新授粉方式的花授粉算法-附代码
新授粉方式的花授粉算法
文章目录
- 新授粉方式的花授粉算法
- 1.花授粉算法
- 2. 改进花授粉算法
- 2.1 自适应调整的转换概率 p
- 2. 2 带惯性权重的新全局授粉方式
- 2.3 融入精英与信息共享机制的新局部授粉方式
- 2.4 基于变异的改进策略
- 3.实验结果
- 4.参考文献
- 5.Matlab代码
- 6.Python代码
摘要:为了解决因花授粉算法搜索方程存在的不足所导致的易早熟、后期收敛速度慢和寻优精度低的问题,提出了一种新授粉方式的花授粉算法(Flower Pollination Algorithm with New pollination Methods,NMFPA)。该算法把惯性权重和两组随机个体差异矢量融入到全局搜索,组成新的全局授粉,以保持种群的差异性,提高算法的全局探索能力;利用信息共享机制与两种新的变异策略构建新局部授粉策略,增强算法的局部开发能力;为了减少个体进化的盲目性,提高算法的收敛速度和精度,采用基于高斯变异的最优个体来引导其他种群个体的进化方向,并且引入非均匀变异机制增加种群的多样性,避免算法易陷入局部极值点,提升算法的全局优化性能。
1.花授粉算法
基础花授粉算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/108346554
2. 改进花授粉算法
2.1 自适应调整的转换概率 p
参数 p 对FPA性能的影响较大,且其取值依赖于求解问题。同时,依据FPA算法的仿生原理可知,若算法中的参数 p 在优化过程中取固定的值,如果 p 取值较大,算法侧重于全局搜索,导致算法收敛速度慢,如果 p 取值较小,算法容易陷入局部极值,甚至找不到最优值,从而影响算法的全局优化能力。针对该问题,本文对 p 采用自适应调整策略,其计算公式为:
p
i
(
t
)
=
p
min
+
(
p
max
−
p
min
)
×
(
0.5
×
(
1
−
t
N
−
i
t
e
r
)
+
0.5
×
f
max
,
t
−
f
i
,
t
f
max
,
t
−
f
min
,
t
)
(1)
\begin{aligned} p_i(t)=& p_{\min }+\left(p_{\max }-p_{\min }\right) \times \left(0.5 \times\left(1-\frac{t}{N_{-} i t e r}\right)+0.5 \times \frac{f_{\max , t}-f_{i, t}}{f_{\max , t}-f_{\min , t}}\right) \end{aligned}\tag{1}
pi(t)=pmin+(pmax−pmin)×(0.5×(1−N−itert)+0.5×fmax,t−fmin,tfmax,t−fi,t)(1)
其中, 转换概率
p
p
p 的取值范围为
p
∈
[
0.2
,
0.9
]
,
f
min,
t
p \in[0.2,0.9], f_{\text {min, } t}
p∈[0.2,0.9],fmin, t 和
f
max
,
t
f_{\max , t}
fmax,t 分别为第
t
t
t 代种群中最小适应度值和最大适应度 值,
f
i
,
t
f_{i, t}
fi,t 为当前个体的适应度值,
N
−
N_{-}
N−iter 为最大迭代次 数,
t
t
t 为当前迭代次数,
p
min
p_{\min }
pmin 是参数
p
p
p 的最小值,
p
max
p_{\max }
pmax 是参数
p
p
p 的最大值。
从公式(1)可知:
(1)
p
p
p 的取值是动态自适应变化的, 且其取值同时 考虑了迭代次数和种群个体的适应度值的作用。
(2) 在进化初期,
p
p
p 的值较大, 算法侧重于全局搜 索, 扩大算法搜索范围, 使种群中的个体更靠近最优解, 随着演化的深入,
