大数据技术之Hive+Flume+Zookeeper+Kafka详解
一、Hive大数据业务分析
1、Hive简介
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
Hive本质是将HQL转化成MapReduce程序。
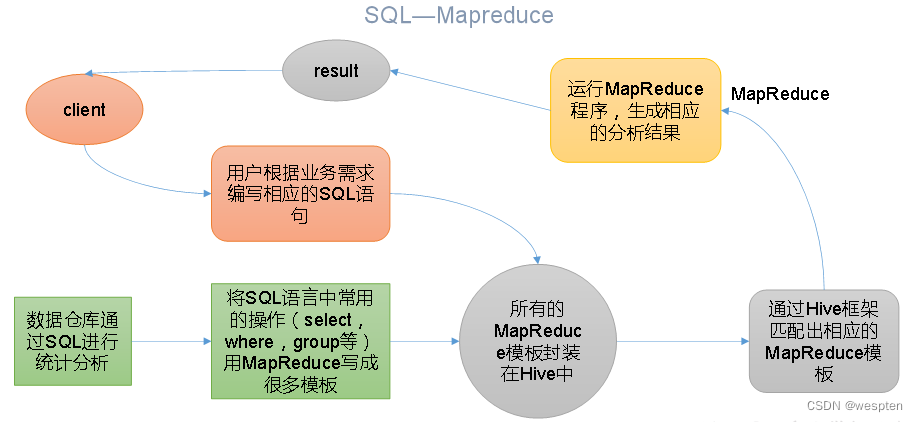
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
Hive的优缺点:
优点:
(1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写MapReduce,减少开发人员的学习成本。
(3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
(4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
(5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点:
1)Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
2)Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
2、Hive架构原理

1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3)Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4)驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。

Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
3、Hive的安装部署
Hive官网地址:Apache Hive
文档查看地址:GettingStarted - Apache Hive - Apache Software Foundation
下载地址:Index of /dist/hive
github地址:GitHub - apache/hive: Apache Hive
1. 下载并解压hive源程序
Hive下载地址:http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz
tar -zxvf hive-1.1.0-cdh5.15.1.tar.gz -C /opt/hive # 解压到/opt/hive中
cd /opt/hive
ln -s hive-1.1.0-cdh5.15.1 current
chown -R hadoop:hadoop hive-1.1.0-cdh5.15.1 # 修改目录文件权限
2. 配置环境变量
为了方便使用,我们把hive命令加入到环境变量中去,编辑~/.bashrc文件vim ~/.bashrc,在最后面一行添加:
export HIVE_HOME=/opt/hive/current
export PATH=$PATH:$HIVE_HOME/bin
保存退出后,运行source ~/.bashrc使配置立即生效。
解决日志Jar包冲突:
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak3. Hive配置文件hive-site.xml
新建一个文件hive-site.xml,并在hive-site.xml中粘贴如下配置信息:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hivepasswd</value>
</property>
</configuration>
由于使用的是mysql5.7版本,默认hive和数据库连接是走的ssl方式,因此这里需要加上“useSSL=false”关闭ssl连接,通过普通模式进行连接。
Hive的配置文件是XML格式,而在xml文件中&;才表示&,因此jdbc连接数据库的方式应该这么写:
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false4、安装并配置mysql
Hive默认使用的元数据库为derby,开启Hive之后就会占用元数据库,且不与其他客户端共享数据,如果想多窗口操作就会报错,操作比较局限。以我们需要将Hive的元数据地址改为MySQL,可支持多窗口操作。
1. centos下载并安装mysql
检查当前系统是否安装过Mysql:
[yyds@hadoop102 ~]$ rpm -qa|grep mariadb
mariadb-libs-5.5.56-2.el7.x86_64 //如果存在通过如下命令卸载
[yyds @hadoop102 ~]$ sudo rpm -e --nodeps mariadb-libs //用此命令卸载mariadb将MySQL安装包拷贝到/opt/software目录下:
[yyds @hadoop102 software]# ll
总用量 528384
-rw-r--r--. 1 root root 609556480 3月 21 15:41 mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar解压MySQL安装包:
[yyds @hadoop102 software]# tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
在安装目录下执行rpm安装:
[yyds @hadoop102 software]$ sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
[yyds @hadoop102 software]$ sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
[yyds @hadoop102 software]$ sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
[yyds @hadoop102 software]$ sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
[yyds @hadoop102 software]$ sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm注意:按照顺序依次执行。
如果Linux是最小化安装的,在安装mysql-community-server-5.7.28-1.el7.x86_64.rpm时可能会出 现如下错误:
[yyds@hadoop102 software]$ sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
警告:mysql-community-server-5.7.28-1.el7.x86_64.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY
错误:依赖检测失败:
libaio.so.1()(64bit) 被 mysql-community-server-5.7.28-1.el7.x86_64 需要
libaio.so.1(LIBAIO_0.1)(64bit) 被 mysql-community-server-5.7.28-1.el7.x86_64 需要
libaio.so.1(LIBAIO_0.4)(64bit) 被 mysql-community-server-5.7.28-1.el7.x86_64 需要通过yum安装缺少的依赖,然后重新安装mysql-community-server-5.7.28-1.el7.x86_64 即可:
[yyds@hadoop102 software] yum install -y libaio删除/etc/my.cnf文件中datadir指向的目录下的所有内容,如果有内容的情况下,查看datadir的值:
[mysqld]
datadir=/var/lib/mysql删除/var/lib/mysql目录下的所有内容:
[yyds @hadoop102 mysql]# cd /var/lib/mysql
[yyds @hadoop102 mysql]# sudo rm -rf ./* //注意执行命令的位置初始化数据库:
[yyds @hadoop102 opt]$ sudo mysqld --initialize --user=mysql查看临时生成的root用户的密码:
yyds @hadoop102 opt]$ cat /var/log/mysqld.log 
启动MySQL服务:
[yyds @hadoop102 opt]$ sudo systemctl start mysqld登录MySQL数据库:
[yyds @hadoop102 opt]$ mysql -uroot -p
Enter password: 输入临时生成的密码登录成功。
必须先修改root用户的密码,否则执行其他的操作会报错:
mysql> set password = password("新密码")修改mysql库下的user表中的root用户允许任意ip连接:
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;2. 下载mysql jdbc包
下载地址:MySQL :: Download Connector/J
将MySQL的JDBC驱动拷贝到Hive的lib目录下:
tar -zxvf mysql-connector-java-5.1.47.tar.gz #解压
cp mysql-connector-java-5.1.47/mysql-connector-java-5.1.47-bin.jar /opt/hive/lib #将mysql-connector-java-5.1.47-bin.jar //拷贝到/opt/hive/lib目录下目前有最新版本mysql-connector-java-8.0.12,但经过测试最新版本有些问题,因此推荐使用mysql-connector-java-5.1.47这个版本。
3. 启动并登陆mysql
systemctl start mysqld #启动mysql服务
mysql -u root –p #进入mysql命令行4. 配置hive连接mysql的用户
这里创建一个mysql用户,hive用此用户连接到mysql。创建mysql用户如下:
mysql> grant all on *.* to hive@localhost identified by 'hivepasswd'; #将所有数据库的所有表的所有权限赋给hive用户,这个用户和密码在hive-site.xml配置文件中会用到。
mysql> flush privileges; #刷新mysql系统权限关系表5. 配置Metastore到MySql
在$HIVE_HOME/conf目录下新建hive-site.xml文件:
vim $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- Hive元数据存储的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>5、启动hive命令行模式
1)初始化元数据库
登陆MySQL:
[yyds@hadoop102 software]$ mysql -uroot -p000000新建Hive元数据库:
mysql> create database metastore;
mysql> quit;初始化Hive元数据库:
[yyds@hadoop102 software]$ schematool -initSchema -dbType mysql -verbose2)启动Hive
启动Hive,先启动hadoop集群:
通过hive cli格式开始启动hive:
[yyds@cdh5node2 conf]# su - hadoop
[hadoop@cdh5node2 ~]$ hive #启动hive使用Hive:
hive> show databases;
hive> show tables;
hive> create table test (id int);
hive> insert into test values(1);
hive> select * from test;开启另一个窗口测试开启hive:
[yyds@hadoop102 hive]$ bin/hive3)使用元数据服务的方式访问Hive
在hive-site.xml文件中添加如下配置信息:
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>启动metastore:
[yyds@hadoop202 hive]$ hive --service metastore
2020-04-24 16:58:08: Starting Hive Metastore Server
注意: 启动后窗口不能再操作,需打开一个新的shell窗口做别的操作启动 hive:
[yyds@hadoop202 hive]$ bin/hive4)使用JDBC方式访问Hive
在hive-site.xml文件中添加如下配置信息:
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>启动hiveserver2:
[yyds@hadoop102 hive]$ bin/hive --service hiveserver2启动beeline客户端(需要多等待一会):
[yyds@hadoop102 hive]$ bin/beeline -u jdbc:hive2://hadoop102:10000 -n yyds看到如下界面:
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://hadoop102:10000>解决Hive启动后,会进行Hive metastore(hive元数据库)的初始化工作,如果初始化正常,就能进入hive命令行了。
接着执行一个HQL查询:
hive> show databases;
OK
default
Time taken: 12.504 seconds, Fetched: 1 row(s)如果hive安装、配置正常,会输出上面信息,同时hive会在mysql数据库里创建一个名为hive的库,这个hive库就是Hive metastore。
如果hive无法自动创建元数据库,也可以通过如下命令来完成:
[hadoop@cdh5node2 ~]$schematool -dbType mysql -initSchema其中,schematool工具可用于初始化当前Hive版本的Metastore数据。还可处理从较旧版本到新版本的架构升级。
6、编写启动metastore和hiveserver2脚本
1)Shell命令介绍
前台启动的方式导致需要打开多个shell窗口,可以使用如下方式后台方式启动
nohup: 放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
0:标准输入
1:标准输出
2:错误输出
2>&1:表示将错误重定向到标准输出上
&:放在命令结尾,表示后台运行
一般会组合使用:nohup [xxx命令操作]> file 2>&1 & , 表示将xxx命令运行的结果输出到file中,并保持命令启动的进程在后台运行。
[yyds@hadoop202 hive]$ nohup hive --service metastore 2>&1 &
[yyds@hadoop202 hive]$ nohup hive --service hiveserver2 2>&1 &2)编写脚本
[yyds@hadoop102 hive]$ vim $HIVE_HOME/bin/hiveservices.sh
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac3)添加执行权限
[yyds@hadoop102 hive]$ chmod u+x $HIVE_HOME/bin/hiveservices.sh4)启动Hive后台服务
[yyds@hadoop102 hive]$ hiveservices.sh start7、Hive常用交互命令
[yyds@hadoop102 hive]$ bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the console)1)“-e”不进入hive的交互窗口执行sql语句
[yyds@hadoop102 hive]$ bin/hive -e "select id from student;"2)“-f”执行脚本中sql语句
(1)在/opt/module/hive/下创建datas目录并在datas目录下创建hivef.sql文件
[yyds@hadoop102 datas]$ touch hivef.sql(2)文件中写入正确的sql语句
select *from student;(3)执行文件中的sql语句
[yyds@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql(4)执行文件中的sql语句并将结果写入文件中
[yyds@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/datas/hive_result.txt3)Hive其他命令操作
(1)退出hive窗口
hive(default)>exit;
hive(default)>quit;在新版的hive中没区别了,在以前的版本是有的:
exit:先隐性提交数据,再退出;
quit:不提交数据,退出;
(2)在hive cli命令窗口中如何查看hdfs文件系统
hive(default)>dfs -ls /;(3)查看在hive中输入的所有历史命令
进入到当前用户的根目录/root或/home/yyds,查看. hivehistory文件:
[root@hadoop102 ~]$ cat .hivehistory8、Hive常见属性配置
1)打印当前库和表头
在hive-site.xml中加入如下两个配置:
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>2)Hive运行日志信息配置
Hive的log默认存放在/tmp/yyds/hive.log目录下(当前用户名下),修改hive的log存放日志到/opt/module/hive/logs。
(1)修改/opt/module/hive/conf/hive-log4j2.properties.template文件名称为
hive-log4j2.properties:
[yyds@hadoop102 conf]$ pwd
/opt/module/hive/conf
[yyds@hadoop102 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties(2)在hive-log4j.properties文件中修改log存放位置
property.hive.log.dir=/opt/module/hive/logs3)参数配置方式
查看当前所有的配置信息:
hive>set;参数的配置三种方式:
(1)配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
(2)命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
例如:
[yyds@hadoop103 hive]$ bin/hive -hiveconf mapred.reduce.tasks=10;注意:仅对本次hive启动有效。
查看参数设置:
hive (default)> set mapred.reduce.tasks;(3)参数声明方式
可以在HQL中使用SET关键字设定参数
例如:
hive (default)> set mapred.reduce.tasks=100;注意:仅对本次hive启动有效。
查看参数设置:
hive (default)> set mapred.reduce.tasks;上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
9、Hive数据类型
1)基本数据类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
| TINYINT | byte | 1byte有符号整数 | 20 |
| SMALINT | short | 2byte有符号整数 | 20 |
| INT | int | 4byte有符号整数 | 20 |
| BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
2)集合数据类型
| 数据类型 | 描述 | 语法示例 |
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 | struct() 例如struct<street:string, city:string> |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() 例如map<string, int> |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 | Array() 例如array<string> |
Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
3)案例实操
(1)假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 19 ,
"xiaoxiao song": 18
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}(2)基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
创建本地测试文件test.txt:
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing注意:MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
(3)Hive上创建测试表test
create table test(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';字段解释:
row format delimited fields terminated by ',' -- 列分隔符
collection items terminated by '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
map keys terminated by ':' -- MAP中的key与value的分隔符
lines terminated by '\n'; -- 行分隔符
(4)导入文本数据到测试表
load data local inpath '/opt/module/hive/datas/test.txt' into table test;
(5)访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT的访问方式
hive (default)> select friends[1],children['xiao song'],address.city from test
where name="songsong";
OK
_c0 _c1 city
lili 18 beijing
Time taken: 0.076 seconds, Fetched: 1 row(s)4)类型转化
Hive的原子数据类型是可以进行隐式转换的,类似于Java的类型转换,例如某表达式使用INT类型,TINYINT会自动转换为INT类型,但是Hive不会进行反向转化,例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST操作。
隐式类型转换规则如下:
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
可以使用CAST操作显示进行数据类型转换:
例如CAST('1' AS INT)将把字符串'1' 转换成整数1;如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。
0: jdbc:hive2://hadoop102:10000> select '1'+2, cast('1'as int) + 2;
+------+------+--+
| _c0 | _c1 |
+------+------+--+
| 3.0 | 3 |
+------+------+--+10、Hive DDL 数据定义语句
1)Hive和数据库比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
① 查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
② 数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据。
③ 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
④ 数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
1. 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];1)创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。
hive (default)> create database db_hive;2)避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
hive (default)> create database db_hive;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database db_hive already exists
hive (default)> create database if not exists db_hive;3)创建一个数据库,指定数据库在HDFS上存放的位置
hive (default)> create database db_hive2 location '/db_hive2.db';2. 查询数据库
1)显示数据库
hive> show databases;2)过滤显示查询的数据库
hive> show databases like 'db_hive*';
OK
db_hive
db_hive_13)显示数据库信息
hive> desc database db_hive;
OK
db_hive hdfs://hadoop102:9000/user/hive/warehouse/db_hive.db yydsUSER 4)显示数据库详细信息,extended
hive> desc database extended db_hive;
OK
db_hive hdfs://hadoop102:9000/user/hive/warehouse/db_hive.db yydsUSER 5)切换当前数据库
hive (default)> use db_hive;3. 修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。
hive (default)> alter database db_hive set dbproperties('createtime'='20170830');在hive中查看修改结果:
hive> desc database extended db_hive;
db_name comment location owner_name owner_type parameters
db_hive hdfs://hadoop102:8020/user/hive/warehouse/db_hive.db yyds USER {createtime=20170830}4. 删除数据库
1)删除空数据库
hive>drop database db_hive2;2)如果删除的数据库不存在,最好采用 if exists判断数据库是否存在
hive> drop database db_hive;
FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
hive> drop database if exists db_hive2;3)如果数据库不为空,可以采用cascade命令,强制删除
hive> drop database db_hive;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
hive> drop database db_hive cascade;5. 创建表
1)建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]2)字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY创建分区表
(5)CLUSTERED BY创建分桶表
(6)SORTED BY不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称, hive使用Serde进行行对象的序列与反序列化。
(8)STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
(9)LOCATION :指定表在HDFS上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE允许用户复制现有的表结构,但是不复制数据。
6. 管理表
① 内部表
1)理论
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
2)案例实操
(0)原始数据
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16(1)普通创建表
create table if not exists student(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student';(2)根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student2 as select id, name from student;(3)根据已经存在的表结构创建表
create table if not exists student3 like student;(4)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE ② 外部表
1)理论
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
2)管理表和外部表的使用场景
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
3)案例实操
分别创建部门和员工外部表,并向表中导入数据。
(0)原始数据
dept:
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700emp:
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10(1)上传数据到HDFS
hive (default)> dfs -mkdir /student;
hive (default)> dfs -put /opt/module/datas/student.txt /student;(2)建表语句,创建外部表
创建部门表:
create external table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';创建员工表:
create external table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';(3)查看创建的表
hive (default)>show tables;(4)查看表格式化数据
hive (default)> desc formatted dept;
Table Type: EXTERNAL_TABLE(5)删除外部表
hive (default)> drop table dept;外部表删除后,hdfs中的数据还在,但是metadata中dept的元数据已被删除。
③ 管理表与外部表的互相转换
(1)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE(2)修改内部表student2为外部表
alter table student2 set tblproperties('EXTERNAL'='TRUE');(3)查询表的类型
hive (default)> desc formatted student2;
Table Type: EXTERNAL_TABLE(4)修改外部表student2为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');(5)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE注意:('EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,区分大小写!
7. 修改表
1)重命名表
语法:
ALTER TABLE table_name RENAME TO new_table_name实操案例:
hive (default)> alter table dept_partition2 rename to dept_partition3;2)增加/修改/替换列信息
(1)更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name](2)增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) 注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
实操案例:
(1)查询表结构
hive> desc dept;(2)添加列
hive (default)> alter table dept add columns(deptdesc string);(3)查询表结构
hive> desc dept;(4)更新列
hive (default)> alter table dept change column deptdesc desc string;(5)查询表结构
hive> desc dept;(6)替换列
hive (default)> alter table dept replace columns(deptno string, dname
string, loc string);(7)查询表结构
hive> desc dept;8. 删除表
hive (default)> drop table dept;11、Hive DML 数据操作语句
1. 数据导入
1)向表中装载数据(Load)
hive> load data [local] inpath '数据的path' [overwrite] into table student [partition (partcol1=val1,…)];(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
2)实操案例
(0)创建一张表
hive (default)> create table student(id string, name string) row format delimited fields terminated by '\t';(1)加载本地文件到hive
hive (default)> load data local inpath '/opt/module/hive/datas/student.txt' into table default.student;(2)加载HDFS文件到hive中
上传文件到HDFS:
hive (default)> dfs -put /opt/module/hive/datas/student.txt /user/yyds/hive;加载HDFS上数据:
hive (default)> load data inpath '/user/yyds/hive/student.txt' into table default.student;(3)加载数据覆盖表中已有的数据
上传文件到HDFS:
hive (default)> dfs -put /opt/module/datas/student.txt /user/yyds/hive;加载数据覆盖表中已有的数据:
hive (default)> load data inpath '/user/yyds/hive/student.txt' overwrite into table default.student;2)通过查询语句向表中插入数据(Insert)
(1)创建一张表
hive (default)> create table student_par(id int, name string) row format delimited fields terminated by '\t';(2)基本插入数据
hive (default)> insert into table student_par values(1,'wangwu'),(2,'zhaoliu');(3)基本模式插入(根据单张表查询结果)
hive (default)> insert overwrite table student_par
select id, name from student ; insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
注意:insert不支持插入部分字段。
(4)多表(多分区)插入模式(根据多张表查询结果)
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';3)查询语句中创建表并加载数据(As Select)
(1)根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;4)创建表时通过Location指定加载数据路径
(1)上传数据到hdfs上
hive (default)> dfs -mkdir /student;
hive (default)> dfs -put /opt/module/datas/student.txt /student;(2)创建表,并指定在hdfs上的位置
hive (default)> create external table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/student;(3)查询数据
hive (default)> select * from student5;5)Import数据到指定Hive表中
注意:先用export导出后,再将数据导入。
hive (default)> import table student2 from
'/user/hive/warehouse/export/student';2. 数据导出
1)Insert导出
(1)将查询的结果导出到本地
hive (default)> insert overwrite local directory '/opt/module/hive/datas/export/student'
select * from student;(2)将查询的结果格式化导出到本地
hive(default)>insert overwrite local directory '/opt/module/hive/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from student;(3)将查询的结果导出到HDFS上(没有local)
hive (default)> insert overwrite directory '/user/yyds/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;2)Hadoop命令导出到本地
hive (default)> dfs -get /user/hive/warehouse/student/student.txt
/opt/module/datas/export/student3.txt;3)Hive Shell 命令导出
基本语法:(hive -f/-e 执行语句或者脚本 > file)
[yyds@hadoop102 hive]$ bin/hive -e 'select * from default.student;' >
/opt/module/hive/datas/export/student4.txt;4)Export导出到HDFS上
(defahiveult)> export table default.student to
'/user/hive/warehouse/export/student';export和import主要用于两个Hadoop平台集群之间Hive表迁移。
5)清除表中数据(Truncate)
注意:Truncate只能删除管理表,不能删除外部表中数据。
hive (default)> truncate table student;12、Hive 查询语句
详情,请参考官网:LanguageManual Select - Apache Hive - Apache Software Foundation
查询语句语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]1. 基本查询(Select…From)
1)全表和特定列查询
(0)原始数据
dept:
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700emp:
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10(1)创建部门表
create table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';(2)创建员工表
create table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';(3)导入数据
load data local inpath '/opt/module/datas/dept.txt' into table
dept;
load data local inpath '/opt/module/datas/emp.txt' into table emp;(4)全表查询
hive (default)> select * from emp;
hive (default)> select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp ;(5)选择特定列查询
hive (default)> select empno, ename from emp;注意:
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。
2)列别名
(1)重命名一个列
(2)便于计算
(3)紧跟列名,也可以在列名和别名之间加入关键字‘AS’
(4)案例实操
查询名称和部门:
hive (default)> select ename AS name, deptno dn from emp;3)算术运算符
| 运算符 | 描述 |
| A+B | A和B 相加 |
| A-B | A减去B |
| A*B | A和B 相乘 |
| A/B | A除以B |
| A%B | A对B取余 |
| A&B | A和B按位取与 |
| A|B | A和B按位取或 |
| A^B | A和B按位取异或 |
| ~A | A按位取反 |
案例实操:查询出所有员工的薪水后加1显示。
hive (default)> select sal +1 from emp;4)常用函数
① 常用计算函数
1. 求总行数(count)
hive (default)> select count(*) cnt from emp;2. 求工资的最大值(max)
hive (default)> select max(sal) max_sal from emp;3. 求工资的最小值(min)
hive (default)> select min(sal) min_sal from emp;4. 求工资的总和(sum)
hive (default)> select sum(sal) sum_sal from emp; 5. 求工资的平均值(avg)
hive (default)> select avg(sal) avg_sal from emp;② 常用日期函数
1. unix_timestamp:返回当前或指定时间的时间戳
select unix_timestamp();
select unix_timestamp("2020-10-28",'yyyy-MM-dd');2. from_unixtime:将时间戳转为日期格式
select from_unixtime(1603843200);3. current_date:当前日期
select current_date;4. current_timestamp:当前的日期加时间
select current_timestamp;5. to_date:抽取日期部分
select to_date('2020-10-28 12:12:12');6. year:获取年
select year('2020-10-28 12:12:12');7. month:获取月
select month('2020-10-28 12:12:12');8. day:获取日
select day('2020-10-28 12:12:12');9. hour:获取时
select hour('2020-10-28 12:13:14');10. minute:获取分
select minute('2020-10-28 12:13:14');11. second:获取秒
select second('2020-10-28 12:13:14');12. weekofyear:当前时间是一年中的第几周
select weekofyear('2020-10-28 12:12:12');13. dayofmonth:当前时间是一个月中的第几天
select dayofmonth('2020-10-28 12:12:12');14. months_between: 两个日期间的月份
select months_between('2020-04-01','2020-10-28');15. add_months:日期加减月
select add_months('2020-10-28',-3);16. datediff:两个日期相差的天数
select datediff('2020-11-04','2020-10-28');17. date_add:日期加天数
select date_add('2020-10-28',4);18. date_sub:日期减天数
select date_sub('2020-10-28',-4);19. last_day:日期的当月的最后一天
select last_day('2020-02-30');20. date_format(): 格式化日期
select date_format('2020-10-28 12:12:12','yyyy/MM/dd HH:mm:ss');
③ 常用取整函数
1. round: 四舍五入
select round(3.14);
select round(3.54);2. ceil: 向上取整
select ceil(3.14);
select ceil(3.54);3. floor: 向下取整
select floor(3.14);
select floor(3.54);④ 常用字符串操作函数
1. upper: 转大写
select upper('low');2. lower: 转小写
select lower('low');3. length: 长度
select length("yyds");4. trim: 前后去空格
select trim(" yyds");5. lpad: 向左补齐,到指定长度
select lpad('yyds',9,'g');6. rpad: 向右补齐,到指定长度
select rpad('yyds',9,'g');7. regexp_replace:使用正则表达式匹配目标字符串,匹配成功后替换!
SELECT regexp_replace('2020/10/25', '/', '-');⑤ 集合操作
1. size: 集合中元素的个数
select size(friends) from test3;2. map_keys: 返回map中的key
select map_keys(children) from test3;3. map_values: 返回map中的value
select map_values(children) from test3;4. array_contains: 判断array中是否包含某个元素
select array_contains(friends,'bingbing') from test3;5. sort_array: 将array中的元素排序
select sort_array(friends) from test3;⑥ 多维分析
1. grouping sets:多维分析
5)Limit语句
典型的查询会返回多行数据。LIMIT子句用于限制返回的行数。
hive (default)> select * from emp limit 5;
hive (default)> select * from emp limit 2,3;6)Where语句
(1)使用WHERE子句,将不满足条件的行过滤掉
(2)WHERE子句紧随FROM子句
(3)案例实操
查询出薪水大于1000的所有员工:
hive (default)> select * from emp where sal >1000;注意:where子句中不能使用字段别名。
7)比较运算符(Between/In/ Is Null)
下面表中描述了谓词操作符,这些操作符同样可以用于JOIN…ON和HAVING语句中。
| 操作符 | 支持的数据类型 | 描述 |
| A=B | 基本数据类型 | 如果A等于B则返回TRUE,反之返回FALSE |
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回TRUE,如果一边为NULL,返回False |
| A<>B, A!=B | 基本数据类型 | A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
| A<B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
| A<=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL | 所有数据类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL | 所有数据类型 | 如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(数值1, 数值2) | 所有数据类型 | 使用 IN运算显示列表中的值 |
| A [NOT] LIKE B | STRING 类型 | B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
| A RLIKE B, A REGEXP B | STRING 类型 | B是基于java的正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
案例实操:
(1)查询出薪水等于5000的所有员工
hive (default)> select * from emp where sal =5000;(2)查询工资在500到1000的员工信息
hive (default)> select * from emp where sal between 500 and 1000;(3)查询comm为空的所有员工信息
hive (default)> select * from emp where comm is null;(4)查询工资是1500或5000的员工信息
hive (default)> select * from emp where sal IN (1500, 5000);8)Like和RLike
(1)使用LIKE运算选择类似的值
(2)选择条件可以包含字符或数字
% 代表零个或多个字符(任意个字符)。
_ 代表一个字符。
(3)RLIKE子句
RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
案例实操:
(1)查找名字以A开头的员工信息
hive (default)> select * from emp where ename LIKE 'A%';(2)查找名字中第二个字母为A的员工信息
hive (default)> select * from emp where ename LIKE '_A%';(3)查找名字中带有A的员工信息
hive (default)> select * from emp where ename RLIKE '[A]';9)逻辑运算符(And/Or/Not)
| 操作符 | 含义 |
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
案例实操:
(1)查询薪水大于1000,部门是30
hive (default)> select * from emp where sal>1000 and deptno=30;(2)查询薪水大于1000,或者部门是30
hive (default)> select * from emp where sal>1000 or deptno=30;(3)查询除了20部门和30部门以外的员工信息
hive (default)> select * from emp where deptno not IN(30, 20);2. 分组
1)Group By语句
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
案例实操:
(1)计算emp表每个部门的平均工资
hive (default)> select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;(2)计算emp每个部门中每个岗位的最高薪水
hive (default)> select t.deptno, t.job, max(t.sal) max_sal from emp t group by
t.deptno, t.job;2)Having语句
having与where不同点:
(1)where后面不能写分组函数,而having后面可以使用分组函数。
(2)having只用于group by分组统计语句。
案例实操:
(1)求每个部门的平均薪水大于2000的部门
求每个部门的平均工资:
hive (default)> select deptno, avg(sal) from emp group by deptno;求每个部门的平均薪水大于2000的部门:
hive (default)> select deptno, avg(sal) avg_sal from emp group by deptno having
avg_sal > 2000;3. Join语句
1)等值Join
Hive支持通常的SQL JOIN语句。
案例实操:
(1)根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称。
hive (default)> select e.empno, e.ename, d.deptno, d.dname from emp e join dept d on e.deptno = d.deptno;2)表的别名
好处:
(1)使用别名可以简化查询。
(2)使用表名前缀可以提高执行效率。
案例实操:
合并员工表和部门表:
hive (default)> select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno
= d.deptno;3)内连接
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
hive (default)> select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno
= d.deptno;4)左外连接
左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
hive (default)> select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;5)右外连接
右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。
hive (default)> select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;6)满外连接
满外连接:将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
hive (default)> select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno
= d.deptno;7)多表连接
注意:连接 n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。
数据准备:
1700 Beijing
1800 London
1900 Tokyo(1)创建位置表
create table if not exists location(
loc int,
loc_name string
)
row format delimited fields terminated by '\t';(2)导入数据
hive (default)> load data local inpath '/opt/module/datas/location.txt' into table location;(3)多表连接查询
hive (default)>SELECT e.ename, d.dname, l.loc_name
FROM emp e
JOIN dept d
ON d.deptno = e.deptno
JOIN location l
ON d.loc = l.loc;大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表e和表d进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表l;进行连接操作。
注意:为什么不是表d和表l先进行连接操作呢?这是因为Hive总是按照从左到右的顺序执行的。
优化:当对3个或者更多表进行join连接时,如果每个on子句都使用相同的连接键的话,那么只会产生一个MapReduce job。
8)笛卡尔积
(1)笛卡尔积会在下面条件下产生
(1)省略连接条件
(2)连接条件无效
(3)所有表中的所有行互相连接
案例实操:
hive (default)> select empno, dname from emp, dept;4. 排序
1)全局排序(Order By)
Order By:全局排序,只有一个Reducer
(1)使用 ORDER BY 子句排序
ASC(ascend): 升序(默认)
DESC(descend): 降序
(2)ORDER BY 子句在SELECT语句的结尾
案例实操:
(1)查询员工信息按工资升序排列
hive (default)> select * from emp order by sal;(2)查询员工信息按工资降序排列
hive (default)> select * from emp order by sal desc;2)按照别名排序
按照员工薪水的2倍排序:
hive (default)> select ename, sal*2 twosal from emp order by twosal;3)多个列排序
按照部门和工资升序排序:
hive (default)> select ename, deptno, sal from emp order by deptno, sal ;4)每个Reduce内部排序(Sort By)
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用sort by。
Sort by为每个reducer产生一个排序文件。每个Reducer内部进行排序,对全局结果集来说不是排序。
(1)设置reduce个数
hive (default)> set mapreduce.job.reduces=3;(2)查看设置reduce个数
hive (default)> set mapreduce.job.reduces;(3)根据部门编号降序查看员工信息
hive (default)> select * from emp sort by deptno desc;(4)将查询结果导入到文件中(按照部门编号降序排序)
hive (default)> insert overwrite local directory '/opt/module/hive/datas/sortby-result'
select * from emp sort by deptno desc;5)分区(Distribute By)
Distribute By: 在有些情况下,我们需要控制某个特定行应该到哪个reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by类似MR中partition(自定义分区),进行分区,结合sort by使用。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
案例实操:
(1)先按照部门编号分区,再按照员工编号降序排序。
hive (default)> set mapreduce.job.reduces=3;
hive (default)> insert overwrite local directory '/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;注意:
-
- distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。
- Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
6)Cluster By
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
(1)以下两种写法等价
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
13、Hive 分区表和分桶表
1. 分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
1)分区表基本操作
(1)引入分区表(需要根据日期对日志进行管理, 通过部门信息模拟)
dept_20200401.log
dept_20200402.log
dept_20200403.log
……(2)创建分区表语法
hive (default)> create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (day string)
row format delimited fields terminated by '\t';注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。
(3)加载数据到分区表中
① 数据准备
dept_20200401.log
10 ACCOUNTING 1700
20 RESEARCH 1800dept_20200402.log
30 SALES 1900
40 OPERATIONS 1700dept_20200403.log
50 TEST 2000
60 DEV 1900② 加载数据
hive (default)> load data local inpath '/opt/module/hive/datas/dept_20200401.log' into table dept_partition partition(day='20200401');
hive (default)> load data local inpath '/opt/module/hive/datas/dept_20200402.log' into table dept_partition partition(day='20200402');
hive (default)> load data local inpath '/opt/module/hive/datas/dept_20200403.log' into table dept_partition partition(day='20200403');注意:分区表加载数据时,必须指定分区。

