分库分表二:ShardingJDBC进阶实战案例上
文章目录
- ShardingJDBC进阶实战上
- 案例三:Hint分片策略实现sql零入侵
- 案例四:复合分片策略实现多分片键
- 案例五:广播表
ShardingJDBC进阶实战上
对于ShardingJDBC的环境搭建和入门案例请移步ShardingSphere介绍和入门实战
案例三:Hint分片策略实现sql零入侵
自定义Hint算法
//库的算法
public class MyDBHintSharding implements HintShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<Integer> shardingValue) {
//这里的值是通过 HintManager 传进来的 和sql无关
String logicTableName = shardingValue.getLogicTableName();
Collection<Integer> list = shardingValue.getValues();
List<String> dbNames = new ArrayList<>();
if (list.isEmpty()) throw new UnsupportedOperationException(" route db is null. please check your HintManager");
list.forEach(s->{
String dbName = "m"+s;
if (availableTargetNames.contains(dbName)) dbNames.add(dbName) ;
});
if (dbNames.isEmpty()) throw new UnsupportedOperationException(" route "+dbNames+" is not supported. please check your config");
return dbNames;
}
}
//表的算法
public class MyTableHintSharding implements HintShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<Integer> shardingValue) {
//这里的值是通过 HintManager 传进来的 和sql无关
String logicTableName = shardingValue.getLogicTableName();
Collection<Integer> list = shardingValue.getValues();
List<String> tableNames = new ArrayList<>();
if (list.isEmpty()) throw new UnsupportedOperationException(" route table is null. please check your HintManager");
list.forEach(s->{
String dbName = logicTableName+s;
if (availableTargetNames.contains(dbName)) tableNames.add(dbName) ;
});
if (tableNames.isEmpty()) throw new UnsupportedOperationException(" route "+tableNames+" is not supported. please check your config");
return tableNames;
}
}
yml配置
shardingsphere:
props:
# 开启sql打印
sql:
show: true
datasource:
# 配置逻辑库名
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/sharding_test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true
username: root
password: root
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxx/xmkf_zt?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true
username: xxx
password: xxx
sharding:
tables:
# 配置逻辑表名
sharding_user:
actual-data-nodes:
# 逻辑库逻辑表对应真实库、表的关系
m$->{1..2}.sharding_user$->{1..2}
# 配置主键生成策略
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
# 分库策略
database-strategy:
hint:
# 分片算法
algorithm-class-name: org.springblade.common.shardingJDBC.MyDBHintSharding
# 分表策略
table-strategy:
hint:
# 分片算法
algorithm-class-name: org.springblade.common.shardingJDBC.MyTableHintSharding
插入操作中指定库和表,而不在通过分片键和sql来分库分表
@GetMapping("/shardingTest")
@ApiOperation(value = "测试分库分表")
@ApiOperationSupport(order = 9, author = "lsx")
public R shardingTest(String name,Integer age){
HintManager instance = HintManager.getInstance();
//根据业务需求指定存到哪个库
instance.addDatabaseShardingValue("sharding_user",1);
//根据业务需求指定存到哪个表
instance.addTableShardingValue("sharding_user",1);
//通过HintManager 的配置 以下数据都保存到 m1的sharding_user1 当中
List<ShardingUser> list = new ArrayList<>();
for (int i = 0;i<100;i++){
ShardingUser user = new ShardingUser();
user.setUserName(name+i);
user.setAge(i);
list.add(user);
}
try {
shardingUserService.saveBatch(list);
}catch (Exception e){
e.printStackTrace();
}finally {
//线程安全,所有用完要注意关闭。
instance.close();
}
return R.success("成功");
}
Hint分片策略的特点在于 人为指定库和表,而不是通过sql去判断。难点在于如何动态的根据业务需求动态的指定库和表。
查询也是一样,跟sql没有关系,而是通过HintManager 进行配置。这样的好处是解放了sql的限制,可以在查询的时候写复杂的sql。
案例四:复合分片策略实现多分片键