p
p
p 的值越来越小, 使算法倾向局部精 细化搜索, 有利于算法找到最优值。
2. 2 带惯性权重的新全局授粉方式
依据 FPA 算法的仿生原理,FPA 算法在全局授粉时,利用Lévy飞行和最优个体策略对种群中的个体同时施加影响,通过最优个体引导种群中的其他个体进行探索,有利于提高算法的性能,但在进化后期,由于最优个体对其他个体的吸引,使得种群个体具有强烈的趋同性,即减弱了种群个体的差异性。同时,智能算法中通常是利用最优个体策略提高算法的局部搜索能力 [22] ,采用Lévy飞行机制改善算法的全局搜索能力,而将两种策略融入到一起,势必引起相互抵触,影响算法的全局优化能力。另外,在FPA算法演化后期,由于种群个体的多样性快速丧失而使得FPA易陷入局部最优,影响了算法全局搜索能力。为了解决上述存在的问题,通过融入带惯性权重的思想对FPA算法的全局授粉方式进行改进,具体如下:
if rand
⩽
θ
\leqslant \theta
⩽θ
x
i
t
+
1
=
x
i
l
+
γ
L
(
λ
)
(
x
i
1
l
−
x
i
2
l
+
x
i
3
l
−
x
i
4
l
)
(
2
)
x_i^{t+1}=x_i^l+\gamma L(\lambda)\left(x_{i_1}^l-x_{i_2}^l+x_{i_3}^l-x_{i_4}^l\right)\quad(2)
xit+1=xil+γL(λ)(xi1l−xi2l+xi3l−xi4l)(2)
else
x i t + 1 = ω x i t + γ L ( λ ) ( x i 1 t − x i 2 t + x i 3 t − x i 4 t ) ( 3 ) x_i^{t+1}=\omega x_i^t+\gamma L(\lambda)\left(x_{i_1}^t-x_{i_2}^t+x_{i_3}^t-x_{i_4}^t\right)\quad(3) xit+1=ωxit+γL(λ)(xi1t−xi2t+xi3t−xi4t)(3)
endif
其中, rand
∈
[
0
,
1
]
\in[0,1]
∈[0,1] 是服从均匀分布的随机数;
i
,
i
1
,
i
2
i, i_1, i_2
i,i1,i2,
i
3
,
i
4
i_3, i_4
i3,i4 分别是从当前种群中随机选取的 5 个不同个体的 下标;
x
i
t
+
1
、
x
i
t
x_i^{t+1} 、 x_i^t
xit+1、xit 分别是第
t
+
1
t+1
t+1 代、第
t
t
t 代的解;
γ
\gamma
γ 是控制 步长的缩放因子;
L
L
L 是对应于花粉传播者的 Lévy 飞行 随机搜索步长;
λ
=
3
/
2
。
θ
\lambda=3 / 2 。 \theta
λ=3/2。θ 和
ω
\omega
ω 的计算公式分别为公 式(4)和公式(5):
θ
=
0.5
×
(
1
−
t
N
−
i
ter
)
+
0.5
×
f
max
,
t
−
f
i
,
t
f
max
,
t
−
f
min
,
t
(
4
)
ω
=
0.01
×
(
1
−
exp
(
−
t
N
−
iter
)
)
(
5
)
\begin{aligned} &\theta=0.5 \times\left(1-\frac{t}{N_{-} i \text { ter }}\right)+0.5 \times \frac{f_{\max , t}-f_{i, t}}{f_{\max , t}-f_{\min , t}} &(4)\\ &\omega=0.01 \times\left(1-\exp \left(-\frac{t}{N_{-} \text {iter }}\right)\right)&(5) \end{aligned}
θ=0.5×(1−N−i ter t)+0.5×fmax,t−fmin,tfmax,t−fi,tω=0.01×(1−exp(−N−iter t))(4)(5)