(4)查询分区表中数据
单分区查询:
hive (default)> select * from dept_partition where day='20200401';多分区联合查询:
hive (default)> select * from dept_partition where day='20200401'
union
select * from dept_partition where day='20200402'
union
select * from dept_partition where day='20200403';
hive (default)> select * from dept_partition where day='20200401' or
day='20200402' or day='20200403' ; (5)查询分区表中数据
创建单个分区:
hive (default)> alter table dept_partition add partition(day='20200404') ;同时创建多个分区:
hive (default)> alter table dept_partition add partition(day='20200405') partition(day='20200406');(6)删除分区
删除单个分区:
hive (default)> alter table dept_partition drop partition (day='20200406');同时删除多个分区:
hive (default)> alter table dept_partition drop partition (day='20200404'), partition(day='20200405');(7)查看分区表有多少分区
hive> show partitions dept_partition;(8)查看分区表结构
hive> desc formatted dept_partition;
# Partition Information
# col_name data_type comment
month string 2)二级分区
思考: 如何一天的日志数据量也很大,如何再将数据拆分?
(1)创建二级分区表
hive (default)> create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';(2)正常的加载数据
① 加载数据到二级分区表中
hive (default)> load data local inpath '/opt/module`/hive/datas/dept_20200401.log' into table
dept_partition2 partition(day='20200401', hour='12');② 查询分区数据
hive (default)> select * from dept_partition2 where day='20200401' and hour='12';(3)把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
方式一:上传数据后修复。
上传数据:
hive (default)> dfs -mkdir -p
/user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=13;
hive (default)> dfs -put /opt/module/datas/dept_20200401.log /user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=13;查询数据(查询不到刚上传的数据):
hive (default)> select * from dept_partition2 where day='20200401' and hour='13';执行修复命令:
hive> msck repair table dept_partition2;再次查询数据:
hive (default)> select * from dept_partition2 where day='20200401' and hour='13';方式二:上传数据后添加分区。
上传数据:
hive (default)> dfs -mkdir -p
/user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=14;
hive (default)> dfs -put /opt/module/hive/datas/dept_20200401.log /user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=14;执行添加分区:
hive (default)> alter table dept_partition2 add partition(day='201709',hour='14');查询数据:
hive (default)> select * from dept_partition2 where day='20200401' and hour='14';方式三:创建文件夹后load数据到分区。
创建目录:
hive (default)> dfs -mkdir -p
/user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=15;上传数据:
hive (default)> load data local inpath '/opt/module/hive/datas/dept_20200401.log' into table
dept_partition2 partition(day='20200401',hour='15');查询数据:
hive (default)> select * from dept_partition2 where day='20200401' and hour='15';3)动态分区
关系型数据库中,对分区表Insert数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive中也提供了类似的机制,即动态分区(Dynamic Partition),只不过,使用Hive的动态分区,需要进行相应的配置。
开启动态分区参数设置:
(1)开启动态分区功能(默认true,开启)
hive.exec.dynamic.partition=true(2)设置为非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict(3)在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000
hive.exec.max.dynamic.partitions=1000(4)在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100(5)整个MR Job中,最大可以创建多少个HDFS文件。默认100000
hive.exec.max.created.files=100000(6)当有空分区生成时,是否抛出异常。一般不需要设置。默认false
hive.error.on.empty.partition=false案例实操:
需求:将dept表中的数据按照地区(loc字段),插入到目标表dept_partition的相应分区中。
(1)创建目标分区表
hive (default)> create table dept_partition_dy(id int, name string) partitioned by (loc int) row format delimited fields terminated by '\t';(2)设置动态分区
set hive.exec.dynamic.partition.mode = nonstrict;
hive (default)> insert into table dept_partition_dy partition(loc) select deptno, dname, loc from dept;(3)查看目标分区表的分区情况
hive (default)> show partitions dept_partition;思考:目标分区表是如何匹配到分区字段的?
2. 分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
1)先创建分桶表
(1)数据准备
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16(2)创建分桶表
create table stu_bucket(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';(3)查看表结构
hive (default)> desc formatted stu_bucket;
Num Buckets: 4 (4)导入数据到分桶表中,load的方式
hive (default)> load data inpath '/student.txt' into table stu_bucket;(5)查看创建的分桶表中是否分成4个桶

