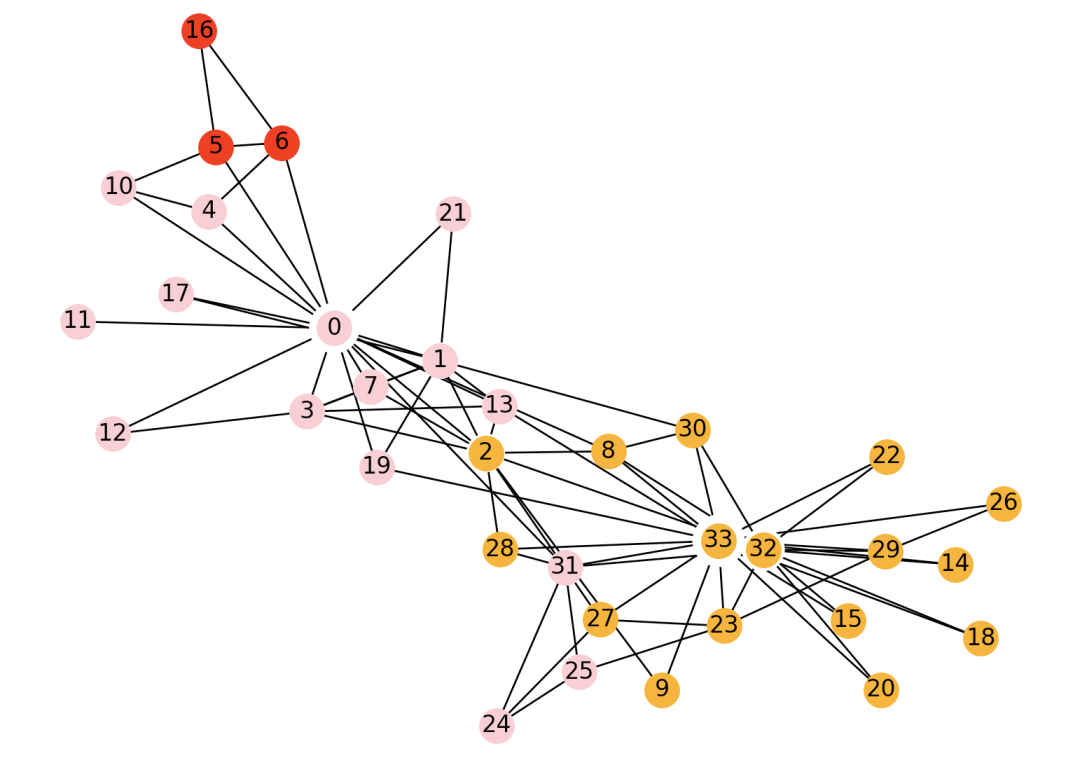
五、greedy_modularity社区算法
1、实现策略
贪心模块度社区算法,是一种用于检测社区结构的分层聚集算法,它在具有n个顶点和m条边的网络上的运行时间是O(mdlogn),其中d是描述社区结构的树状图的深度。

地址:https://arxiv.org/pdf/cond-mat/0408187v2.pdf
2、代码实现:
>>> import networkx as nx
>>> import matplotlib.pyplot as plt
>>> G = nx.karate_club_graph()
>>> com = list(kernighan_lin_bisection(G))
>>> import matplotlib.pyplot as plt
>>> from networkx.algorithms.community import greedy_modularity_communities
>>> com = list(greedy_modularity_communities(G))
>>> print('社区数量', len(com))
社区数量 3
>>> draw_spring(G, com)
3、效果:
参考文献
1、https://icode9.com/content-1-1321350.html
2、https://blog.csdn.net/qq_16543881/article/details/122825957
3、https://blog.csdn.net/qq_16543881/article/details/122781642