其中,
f
max
,
t
f_{\max , t}
fmax,t 为第
t
t
t 代种群中最大适应度值,
f
i
,
t
f_{i, t}
fi,t 为当前 个体的适应度值,
N
−
N_{-}
N−iter 为最大迭代次数,
t
t
t 为当前迭 代次数。
从 NMFPA算法的设计思想可知, 算法的演化初期, 种群个体的差异性比较大, 算法的探测能力较强, 无需 对个体进行大幅度扰动, 而随着进化的不断深入, 个体 的多样性越来越小, 算法的勘探能力被削弱了, 影响了 算法的优化性能。依据上述公式 (5) 可知, 在算法的进 化初期, 变量
t
t
t 的值较小, 则惯性权重
ω
\omega
ω 的取值较小, 对 种群的扰动性较弱; 当算法进入演化后期, 变量
t
t
t 的值 越来越大, 惯性权重
ω
\omega
ω 的值越来越大, 对种群的扰动性 较强, 有利于增加种群的多样性, 以增强算法的全局优 化能力。公式(5) 中的系数
0.01
0.01
0.01, 是经过大量实验获得 的经验值。
带惯性权重的新全局授粉方式, 在保留 Lévy 飞行 机制的同时利用了两组随机个体的差异矢量, 增加了 算法的扰动性和算法在多维空间的探索能力。在进化 后期, 全局授粉部分采用带惯性权重的搜索机制, 增加 种群个体的多样性, 有效避免算法早熟, 提高算法优化 性能。
2.3 融入精英与信息共享机制的新局部授粉方式
从花授粉算法的局部搜索方程可知:
(1)产生的新个体是在个体的原状态基础上加上一 个扰动项,该扰动项是由一个均匀分布的随机数和两个 随机个体差分矢量的乘积。虽然随机产生的子代能够 较好地保持算法种群个体之间的差异性, 使算法能够维 持良好的持续优化能力,但也降低了算法的收敛速度。
(2)搜索策略没有充分利用种群信息, 使算法在进 化过程中种群个体之间的差异性过早地丢失, 不能较好 地解决“早熟”问题,影响了算法解的质量。
针对上述存在的问题,采用精英策略和信息共享机 制对标准 FPA算法的局部授粉方式进行改进, 新的变异 策略如下:
(1)
F
P
A
/
r
a
n
d
/
1
\mathrm{FPA} / \mathrm{rand} / 1
FPA/rand/1 变异策略:
v
i
,
t
=
x
r
1
+
δ
×
(
x
r
2
,
t
−
x
r
3
,
t
)
(6)
v_{i, t}=x_{r_1}+\delta \times\left(x_{r_2, t}-x_{r_3, t}\right) \tag{6}
vi,t=xr1+δ×(xr2,t−xr3,t)(6)
(2)
F
P
A
/
b
e
s
t
/
2
\mathrm{FPA} / \mathrm{best} / 2
FPA/best/2 变异策略:
v
i
,
t
=
x
best
,
t
+
α
×
(
x
r
1
,
t
−
x
r
2
,
t
)
+
β
×
(
x
r
3
,
t
−
x
r
4
,
t
)
(7)
v_{i, t}=x_{\text {best }, t}+\alpha \times\left(x_{r_1, t}-x_{r_2, t}\right)+\beta \times\left(x_{r_3, t}-x_{r_4, t}\right) \tag{7}
vi,t=xbest ,t+α×(xr1,t−xr2,t)+β×(xr3,t−xr4,t)(7)
其中,
i
∈
(
1
,
2
,
⋯
,
N
P
i \in\left(1,2, \cdots, N P\right.
i∈(1,2,⋯,NP (种群数)) 为当前个体的下标,
r
1
r_1
r1,
r
2
,
r
3
r_2, r_3
r2,r3 和
r
4
r_4
r4 为 4 个不同的随机个体的下标,
x
best
,
t