(6)查询分桶的数据
hive(default)> select * from stu_buck;(7)分桶规则
根据结果可知:Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方 式决定该条记录存放在哪个桶当中.
2)分桶表操作需要注意的事项:
(1)reduce的个数设置为-1,让Job自行决定需要用多少个reduce或者将reduce的个数设置为大于等于分桶表的桶数
(2)从hdfs中load数据到分桶表中,避免本地文件找不到问题
(3)不要使用本地模式
3)insert方式将数据导入分桶表
hive(default)>insert into table stu_buck select * from student_insert ;3. 抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
语法: TABLESAMPLE(BUCKET x OUT OF y)
查询表stu_buck中的数据:
hive (default)> select * from stu_buck tablesample(bucket 1 out of 4 on id);注意:x的值必须小于等于y的值,否则:
AILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck14、Hive 操作语句总结
创建表:
hive> CREATE TABLE A (a INT, b STRING); 创建表并创建索引字段ds:
hive> CREATE TABLE A (a INT, b STRING) PARTITIONED BY (dt STRING);
hive> create table test_table (id string, ip string,pt string) partitioned by (dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';显示所有表:
hive> SHOW TABLES;更改表名:
hive> ALTER TABLE A RENAME TO B 表添加一列:
hive> ALTER TABLE B ADD COLUMNS (new_col INT);创建复制表结构:
hive> create table test_table_002 like test_table;删除表:
hive> DROP TABLE IF EXISTS A;hive 默认的字段分隔符为ascii码的控制符\001,若在建表的时候没有指明分隔符,load文件的时候文件的分隔符需要是'\001';若文件分隔符不是'001',程序不会报错,但表查询的结果会全部为'null';如果要测试的话,造数据在vi 打开文件里面,用ctrl+v然后再ctrl+a可以输入这个控制符\001。
加载本地文件数据,将本地文件导入hive表中,其中/examples/files/kv1.txt是本地操作系统下的路径:
hive> LOAD DATA LOCAL INPATH '/examples/files/kv1.txt' OVERWRITE INTO TABLE A; 加载本地文件数据,将本地文件导入hive表中,同时给定分区信息:
hive> LOAD DATA LOCAL INPATH '/examples/files/kv2.txt' OVERWRITE INTO TABLE A PARTITION (dt='2018-08-15');加载HDFS数据,将HDFS上的文件导入hive表,同时给定分区信息:
hive> LOAD DATA INPATH '/user/mydata/kv3.txt' OVERWRITE INTO TABLE A PARTITION (dt='2018-08-15');如果有local这个关键字,则这个路径应该为本地文件系统路径;如果省略掉local关键字,那么这个路径应该是分布式文件系统中的路径。
将hive表数据导入到本地A_table目录中:
insert overwrite local directory '/home/hadoop/A_table' row format delimited fields terminated by '\t' select * from A;
插入数据:
hive> insert into test_table partition(dt='2018-08-15') select * from test_table_001; #追加插入
hive> insert overwrite test_table partition(dt='2018-08-15') select * from test_table_001; #覆盖分区插入添加分区:
hive> alter table test_table add if not exists partition(dt='2018-08-08') ;删除分区:
hive> alter table test_table drop if exists partition(dt='2018-08-08') ;清空分区数据:
hive> truncate table test_table partition(dt='2018-08-08') ;
15、函数
1)系统内置函数
(1)查看系统自带的函数
hive> show functions;(2)显示自带的函数的用法
hive> desc function upper;(3)详细显示自带的函数的用法
hive> desc function extended upper;2)常用内置函数
1. 空字段赋值
(1)函数说明
NVL:给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL。
(2)数据准备:采用员工表。
(3)查询:如果员工的comm为NULL,则用-1代替。
hive (default)> select comm,nvl(comm, -1) from emp;
OK
comm _c1
NULL -1.0
300.0 300.0
500.0 500.0
NULL -1.0
1400.0 1400.0
NULL -1.0
NULL -1.0
NULL -1.0
NULL -1.0
0.0 0.0
NULL -1.0
NULL -1.0
NULL -1.0
NULL -1.0(4)查询:如果员工的comm为NULL,则用领导id代替
hive (default)> select comm, nvl(comm,mgr) from emp;
OK
comm _c1
NULL 7902.0
300.0 300.0
500.0 500.0
NULL 7839.0
1400.0 1400.0
NULL 7839.0
NULL 7839.0
NULL 7566.0
NULL NULL
0.0 0.0
NULL 7788.0
NULL 7698.0
NULL 7566.0
NULL 7782.02. CASE WHEN THEN ELSE END
(1)数据准备
| name | dept_id | sex |
| 悟空 | A | 男 |
| 大海 | A | 男 |
| 宋宋 | B | 男 |
| 凤姐 | A | 女 |
| 婷姐 | B | 女 |
| 婷婷 | B | 女 |
(2)需求
求出不同部门男女各多少人,结果如下:
dept_Id 男 女
A 2 1
B 1 2(3)创建本地emp_sex.txt,导入数据:
[yyds@hadoop102 datas]$ vi emp_sex.txt
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 B 女
婷婷 B 女(4)创建hive表并导入数据
create table emp_sex(
name string,
dept_id string,
sex string)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/hive/datas/emp_sex.txt' into table emp_sex;(5)按需求查询数据
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;3. 行转列
(1)相关函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
注意: CONCAT_WS must be "string or array<string>
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
(2)数据准备
| name | constellation | blood_type |
| 孙悟空 | 白羊座 | A |
| 大海 | 射手座 | A |
| 宋宋 | 白羊座 | B |
| 猪八戒 | 白羊座 | A |
| 凤姐 | 射手座 | A |
| 苍老师 | 白羊座 | B |
(3)需求
把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋|苍老师(4)创建本地constellation.txt,导入数据:
[yyds@hadoop102 datas]$ vim person_info.txt
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
苍老师 白羊座 B(5)创建hive表并导入数据
create table person_info(
name string,
constellation string,
blood_type string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/module/hive/datas/person_info.txt" into table person_info;(6)按需求查询数据
SELECT t1.c_b , CONCAT_WS("|",collect_set(t1.name))
FROM (
SELECT NAME ,CONCAT_WS(',',constellation,blood_type) c_b
FROM person_info
)t1
GROUP BY t1.c_b4. 列转行
(1)函数说明
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
(2)数据准备
数据准备
| movie | category |
| 《疑犯追踪》 | 悬疑,动作,科幻,剧情 |
| 《Lie to me》 | 悬疑,警匪,动作,心理,剧情 |
| 《战狼2》 | 战争,动作,灾难 |
(3)需求
将电影分类中的数组数据展开。结果如下:
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难(4)创建本地movie.txt,导入数据:
[yyds@hadoop102 datas]$ vi movie_info.txt
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难(5)创建hive表并导入数据
create table movie_info(
movie string,
category string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/module/hive/datas/movie_info.txt" into table movie_info;(6)按需求查询数据
SELECT movie,category_name
FROM movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name ;5. 窗口函数(开窗函数)
(1)相关函数说明
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的改变而变化。
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING表示到后面的终点
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。
注意:n必须为int类型。
(2)数据准备:name,orderdate,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94(3)需求
1. 查询在2017年4月份购买过的顾客及总人数
2. 查询顾客的购买明细及月购买总额
3. 上述的场景, 将每个顾客的cost按照日期进行累加
4. 查询每个顾客上次的购买时间
5. 查询前20%时间的订单信息
(4)创建本地business.txt,导入数据
[yyds@hadoop102 datas]$ vi business.txt(5)创建hive表并导入数据
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath "/opt/module/hive/datas/business.txt" into table business;(6)按需求查询数据
查询在2017年4月份购买过的顾客及总人数:
select name,count(*) over ()
from business
where substring(orderdate,1,7) = '2017-04'
group by name;查询顾客的购买明细及月购买总额:
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from
business;将每个顾客的cost按照日期进行累加:
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from business;rows必须跟在Order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量。
查看顾客上次的购买时间:
select name,orderdate,cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2
from business;查询前20%时间的订单信息:
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;6. Rank
(1)函数说明
RANK() 排序相同时会重复,总数不会变。
DENSE_RANK() 排序相同时会重复,总数会减少。
ROW_NUMBER() 会根据顺序计算。
(2)数据准备
| name | subject | score |
| 孙悟空 | 语文 | 87 |
| 孙悟空 | 数学 | 95 |
| 孙悟空 | 英语 | 68 |
| 大海 | 语文 | 94 |
| 大海 | 数学 | 56 |
| 大海 | 英语 | 84 |
| 宋宋 | 语文 | 64 |
| 宋宋 | 数学 | 86 |
| 宋宋 | 英语 | 84 |
| 婷婷 | 语文 | 65 |
| 婷婷 | 数学 | 85 |
| 婷婷 | 英语 | 78 |
(3)需求
计算每门学科成绩排名。
(4)创建本地score.txt,导入数据
[yyds@hadoop102 datas]$ vi score.txt(5)创建hive表并导入数据
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/hive/datas/score.txt' into table score;(6)按需求查询数据
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
name subject score rp drp rmp
孙悟空 数学 95 1 1 1
宋宋 数学 86 2 2 2
婷婷 数学 85 3 3 3
大海 数学 56 4 4 4
宋宋 英语 84 1 1 1
大海 英语 84 1 1 2
婷婷 英语 78 3 2 3
孙悟空 英语 68 4 3 4
大海 语文 94 1 1 1
孙悟空 语文 87 2 2 2
婷婷 语文 65 3 3 3
宋宋 语文 64 4 4 4扩展:求出每门学科前三名的学生?
3)自定义函数
Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出
(2)UDAF(User-Defined Aggregation Function)
聚集函数,多进一出
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出
如lateral view explode()
官方文档地址:HivePlugins - Apache Hive - Apache Software Foundation
编程步骤:
(1)继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;(2)实现类中的抽象方法
(3)在hive的命令行窗口创建函数
添加jar:
add jar linux_jar_path创建function:
create [temporary] function [dbname.]function_name AS class_name;(4)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;4)自定义UDF函数
(0)需求
自定义一个UDF实现计算给定字符串的长度,例如:
hive(default)> select my_len("abcd");
4(1)创建一个Maven工程Hive
(2)导入依赖
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>(3)创建一个类
package com.yyds.hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* 自定义UDF函数,需要继承GenericUDF类
* 需求: 计算指定字符串的长度
*/
public class MyStringLength extends GenericUDF {
/**
*
* @param arguments 输入参数类型的鉴别器对象
* @return 返回值类型的鉴别器对象
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 判断输入参数的个数
if(arguments.length !=1){
throw new UDFArgumentLengthException("Input Args Length Error!!!");
}
// 判断输入参数的类型
if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0,"Input Args Type Error!!!");
}
//函数本身返回值为int,需要返回int类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数的逻辑处理
* @param arguments 输入的参数
* @return 返回值
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
if(arguments[0].get() == null){
return 0 ;
}
return arguments[0].get().toString().length();
}
@Override
public String getDisplayString(String[] children) {
return "";
}
}(4)打成jar包上传到服务器/opt/module/hive/datas/myudf.jar
(5)将jar包添加到hive的classpath
hive (default)> add jar /opt/module/hive/datas/myudf.jar;(6)创建临时函数与开发好的java class关联
hive (default)> create temporary function my_len as "com.yyds.hive. MyStringLength";(7)即可在hql中使用自定义的函数
hive (default)> select ename,my_len(ename) ename_len from emp;5)自定义UDTF函数
(0)需求
自定义一个UDTF实现将一个任意分割符的字符串切割成独立的单词,例如:
hive(default)> select myudtf("hello,world,hadoop,hive", ",");
hello
world
hadoop
hive(1)代码实现
package com.yyds.udtf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
public class MyUDTF extends GenericUDTF {
private ArrayList<String> outList = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//1.定义输出数据的列名和类型
List<String> fieldNames = new ArrayList<>();
List<ObjectInspector> fieldOIs = new ArrayList<>();
//2.添加输出数据的列名和类型
fieldNames.add("lineToWord");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
//1.获取原始数据
String arg = args[0].toString();
//2.获取数据传入的第二个参数,此处为分隔符
String splitKey = args[1].toString();
//3.将原始数据按照传入的分隔符进行切分
String[] fields = arg.split(splitKey);
//4.遍历切分后的结果,并写出
for (String field : fields) {
//集合为复用的,首先清空集合
outList.clear();
//将每一个单词添加至集合
outList.add(field);
//将集合内容写出
forward(outList);
}
}
@Override
public void close() throws HiveException {
}
}(2)打成jar包上传到服务器/opt/module/hive/data/myudtf.jar
(3)将jar包添加到hive的classpath下
hive (default)> add jar /opt/module/hive/data/myudtf.jar;(4)创建临时函数与开发好的java class关联
hive (default)> create temporary function myudtf as "com.yyds.hive.MyUDTF";(5)使用自定义的函数
hive (default)> select myudtf("hello,world,hadoop,hive",",") ;16、压缩与存储
1. Hadoop压缩配置
1)MR支持的压缩编码
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
| DEFLATE | DEFLATE | .deflate | 否 |
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .bz2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码器 |
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
snappy | A fast compressor/decompressor
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
2)压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):

2. 开启Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。具体配置如下:
案例实操:
(1)开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;(2)开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;(3)设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;(4)执行查询语句
hive (default)> select count(ename) name from emp;3. 开启Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
案例实操:
(1)开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;(2)开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;(3)设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;(4)设置mapreduce最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;(5)测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory
'/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;4. 文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
1)列式存储和行式存储

如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
(1)行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
(2)列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的。
ORC和PARQUET是基于列式存储的。
2)TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
3)Orc格式
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
如下图所示可以看到每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:

(1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
(2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
(3)Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
4)Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
(1)行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
(2)列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
(3)页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
Parquet文件的格式:

上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
5)主流文件存储格式对比实验
从存储文件的压缩比和查询速度两个角度对比。
存储文件的压缩比测试:
(1)测试数据
2017-08-10 13:00:00 http://www.taobao.com/17/?tracker_u=1624169&type=1 B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1 http://hao.360.cn/ 1.196.34.243 NULL -1
2017-08-10 13:00:00 http://www.taobao.com/item/962967_14?ref=1_1_52_search.ctg_1 T82C9WBFB1N8EW14YF2E2GY8AC9K5M5P http://www.yihaodian.com/ctg/s2/c24566-%E5%B1%B1%E6%A5%82%E5%88%B6%E5%93%81?ref=pms_15_78_258 222.78.246.228 134939954 156
2017-08-10 13:00:00 http://www.taobao.com/1/?tracker_u=1013304189&uid=2687512&type=3 W17C89RU8DZ6NMN7JD2ZCBDMX1CQVZ1W http://www.yihaodian.com/1/?tracker_u=1013304189&uid=2687512&type=3 118.205.0.18 NULL -20
2017-08-10 13:00:00 http://m.taobao.com/getCategoryByRootCategoryId_1_5146 f55598cafba346eb217ff3fbd0de2930 http://m.yihaodian.com/getCategoryByRootCategoryId_1_5135 10.4.6.53 NULL -1000
2017-08-10 13:00:00 http://m.taobao.com/getCategoryByRootCategoryId_1_24728 f55598cafba346eb217ff3fbd0de2930 http://m.yihaodian.com/getCategoryByRootCategoryId_1_5146 10.4.4.109 NULL -1000
2017-08-10 13:00:00 http://union.taobao.com/link_make/viewPicInfo.do?imgSize=660x70&truckerU=101542127 4PBTT18JEEJHM91DNGKNUSZTA29W8WP3 http://www.jintoutiao.com/yule.html 125.38.159.84 NULL -30
2017-08-10 13:00:00 http://www.taobao.com/item/9680587_1?smt_b=C0B0A09BECBF110A470F00C 615MMAA5RFVRRMHJVP5VCHTQGEGDW988 211.167.237.134 NULL -20
2017-08-10 13:00:00 http://union.taobao.com/link_make/viewPicInfo.do?imgSize=660x70&truckerU=101542127 QCU8A6VCNX28YGGJVQAABG4BJ6F8QT1B http://jintoutiao.com/yule.html 117.22.144.64 NULL 327
2017-08-10 13:00:00 http://www.taobao.com/ctg/s2/c8325-%E7%99%BE%E6%B4%81%E5%B8%83-%E9%92%A2%E4%B8%9D%E7%90%83/ ZYVF5W5WDFGAQP1S45RTFR7SPVM8GY5Q http://www.yihaodian.com/item/user/continueShopping.do?lc=\u6c34\u4e0a\u7528\u5177&csps=1984887_3_1_950411&pageType=B 61.128.247.131 5305018 -40
2017-08-10 13:00:00 http://m.taobao.com/getProductDetail_1_1001417 A90A3460D49D437E96BC3B4DC138B628 http://m.yihaodian.com/searchProduct_1_银杏洗面奶_2 222.128.241.1 NULL -20
2017-08-10 13:00:00 http://search.taobao.com/s2/c0-0/k%25E6%25B4%2597%25E5%258F%2591%25E6%25B0%25B4/ WGSMFJD42BQEYB57EUHPUHHZMZHJTGX2 http://www.yihaodian.com/3/?type=3&tracker_u=1013241403 60.30.93.90 NULL -30
2017-08-10 13:00:00 http://m.taobao.com/ RJSDGJVTMNBHXE9HX53ZTZTV11NCYTED 58.39.59.80 NULL -10
2017-08-10 13:00:00 http://www.taobao.com/cart/cart.do?action=view CB4CUVX8MHE1NF3F8GKSJCZMNUYVQB9N 116.25.135.202 126027330 238
2017-08-10 13:00:00 http://m.taobao.com 169003c92a02da66a335f422acc69242 http://m.yihaodian.com/getCategoryByRootCategoryId_1_0 10.4.4.109 NULL -1000
2017-08-10 13:00:00 http://m.taobao.com/searchProduct ede5b4097d7990b15d9c3c566df7e04d 10.4.6.53 NULL -1000
2017-08-10 13:00:00 http://m.taobao.com/getCurrentGrouponList_3_-1 D14A18209FB9FDB9A971293D9AF0330C http://m.yihaodian.com/getCurrentGrouponList_3_-1 61.149.71.175 NULL -20
2017-08-10 13:00:00 http://m.taobao.com/getCategoryByRootCategoryId_1_5404 f55598cafba346eb217ff3fbd0de2930 http://m.yihaodian.com/getCategoryByRootCategoryId_1_5138 10.4.6.47 NULL -1000
2017-08-10 13:00:00 http://www.taobao.com/ctg/s2/c5464-%E8%82%89%E5%B9%B2-%E8%82%89%E6%9D%BE/ AEHC5FQSA4CYAZQMGP7113B25QTNCS2C http://www.yihaodian.com/19/?tracker_u=10535027967&type=1 222.240.184.147 NULL 222
2017-08-10 13:00:00 http://search.taobao.com/s2/c0-0/b907857/a40045-s1-v0-p1-price-d0-f0-m1-rt0-pid-khtc/ XQQMRX1HSE3AN9F33HCSV4QSDHU22N7Z http://search.yihaodian.com/s2/c0-0/b907857/ 202.204.48.147 NULL -20
2017-08-10 13:00:00 http://search.taobao.com/s2/c0-0/k%25E5%25B0%258F%25E8%2584%259A%25E4%25B8%25AB%25E5%259E%258B%25E5%258F%258C%25E9%259D%25A2%25E8%25B4%25B4%25E7%2589%25A9%25E5%2599%25A8%2520/ HA8NMG2CNF1SEPZCEFAU3DTJVK1NQCXZ 183.153.86.246 134989533 52
2017-08-10 13:00:00 http://www.taobao.com/item/1065245_6?ref=1_1_52_search.ctg_1 CKVXZVP6ENDJVM9T6JYA6U8H3UMG66PU http://www.yihaodian.com/ctg/s2/c6631-%E5%8D%B8%E5%A6%86/ 119.135.177.40 7065561 252
2017-08-10 13:00:00 http://search.taobao.com/s2/c0-0/k%25E5%258A%259E%25E5%2585%25AC/ 6844YVHVX7X3MHCT4ZSK6B1RU2ADAGCW 61.164.209.63 NULL 52
2017-08-10 13:00:00 http://www.taobao.com/checkoutV3/index.do BY2AP4Y7MA1QFS3Z1VXRGBAGUNX3KYR9 http://www.yihaodian.com/cart/cart.do?action=view 119.139.235.172 126380183 238
2017-08-10 13:00:00 http://m.taobao.com/getCategoryByRootCategoryId_1_5154 e9edbb994bf76bf683aa0ff633306f29 http://m.yihaodian.com/getCategoryByRootCategoryId_1_5143 10.4.6.47 NULL -1000
2017-08-10 13:00:00 http://www.taobao.com/2/?tracker_u=10627255 X2Q4KJ36X73Y388Y2J24ZR2874921V35 27.203.254.52 NULL 29
2017-08-10 13:00:00 http://search.taobao.com/s2/c0-0/k%E6%8A%98%E5%8F%A0%E5%BA%8A/ GQSZPP1T51NVVDHFJ79DERUYZ9BY4YPV http://www.yihaodian.com/ctg/s2/c21055-%E6%B2%99%E5%8F%91/ 182.139.161.242 NULL -1
2017-08-10 13:00:00 http://www.taobao.com/ctg/s2/c6504-%E9%9D%A2%E5%8C%85%E7%94%9C%E5%93%81%E5%88%B8/b5011/ 8QBDUSW4T7DVYNX2V3REBNUYMZMJKS3Z http://www.yihaodian.com/1/?type=2 101.229.209.34 7102251 -10
2017-08-10 13:00:00 http://www.taobao.com/item/9680587_1?smt_b=C0B0A09BECBF1106C70F00C MJAGGMWCC73BEXY88PHK7GKY185ZD4Z7 http://vas.funshion.com/attachment/editor/minisite/track/track.php?r=1&t=b&fs-c-url=http://pub.funshion.com/interface/click?uid=&mac=00306717F4C0&fck=2943F792A9E2075AA0636EEA86125D35&ap=w_da_so_02&ad=3912&mid=&re=http%3A%2F%2Fmc.funshion.com%2Finterface%2Fcc%3Fmcid%3D297%26source%3Dopt-w_da_so_02&reqId=f1798890-c040-11e2-a047-d5df87697805 58.62.185.212 NULL 237
2017-08-10 13:00:00 http://m.taobao.com/productList_1_5135_2 34E89C489B1E708883DD40AD20DB722E http://m.yihaodian.com/getCategoryByRootCategoryId_5135 106.3.103.145 NULL -20
2017-08-10 13:00:00 http://www.taobao.com/item/9680587_1?smt_b=C0B0A09BECBF110A470F00C AMUSZGN1AHC2V5JYU48QEH3QHZJWQVEB 222.35.85.77 NULL -20
2017-08-10 13:00:00 http://www.taobao.com/16/?tracker_u=7520169&type=1 DXWSKTYMMJZ4YZ6V4TWBV1GD2TFF4TMF http://www.yihaodian.com/1/?tracker_u=7520169&type=1 123.150.218.141 NULL -30
2017-08-10 13:00:00 http://m.taobao.com/searchProduct bd5776b0cc527cfdc877c22a03361364 10.4.3.83 NULL -1000
2017-08-10 13:00:00 http://m.taobao.com/searchProduct 27ca0c24fa42cf415baa1277f907860f 10.4.4.109 NULL -1000
2017-08-10 13:00:00 http://m.taobao.com/searchProduct 069e71e0bf74a381cbbb731cd23c7997 10.4.6.28 NULL -1000
2017-08-10 13:00:00 http://m.taobao.com/getProductDetail_6_9475 ae34b1030bcf048b2a7c3970ecd273c0 http://m.yihaodian.com/getCategoryByRootCategoryId_1_5404 10.4.6.47 NULL -1000
2017-08-10 13:00:00 http://www.taobao.com/item/1610446_1 9CBDTSZYG3Q4TXW63GJ5DQXA1JTN8P59 http://www.yihaodian.com/S-theme/41352/ 222.71.218.101 NULL -10
2017-08-10 13:00:00 http://m.taobao.com/searchProductsOnly 36d34d07-9723-4a35-8e23-13c7f2d50b1f 10.4.6.47 NULL -1000
2017-08-10 13:00:00 http://search.taobao.com/s2/c0-0/k%25E8%25AF%25AD%25E6%2596%2587%25E5%258F%258A%25E8%25A7%25A3%25E9%25A2%2598%25E6%258C%2587%25E5%25AF%25BC/ 4AU8GBUFURH4QTRB9275BUEZ2WDKHPNV 124.65.148.196 132780751 -20
2017-08-10 13:00:00 http://my.taobao.com/order/myOrder.do?chooseType=1 7PUMXW534N7ZXXF1FVVCZD62Y89AYC3E http://www.yihaodian.com/6/?tracker_u=1013304189&uid=2722204&type=3 61.174.53.86 134781570 52
2017-08-10 13:00:00 http://m.taobao.com/getMyYihaodianSessionUser bccf7b99af3af9f644fc54d5b43d5f36 10.4.4.109 126152325 -1000
2017-08-10 13:00:00 http://www.taobao.com/ch(2)TextFile
创建表,存储数据格式为TEXTFILE:
create table log_text (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as textfile;向表中加载数据:
hive (default)> load data local inpath '/opt/module/hive/datas/log.data' into table log_text ;查看表中数据大小:
hive (default)> dfs -du -h /user/hive/warehouse/log_text;(3)ORC
创建表,存储数据格式为ORC:
create table log_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="NONE"); -- 设置orc存储不使用压缩向表中加载数据:
hive (default)> insert into table log_orc select * from log_text ;查看表中数据大小:
hive (default)> dfs -du -h /user/hive/warehouse/log_orc/ ;7.7 M /user/hive/warehouse/log_orc/000000_0
(4)Parquet
创建表,存储数据格式为parquet:
create table log_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet ;向表中加载数据:
hive (default)> insert into table log_parquet select * from log_text ;查看表中数据大小:
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet/ ;13.1 M /user/hive/warehouse/log_parquet/000000_0
存储文件的对比总结:
ORC > Parquet > textFile
存储文件的查询速度测试:
(1)TextFile
hive (default)> insert overwrite local directory '/opt/module/hive/datas/log_text' select substring(url,1,4) from log_text ;
No rows affected (10.522 seconds)(2)ORC
hive (default)> insert overwrite local directory '/opt/module/hive/datas/log_orc' select substring(url,1,4) from log_orc ;
No rows affected (11.495 seconds)(3)Parquet
hive (default)> insert overwrite local directory '/opt/module/hive/datas/log_parquet' select substring(url,1,4) from log_parquet ;
No rows affected (11.445 seconds)存储文件的查询速度总结:查询速度相近。
5. 存储和压缩结合
1)测试存储和压缩
官网:LanguageManual ORC - Apache Hive - Apache Software Foundation
ORC存储方式的压缩:
| Key | Default | Notes |
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.stripe.size | 268,435,456 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
| orc.bloom.filter.columns | "" | comma separated list of column names for which bloom filter should be created |
| orc.bloom.filter.fpp | 0.05 | false positive probability for bloom filter (must >0.0 and <1.0) |
注意:所有关于ORCFile的参数都是在HQL语句的TBLPROPERTIES字段里面出现
(1)创建一个ZLIB压缩的ORC存储方式
建表语句:
create table log_orc_zlib(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="ZLIB");插入数据:
insert into log_orc_zlib select * from log_text;查看插入后数据:
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_zlib/ ;2.78 M /user/hive/warehouse/log_orc_none/000000_0
(2)创建一个SNAPPY压缩的ORC存储方式
建表语句:
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");插入数据:
insert into log_orc_snappy select * from log_text;查看插入后数据:
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_snappy/ ;3.75 M /user/hive/warehouse/log_orc_snappy/000000_0
ZLIB比Snappy压缩的还小。原因是ZLIB采用的是deflate压缩算法。比snappy压缩的压缩率高。
(3)创建一个SNAPPY压缩的parquet存储方式
建表语句:
create table log_parquet_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet
tblproperties("parquet.compression"="SNAPPY");插入数据:
insert into log_parquet_snappy select * from log_text;查看插入后数据:
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet_snappy / ;6.39 MB /user/hive/warehouse/ log_parquet_snappy /000000_0
(4)存储方式和压缩总结
在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy,lzo。
17、Hive企业级优化
1. 执行计划(Explain)
基本语法:
EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query案例实操:
(1)查看下面这条语句的执行计划
没有生成MR任务的:
hive (default)> explain select * from emp;
Explain
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
TableScan
alias: emp
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: empno (type: int), ename (type: string), job (type: string), mgr (type: int), hiredate (type: string), sal (type: double), comm (type: double), deptno (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
ListSink有生成MR任务的:
hive (default)> explain select deptno, avg(sal) avg_sal from emp group by deptno;
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: emp
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: sal (type: double), deptno (type: int)
outputColumnNames: sal, deptno
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(sal), count(sal)
keys: deptno (type: int)
mode: hash
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: double), _col2 (type: bigint)
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0), count(VALUE._col1)
keys: KEY._col0 (type: int)
mode: mergepartial
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), (_col1 / _col2) (type: double)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink(2)查看详细执行计划
hive (default)> explain extended select * from emp;
hive (default)> explain extended select deptno, avg(sal) avg_sal from emp group by deptno;2. Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。
在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>案例实操:
(1)把hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序。
hive (default)> set hive.fetch.task.conversion=none;
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;(2)把hive.fetch.task.conversion设置成more,然后执行查询语句,如下查询方式都不会执行mapreduce程序。
hive (default)> set hive.fetch.task.conversion=more;
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;3. 本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
set hive.exec.mode.local.auto=true; //开启本地mr
//设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;案例实操:
(1)开启本地模式,并执行查询语句
hive (default)> set hive.exec.mode.local.auto=true;
hive (default)> select * from emp cluster by deptno;
Time taken: 1.328 seconds, Fetched: 14 row(s)(2)关闭本地模式,并执行查询语句
hive (default)> set hive.exec.mode.local.auto=false;
hive (default)> select * from emp cluster by deptno;
Time taken: 20.09 seconds, Fetched: 14 row(s)4. 表的优化
1)小表大表Join(MapJoin)
将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成join。
实际测试发现:新版的hive已经对小表JOIN大表和大表JOIN小表进行了优化。小表放在左边和右边已经没有明显区别。
案例实操:
(1)需求
测试大表JOIN小表和小表JOIN大表的效率。
(2)开启MapJoin参数设置
设置自动选择Mapjoin:
set hive.auto.convert.join = true; 默认为true大表小表的阈值设置(默认25M以下认为是小表):
set hive.mapjoin.smalltable.filesize = 25000000;(3)MapJoin工作机制