在实际生产中,我们通常根据id作为分片键,但是往往在查询的时候会根据时间来查,比如订单,某个时间段,或者根据某个时间段进行统计订单的数量,这种情况如果只用id作为分片键,就会导致全表全库扫描。
比如有这样一个需求:根据季度来区分订单,查询的时候大概率也是按照季度来查询订单。对于这种需求我们可以根据订单时间和id作为复合的分片键。
例如,第一季度(1-3月)和第二季度(4-6月)放到m1的数据库中,第三季度(7-9月)和第四季度(10-12月)放到m2的数据库中。然后每个库根据id的奇偶数分配到表1和表2中。
那么接下来就实现这个功能。
功能实现
自定义分库算法
public class MyDbComplexSharding implements ComplexKeysShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
Map<String, Collection> keyMap = shardingValue.getColumnNameAndShardingValuesMap();
Map<String, Range> rangeMap = shardingValue.getColumnNameAndRangeValuesMap();
//精确匹配
Collection collection = keyMap.get("create_time");
if (!CollectionUtil.isEmpty(collection)){
List<Date> list = new ArrayList<>(collection);
//解析月份 确定库
int i = parseMonth(list.get(0));
if(i != 0){
return Arrays.asList("m"+i);
}
}
//范围匹配
if (CollectionUtil.isEmpty(rangeMap)) return availableTargetNames;
String lower = "";
String upper = "";
SimpleDateFormat sim=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Set<String> set =new HashSet<>();
try {
if (rangeMap.get("create_time") != null){
lower = rangeMap.get("create_time").lowerEndpoint().toString();
Date lowerDate = sim.parse(lower);
//解析月份 确定库
int i = parseMonth(lowerDate);
set.add("m"+i);
}
if (rangeMap.get("create_time") != null){
upper = rangeMap.get("create_time").upperEndpoint().toString();
Date upperDate = sim.parse(upper);
int i = parseMonth(upperDate);
set.add("m"+i);
}
return set;
}catch (Exception e){
e.printStackTrace();
return availableTargetNames;
}
}
private int parseMonth(Date date){
Calendar c = Calendar.getInstance();
c.setTime(date);
int month = c.get(Calendar.MONTH) + 1;
if (month>=1 && month<=6){
return 1;
}else if (month>=7 && month<=12){
return 2;
}
return 0;
}
}
自定义分表算法
public class MyTableComplexSharding implements ComplexKeysShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
Map<String, Collection> keyMap = shardingValue.getColumnNameAndShardingValuesMap();
Map<String, Range> rangeMap = shardingValue.getColumnNameAndRangeValuesMap();
Collection collection = keyMap.get("id");
if (!CollectionUtil.isEmpty(collection)){
String id = collection.iterator().next()+"";
char lastIndex = id.charAt(id.length() - 1);
//根据id奇偶数 确定表
int a = Integer.valueOf(lastIndex) % 2 + 1;
String logicTableName = shardingValue.getLogicTableName();
return Arrays.asList(logicTableName + a);
}
//id不存在范围查询 所以没有做范围的判断
return availableTargetNames;
}
}
yml配置
shardingsphere:
props:
# 开启sql打印
sql:
show: true
datasource:
# 配置逻辑库名
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/sharding_test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true
username: root
password: root
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxx/xmkf_zt?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true
username: xxx
password: xxx
sharding:
tables:
# 配置逻辑表名
sharding_user:
actual-data-nodes:
# 逻辑库逻辑表对应真实库、表的关系
m$->{1..2}.sharding_user$->{1..2}
# 配置主键生成策略
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
# 分库策略
database-strategy:
complex:
# 分片键
sharding-columns: id,create_time
# 分片算法
algorithm-class-name: org.springblade.common.shardingJDBC.MyDbComplexSharding
table-strategy:
complex:
# 分片键
sharding-columns: id,create_time
# 分片算法
algorithm-class-name: org.springblade.common.shardingJDBC.MyTableComplexSharding
测试插入
@GetMapping("/shardingTest")