x_{\text {best }, t}
xbest ,t 为第
t
t
t 代种群中最优个体。
δ
,
α
,
β
\delta, \alpha, \beta
δ,α,β 是均值为
0.5
0.5
0.5 、标准偏差为
0.1
0.1
0.1 的高斯分布, 通过缩放因子
δ
、
α
\delta 、 \alpha
δ、α 和
β
\beta
β 对算法的进化 速度进行调节。
在新的局部搜索方法中, “FPA/rand/1”变异策略增 加了算法种群个体的差异性, 提高了算法优化能力, 但 算法的收敛速度在一定程度上降低了; “FPA/best/2” 变 异机制通过最优个体引导种群中其他个体的搜索方向,最优个体的有用信息有利于开发最优个体的搜索范围, 提高算法的寻优效率, 使其收敛速度与开发能力获得提 升,但也容易导致算法陷入局部最优。因此,为了使其 取长补短,更好提升算法的收敛能力,本文通过公式 (4) 的非线性递减概率规则来融合这两种变异策略。依据
θ
\theta
θ 的表达式可知, 在算法的进化初期, 算法偏重于全局 搜索; 在进化后期,侧重于局部搜索, 有利于提高算法的 寻优性能。
另外,在FPA算法中个体之间缺乏信自交流, 使其 容易陷入局部极值, 本文把信息共享机制融入到FPA 的 局部搜索中, 即利用公式 (8)来进行个体间的学习
[
23
]
{ }^{[23]}
[23], 从 而达到改善解的质量。
x
new
i
=
{
x
old
i
+
s
×
(
x
i
−
x
j
)
,
f
(
x
j
)
<
f
(
x
i
)
x
old
i
+
s
×
(
x
j
−
x
i
)
,
f
(
x
i
)
<
f
(
x
j
)
(8)
x_{\text {new }}^i=\left\{\begin{array}{l} x_{\text {old }}^i+s \times\left(x^i-x^j\right), f\left(x^j\right)<f\left(x^i\right) \\ x_{\text {old }}^i+s \times\left(x^j-x^i\right), f\left(x^i\right)<f\left(x^j\right) \end{array}\right.\tag{8}
xnew i={xold i+s×(xi−xj),f(xj)<f(xi)xold i+s×(xj−xi),f(xi)<f(xj)(8)
其中,
f
(
x
i
)
f\left(x^i\right)
f(xi) 和
f
(
x
j
)
f\left(x^j\right)
f(xj) 分别表示个体
x
i
x^i
xi 和
x
j
x^j
xj 的目标函数 适应度值,
s
=
s=
s= rand 为学习步长,
x
new
i
,
x
old
i
x_{\text {new }}^i, x_{\text {old }}^i
xnew i,xold i 分别是个体
i
i
i 的最新状态和原始状态。
基于上述思想, 构建 FPA具有信息共享机制的新局 部授粉方式:
通过公式 (8)实现个体之间的信息交流;
if rand
⩾
θ
\geqslant \theta
⩾θ then
依据公式 (7)执行变异, 产生新的个体;
else
依据公式 (6)执行变异, 产生新的个体;
endif
其中
θ
\theta
θ 的计算公式为公式(4)。
2.4 基于变异的改进策略
从 FPA 的构成可知, FPA 是依据参数
p
p
p 的值随机地 选取全局搜索或者局部搜索, 这容易导致产生的新个体 偏离全局最优解的方向, 影响 FPA 的收敛能力。为了解 决该问题, 本文在进入下一次迭代之前, 利用基于高斯 变异的最优个体对种群中的其他个体的进化方向进行 引导, 以达到提高算法的收敛性能。但是, 由于在上述 多个位置运用了最优个体策略, 增加了 FPA算法在收敛 后期容易陷入局部极值风险, 因此在个体进入下次演化 之前, 对个体进行非均匀变异, 因为非均匀变异是一种 能有效避免算法早熟的算子