(4)建大表、小表和JOIN后表的语句
// 创建大表
create table bigtable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 创建小表
create table smalltable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 创建join后表的语句
create table jointable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';(5)分别向大表和小表中导入数据
hive (default)> load data local inpath '/opt/module/hive/datas/bigtable' into table bigtable;
hive (default)>load data local inpath '/opt/module/hive/datas/smalltable' into table smalltable;(6)小表JOIN大表语句
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from smalltable s
join bigtable b
on b.id = s.id;
Time taken: 35.921 seconds
No rows affected (44.456 seconds)(7)执行大表JOIN小表语句
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable b
join smalltable s
on s.id = b.id;
Time taken: 34.196 seconds
No rows affected (26.287 seconds)2)大表Join大表
(1)空KEY过滤
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。例如key对应的字段为空,操作如下:
案例实操:
① 配置历史服务器
配置mapred-site.xml:
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>启动历史服务器:
sbin/mr-jobhistory-daemon.sh start historyserver查看jobhistory
http://hadoop102:19888/jobhistory
② 创建原始数据表、空id表、合并后数据表
// 创建空id表
create table nullidtable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';③ 分别加载原始数据和空id数据到对应表中
hive (default)> load data local inpath '/opt/module/hive/datas/nullid' into table nullidtable;④ 测试不过滤空id
hive (default)> insert overwrite table jointable select n.* from nullidtable n
left join bigtable o on n.id = o.id;⑤ 测试过滤空id
hive (default)> insert overwrite table jointable select n.* from (select * from nullidtable where id is not null ) n left join bigtable o on n.id = o.id;(2)空key转换
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。例如:
案例实操:
不随机分布空null值:
① 设置5个reduce个数
set mapreduce.job.reduces = 5;② JOIN两张表
insert overwrite table jointable
select n.* from nullidtable n left join bigtable b on n.id = b.id;结果:如下图所示,可以看出来,出现了数据倾斜,某些reducer的资源消耗远大于其他reducer。

随机分布空null值:
① 设置5个reduce个数
set mapreduce.job.reduces = 5;② JOIN两张表
insert overwrite table jointable
select n.* from nullidtable n full join bigtable o on
nvl(n.id,rand()) = o.id;结果:如下图所示,可以看出来,消除了数据倾斜,负载均衡reducer的资源消耗。

(3)SMB(Sort Merge Bucket join)
① 创建第二张大表:
create table bigtable2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/bigtable' into table bigtable2;测试大表直接JOIN:
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable s
join bigtable2 b
on b.id = s.id;② 创建分桶表1,桶的个数不要超过可用CPU的核数
create table bigtable_buck1(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
insert into bigtable_buck1 select * from bigtable; ③ 创建分通表2,桶的个数不要超过可用CPU的核数
create table bigtable_buck2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
insert into bigtable_buck2 select * from bigtable; ④ 设置参数
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;⑤ 测试
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;3)Group By
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。

并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
(1)开启Map端聚合参数设置
① 是否在Map端进行聚合,默认为True
set hive.map.aggr = true② 在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000③ 有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
hive (default)> select deptno from emp group by deptno;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 23.68 sec HDFS Read: 19987 HDFS Write: 9 SUCCESS
Total MapReduce CPU Time Spent: 23 seconds 680 msec
OK
deptno
10
20
30优化以后:
hive (default)> set hive.groupby.skewindata = true;
hive (default)> select deptno from emp group by deptno;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 28.53 sec HDFS Read: 18209 HDFS Write: 534 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 5 Cumulative CPU: 38.32 sec HDFS Read: 15014 HDFS Write: 9 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 6 seconds 850 msec
OK
deptno
10
20
304)Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换,但是需要注意group by造成的数据倾斜问题.
案例实操:
① 创建一张大表
hive (default)> create table bigtable(id bigint, time bigint, uid string, keyword
string, url_rank int, click_num int, click_url string) row format delimited
fields terminated by '\t';② 加载数据
hive (default)> load data local inpath '/opt/module/datas/bigtable' into table bigtable;③ 设置5个reduce个数
set mapreduce.job.reduces = 5;④ 执行去重id查询
hive (default)> select count(distinct id) from bigtable;
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.12 sec HDFS Read: 120741990 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 120 msec
OK
c0
100001
Time taken: 23.607 seconds, Fetched: 1 row(s)⑤ 采用GROUP by去重id
hive (default)> select count(id) from (select id from bigtable group by id) a;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 17.53 sec HDFS Read: 120752703 HDFS Write: 580 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 4.29 sec2 HDFS Read: 9409 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 21 seconds 820 msec
OK
_c0
100001
Time taken: 50.795 seconds, Fetched: 1 row(s)虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
5)笛卡尔积
尽量避免笛卡尔积,join的时候不加on条件,或者无效的on条件,Hive只能使用1个reducer来完成笛卡尔积。
6)行列过滤
列处理:在SELECT中,只拿需要的列,如果有分区,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤,比如:
案例实操:
① 测试先关联两张表,再用where条件过滤
hive (default)> select o.id from bigtable b
join bigtable o.id = b.id
where o.id <= 10;Time taken: 34.406 seconds, Fetched: 100 row(s)
② 通过子查询后,再关联表
hive (default)> select b.id from bigtable b
join (select id from bigtable where id <= 10 ) o on b.id = o.id;Time taken: 30.058 seconds, Fetched: 100 row(s)
5. 合理设置Map及Reduce数
1、通常情况下,作业会通过input的目录产生一个或者多个map任务。
主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小。
2、是不是map数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
3、是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
针对上面的问题2和3,我们需要采取两种方式来解决:即减少map数和增加map数;
1)复杂文件增加Map数
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
增加map的方法为:根据
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M公式,调整maxSize最大值。让maxSize最大值低于blocksize就可以增加map的个数。
案例实操:
(1)执行查询
hive (default)> select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1(2)设置最大切片值为100个字节
hive (default)> set mapreduce.input.fileinputformat.split.maxsize=100;
hive (default)> select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 6; number of reducers: 12)小文件进行合并
(1)在map执行前合并小文件,减少map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;(2)在Map-Reduce的任务结束时合并小文件的设置
在map-only任务结束时合并小文件,默认true:
SET hive.merge.mapfiles = true;在map-reduce任务结束时合并小文件,默认false:
SET hive.merge.mapredfiles = true;合并文件的大小,默认256M:
SET hive.merge.size.per.task = 268435456;当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge:
SET hive.merge.smallfiles.avgsize = 16777216;3)合理设置Reduce数
(1)调整reduce个数方法一
每个Reduce处理的数据量默认是256MB:
hive.exec.reducers.bytes.per.reducer=256000000每个任务最大的reduce数,默认为1009:
hive.exec.reducers.max=1009计算reducer数的公式:
N=min(参数2,总输入数据量/参数1)(2)调整reduce个数方法二
在hadoop的mapred-default.xml文件中修改。
设置每个job的Reduce个数:
set mapreduce.job.reduces = 15;(3)reduce个数并不是越多越好
1、过多的启动和初始化reduce也会消耗时间和资源。
2、另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题。
在设置reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的reduce数;使单个reduce任务处理数据量大小要合适。
6. 并行执行
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。或者Hive执行过程中可能需要的其他阶段。默认情况下,Hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。不过,如果有更多的阶段可以并行执行,那么job可能就越快完成。
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。不过,在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。当然,得是在系统资源比较空闲的时候才有优势,否则,没资源,并行也起不来。
7. 严格模式
Hive可以通过设置防止一些危险操作:
1)分区表不使用分区过滤
将hive.strict.checks.no.partition.filter设置为true时,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
2)使用order by没有limit过滤
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reducer中进行处理,强制要求用户增加这个LIMIT语句可以防止Reducer额外执行很长一段时间。
3)笛卡尔积
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在 执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
18、Hive 练习
1. 题目一
我们有如下的用户访问数据:
| userId | visitDate | visitCount |
| u01 | 2017/1/21 | 5 |
| u02 | 2017/1/23 | 6 |
| u03 | 2017/1/22 | 8 |
| u04 | 2017/1/20 | 3 |
| u01 | 2017/1/23 | 6 |
| u01 | 2017/2/21 | 8 |
| u02 | 2017/1/23 | 6 |
| u01 | 2017/2/22 | 4 |
要求使用SQL统计出每个用户的累积访问次数,如下表所示:
| 用户id | 月份 | 小计 | 累积 |
| u01 | 2017-01 | 11 | 11 |
| u01 | 2017-02 | 12 | 23 |
| u02 | 2017-01 | 12 | 12 |
| u03 | 2017-01 | 8 | 8 |
| u04 | 2017-01 | 3 | 3 |
数据:
u01 2017/1/21 5
u02 2017/1/23 6
u03 2017/1/22 8
u04 2017/1/20 3
u01 2017/1/23 6
u01 2017/2/21 8
u02 2017/1/23 6
u01 2017/2/22 41)创建表
create table action
(userId string,
visitDate string,
visitCount int)
row format delimited fields terminated by "\t";select tmp.*,sum(sum1) over( partition by userid rows between unbounded preceding and current row) from ( select userid,date_format(regexp_replace(visitDate, '/', '-'),'yyy-MM'),sum(visitCount) sum1 from action group by userId,date_format(regexp_replace(visitDate, '/', '-'),'yyy-MM'))tmp;2. 题目二
有50W个京东店铺,每个顾客访问任何一个店铺的任何一个商品时都会产生一条访问日志,访问日志存储的表名为visit,访客的用户id为user_id,被访问的店铺名称为shop,请统计:
u1 a
u2 b
u1 b
u1 a
u3 c
u4 b
u1 a
u2 c
u5 b
u4 b
u6 c
u2 c
u1 b
u2 a
u2 a
u3 a
u5 a
u5 a
u5 a建表:
create table visit(user_id string,shop string) row format delimited fields terminated
by '\';1)每个店铺的UV(访客数)
select shop,count(user_id)cou from visit group by shop;2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
select shop,user_id,ct from (select *,rank() over(partition by shop order by ct desc) rk from (select shop,user_id,count(user_id) ct from visit group by shop,user_id) tmp) a where rk<=3;3. 题目三
以下表记录了用户每天的蚂蚁森林低碳生活领取的记录流水。
table_name:user_low_carbon
user_id data_dt low_carbon
用户 日期 减少碳排放(g)
蚂蚁森林植物换购表,用于记录申领环保植物所需要减少的碳排放量
table_name: plant_carbon、
plant_id plant_name low_carbon
植物编号 植物名 换购植物所需要的碳
1)蚂蚁森林植物申领统计
问题:假设2017年1月1日开始记录低碳数据(user_low_carbon),假设2017年10月1日之前满足申领条件的用户都申领了一颗p004-胡杨,
剩余的能量全部用来领取“p002-沙柳” 。
统计在10月1日累计申领“p002-沙柳” 排名前10的用户信息;以及他比后一名多领了几颗沙柳。
得到的统计结果如下表样式:
user_id plant_count less_count(比后一名多领了几颗沙柳)
u_101 1000 100
u_088 900 400
u_103 500 …select t6.user_id,t6.sum1,(t6.sum1-t6.next_sum1) from (select user_id,sum1,lead(t5.sum1,1) over(order by sum1 desc ) next_sum1 from (select user_id,floor((sum - t4.low_carbon)/t3.low_carbon) sum1 from (select user_id,sum(t1.low_carbon) sum from (select user_id,date_format(regexp_replace(data_dt,'/','-'),'yyyy-MM-dd') data_dt,low_carbon from user_low_carbon) t1 where t1.data_dt<'2017-10-01' group by user_id order by sum desc limit 11)t2,(select low_carbon from plant_carbon where plant_id='p002')t3, (select low_carbon from plant_carbon where plant_id='p004') t4)t5 limit 10 ) t6 order by t6.sum1 desc;2)蚂蚁森林低碳用户排名分析
问题:查询user_low_carbon表中每日流水记录,条件为:
用户在2017年,连续三天(或以上)的天数里,
每天减少碳排放(low_carbon)都超过100g的用户低碳流水。
需要查询返回满足以上条件的user_low_carbon表中的记录流水。
例如用户u_002符合条件的记录如下,因为2017/1/2~2017/1/5连续四天的碳排放量之和都大于等于100g:
seq(key) user_id data_dt low_carbon
xxxxx10 u_002 2017/1/2 150
xxxxx11 u_002 2017/1/2 70
xxxxx12 u_002 2017/1/3 30
xxxxx13 u_002 2017/1/3 80
xxxxx14 u_002 2017/1/4 150
xxxxx14 u_002 2017/1/5 101备注:统计方法不限于sql、procedure、python、java等。
思路一:
select t5.user_id,t6.data_dt,t6.low_carbon from (select t4.user_id,t4.day_sum,t4.jt from (select t3.user_id,t3.day_sum,t3.jt,
datediff(t3.jt,t3.qt) jt_qt_diff,
datediff(t3.jt,t3.zt) jt_zt_diff,
datediff(t3.jt,t3.mt) jt_mt_diff,
datediff(t3.jt,t3.ht) jt_ht_diff
from (select t2.user_id,t2.day_sum,t2.data_dt jt,
lag(t2.data_dt,2,'1970-01-01') over(partition by t2.user_id order by t2.data_dt) qt,
lag(t2.data_dt,1,'1970-01-01') over(partition by t2.user_id order by t2.data_dt) zt,
lead(t2.data_dt,1,'9999-99-99') over(partition by t2.user_id order by t2.data_dt) mt,
lead(t2.data_dt,2,'9999-99-99') over(partition by t2.user_id order by t2.data_dt) ht
from (select t1.user_id,t1.data_dt,sum(t1.low_carbon) day_sum from (select user_id,date_format(regexp_replace(data_dt,'/','-'),'yyyy-MM-dd') data_dt,low_carbon from user_low_carbon) t1 group by user_id,data_dt having day_sum>100) t2)t3)t4 where jt_qt_diff=2 and jt_zt_diff=1 or jt_zt_diff =1 and jt_mt_diff=-1 or jt_mt_diff=-1 and jt_ht_diff=-1
)t5 join (select user_id,date_format(regexp_replace(data_dt,'/','-'),'yyyy-MM-dd') data_dt,low_carbon from user_low_carbon)t6 on t5.user_id=t6.user_id and t5.jt=t6.data_dt;思路二:
select t6.user_id,t6.data_dt,t7.low_carbon,t6.lx_day from (select t5.user_id,t5.data_dt,t5.lx_day from(select t4.user_id,t4.data_dt,count(t4.lx_data) over(partition by t4.user_id,t4.lx_data) lx_day from (select t3.user_id,t3.data_dt,date_sub(t3.data_dt,t3.rn) lx_data from (select t2.user_id,t2.data_dt,row_number() over(partition by t2.user_id order by t2.data_dt) rn from (select t1.user_id,t1.data_dt,sum(t1.low_carbon) day_sum from (select user_id,date_format(regexp_replace(data_dt,'/','-'),'yyyy-MM-dd') data_dt,low_carbon from user_low_carbon) t1 group by user_id,data_dt having day_sum>=100) t2)t3)t4)t5 where t5.lx_day >=3)t6 join (select user_id,date_format(regexp_replace(data_dt,'/','-'),'yyyy-MM-dd') data_dt,low_carbon from user_low_carbon) t7 on t6.user_id=t7.user_id and t6.data_dt=t7.data_dt;提供的数据说明:
user_low_carbon:u_001 2017/1/1 10
u_001 2017/1/2 150
u_001 2017/1/2 110
u_001 2017/1/2 10
u_001 2017/1/4 50
u_001 2017/1/4 10
u_001 2017/1/6 45
u_001 2017/1/6 90
u_002 2017/1/1 10
u_002 2017/1/2 150
u_002 2017/1/2 70
u_002 2017/1/3 30
u_002 2017/1/3 80
u_002 2017/1/4 150
u_002 2017/1/5 101
u_002 2017/1/6 68
u_003 2017/1/1 20
u_003 2017/1/2 10
u_003 2017/1/2 150
u_003 2017/1/3 160
u_003 2017/1/4 20
u_003 2017/1/5 120
u_003 2017/1/6 20
plant_carbon:
p001 梭梭树 17
p002 沙柳 19
p003 樟子树 146
p004 胡杨 215创建表:
create table user_low_carbon(user_id String,data_dt String,low_carbon int) row format delimited fields terminated by '\t';
create table plant_carbon(plant_id string,plant_name String,low_carbon int) row format delimited fields terminated by '\t';加载数据:
load data local inpath "/opt/module/hive/datas/user_low_carbon.txt" into table user_low_carbon;
load data local inpath "/opt/module/hive/datas/plant_carbon.txt" into table plant_carbon;设置本地模式:
set hive.exec.mode.local.auto=true;19、Hive 实战
1. 需求描述
统计硅谷影音视频网站的常规指标,各种TopN指标:
-- 统计视频观看数Top10
-- 统计视频类别热度Top10
-- 统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
-- 统计视频观看数Top50所关联视频的所属类别Rank
-- 统计每个类别中的视频热度Top10,以Music为例
-- 统计每个类别视频观看数Top10
-- 统计上传视频最多的用户Top10以及他们上传的视频观看次数在前20的视频
2. 数据结构
1)视频表
| 字段 | 备注 | 详细描述 |
| videoId | 视频唯一id(String) | 11位字符串 |
| uploader | 视频上传者(String) | 上传视频的用户名String |
| age | 视频年龄(int) | 视频在平台上的整数天 |
| category | 视频类别(Array<String>) | 上传视频指定的视频分类 |
| length | 视频长度(Int) | 整形数字标识的视频长度 |
| views | 观看次数(Int) | 视频被浏览的次数 |
| rate | 视频评分(Double) | 满分5分 |
| Ratings | 流量(Int) | 视频的流量,整型数字 |
| conments | 评论数(Int) | 一个视频的整数评论数 |
| relatedId | 相关视频id(Array<String>) | 相关视频的id,最多20个 |
2)用户表
| 字段 | 备注 | 字段类型 |
| uploader | 上传者用户名 | string |
| videos | 上传视频数 | int |
| friends | 朋友数量 | int |
3. 准备工作
1)ETL
通过观察原始数据形式,可以发现,视频可以有多个所属分类,每个所属分类用&符号分割,且分割的两边有空格字符,同时相关视频也是可以有多个元素,多个相关视频又用“\t”进行分割。为了分析数据时方便对存在多个子元素的数据进行操作,我们首先进行数据重组清洗操作。即:将所有的类别用“&”分割,同时去掉两边空格,多个相关视频id也使用“&”进行分割。
ETL之封装工具类:
public class ETLUtil {
/**
* 数据清洗方法
*/
public static String etlData(String srcData){
StringBuffer resultData = new StringBuffer();
//1. 先将数据通过\t 切割
String[] datas = srcData.split("\t");
//2. 判断长度是否小于9
if(datas.length <9){
return null ;
}
//3. 将数据中的视频类别的空格去掉
datas[3]=datas[3].replaceAll(" ","");
//4. 将数据中的关联视频id通过&拼接
for (int i = 0; i < datas.length; i++) {
if(i < 9){
//4.1 没有关联视频的情况
if(i == datas.length-1){
resultData.append(datas[i]);
}else{
resultData.append(datas[i]).append("\t");
}
}else{
//4.2 有关联视频的情况
if(i == datas.length-1){
resultData.append(datas[i]);
}else{
resultData.append(datas[i]).append("&");
}
}
}
return resultData.toString();
}
} ETL之Mapper:
/**
* 清洗的原始数据
* 清洗规则
* 1. 将数据长度小于9的清洗掉
* 2. 将数据中的视频类别中间的空格去掉 People & Blogs
* 3. 将数据中的关联视频id通过&符号拼接
*/
public class EtlMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
private Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//清洗
String resultData = ETLUtil.etlData(line);
if(resultData != null) {
//写出
k.set(resultData);
context.write(k,NullWritable.get());
}
}
}ETL之Driver:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EtlDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(EtlDriver.class);
job.setMapperClass(EtlMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
} 将ETL程序打包为etl.jar 并上传到Linux的 /opt/module/hive/datas 目录下。
上传原始数据到HDFS:
[yyds@hadoop102 datas] pwd
/opt/module/hive/datas
[yyds@hadoop102 datas] hadoop fs -mkdir -p /gulivideo/video
[yyds@hadoop102 datas] hadoop fs -mkdir -p /gulivideo/user
[yyds@hadoop102 datas] hadoop fs -put gulivideo/user/user.txt /gulivideo/user
[yyds@hadoop102 datas] hadoop fs -put gulivideo/video/*.txt /gulivideo/videoETL数据:
[yyds@hadoop102 datas] hadoop jar etl.jar com.yyds.hive.etl.EtlDriver /gulivideo/video /gulivideo/video/output2)准备表
需要准备的表:
创建原始数据表:gulivideo_ori,gulivideo_user_ori,
创建最终表:gulivideo_orc,gulivideo_user_orc
创建原始数据表:
gulivideo_ori:
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as textfile;创建原始数据表: gulivideo_user_ori:
create table gulivideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as textfile;创建orc存储格式带snappy压缩的表:
gulivideo_orc:
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
stored as orc
tblproperties("orc.compress"="SNAPPY");gulivideo_user_orc:
create table gulivideo_user_orc(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as orc
tblproperties("orc.compress"="SNAPPY");向ori表插入数据:
load data inpath "/gulivideo/video/output" into table gulivideo_ori;
load data inpath "/gulivideo/user" into table gulivideo_user_ori;向orc表插入数据:
insert into table gulivideo_orc select * from gulivideo_ori;
insert into table gulivideo_user_orc select * from gulivideo_user_ori;3)安装Tez引擎(了解)
Tez是一个Hive的运行引擎,性能优于MR。为什么优于MR呢?看下。