@ApiOperation(value = "测试分库分表")
@ApiOperationSupport(order = 9, author = "lsx")
public R shardingTest(String name, Integer age) {
List<ShardingUser> list = new ArrayList<>();
for (int i = 0; i < 100; i++) {
ShardingUser user = new ShardingUser();
user.setUserName(name + i);
user.setAge(i);
Calendar c = Calendar.getInstance();
c.set(2022,new Random().nextInt(12),new Random().nextInt(29));
user.setCreateTime(c.getTime());
list.add(user);
}
shardingUserService.saveBatch(list);
return R.success("成功");
}
m1库表1的数据
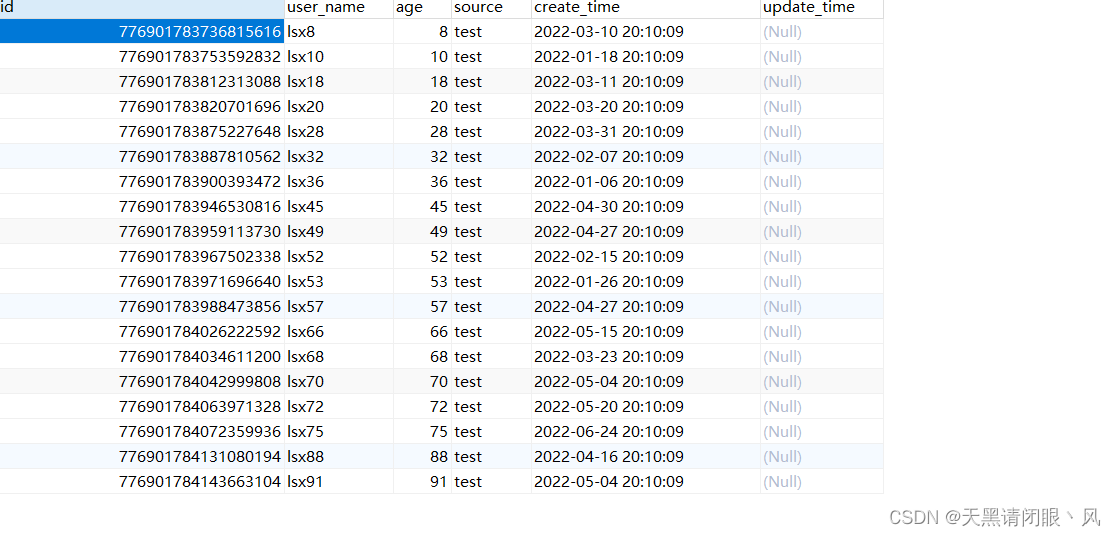
月份都是6月以下,id都是偶数。其他不展示了
测试查询
//根据id查询
@GetMapping("/shardingQuery")
@ApiOperation(value = "测试分库分表查询")
@ApiOperationSupport(order = 10, author = "lsx")
public R shardingQuery(String id) {
ShardingUser one = shardingUserService.getById(Long.valueOf(id));
return R.data(one);
}

通过id可以判断出是表一还是表2,但是无法判断出那个库,所以实际执行的sql 两个库都查了,但是只查了表1
范围查询
@GetMapping("/shardingQuery")
@ApiOperation(value = "测试分库分表查询")
@ApiOperationSupport(order = 10, author = "lsx")
public R shardingQuery(String id) {
QueryWrapper<ShardingUser> query = new QueryWrapper<>();
query.between("create_time", "2022-01-21 19:30:47", "2022-05-26 19:30:47");
List<ShardingUser> list = shardingUserService.list(query);
return R.data(list);
}

根据时间可以确定了要查哪些库,但是没法确定查哪些表,所以根据时间范围都是6月份以内,所以查1库,由于没法确定id奇偶数所以表1表2都查
虽然到此功能实现了,但是还有一些瑕疵,比如根据id查询的时候如何确定查询那个库而不是全部都查,其实这个可以把时间添加到id上面去,这需要自定义主键生成策略,这个后面在优化。
案例五:广播表
广播表定义是所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中都完全一致。例如字典表。
在两个数据库创建字典表作为广播表
CREATE TABLE `sharding_dict` (
`id` bigint(20) NOT NULL,
`dict_key` varchar(255) DEFAULT NULL,
`dict_value` varchar(255) DEFAULT NULL,
`source` varchar(255) DEFAULT 'zt',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
同样每个库分为表1和表2

实体类
@Data
@TableName("sharding_dict")
public class ShardingDict {
@TableId(type = IdType.NONE)
private Long id;
private String dictKey;
private String dictValue;
private String source;
}
yml
shardingsphere:
props:
# 开启sql打印
sql:
show: true
datasource:
# 配置逻辑库名
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/sharding_test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true
username: root
password: root
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxx/xmkf_zt?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true
username: xxx
password: xxx
sharding:
# 分库分表配置
tables:
sharding_dict:
actual-data-nodes:
# 逻辑库逻辑表对应真实库、表的关系
m$->{1..2}.sharding_dict$->{1..2}
# 配置主键生成策略
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
# 分库策略
database-strategy:
inline:
# 分片键
sharding-column: id
# 分片算法
algorithm-expression: m$->{id%2+1}
# 分表策略
table-strategy:
inline:
# 分片键
sharding-column: id
# 分片算法
algorithm-expression: sharding_dict$->{(id%4).intdiv(2)+1}
# 配置广播表
broadcast-tables: sharding_dict
测试
@GetMapping("/shardingRadio")
@ApiOperation(value = "测试广播表")
@ApiOperationSupport(order = 11, author = "lsx")
public R shardingRadio() {
List<ShardingDict> list = new ArrayList<>();
for (int i = 0; i < 20; i++) {
ShardingDict dict = new ShardingDict();
dict.setDictKey("aaa"+i);
dict.setDictValue(i+"");
list.add(dict);
}
dictService.saveBatch(list);
return R.success("成功");
}


有打印的sql可以看出虽然我们配置了分表,但是实际上两个数据都有插入,并且插入的都是广播表而不是具体的分表。
也就是说
如果配置了sharding_dict作为广播表,那么sharding_dict1和sharding_dict2都不会插入数据,而m1和m2的数据库会插入数据到sharding_dict并且数据是一样的。