[
24
]
{ }^{[24]}
[24] 。改进策略定义如下:
(1)基于高斯变异的最优个体改进策略:
x
i
new
=
x
best
+
k
×
N
(
0
,
1
)
x
best
(
9
)
k
=
1
−
t
/
N
−
iter
(
10
)
\begin{aligned} &x_i^{\text {new }}=x_{\text {best }}+k \times N(0,1) x_{\text {best }} &(9)\\ &k=1-t / N_{-} \text {iter }&(10) \end{aligned}
xinew =xbest +k×N(0,1)xbest k=1−t/N−iter (9)(10)
其中,
x
best
x_{\text {best }}
xbest 为当前种群中最优个体;
x
i
new
x_i^{\text {new }}
xinew 是第
i
i
i 个个体 的新状态;
t
t
t 为当前迭代次数,
N
−
i
N_{-} i
N−i ter 为最大迭代次数;
k
∈
(
1
,
0
]
k \in(1,0]
k∈(1,0] 为递减变量,
N
(
0
,
1
)
N(0,1)
N(0,1) 为高斯变异随机向量。
(2)非均匀变异。变异是种群个体能够持续进化的 关键操作,而非均匀变异是对原有个体进行不同幅度的变异而产生新的个体。定义如下:
x
i
new
=
{
x
i
old
+
Δ
(
t
,
U
b
−
x
i
old
)
,
r
<
0.5
x
i
old
−
Δ
(
t
,
x
i
old
−
L
b
)
,
r
⩾
0.5
(
11
)
Δ
(
t
,
y
)
=
y
(
1
−
r
(
1
−
t
/
N
−
iter
)
b
)
(
12
)
\begin{aligned} &x_i^{\text {new }}=\left\{\begin{array}{l} x_i^{\text {old }}+\Delta\left(t, U b-x_i^{\text {old }}\right), r<0.5 \\ x_i^{\text {old }}-\Delta\left(t, x_i^{\text {old }}-L b\right), r \geqslant 0.5 \end{array}\right. &(11)\\ &\Delta(t, y)=y\left(1-r^{\left(1-t / N_{-} \text {iter }\right)^b}\right)&(12) \end{aligned}
xinew ={xiold +Δ(t,Ub−xiold ),r<0.5xiold −Δ(t,xiold −Lb),r⩾0.5Δ(t,y)=y(1−r(1−t/N−iter )b)(11)(12)
其中,
t
t
t 是当前迭代次数,
U
b
U b
Ub 和
L
b
L b
Lb 是解的上界和下界,
r
r
r 是
[
0
,
1
]
[0,1]
[0,1] 之间的随机数,
b
b
b 是决定非均匀度的系统参 数,
N
−
i
N_{-} i
N−i ter 为最大迭代次数,
x
i
old
x_i^{\text {old }}
xiold 是第
i
i
i 个个体的原始 状态,
x
i
new
x_i^{\text {new }}
xinew 是第
i
i
i 个个体的新状态。
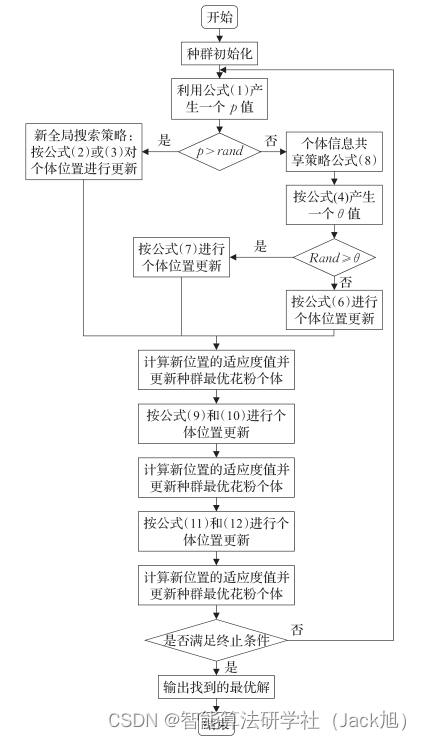
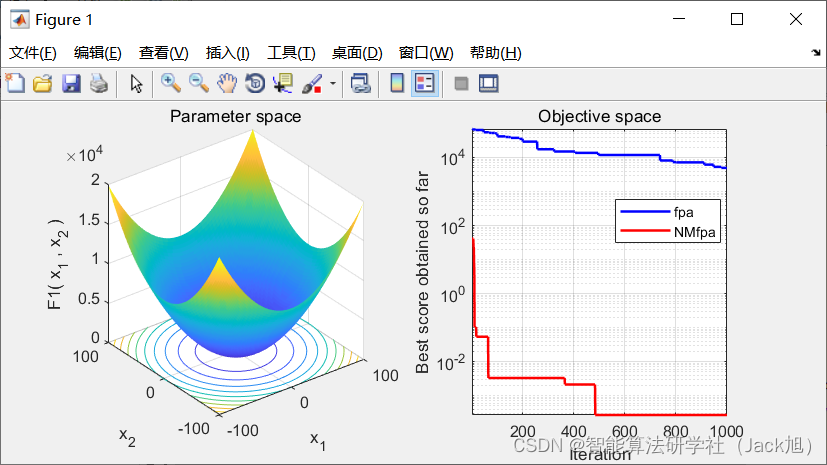
3.实验结果
4.参考文献
[1]段艳明,肖辉辉,林芳.新授粉方式的花授粉算法[J].计算机工程与应用,2018,54(23):94-108.