用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS。
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
将tez安装包拷贝到集群,并解压tar包:
[yyds@hadoop102 software]$ mkdir /opt/module/tez
[yyds@hadoop102 software]$ tar -zxvf /opt/software/tez-0.10.1-SNAPSHOT-minimal.tar.gz -C /opt/module/tez上传tez依赖到HDFS:
[yyds@hadoop102 software]$ hadoop fs -mkdir /tez
[yyds@hadoop102 software]$ hadoop fs -put /opt/software/tez-0.10.1-SNAPSHOT.tar.gz /tez新建tez-site.xml:
[yyds@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/tez-site.xml添加如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1-SNAPSHOT.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>修改Hadoop环境变量:
[yyds@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/shellprofile.d/tez.sh添加Tez的Jar包相关信息:
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after
hadoop_add_classpath "/opt/module/tez/*" after
hadoop_add_classpath "/opt/module/tez/lib/*" after
}修改Hive的计算引擎:
[yyds@hadoop102 software]$ vim $HIVE_HOME/conf/hive-site.xml添加:
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>解决日志Jar包冲突:
[yyds@hadoop102 software]$ rm /opt/module/tez/lib/slf4j-log4j12-1.7.10.jar4. 业务分析
1)统计视频观看数Top10
思路:使用order by按照views字段做一个全局排序即可,同时我们设置只显示前10条。
最终代码:
SELECT
videoId,
views
FROM
gulivideo_orc
ORDER BY
views DESC
LIMIT 10;2)统计视频类别热度Top10
思路:
(1)即统计每个类别有多少个视频,显示出包含视频最多的前10个类别。
(2)我们需要按照类别group by聚合,然后count组内的videoId个数即可。
(3)因为当前表结构为:一个视频对应一个或多个类别。所以如果要group by类别,需要先将类别进行列转行(展开),然后再进行count即可。
(4)最后按照热度排序,显示前10条。
最终代码:
SELECT
t1.category_name ,
COUNT(t1.videoId) hot
FROM
(
SELECT
videoId,
category_name
FROM
gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
) t1
GROUP BY
t1.category_name
ORDER BY
hot
DESC
LIMIT 103)统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
思路:
(1)先找到观看数最高的20个视频所属条目的所有信息,降序排列
(2)把这20条信息中的category分裂出来(列转行)
(3)最后查询视频分类名称和该分类下有多少个Top20的视频
最终代码:
SELECT
t2.category_name,
COUNT(t2.videoId) video_sum
FROM
(
SELECT
t1.videoId,
category_name
FROM
(
SELECT
videoId,
views ,
category
FROM
gulivideo_orc
ORDER BY
views
DESC
LIMIT 20
) t1
lateral VIEW explode(t1.category) t1_tmp AS category_name
) t2
GROUP BY t2.category_name4)统计视频观看数Top50所关联视频的所属类别排序
代码:
SELECT
t6.category_name,
t6.video_sum,
rank() over(ORDER BY t6.video_sum DESC ) rk
FROM
(
SELECT
t5.category_name,
COUNT(t5.relatedid_id) video_sum
FROM
(
SELECT
t4.relatedid_id,
category_name
FROM
(
SELECT
t2.relatedid_id ,
t3.category
FROM
(
SELECT
relatedid_id
FROM
(
SELECT
videoId,
views,
relatedid
FROM
gulivideo_orc
ORDER BY
views
DESC
LIMIT 50
)t1
lateral VIEW explode(t1.relatedid) t1_tmp AS relatedid_id
)t2
JOIN
gulivideo_orc t3
ON
t2.relatedid_id = t3.videoId
) t4
lateral VIEW explode(t4.category) t4_tmp AS category_name
) t5
GROUP BY
t5.category_name
ORDER BY
video_sum
DESC
) t65)统计每个类别中的视频热度Top10,以Music为例
思路:
(1)要想统计Music类别中的视频热度Top10,需要先找到Music类别,那么就需要将category展开,所以可以创建一张表用于存放categoryId展开的数据。
(2)向category展开的表中插入数据。
(3)统计对应类别(Music)中的视频热度。
统计Music类别的Top10(也可以统计其他)
SELECT
t1.videoId,
t1.views,
t1.category_name
FROM
(
SELECT
videoId,
views,
category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
WHERE
t1.category_name = "Music"
ORDER BY
t1.views
DESC
LIMIT 106)统计每个类别视频观看数Top10
最终代码:
SELECT
t2.videoId,
t2.views,
t2.category_name,
t2.rk
FROM
(
SELECT
t1.videoId,
t1.views,
t1.category_name,
rank() over(PARTITION BY t1.category_name ORDER BY t1.views DESC ) rk
FROM
(
SELECT
videoId,
views,
category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
)t2
WHERE t2.rk <=107)统计上传视频最多的用户Top10以及他们上传的视频观看次数在前20的视频
思路:
(1)求出上传视频最多的10个用户
(2)关联gulivideo_orc表,求出这10个用户上传的所有的视频,按照观看数取前20
最终代码:
SELECT
t2.videoId,
t2.views,
t2.uploader
FROM
(
SELECT
uploader,
videos
FROM gulivideo_user_orc
ORDER BY
videos
DESC
LIMIT 10
) t1
JOIN gulivideo_orc t2
ON t1.uploader = t2.uploader
ORDER BY
t2.views
DESC
LIMIT 2020、常见错误及解决方案
1. 如果更换Tez引擎后,执行任务卡住,可以尝试调节容量调度器的资源调度策略
将$HADOOP_HOME/etc/hadoop/capacity-scheduler.xml文件中的:
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>改成:
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>2. 连接不上mysql数据库
(1)导错驱动包,应该把mysql-connector-java-5.1.27-bin.jar导入/opt/module/hive/lib的不是这个包。错把mysql-connector-java-5.1.27.tar.gz导入hive/lib包下。
(2)修改user表中的主机名称没有都修改为%,而是修改为localhost
3. hive默认的输入格式处理是CombineHiveInputFormat,会对小文件进行合并
hive (default)> set hive.input.format;
hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat可以采用HiveInputFormat就会根据分区数输出相应的文件。
hive (default)> set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;4. 不能执行mapreduce程序
可能是hadoop的yarn没开启。
5. 启动mysql服务时,报MySQL server PID file could not be found! 异常
在/var/lock/subsys/mysql路径下创建hadoop102.pid,并在文件中添加内容:4396。
6. 报service mysql status MySQL is not running, but lock file (/var/lock/subsys/mysql[失败])异常。
解决方案:在/var/lib/mysql 目录下创建: -rw-rw----. 1 mysql mysql 5 12月 22 16:41 hadoop102.pid 文件,并修改权限为 777。
7. JVM堆内存溢出
描述:java.lang.OutOfMemoryError: Java heap space
解决:在yarn-site.xml中加入如下代码
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>8. 虚拟内存限制
在yarn-site.xml中添加如下配置:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>二、Flume数据采集
1、Flume简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。

Flume组成架构如下图所示:

1)Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent主要有3个部分组成,Source、Channel、Sink。
2)Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、 taildir 、sequence generator、syslog、http、legacy。
3)Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
4)Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
5)Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。

2、Flume安装部署
1. 安装地址
(1)Flume官网地址:Welcome to Apache Flume — Apache Flume
(2)文档查看地址:Flume 1.10.1 User Guide — Apache Flume
(3)下载地址:Index of /dist/flume
2. 安装部署
(1)将apache-flume-1.9.0-bin.tar.gz上传到linux的/opt/software目录下
(2)解压apache-flume-1.9.0-bin.tar.gz到/opt/module/目录下
[yyds@hadoop102 software]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/(3)修改apache-flume-1.9.0-bin的名称为flume
[yyds@hadoop102 module]$ mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume(4)将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
[yyds@hadoop102 lib]$ rm /opt/module/flume/lib/guava-11.0.2.jar3、Flume使用案例
1. 监控端口数据官方案例
1)案例需求:
使用Flume监听一个端口,收集该端口数据,并打印到控制台。
2)需求分析
监听数据端口案例分析:

3)实现步骤:
(1)安装netcat工具
[yyds@hadoop102 software]$ sudo yum install -y nc(2)判断44444端口是否被占用
[yyds@hadoop102 flume-telnet]$ sudo netstat -nlp | grep 44444(3)创建Flume Agent配置文件flume-netcat-logger.conf
(4)在flume目录下创建job文件夹并进入job文件夹
[yyds@hadoop102 flume]$ mkdir job
[yyds@hadoop102 flume]$ cd job/(5)在job文件夹下创建Flume Agent配置文件flume-netcat-logger.conf
[yyds@hadoop102 job]$ vim flume-netcat-logger.conf(6)在flume-netcat-logger.conf文件中添加如下内容
添加内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1详情参考官方手册:Flume 1.10.1 User Guide — Apache Flume
配置文件解析:

(7)先开启flume监听端口
第一种写法:
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console第二种写法:
[yyds@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console参数说明:
--conf/-c:表示配置文件存储在conf/目录
--name/-n:表示给agent起名为a1
--conf-file/-f:flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。
-Dflume.root.logger=INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。(8)使用netcat工具向本机的44444端口发送内容
[yyds@hadoop102 ~]$ nc localhost 44444
hello
yyds(9)在Flume监听页面观察接收数据情况

思考:nc hadoop102 44444,flume能否接收到?
2. 实时监控单个追加文件
1)案例需求:实时监控Hive日志,并上传到HDFS中
2)需求分析
实时读取本地文件到HDFS案例:

3)实现步骤:
(1)Flume要想将数据输出到HDFS,依赖Hadoop相关jar包
检查/etc/profile.d/my_env.sh文件,确认Hadoop和Java环境变量配置正确:
JAVA_HOME=/opt/module/jdk1.8.0_212
HADOOP_HOME=/opt/module/ha/hadoop-3.1.3
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH JAVA_HOME HADOOP_HOME(2)创建flume-file-hdfs.conf文件
创建文件:
[yyds@hadoop102 job]$ vim flume-file-hdfs.conf注:要想读取Linux系统中的文件,就得按照Linux命令的规则执行命令。由于Hive日志在Linux系统中所以读取文件的类型选择:exec即execute执行的意思。表示执行Linux命令来读取文件。
添加如下内容:
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:8020/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2注意:
对于所有与时间相关的转义序列,Event Header中必须存在以 “timestamp”的key(除非hdfs.useLocalTimeStamp设置为true,此方法会使用TimestampInterceptor自动添加timestamp)。
a3.sinks.k3.hdfs.useLocalTimeStamp = true配置文件解析:

(3)运行Flume
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf(4)开启Hadoop和Hive并操作Hive产生日志
[yyds@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[yyds@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[yyds@hadoop102 hive]$ bin/hive
hive (default)>(5)在HDFS上查看文件。
3. 实时监控目录下多个新文件
1)案例需求:使用Flume监听整个目录的文件,并上传至HDFS
2)需求分析
实时读取目录文件到HDFS案例:

3)实现步骤:
(1)创建配置文件flume-dir-hdfs.conf
创建一个文件:
[yyds@hadoop102 job]$ vim flume-dir-hdfs.conf添加如下内容:
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3配置文件解析:

(2)启动监控文件夹命令
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf说明:在使用Spooling Directory Source时,不要在监控目录中创建并持续修改文件;上传完成的文件会以.COMPLETED结尾;被监控文件夹每500毫秒扫描一次文件变动。
(3)向upload文件夹中添加文件
在/opt/module/flume目录下创建upload文件夹:
[yyds@hadoop102 flume]$ mkdir upload向upload文件夹中添加文件:
[yyds@hadoop102 upload]$ touch yyds.txt
[yyds@hadoop102 upload]$ touch yyds.tmp
[yyds@hadoop102 upload]$ touch yyds.log(4)查看HDFS上的数据
4. 实时监控目录下的多个追加文件
Exec source适用于监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;而Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传。
1)案例需求:使用Flume监听整个目录的实时追加文件,并上传至HDFS
2)需求分析
实时读取目录文件到HDFS:

3)实现步骤:
(1)创建配置文件flume-taildir-hdfs.conf
创建一个文件:
[yyds@hadoop102 job]$ vim flume-taildir-hdfs.conf添加如下内容:
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume/tail_dir.json
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.*log.*
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:8020/flume/upload2/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3配置文件解析:

(2)启动监控文件夹命令
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-taildir-hdfs.conf(3)向files文件夹中追加内容
在/opt/module/flume目录下创建files文件夹:
[yyds@hadoop102 flume]$ mkdir files向upload文件夹中添加文件:
[yyds@hadoop102 files]$ echo hello >> file1.txt
[yyds@hadoop102 files]$ echo yyds >> file2.txt(4)查看HDFS上的数据
Taildir说明:
Taildir Source维护了一个json格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File的格式如下:
{"inode":2496272,"pos":12,"file":"/opt/module/flume/files/file1.txt"}
{"inode":2496275,"pos":12,"file":"/opt/module/flume/files/file2.txt"}注:Linux中储存文件元数据的区域就叫做inode,每个inode都有一个号码,操作系统用inode号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。
4、Flume进阶知识
1. Flume事务

2. Flume Agent内部原理

重要组件:
1)ChannelSelector
ChannelSelector的作用就是选出Event将要被发往哪个Channel。其共有两种类型,分别是Replicating(复制)和Multiplexing(多路复用)。
ReplicatingSelector会将同一个Event发往所有的Channel,Multiplexing会根据相应的原则,将不同的Event发往不同的Channel。
2)SinkProcessor
SinkProcessor共有三种类型,分别是DefaultSinkProcessor、LoadBalancingSinkProcessor和FailoverSinkProcessor
DefaultSinkProcessor对应的是单个的Sink,LoadBalancingSinkProcessor和FailoverSinkProcessor对应的是Sink Group,LoadBalancingSinkProcessor可以实现负载均衡的功能,FailoverSinkProcessor可以错误恢复的功能。
3. Flume拓扑结构
1)简单串联
Flume Agent连接:

这种模式是将多个flume顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的flume数量, flume数量过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。
2)复制和多路复用
单source,多channel、sink:

Flume支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel中,或者将不同数据分发到不同的channel中,sink可以选择传送到不同的目的地。
3)负载均衡和故障转移
Flume负载均衡或故障转移:

Flume支持使用将多个sink逻辑上分到一个sink组,sink组配合不同的SinkProcessor可以实现负载均衡和错误恢复的功能。
4)聚合
Flume Agent聚合:

这种模式是我们最常见的,也非常实用,日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用flume的这种组合方式能很好的解决这一问题,每台服务器部署一个flume采集日志,传送到一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase等,进行日志分析。
4. Flume企业开发案例
1)复制和多路复用
案例需求:
使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3负责输出到Local FileSystem。
需求分析:
单数据源多出口案例(选择器)

实现步骤:
(1)准备工作
在/opt/module/flume/job目录下创建group1文件夹:
[yyds@hadoop102 job]$ cd group1/在/opt/module/datas/目录下创建flume3文件夹:
[yyds@hadoop102 datas]$ mkdir flume3(2)创建flume-file-flume.conf
配置1个接收日志文件的source和两个channel、两个sink,分别输送给flume-flume-hdfs和flume-flume-dir。
编辑配置文件:
[yyds@hadoop102 group1]$ vim flume-file-flume.conf添加如下内容:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给所有channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
# sink端的avro是一个数据发送者
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2(3)创建flume-flume-hdfs.conf
配置上级Flume输出的Source,输出是到HDFS的Sink。
编辑配置文件:
[yyds@hadoop102 group1]$ vim flume-flume-hdfs.conf添加如下内容:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
# source端的avro是一个数据接收服务
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop102:8020/flume2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k1.hdfs.rollCount = 0
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1(4)创建flume-flume-dir.conf
配置上级Flume输出的Source,输出是到本地目录的Sink。
编辑配置文件:
[yyds@hadoop102 group1]$ vim flume-flume-dir.conf添加如下内容:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/data/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。
(5)执行配置文件
分别启动对应的flume进程:flume-flume-dir,flume-flume-hdfs,flume-file-flume。
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf(6)启动Hadoop和Hive
[yyds@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[yyds@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[yyds@hadoop102 hive]$ bin/hive
hive (default)>(7)检查HDFS上数据

(8)检查/opt/module/datas/flume3目录中数据
[yyds@hadoop102 flume3]$ ll
总用量 8
-rw-rw-r--. 1 yyds yyds 5942 5月 22 00:09 1526918887550-32)负载均衡和故障转移
案例需求:
使用Flume1监控一个端口,其sink组中的sink分别对接Flume2和Flume3,采用FailoverSinkProcessor,实现故障转移的功能。
需求分析:
故障转移案例:

实现步骤:
(1)准备工作
在/opt/module/flume/job目录下创建group2文件夹:
[yyds@hadoop102 job]$ cd group2/(2)创建flume-netcat-flume.conf
配置1个netcat source和1个channel、1个sink group(2个sink),分别输送给flume-flume-console1和flume-flume-console2。
编辑配置文件:
[yyds@hadoop102 group2]$ vim flume-netcat-flume.conf添加如下内容:
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1(3)创建flume-flume-console1.conf
配置上级Flume输出的Source,输出是到本地控制台。
编辑配置文件:
[yyds@hadoop102 group2]$ vim flume-flume-console1.conf添加如下内容:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1(4)创建flume-flume-console2.conf
配置上级Flume输出的Source,输出是到本地控制台。
编辑配置文件:
[yyds@hadoop102 group2]$ vim flume-flume-console2.conf添加如下内容:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2(5)执行配置文件
分别开启对应配置文件:flume-flume-console2,flume-flume-console1,flume-netcat-flume。
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf(6)使用netcat工具向本机的44444端口发送内容
$ nc localhost 44444(7)查看Flume2及Flume3的控制台打印日志
(8)将Flume2 kill,观察Flume3的控制台打印情况。
注:使用jps -ml查看Flume进程。
3)聚合
案例需求:
hadoop102上的Flume-1监控文件/opt/module/group.log,hadoop103上的Flume-2监控某一个端口的数据流,Flume-1与Flume-2将数据发送给hadoop104上的Flume-3,Flume-3将最终数据打印到控制台。
需求分析:
多数据源汇总案例:

实现步骤:
(1)准备工作
分发Flume:
[yyds@hadoop102 module]$ xsync flume在hadoop102、hadoop103以及hadoop104的/opt/module/flume/job目录下创建一个group3文件夹。
[yyds@hadoop102 job]$ mkdir group3
[yyds@hadoop103 job]$ mkdir group3
[yyds@hadoop104 job]$ mkdir group3(2)创建flume1-logger-flume.conf
配置Source用于监控hive.log文件,配置Sink输出数据到下一级Flume。
在hadoop102上编辑配置文件:
[yyds@hadoop102 group3]$ vim flume1-logger-flume.conf 添加如下内容:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/group.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop104
a1.sinks.k1.port = 4141
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1(3)创建flume2-netcat-flume.conf
配置Source监控端口44444数据流,配置Sink数据到下一级Flume。
在hadoop103上编辑配置文件:
[yyds@hadoop102 group3]$ vim flume2-netcat-flume.conf添加如下内容:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = netcat
a2.sources.r1.bind = hadoop103
a2.sources.r1.port = 44444
# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = hadoop104
a2.sinks.k1.port = 4141
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1(4)创建flume3-flume-logger.conf
配置source用于接收flume1与flume2发送过来的数据流,最终合并后sink到控制台。
在hadoop104上编辑配置文件:
[yyds@hadoop104 group3]$ touch flume3-flume-logger.conf
[yyds@hadoop104 group3]$ vim flume3-flume-logger.conf添加如下内容:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop104
a3.sources.r1.port = 4141
# Describe the sink
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1(5)执行配置文件
分别开启对应配置文件:flume3-flume-logger.conf,flume2-netcat-flume.conf,flume1-logger-flume.conf。
[yyds@hadoop104 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group3/flume3-flume-logger.conf -Dflume.root.logger=INFO,console
[yyds@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group3/flume1-logger-flume.conf
[yyds@hadoop103 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group3/flume2-netcat-flume.conf(6)在hadoop103上向/opt/module目录下的group.log追加内容
[yyds@hadoop103 module]$ echo 'hello' > group.log(7)在hadoop102上向44444端口发送数据
[yyds@hadoop102 flume]$ telnet hadoop102 44444(8)检查hadoop104上数据

5. 自定义Interceptor
1)案例需求
使用Flume采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统。
2)需求分析
在实际的开发中,一台服务器产生的日志类型可能有很多种,不同类型的日志可能需要发送到不同的分析系统。此时会用到Flume拓扑结构中的Multiplexing结构,Multiplexing的原理是,根据event中Header的某个key的值,将不同的event发送到不同的Channel中,所以我们需要自定义一个Interceptor,为不同类型的event的Header中的key赋予不同的值。
在该案例中,我们以端口数据模拟日志,以数字(单个)和字母(单个)模拟不同类型的日志,我们需要自定义interceptor区分数字和字母,将其分别发往不同的分析系统(Channel)。
Interceptor和Multiplexing ChannelSelector案例

3)实现步骤
(1)创建一个maven项目,并引入以下依赖。
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>(2)定义CustomInterceptor类并实现Interceptor接口。
package com.yyds.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
public class CustomInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
if (body[0] < 'z' && body[0] > 'a') {
event.getHeaders().put("type", "letter");
} else if (body[0] > '0' && body[0] < '9') {
event.getHeaders().put("type", "number");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new CustomInterceptor();
}
@Override
public void configure(Context context) {
}
}
}(3)编辑flume配置文件
为hadoop102上的Flume1配置1个netcat source,1个sink group(2个avro sink),并配置相应的ChannelSelector和interceptor。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.yyds.flume.interceptor.CustomInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = type
a1.sources.r1.selector.mapping.letter = c1
a1.sources.r1.selector.mapping.number = c2
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop103
a1.sinks.k1.port = 4141
a1.sinks.k2.type=avro
a1.sinks.k2.hostname = hadoop104
a1.sinks.k2.port = 4242
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Use a channel which buffers events in memory
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2为hadoop103上的Flume4配置一个avro source和一个logger sink:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop103
a1.sources.r1.port = 4141
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1为hadoop104上的Flume3配置一个avro source和一个logger sink:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop104
a1.sources.r1.port = 4242
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1(4)分别在hadoop102,hadoop103,hadoop104上启动flume进程,注意先后顺序。
(5)在hadoop102使用netcat向localhost:44444发送字母和数字。
(6)观察hadoop103和hadoop104打印的日志。
6. 自定义Source
1)介绍
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。官方提供的source类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些source。
官方也提供了自定义source的接口:
https://flume.apache.org/FlumeDeveloperGuide.html#source
根据官方说明自定义MySource需要继承AbstractSource类并实现Configurable和PollableSource接口。
实现相应方法:
getBackOffSleepIncrement() //backoff 步长
getMaxBackOffSleepInterval()//backoff 最长时间
configure(Context context)//初始化context(读取配置文件内容)
process()//获取数据封装成event并写入channel,这个方法将被循环调用。使用场景:读取MySQL数据或者其他文件系统。
2)需求
使用flume接收数据,并给每条数据添加前缀,输出到控制台。前缀可从flume配置文件中配置。
自定义Source需求:

3)自定义Source需求分析

4)编码
(1)导入pom依赖
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>(2)编写代码
package com.yyds;
import org.apache.flume.Context;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
import java.util.HashMap;
public class MySource extends AbstractSource implements Configurable, PollableSource {
//定义配置文件将来要读取的字段
private Long delay;
private String field;
//初始化配置信息
@Override
public void configure(Context context) {
delay = context.getLong("delay");
field = context.getString("field", "Hello!");
}
@Override
public Status process() throws EventDeliveryException {
try {
//创建事件头信息
HashMap<String, String> hearderMap = new HashMap<>();
//创建事件
SimpleEvent event = new SimpleEvent();
//循环封装事件
for (int i = 0; i < 5; i++) {
//给事件设置头信息
event.setHeaders(hearderMap);
//给事件设置内容
event.setBody((field + i).getBytes());
//将事件写入channel
getChannelProcessor().processEvent(event);
Thread.sleep(delay);
}
} catch (Exception e) {
e.printStackTrace();
return Status.BACKOFF;
}
return Status.READY;
}
@Override
public long getBackOffSleepIncrement() {
return 0;
}
@Override
public long getMaxBackOffSleepInterval() {
return 0;
}
}5)测试
(1)打包
将写好的代码打包,并放到flume的lib目录(/opt/module/flume)下。
(2)配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = com.yyds.MySource
a1.sources.r1.delay = 1000
#a1.sources.r1.field = yyds
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1(3)开启任务
[yyds@hadoop102 flume]$ pwd
/opt/module/flume
[yyds@hadoop102 flume]$ bin/flume-ng agent -c conf/ -f job/mysource.conf -n a1 -Dflume.root.logger=INFO,console(4)结果展示

7. 自定义Sink
1)介绍
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。官方提供的Sink类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些Sink。
官方也提供了自定义sink的接口:
https://flume.apache.org/FlumeDeveloperGuide.html#sink根据官方说明自定义MySink需要继承AbstractSink类并实现Configurable接口。
实现相应方法:
configure(Context context)//初始化context(读取配置文件内容)
process()//从Channel读取获取数据(event),这个方法将被循环调用。使用场景:读取Channel数据写入MySQL或者其他文件系统。
2)需求
使用flume接收数据,并在Sink端给每条数据添加前缀和后缀,输出到控制台。前后缀可在flume任务配置文件中配置。
流程分析:

3)编码
package com.yyds;
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MySink extends AbstractSink implements Configurable {
//创建Logger对象
private static final Logger LOG = LoggerFactory.getLogger(AbstractSink.class);
private String prefix;
private String suffix;
@Override
public Status process() throws EventDeliveryException {
//声明返回值状态信息
Status status;
//获取当前Sink绑定的Channel
Channel ch = getChannel();
//获取事务
Transaction txn = ch.getTransaction();
//声明事件
Event event;
//开启事务
txn.begin();
//读取Channel中的事件,直到读取到事件结束循环
while (true) {
event = ch.take();
if (event != null) {
break;
}
}
try {
//处理事件(打印)
LOG.info(prefix + new String(event.getBody()) + suffix);
//事务提交
txn.commit();
status = Status.READY;
} catch (Exception e) {
//遇到异常,事务回滚
txn.rollback();
status = Status.BACKOFF;
} finally {
//关闭事务
txn.close();
}
return status;
}
@Override
public void configure(Context context) {
//读取配置文件内容,有默认值
prefix = context.getString("prefix", "hello:");
//读取配置文件内容,无默认值
suffix = context.getString("suffix");
}
}4)测试
(1)打包
将写好的代码打包,并放到flume的lib目录(/opt/module/flume)下。
(2)配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = com.yyds.MySink
#a1.sinks.k1.prefix = yyds:
a1.sinks.k1.suffix = :yyds
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1(3)开启任务
[yyds@hadoop102 flume]$ bin/flume-ng agent -c conf/ -f job/mysink.conf -n a1 -Dflume.root.logger=INFO,console
[yyds@hadoop102 ~]$ nc localhost 44444
hello
OK
yyds
OK8. Flume数据流监控
1)Ganglia的安装与部署
Ganglia由gmond、gmetad和gweb三部分组成。
gmond(Ganglia Monitoring Daemon)是一种轻量级服务,安装在每台需要收集指标数据的节点主机上。使用gmond,你可以很容易收集很多系统指标数据,如CPU、内存、磁盘、网络和活跃进程的数据等。
gmetad(Ganglia Meta Daemon)整合所有信息,并将其以RRD格式存储至磁盘的服务。
gweb(Ganglia Web)Ganglia可视化工具,gweb是一种利用浏览器显示gmetad所存储数据的PHP前端。在Web界面中以图表方式展现集群的运行状态下收集的多种不同指标数据。
安装ganglia:
(1)规划
hadoop102: gweb gmetad gmod
hadoop103: gmod
hadoop104: gmod(2)在102 103 104分别安装epel-release
[yyds@hadoop102 flume]$ sudo yum -y install epel-release(3)在102 安装
[yyds@hadoop102 flume]$ sudo yum -y install ganglia-gmetad
[yyds@hadoop102 flume]$ sudo yum -y install ganglia-web
[yyds@hadoop102 flume]$ sudo yum -y install ganglia-gmond(4)在103 和 104 安装
[yyds@hadoop102 flume]$ sudo yum -y install ganglia-gmond在102修改配置文件/etc/httpd/conf.d/ganglia.conf:
[yyds@hadoop102 flume]$ sudo vim /etc/httpd/conf.d/ganglia.conf修改为红颜色的配置:
# Ganglia monitoring system php web frontend
#
Alias /ganglia /usr/share/ganglia
<Location /ganglia>
# Require local
# 通过windows访问ganglia,需要配置Linux对应的主机(windows)ip地址
Require ip 192.168.202.1
# Require ip 10.1.2.3
# Require host example.org
</Location>在102修改配置文件/etc/ganglia/gmetad.conf:
[yyds@hadoop102 flume]$ sudo vim /etc/ganglia/gmetad.conf修改为:
data_source "my cluster" hadoop102在102 103 104修改配置文件/etc/ganglia/gmond.conf:
[yyds@hadoop102 flume]$ sudo vim /etc/ganglia/gmond.conf
修改为:
cluster {
name = "my cluster"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
# mcast_join = 239.2.11.71
# 数据发送给hadoop102
host = hadoop102
port = 8649
ttl = 1
}
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
# 接收来自任意连接的数据
bind = 0.0.0.0
retry_bind = true
# Size of the UDP buffer. If you are handling lots of metrics you really
# should bump it up to e.g. 10MB or even higher.
# buffer = 10485760
}在102修改配置文件/etc/selinux/config:
[yyds@hadoop102 flume]$ sudo vim /etc/selinux/config
修改为:
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted提示:selinux本次生效关闭必须重启,如果此时不想重启,可以临时生效之。
[yyds@hadoop102 flume]$ sudo setenforce 0启动ganglia:
(1)在102 103 104 启动
[yyds@hadoop102 flume]$ sudo systemctl start gmond(2)在102 启动
[yyds@hadoop102 flume]$ sudo systemctl start httpd
[yyds@hadoop102 flume]$ sudo systemctl start gmetad打开网页浏览ganglia页面:http://hadoop102/ganglia
提示:如果完成以上操作依然出现权限不足错误,请修改/var/lib/ganglia目录的权限。
[yyds@hadoop102 flume]$ sudo chmod -R 777 /var/lib/ganglia2)操作Flume测试监控
(1)启动Flume任务
[yyds@hadoop102 flume]$ bin/flume-ng agent \
-c conf/ \
-n a1 \
-f datas/netcat-flume-logger.conf \
-Dflume.root.logger=INFO,console \
-Dflume.monitoring.type=ganglia \
-Dflume.monitoring.hosts=hadoop202:8649(2)发送数据观察ganglia监测图
[yyds@hadoop102 flume]$ nc localhost 44444样式如图:

图例说明:
| 字段(图表名称) | 字段含义 |
| EventPutAttemptCount | source尝试写入channel的事件总数量 |
| EventPutSuccessCount | 成功写入channel且提交的事件总数量 |
| EventTakeAttemptCount | sink尝试从channel拉取事件的总数量。 |
| EventTakeSuccessCount | sink成功读取的事件的总数量 |
| StartTime | channel启动的时间(毫秒) |
| StopTime | channel停止的时间(毫秒) |
| ChannelSize | 目前channel中事件的总数量 |
| ChannelFillPercentage | channel占用百分比 |
| ChannelCapacity | channel的容量 |
5、Flume企业面试
1. 你是如何实现Flume数据传输的监控的?
使用第三方框架Ganglia实时监控Flume。
2. Flume的Source,Sink,Channel的作用?你们Source是什么类型?
1)作用
(1)Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy
(2)Channel组件对采集到的数据进行缓存,可以存放在Memory或File中。
(3)Sink组件是用于把数据发送到目的地的组件,目的地包括Hdfs、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。
2)我公司采用的Source类型为:
(1)监控后台日志:exec
(2)监控后台产生日志的端口:netcat
3. Flume的Channel Selectors

4. Flume参数调优
1)Source
增加Source个(使用Tair Dir Source时可增加FileGroups个数)可以增大Source的读取数据的能力。例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个Source 以保证Source有足够的能力获取到新产生的数据。
batchSize参数决定Source一次批量运输到Channel的event条数,适当调大这个参数可以提高Source搬运Event到Channel时的性能。
2)Channel
type 选择memory时Channel的性能最好,但是如果Flume进程意外挂掉可能会丢失数据。type选择file时Channel的容错性更好,但是性能上会比memory channel差。
使用file Channel时dataDirs配置多个不同盘下的目录可以提高性能。
Capacity 参数决定Channel可容纳最大的event条数。transactionCapacity 参数决定每次Source往channel里面写的最大event条数和每次Sink从channel里面读的最大event条数。transactionCapacity需要大于Source和Sink的batchSize参数。
3)Sink
增加Sink的个数可以增加Sink消费event的能力。Sink也不是越多越好够用就行,过多的Sink会占用系统资源,造成系统资源不必要的浪费。
batchSize参数决定Sink一次批量从Channel读取的event条数,适当调大这个参数可以提高Sink从Channel搬出event的性能。
5. Flume的事务机制
Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务分别负责从Soucrce到Channel,以及从Channel到Sink的事件传递。比如spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到Channel且提交成功,那么Soucrce就将该文件标记为完成。同理,事务以类似的方式处理从Channel到Sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到Channel中,等待重新传递。
6. Flume采集数据会丢失吗?
根据Flume的架构原理,Flume是不可能丢失数据的,其内部有完善的事务机制,Source到Channel是事务性的,Channel到Sink是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是Channel采用memoryChannel,agent宕机导致数据丢失,或者Channel存储数据已满,导致Source不再写入,未写入的数据丢失。
Flume不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由Sink发出,但是没有接收到响应,Sink会再次发送数据,此时可能会导致数据的重复。
三、Zookeeper分布式注册中心
1、Zookeeper简介
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
Zookeeper从设计模式角度来理解,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生了变化,Zookeeper就负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookeeper = 文件系统 + 通知机制。
Zookeeper工作机制:

Zookeeper特点:

Zookeeper数据结构:

Zookeeper应用场景:
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
统一命名服务:

统一配置管理:

统一集群管理:

服务器动态上下线:

软负载均衡:

2、Zookeeper下载安装
1. Zookeeper下载
1)官网首页
Apache ZooKeeper
2)下载截图


2. Zookeeper安装
1)本地模式安装部署
(1)安装Jdk
(2)拷贝Zookeeper安装包到Linux系统下
(3)解压到指定目录
[yyds@hadoop102 software]$ tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/2)配置修改
(1)将/opt/module/zookeeper-3.5.7/conf这个路径下的zoo_sample.cfg修改为zoo.cfg:
[yyds@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg(2)打开zoo.cfg文件,修改dataDir路径:
[yyds@hadoop102 zookeeper-3.5.7]$ vim zoo.cfg修改如下内容:
dataDir=/opt/module/zookeeper-3.5.7/zkData(3)在/opt/module/zookeeper-3.5.7/这个目录上创建zkData文件夹:
[yyds@hadoop102 zookeeper-3.5.7]$ mkdir zkData3)操作Zookeeper
(1)启动Zookeeper
[yyds@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start(2)查看进程是否启动
[yyds@hadoop102 zookeeper-3.5.7]$ jps
4020 Jps
4001 QuorumPeerMain(3)查看状态:
[yyds@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: standalone(4)启动客户端:
[yyds@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh(5)退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit(6)停止Zookeeper
[yyds@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh stop3. 配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
1)tickTime =2000:通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
2)initLimit =10:LF初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
3)syncLimit =5:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4)dataDir:数据文件目录+数据持久化路径
主要用于保存Zookeeper中的数据。
5)clientPort =2181:客户端连接端口
监听客户端连接的端口。
3、Zookeeper实战
1. 分布式安装部署
1)集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
2)解压安装
(1)解压Zookeeper安装包到/opt/module/目录下
[yyds@hadoop102 software]$ tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/(2)同步/opt/module/zookeeper-3.5.7目录内容到hadoop103、hadoop104
[yyds@hadoop102 module]$ xsync zookeeper-3.5.7/3)配置服务器编号
(1)在/opt/module/zookeeper-3.5.7/这个目录下创建zkData
[yyds@hadoop102 zookeeper-3.5.7]$ mkdir -p zkData(2)在/opt/module/zookeeper-3.5.7/zkData目录下创建一个myid的文件
[yyds@hadoop102 zkData]$ touch myid添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码。
(3)编辑myid文件
[yyds@hadoop102 zkData]$ vi myid文件中添加与server对应的编号:
2(4)拷贝配置好的zookeeper到其他机器上
[yyds@hadoop102 zkData]$ xsync myid并分别在hadoop103、hadoop104上修改myid文件中内容为3、4
4)配置zoo.cfg文件
(1)重命名/opt/module/zookeeper-3.5.7/conf这个目录下的zoo_sample.cfg为zoo.cfg
[yyds@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg(2)打开zoo.cfg文件
[yyds@hadoop102 conf]$ vim zoo.cfg修改数据存储路径配置:
dataDir=/opt/module/zookeeper-3.5.7/zkData增加如下配置:
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888(3)同步zoo.cfg配置文件
[yyds@hadoop102 conf]$ xsync zoo.cfg(4)配置参数解读
server.A=B:C:DA是一个数字,表示这个是第几号服务器。
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址。
C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5)集群操作
(1)分别启动Zookeeper
[yyds@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[yyds@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[yyds@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start(2)查看状态
[yyds@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
[yyds@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: leader
[yyds@hadoop104 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower2. 客户端命令行操作
| 命令基本语法 | 功能描述 |
| help | 显示所有操作命令 |
| ls path | 使用 ls 命令来查看当前znode的子节点 -w 监听子节点变化 -s 附加次级信息 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path | 获得节点的值 -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
1)启动客户端
[yyds@hadoop103 zookeeper-3.5.7]$ bin/zkCli.sh2)显示所有操作命令
[zk: localhost:2181(CONNECTED) 1] help3)查看当前znode中所包含的内容
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]4)查看当前节点详细数据
[zk: localhost:2181(CONNECTED) 1] ls -s /
[zookeeper]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 15)分别创建2个普通节点
[zk: localhost:2181(CONNECTED) 3] create /sanguo "diaochan"
Created /sanguo
[zk: localhost:2181(CONNECTED) 4] create /sanguo/shuguo "liubei"
Created /sanguo/shuguo6)获得节点的值
[zk: localhost:2181(CONNECTED) 5] get /sanguo
diaochan
[zk: localhost:2181(CONNECTED) 6] get -s /sanguo
diaochan
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000003
mtime = Wed Aug 29 00:03:23 CST 2018
pZxid = 0x100000004
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 1
[zk: localhost:2181(CONNECTED) 7]
[zk: localhost:2181(CONNECTED) 7] get -s /sanguo/shuguo
liubei
cZxid = 0x100000004
ctime = Wed Aug 29 00:04:35 CST 2018
mZxid = 0x100000004
mtime = Wed Aug 29 00:04:35 CST 2018
pZxid = 0x100000004
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 07)创建临时节点
[zk: localhost:2181(CONNECTED) 7] create -e /sanguo/wuguo "zhouyu"
Created /sanguo/wuguo(1)在当前客户端是能查看到的
[zk: localhost:2181(CONNECTED) 3] ls /sanguo
[wuguo, shuguo](2)退出当前客户端然后再重启客户端
[zk: localhost:2181(CONNECTED) 12] quit
[yyds@hadoop104 zookeeper-3.5.7]$ bin/zkCli.sh(3)再次查看根目录下短暂节点已经删除
[zk: localhost:2181(CONNECTED) 0] ls /sanguo
[shuguo]8)创建带序号的节点
(1)先创建一个普通的根节点/sanguo/weiguo
[zk: localhost:2181(CONNECTED) 1] create /sanguo/weiguo "caocao"
Created /sanguo/weiguo(2)创建带序号的节点
[zk: localhost:2181(CONNECTED) 2] create /sanguo/weiguo "caocao"
Node already exists: /sanguo/weiguo
[zk: localhost:2181(CONNECTED) 3] create -s /sanguo/weiguo "caocao"
Created /sanguo/weiguo0000000000
[zk: localhost:2181(CONNECTED) 4] create -s /sanguo/weiguo "caocao"
Created /sanguo/weiguo0000000001
[zk: localhost:2181(CONNECTED) 5] create -s /sanguo/weiguo "caocao"
Created /sanguo/weiguo0000000002
[zk: localhost:2181(CONNECTED) 6] ls /sanguo
[shuguo, weiguo, weiguo0000000000, weiguo0000000001, weiguo0000000002, wuguo]
[zk: localhost:2181(CONNECTED) 6]如果节点下原来没有子节点,序号从0开始依次递增。如果原节点下已有2个节点,则再排序时从2开始,以此类推。
9)修改节点数据值
[zk: localhost:2181(CONNECTED) 6] set /sanguo/weiguo "caopi"10)节点的值变化监听
(1)在hadoop104主机上注册监听/sanguo节点数据变化
[zk: localhost:2181(CONNECTED) 26] [zk: localhost:2181(CONNECTED) 8] get -w /sanguo(2)在hadoop103主机上修改/sanguo节点的数据
[zk: localhost:2181(CONNECTED) 1] set /sanguo "xishi"(3)观察hadoop104主机收到数据变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/sanguo11)节点的子节点变化监听(路径变化)
(1)在hadoop104主机上注册监听/sanguo节点的子节点变化
[zk: localhost:2181(CONNECTED) 1] ls -w /sanguo
[aa0000000001, server101](2)在hadoop103主机/sanguo节点上创建子节点
[zk: localhost:2181(CONNECTED) 2] create /sanguo/jin "simayi"
Created /sanguo/jin(3)观察hadoop104主机收到子节点变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/sanguo12)删除节点
[zk: localhost:2181(CONNECTED) 4] delete /sanguo/jin13)递归删除节点
[zk: localhost:2181(CONNECTED) 15] deleteall /sanguo/shuguo14)查看节点状态
[zk: localhost:2181(CONNECTED) 17] stat /sanguo
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000011
mtime = Wed Aug 29 00:21:23 CST 2018
pZxid = 0x100000014
cversion = 9
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 13. API应用
① IDEA环境搭建
1)创建一个Maven Module
2)添加pom文件
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>3)拷贝log4j.properties文件到项目根目录
需要在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n② 初始化ZooKeeper客户端
public class Zookeeper {
private String connectString;
private int sessionTimeout;
private ZooKeeper zkClient;
@Before //获取客户端对象
public void init() throws IOException {
connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
int sessionTimeout = 10000;
//参数解读 1集群连接字符串 2连接超时时间 单位:毫秒 3当前客户端默认的监控器
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
}
});
}
@After //关闭客户端对象
public void close() throws InterruptedException {
zkClient.close();
}
}③ 获取子节点列表,不监听
@Test
public void ls() throws IOException, KeeperException, InterruptedException {
//用客户端对象做各种操作
List<String> children = zkClient.getChildren("/", false);
System.out.println(children);
}④ 获取子节点列表,并监听
@Test
public void lsAndWatch() throws KeeperException, InterruptedException {
List<String> children = zkClient.getChildren("/yyds", new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event);
}
});
System.out.println(children);
//因为设置了监听,所以当前线程不能结束
Thread.sleep(Long.MAX_VALUE);
}⑤ 创建子节点
@Test
public void create() throws KeeperException, InterruptedException {
//参数解读 1节点路径 2节点存储的数据
//3节点的权限(使用Ids选个OPEN即可) 4节点类型 短暂 持久 短暂带序号 持久带序号
String path = zkClient.create("/yyds", "shanguigu".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
//创建临时节点
//String path = zkClient.create("/yyds2", "shanguigu".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println(path);
//创建临时节点的话,需要线程阻塞
//Thread.sleep(10000);
}⑥ 判断Znode是否存在
@Test
public void exist() throws Exception {
Stat stat = zkClient.exists("/yyds", false);
System.out.println(stat == null ? "not exist" : "exist");
}⑦ 获取子节点存储的数据,不监听
@Test
public void get() throws KeeperException, InterruptedException {
//判断节点是否存在
Stat stat = zkClient.exists("/yyds", false);
if (stat == null) {
System.out.println("节点不存在...");
return;
}
byte[] data = zkClient.getData("/yyds", false, stat);
System.out.println(new String(data));
}⑧ 获取子节点存储的数据,并监听
@Test
public void getAndWatch() throws KeeperException, InterruptedException {
//判断节点是否存在
Stat stat = zkClient.exists("/yyds", false);
if (stat == null) {
System.out.println("节点不存在...");
return;
}
byte[] data = zkClient.getData("/yyds", new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event);
}
}, stat);
System.out.println(new String(data));
//线程阻塞
Thread.sleep(Long.MAX_VALUE);
}⑨ 设置节点的值
@Test
public void set() throws KeeperException, InterruptedException {
//判断节点是否存在
Stat stat = zkClient.exists("/yyds", false);
if (stat == null) {
System.out.println("节点不存在...");
return;
}
//参数解读 1节点路径 2节点的值 3版本号
zkClient.setData("/yyds", "sgg".getBytes(), stat.getVersion());
}⑩ 删除空节点
@Test
public void delete() throws KeeperException, InterruptedException {
//判断节点是否存在
Stat stat = zkClient.exists("/aaa", false);
if (stat == null) {
System.out.println("节点不存在...");
return;
}
zkClient.delete("/aaa", stat.getVersion());
}删除非空节点,递归实现
//封装一个方法,方便递归调用
public void deleteAll(String path, ZooKeeper zk) throws KeeperException, InterruptedException {
//判断节点是否存在
Stat stat = zkClient.exists(path, false);
if (stat == null) {
System.out.println("节点不存在...");
return;
}
//先获取当前传入节点下的所有子节点
List<String> children = zk.getChildren(path, false);
if (children.isEmpty()) {
//说明传入的节点没有子节点,可以直接删除
zk.delete(path, stat.getVersion());
} else {
//如果传入的节点有子节点,循环所有子节点
for (String child : children) {
//删除子节点,但是不知道子节点下面还有没有子节点,所以递归调用
deleteAll(path + "/" + child, zk);
}
//删除完所有子节点以后,记得删除传入的节点
zk.delete(path, stat.getVersion());
}
}
//测试deleteAll
@Test
public void testDeleteAll() throws KeeperException, InterruptedException {
deleteAll("/yyds",zkClient);
}4、Zookeeper内部原理
1. 节点类型

2. Stat结构体
(1)czxid-创建节点的事务zxid
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
(2)ctime - znode被创建的毫秒数(从1970年开始)
(3)mzxid - znode最后更新的事务zxid
(4)mtime - znode最后修改的毫秒数(从1970年开始)
(5)pZxid-znode最后更新的子节点zxid
(6)cversion - znode子节点变化号,znode子节点修改次数
(7)dataversion - znode数据变化号
(8)aclVersion - znode访问控制列表的变化号
(9)ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
(10)dataLength- znode的数据长度
(11)numChildren - znode子节点数量
3. 监听器原理

4. 选举机制
(1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
(2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
(3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
Zookeeper的选举机制:

(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
5. 写数据流程

5、Zookeeper面试题
1. ZooKeeper的部署方式有哪几种?集群中的角色有哪些?集群最少需要几台机器?
(1)部署方式单机模式、集群模式
(2)角色:Leader和Follower
(3)集群最少需要机器数:3
2. ZooKeeper的常用命令
ls create get delete set......
四、Kafka分布式消息队列
1、Kafka简介
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
传统消息队列的应用场景:

使用消息队列的好处:
1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
消息队列的两种模式
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。

(2)发布/订阅模式(一对多,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。

2、Kafka基础架构

1)Producer :消息生产者,就是向kafka broker发消息的客户端。
2)Consumer :消息消费者,向kafka broker取消息的客户端。
3)Consumer Group (CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic。
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
9)follower:每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader。
3、Kafka安装部署
1. 集群规划
hadoop102 hadoop103 hadoop104
zk zk zk
kafka kafka kafka
2. Kafka 下载
Apache Kafka
3. 集群部署
1)解压安装包
[yyds@hadoop102 software]$ tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/2)修改解压后的文件名称
[yyds@hadoop102 module]$ mv kafka_2.11-2.4.1.tgz kafka3)在/opt/module/kafka目录下创建logs文件夹
[yyds@hadoop102 kafka]$ mkdir logs4)修改配置文件
[yyds@hadoop102 kafka]$ cd config/
[yyds@hadoop102 config]$ vi server.properties输入以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能,当前版本此配置默认为true,已从配置文件移除
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:21815)配置环境变量
[yyds@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[yyds@hadoop102 module]$ source /etc/profile6)分发安装包
[yyds@hadoop102 module]$ xsync kafka/注意:分发之后记得配置其他机器的环境变量。
7)分别在hadoop103和hadoop104上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复。
8)启动集群
先启动Zookeeper集群,然后启动kafaka:
[yyds@hadoop102 kafka]$ zk.sh start 依次在hadoop102、hadoop103、hadoop104节点上启动kafka:
[yyds@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[yyds@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[yyds@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties9)关闭集群
[yyds@hadoop102 kafka]$ bin/kafka-server-stop.sh stop
[yyds@hadoop103 kafka]$ bin/kafka-server-stop.sh stop
[yyds@hadoop104 kafka]$ bin/kafka-server-stop.sh stop10)kafka群起脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input Args Error....."
exit
fi
for i in hadoop102 hadoop103 hadoop104
do
case $1 in
start)
echo "==================START $i KAFKA==================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties
;;
stop)
echo "==================STOP $i KAFKA==================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-stop.sh stop
;;
*)
echo "Input Args Error....."
exit
;;
esac
done4、Kafka命令行操作
1)查看当前服务器中的所有topic
[yyds@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --list2)创建topic
[yyds@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic first
选项说明:--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数
3)删除topic
[yyds@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic first4)发送消息
[yyds@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world
>yyds yyds5)消费消息
[yyds@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --topic first
[yyds@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic first--from-beginning:会把主题中现有的所有的数据都读取出来。
6)查看某个Topic的详情
[yyds@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --describe –
-topic first7)修改分区数
[yyds@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --alter –-
topic first --partitions 65、Kafka架构深入理解
1. Kafka工作流程及文件存储机制
Kafka工作流程:

Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
Kafka文件存储机制:

由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,first这个topic有三个分区,则其对应的文件夹为first-0,first-1,first-2。
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.logindex和log文件以当前segment的第一条消息的offset命名。
下图为index文件和log文件的结构示意图:

“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
2. Kafka生产者
① 分区策略
1)分区的原因
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
(2)可以提高并发,因为可以以Partition为单位读写了。
2)分区的原则
我们需要将producer发送的数据封装成一个ProducerRecord对象。

(1) 指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
(2) 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
(3) 既没有 partition 值又没有 key 值的情况下, kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,kafka再随机一个分区进行使用.
② 数据可靠性保证
1)生产者发送数据到topic partition的可靠性保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。

2)Topic partition存储数据的可靠性保证
(1)副本数据同步策略
| 方案 | 优点 | 缺点 |
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点的故障,需要2n+1个副本 |
| 全部完成同步,才发送ack | 选举新的leader时,容忍n台节点的故障,需要n+1个副本 | 延迟高 |
Kafka选择了第二种方案,原因如下:
1. 同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
2. 虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
(2)ISR
采用第二种方案之后,设想以下情景:leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给producer发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
(3)ack应答级别
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。
所以Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
acks参数配置:
acks:
0:这一操作提供了一个最低的延迟,partition的leader接收到消息还没有写入磁盘就已经返回ack,当leader故障时有可能丢失数据;
1: partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;
acks=1 数据丢失案例:

-1(all): partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。
acks=-1 数据丢失案例:

3)leader和 follower故障处理细节
Log文件中的HW和LEO:

LEO:指的是每个副本最大的offset;
HW:指的是消费者能见到的最大的offset,ISR队列中最小的LEO。
(1)follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
(2)leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
③ Exactly Once语义
将服务器的ACK级别设置为-1,可以保证Producer到Server之间不会丢失数据,即At Least Once语义。相对的,将服务器ACK级别设置为0,可以保证生产者每条消息只会被发送一次,即At Most Once语义。
At Least Once可以保证数据不丢失,但是不能保证数据不重复;相对的,At Least Once可以保证数据不重复,但是不能保证数据不丢失。但是,对于一些非常重要的信息,比如说交易数据,下游数据消费者要求数据既不重复也不丢失,即Exactly Once语义。在0.11版本以前的Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
0.11版本的Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指Producer不论向Server发送多少次重复数据,Server端都只会持久化一条。幂等性结合At Least Once语义,就构成了Kafka的Exactly Once语义。即:At Least Once + 幂等性 = Exactly Once
要启用幂等性,只需要将Producer的参数中enable.idempotence设置为true即可。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。
但是PID重启就会变化,同时不同的Partition也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once。
3. Kafka消费者
1)消费方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
2)分区分配策略
一个consumer group中有多个consumer,一个 topic有多个partition,所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer来消费。
Kafka有三种分配策略,RoundRobin,Range , Sticky。
(1)分区分配策略之RoundRobin

(2)分区分配策略之Range

3)offset的维护
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。
消费offset案例:
(0)思想: __consumer_offsets 为kafka中的topic, 那就可以通过消费者进行消费.
(1)修改配置文件consumer.properties
# 不排除内部的topic
exclude.internal.topics=false(2)创建一个topic
bin/kafka-topics.sh --create --topic yyds --zookeeper hadoop102:2181 --partitions 2
--replication-factor 2(3)启动生产者和消费者,分别往yyds生产数据和消费数据
bin/kafka-console-producer.sh --topic yyds --broker-list hadoop102:9092
bin/kafka-console-consumer.sh --consumer.config config/consumer.properties --topic yyds --bootstrap-server hadoop102:9092(4)消费offset
bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server hadoop102:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning(5)消费到的数据
[test-consumer-group,yyds,1]::OffsetAndMetadata(offset=2, leaderEpoch=Optional[0],
metadata=, commitTimestamp=1591935656078, expireTimestamp=None)
[test-consumer-group,yyds,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional[0], metadata=, commitTimestamp=1591935656078, expireTimestamp=None)4)消费者组案例
需求:
测试同一个消费者组中的消费者,同一时刻只能有一个消费者消费。
案例实操:
(1)在hadoop102、hadoop103上修改/opt/module/kafka/config/consumer.properties配置文件中的group.id属性为任意组名。
[yyds@hadoop103 config]$ vi consumer.properties
group.id=mygroup(2)在hadoop104上启动生产者
[yyds@hadoop104 kafka]$ bin/kafka-console-producer.sh \
--broker-list hadoop102:9092 --topic first(3)在hadoop102、hadoop103上分别启动消费者
[yyds@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
bootstrap-server hadoop102:9092 --topic first --consumer.config config/consumer.properties
[yyds@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --consumer.config config/consumer.properties(4)查看hadoop102和hadoop103的消费者的消费情况。
4. Kafka 高效读写数据
1)顺序写磁盘
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
2)应用
Kafka数据持久化是直接持久化到Pagecache中,这样会产生以下几个好处:
- I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能
- I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
- 充分利用所有空闲内存(非 JVM 内存)。如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担
- 读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据
- 如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用
尽管持久化到Pagecache上可能会造成宕机丢失数据的情况,但这可以被Kafka的Replication机制解决。如果为了保证这种情况下数据不丢失而强制将 Page Cache 中的数据 Flush 到磁盘,反而会降低性能。
3)零复制技术

5. Zookeeper在Kafka中的作用
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
Controller的管理工作都是依赖于Zookeeper的。
以下为partition的leader选举过程:

6. Kafka事务
Kafka从0.11版本开始引入了事务支持。事务可以保证Kafka在Exactly Once语义的基础上,生产和消费可以跨分区和会话,要么`全部成功,要么全部失败。
1)Producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transaction,Kafka引入了一个新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态。Transaction Coordinator还负责将事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
2)Consumer事务(精准一次性消费)
上述事务机制主要是从Producer方面考虑,对于Consumer而言,事务的保证就会相对较弱,尤其时无法保证Commit的信息被精确消费。这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事务的消息可能会出现重启后被删除的情况。
如果想完成Consumer端的精准一次性消费,那么需要kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将kafka的offset保存到支持事务的自定义介质(比如mysql)。这部分知识会在后续项目部分涉及。
6、Producer API
1. 消息发送流程
Kafka的Producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量——RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
KafkaProducer发送消息流程:

相关参数:
batch.size:只有数据积累到batch.size之后,sender才会发送数据。
linger.ms:如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。
2. 异步发送API
1)导入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
</dependencies>2)添加log4j配置文件
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>3)编写代码
需要用到的类:
KafkaProducer:需要创建一个生产者对象,用来发送数据
ProducerConfig:获取所需的一系列配置参数
ProducerRecord:每条数据都要封装成一个ProducerRecord对象
(1)不带回调函数的API
package com.yyds.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
//kafka集群,broker-list
props.put("bootstrap.servers", "hadoop102:9092");
props.put("acks", "all");
//重试次数
props.put("retries", 1);
//批次大小
props.put("batch.size", 16384);
//等待时间
props.put("linger.ms", 1);
//RecordAccumulator缓冲区大小
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
}(2)带回调函数的API
回调函数会在producer收到ack时调用,为异步调用,该方法有两个参数,分别是RecordMetadata和Exception,如果Exception为null,说明消息发送成功,如果Exception不为null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
package com.yyds.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i)), new Callback() {
//回调函数,该方法会在Producer收到ack时调用,为异步调用
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("success->" + metadata.offset());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
}3. 分区器
- 默认的分区器 DefaultPartitioner
- 自定义分区器
public class MyPartitioner implements Partitioner {
/**
* 计算某条消息要发送到哪个分区
* @param topic 主题
* @param key 消息的key
* @param keyBytes 消息的key序列化后的字节数组
* @param value 消息的value
* @param valueBytes 消息的value序列化后的字节数组
* @param cluster
* @return
*
* 需求: 以yyds主题为例,2个分区
* 消息的 value包含"yyds"的 进入0号分区
* 其他的消息进入1号分区
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String msgValue = value.toString();
int partition ;
if(msgValue.contains("yyds")){
partition = 0;
}else{
partition = 1;
}
return partition;
}
/**
* 收尾工作
*/
@Override
public void close() {
}
/**
* 读取配置的
* @param configs
*/
@Override
public void configure(Map<String, ?> configs) {
}
}4. 同步发送API
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回ack。
由于send方法返回的是一个Future对象,根据Futrue对象的特点,我们也可以实现同步发送的效果,只需在调用Future对象的get方发即可。
package com.yyds.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i))).get();
}
producer.close();
}
}7、Consumer API
Consumer消费数据时的可靠性是很容易保证的,因为数据在Kafka中是持久化的,故不用担心数据丢失问题。
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
所以offset的维护是Consumer消费数据是必须考虑的问题。
1. 自动提交offset
1)编写代码
需要用到的类:
KafkaConsumer:需要创建一个消费者对象,用来消费数据
ConsumerConfig:获取所需的一系列配置参数
ConsuemrRecord:每条数据都要封装成一个ConsumerRecord对象
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
enable.auto.commit:是否开启自动提交offset功能
auto.commit.interval.ms:自动提交offset的时间间隔
2)消费者自动提交offset
package com.yyds.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("first"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}2. 重置Offset
auto.offset.rest = earliest | latest | none |3. 手动提交offset
虽然自动提交offset十分简介便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而commitAsync则没有失败重试机制,故有可能提交失败。
1)同步提交offset
由于同步提交offset有失败重试机制,故更加可靠,以下为同步提交offset的示例。
package com.yyds.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomComsumer {
public static void main(String[] args) {
Properties props = new Properties();
//Kafka集群
props.put("bootstrap.servers", "hadoop102:9092");
//消费者组,只要group.id相同,就属于同一个消费者组
props.put("group.id", "test");
props.put("enable.auto.commit", "false");//关闭自动提交offset
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("first"));//消费者订阅主题
while (true) {
//消费者拉取数据
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
//同步提交,当前线程会阻塞直到offset提交成功
consumer.commitSync();
}
}
}2)异步提交offset
虽然同步提交offset更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会收到很大的影响。因此更多的情况下,会选用异步提交offset的方式。
以下为异步提交offset的示例:
package com.yyds.kafka.consumer;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
Properties props = new Properties();
//Kafka集群
props.put("bootstrap.servers", "hadoop102:9092");
//消费者组,只要group.id相同,就属于同一个消费者组
props.put("group.id", "test");
//关闭自动提交offset
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("first"));//消费者订阅主题
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);//消费者拉取数据
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
//异步提交
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for" + offsets);
}
}
});
}
}
}3)数据漏消费和重复消费分析
无论是同步提交还是异步提交offset,都有可能会造成数据的漏消费或者重复消费。先提交offset后消费,有可能造成数据的漏消费;而先消费后提交offset,有可能会造成数据的重复消费。
8、自定义Interceptor
1. 拦截器原理
Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。
对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor,其定义的方法包括:
(1)configure(configs)
获取配置信息和初始化数据时调用。
(2)onSend(ProducerRecord):
该方法封装进KafkaProducer.send方法中,即它运行在用户主线程中。Producer确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响目标分区的计算。
(3)onAcknowledgement(RecordMetadata, Exception):
该方法会在消息从RecordAccumulator成功发送到Kafka Broker之后,或者在发送过程中失败时调用。并且通常都是在producer回调逻辑触发之前。onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率。
(4)close:
关闭interceptor,主要用于执行一些资源清理工作
如前所述,interceptor可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个interceptor,则producer将按照指定顺序调用它们,并仅仅是捕获每个interceptor可能抛出的异常记录到错误日志中而非在向上传递。这在使用过程中要特别留意。
2. 拦截器案例
1)需求
实现一个简单的双interceptor组成的拦截链。第一个interceptor会在消息发送前将时间戳信息加到消息value的最前部;第二个interceptor会在消息发送后更新成功发送消息数或失败发送消息数。
2)案例实操
Kafka拦截器:

(1)增加时间戳拦截器
package com.yyds.kafka.interceptor;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class TimeInterceptor implements ProducerInterceptor<String, String> {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 创建一个新的record,把时间戳写入消息体的最前部
return new ProducerRecord(record.topic(), record.partition(), record.timestamp(), record.key(),
System.currentTimeMillis() + "," + record.value().toString());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
}(2)统计发送消息成功和发送失败消息数,并在producer关闭时打印这两个计数器
package com.yyds.kafka.interceptor;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class CounterInterceptor implements ProducerInterceptor<String, String>{
private int errorCounter = 0;
private int successCounter = 0;
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
// 统计成功和失败的次数
if (exception == null) {
successCounter++;
} else {
errorCounter++;
}
}
@Override
public void close() {
// 保存结果
System.out.println("Successful sent: " + successCounter);
System.out.println("Failed sent: " + errorCounter);
}
}(3)producer主程序
package com.yyds.kafka.interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
public class InterceptorProducer {
public static void main(String[] args) throws Exception {
// 1 设置配置信息
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092");
props.put("acks", "all");
props.put("retries", 3);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2 构建拦截链
List<String> interceptors = new ArrayList<>();
interceptors.add("com.yyds.kafka.interceptor.TimeInterceptor"); interceptors.add("com.yyds.kafka.interceptor.CounterInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
String topic = "first";
Producer<String, String> producer = new KafkaProducer<>(props);
// 3 发送消息
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "message" + i);
producer.send(record);
}
// 4 一定要关闭producer,这样才会调用interceptor的close方法
producer.close();
}
}3)测试
(1)在kafka上启动消费者,然后运行客户端java程序。
[yyds@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic first
1501904047034,message0
1501904047225,message1
1501904047230,message2
1501904047234,message3
1501904047236,message4
1501904047240,message5
1501904047243,message6
1501904047246,message7
1501904047249,message8
1501904047252,message99、Kafka监控
1. Kafka Eagle
1)修改kafka启动命令
修改kafka-server-start.sh命令中:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi为:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi注意:修改之后在启动Kafka之前要分发之其他节点。
2)上传压缩包kafka-eagle-bin-1.4.5.tar.gz到集群/opt/software目录
3)解压到本地
[yyds@hadoop102 software]$ tar -zxvf kafka-eagle-bin-1.4.5.tar.gz4)进入刚才解压的目录
[yyds@hadoop102 kafka-eagle-bin-1.4.5]$ ll
总用量 82932
-rw-rw-r--. 1 yyds yyds 84920710 8月 13 23:00 kafka-eagle-web-1.4.5-bin.tar.gz5)将kafka-eagle-web-1.3.7-bin.tar.gz解压至/opt/module
[yyds@hadoop102 kafka-eagle-bin-1.4.5]$ tar -zxvf kafka-eagle-web-1.4.5-bin.tar.gz -C /opt/module/6)修改名称
[yyds@hadoop102 module]$ mv kafka-eagle-web-1.4.5/ eagle7)给启动文件执行权限
[yyds@hadoop102 eagle]$ cd bin/
[yyds@hadoop102 bin]$ ll
总用量 12
-rw-r--r--. 1 yyds yyds 1848 8月 22 2017 ke.bat
-rw-r--r--. 1 yyds yyds 7190 7月 30 20:12 ke.sh
[yyds@hadoop102 bin]$ chmod 777 ke.sh8)修改配置文件 conf/system-config.properties
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=1234569)添加环境变量
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin注意:source /etc/profile
10)启动
[yyds@hadoop102 eagle]$ bin/ke.sh start
... ...
... ...
*******************************************************************
* Kafka Eagle Service has started success.
* Welcome, Now you can visit 'http://192.168.202.102:8048/ke'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/ </Usage>
*******************************************************************
[yyds@hadoop102 eagle]$注意:启动之前需要先启动ZK以及KAFKA。
11)登录页面查看监控数据
http://192.168.202.102:8048/ke

10、Flume对接Kafka
1. 简单实现
1)配置flume
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/data/flume.log
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c12) 启动kafka消费者
3) 进入flume根目录下,启动flume
$ bin/flume-ng agent -c conf/ -n a1 -f jobs/flume-kafka.conf4) 向 /opt/module/data/flume.log里追加数据,查看kafka消费者消费情况
$ echo hello >> /opt/module/data/flume.log2. 数据分离
0)需求: 将flume采集的数据按照不同的类型输入到不同的topic中
将日志数据中带有yyds的,输入到Kafka的first主题中,
将日志数据中带有shangguigu的,输入到Kafka的second主题中,
其他的数据输入到Kafka的third主题中
1)编写Flume的Interceptor
package com.yyds.kafka.flumeInterceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import javax.swing.text.html.HTMLEditorKit;
import java.util.List;
import java.util.Map;
public class FlumeKafkaInterceptor implements Interceptor {
@Override
public void initialize() {
}
/**
* 如果包含"yyds"的数据,发送到first主题
* 如果包含"sgg"的数据,发送到second主题
* 其他的数据发送到third主题
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
//1.获取event的header
Map<String, String> headers = event.getHeaders();
//2.获取event的body
String body = new String(event.getBody());
if(body.contains("yyds")){
headers.put("topic","first");
}else if(body.contains("sgg")){
headers.put("topic","second");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new FlumeKafkaInterceptor();
}
@Override
public void configure(Context context) {
}
}
}2)将写好的interceptor打包上传到Flume安装目录的lib目录下
3)配置flume
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = third
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
#Interceptor
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.yyds.kafka.flumeInterceptor.FlumeKafkaInterceptor$MyBuilder
# # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c14) 启动kafka消费者
5) 进入flume根目录下,启动flume
$ bin/flume-ng agent -c conf/ -n a1 -f jobs/flume-kafka.conf6) 向6666端口写数据,查看kafka消费者消费情况
11、Kafka Streams
1. Kafka Streams简介
Kafka Streams。Apache Kafka开源项目的一个组成部分。是一个功能强大,易于使用的库。用于在Kafka上构建高可分布式、拓展性,容错的应用程序。
2. Kafka Streams 特点
1)功能强大
高扩展性,弹性,容错
2)轻量级
无需专门的集群
一个库,而不是框架
3)完全集成
100%的Kafka 0.10.0版本兼容
易于集成到现有的应用程序
4)实时性
毫秒级延迟
并非微批处理
窗口允许乱序数据
允许迟到数据
3. 为什么要有Kafka Stream
当前已经有非常多的流式处理系统,最知名且应用最多的开源流式处理系统有Spark Streaming和Apache Storm。Apache Storm发展多年,应用广泛,提供记录级别的处理能力,当前也支持SQL on Stream。而Spark Streaming基于Apache Spark,可以非常方便与图计算,SQL处理等集成,功能强大,对于熟悉其它Spark应用开发的用户而言使用门槛低。另外,目前主流的Hadoop发行版,如Cloudera和Hortonworks,都集成了Apache Storm和Apache Spark,使得部署更容易。
既然Apache Spark与Apache Storm拥用如此多的优势,那为何还需要Kafka Stream呢?主要有如下原因。
第一,Spark和Storm都是流式处理框架,而Kafka Stream提供的是一个基于Kafka的流式处理类库。框架要求开发者按照特定的方式去开发逻辑部分,供框架调用。开发者很难了解框架的具体运行方式,从而使得调试成本高,并且使用受限。而Kafka Stream作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。

第二,虽然Cloudera与Hortonworks方便了Storm和Spark的部署,但是这些框架的部署仍然相对复杂。而Kafka Stream作为类库,可以非常方便的嵌入应用程序中,它对应用的打包和部署基本没有任何要求。
第三,就流式处理系统而言,基本都支持Kafka作为数据源。例如Storm具有专门的kafka-spout,而Spark也提供专门的spark-streaming-kafka模块。事实上,Kafka基本上是主流的流式处理系统的标准数据源。换言之,大部分流式系统中都已部署了Kafka,此时使用Kafka Stream的成本非常低。
第四,使用Storm或Spark Streaming时,需要为框架本身的进程预留资源,如Storm的supervisor和Spark on YARN的node manager。即使对于应用实例而言,框架本身也会占用部分资源,如Spark Streaming需要为shuffle和storage预留内存。但是Kafka作为类库不占用系统资源。
第五,由于Kafka本身提供数据持久化,因此Kafka Stream提供滚动部署和滚动升级以及重新计算的能力。
第六,由于Kafka Consumer Rebalance机制,Kafka Stream可以在线动态调整并行度。
4. Kafka Stream数据清洗案例
0)需求
实时处理单词带有”>>>”前缀的内容。例如输入”yyds>>>ximenqing”,最终处理成“ximenqing”
1)需求分析

2)案例实操
(1)创建一个工程,并添加jar包
(2)创建主类
package com.yyds.kafka.stream;
import java.util.Properties;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import org.apache.kafka.streams.processor.TopologyBuilder;
public class Application {
public static void main(String[] args) {
// 定义输入的topic
String from = "first";
// 定义输出的topic
String to = "second";
// 设置参数
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "logFilter");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
StreamsConfig config = new StreamsConfig(settings);
// 构建拓扑
TopologyBuilder builder = new TopologyBuilder();
builder.addSource("SOURCE", from)
.addProcessor("PROCESS", new ProcessorSupplier<byte[], byte[]>() {
@Override
public Processor<byte[], byte[]> get() {
// 具体分析处理
return new LogProcessor();
}
}, "SOURCE")
.addSink("SINK", to, "PROCESS");
// 创建kafka stream
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}(3)具体业务处理
package com.yyds.kafka.stream;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext;
public class LogProcessor implements Processor<byte[], byte[]> {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(byte[] key, byte[] value) {
String input = new String(value);
// 如果包含“>>>”则只保留该标记后面的内容
if (input.contains(">>>")) {
input = input.split(">>>")[1].trim();
// 输出到下一个topic
context.forward("logProcessor".getBytes(), input.getBytes());
}else{
context.forward("logProcessor".getBytes(), input.getBytes());
}
}
@Override
public void punctuate(long timestamp) {
}
@Override
public void close() {
}
}(4)运行程序
(5)在hadoop104上启动生产者
[yyds@hadoop104 kafka]$ bin/kafka-console-producer.sh \
--broker-list hadoop102:9092 --topic first
>hello>>>world
>h>>>yyds
>hahaha(6)在hadoop103上启动消费者
[yyds@hadoop103 kafka]$ bin/kafka-console-consumer.sh \
--zookeeper hadoop102:2181 --from-beginning --topic second
world
yyds
hahaha12、Kafka性能相关配置
Kafka吞吐量的设置:
1. Producer端设置
| 设置项 | 注释 |
| :------------------------------------ | --------------------------------------------------------- |
| buffer.memory | Producer端Accumulator大小,调大其可以增加缓存,不容易溢出 |
| compression.type | 压缩格式,压缩可以增加网络IO效率 |
| batch.size | 加大批次大小可以提高吞吐量 |
| max.request.size | 如果批量增大,这个要相应增大 |
| enable.idempotence | 启用幂等性可以去重但是会降低性能 |
| max.in.flight.requests.per.connection | 同时在途信息个数:调大可增加吞吐量,但是会失去幂等性 |
| transactional.id | 事务ID,设置后会开启事务 |2. Broker端配置
| 设置项 | 注释 |
| :-------------------------------- | --------------------------------------------------- |
| background.threads | 后台任务线程数,默认10个,一般不用动 |
| message.max.bytes | 一条消息最大是多少,默认1MB |
| min.insync.replicas | 最少和leader保持同步的副本数量 |
| num.io.threads | 用于处理IO的线程,默认8个,一般不动 |
| num.network.threads | 用于处理network的线程,默认3个,一般也不动 |
| num.recovery.threads.per.data.dir | 用于启动同步和刷写的线程,默认1个,可以根据需求增加 |
| num.replica.fetchers | follower用于拉取leader的线程,默认1个,可以按需增加 |
| replica.fetch.min.bytes | follower一次拉取的数据,不足会等待 |
| replica.fetch.wait.max.ms | 等待拉取延时 |
| replica.fetch.max.bytes | follower一次拉取数据最大值,当消息过大可以调大 |3. Consumer端配置
| 设置项 | 注释 |
| ---------------- | ------------------------------------------ |
| fetch.min.bytes | 一次拉取数据最小值,适当调大可以增加吞吐量 |
| fetch.max.bytes | 一次拉取数据最大值,根据消息大小调节 |
| max.poll.records | 一次拉取多少条records |4. 消费端和Broker端注意并行度匹配,分区和一组消费者数量相当最理想
13、Kafka面试
1. Kafka中的ISR、AR又代表什么?
ISR:与leader保持同步的follower集合
AR:分区的所有副本
2. Kafka中的HW、LEO等分别代表什么?
LEO:没个副本的最后条消息的offset
HW:一个分区中所有副本最小的offset
3. Kafka中是怎么体现消息顺序性的?
每个分区内,每条消息都有一个offset,故只能保证分区内有序。
4. Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
拦截器 -> 序列化器 -> 分区器
5. Kafka生产者客户端的整体结构是什么样子的?使用了几个线程来处理?分别是什么?
KafkaProducer发送消息流程:

6. “消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?
正确
7. 消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
offset+1
8. 有哪些情形会造成重复消费?
数据重复消息问题:

9. 那些情景会造成消息漏消费?
先提交offset,后消费,有可能造成数据的重复
10. 当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
1)会在zookeeper中的/brokers/topics节点下创建一个新的topic节点,如:/brokers/topics/first
2)触发Controller的监听程序
3)kafka Controller 负责topic的创建工作,并更新metadata cache
11. topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加:
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter --topic topic-config --partitions 312. topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不可以减少,现有的分区数据难以处理。
13. Kafka有内部的topic吗?如果有是什么?有什么所用?
__consumer_offsets,保存消费者offset
14. Kafka分区分配的概念?
一个topic多个分区,一个消费者组多个消费者,故需要将分区分配个消费者(roundrobin、range)
15. 简述Kafka的日志目录结构?
每个分区对应一个文件夹,文件夹的命名为topic-0,topic-1,内部为.log和.index文件
16. 如果我指定了一个offset,Kafka Controller怎么查找到对应的消息?

17. 聊一聊Kafka Controller的作用?
负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
18. Kafka中有那些地方需要选举?这些地方的选举策略又有哪些?
partition leader(ISR),controller(先到先得)
19. 失效副本是指什么?有那些应对措施?
不能及时与leader同步,暂时踢出ISR,等其追上leader之后再重新加入
20. Kafka的那些设计让它有如此高的性能?
分区,顺序写磁盘,0-copy