效果超强!基于Prompt Learning、检索思路实现文本分类,开源数据增强、可信增强技术
文本分类在互联网、金融、医疗、法律、工业等领域都有广泛的应用,例如文章主题分类、商品信息分类、对话意图分类、论文专利分类、邮件自动标签、评论正负倾向识别、投诉事件分类、广告检测、敏感违法内容检测等,这些应用场景全部都可以抽象为文本分类任务。但如何进行技术方案选型、如何进行模型调优、如何解决少样本等问题,使很多开发者望而却步,迟迟难以上线。
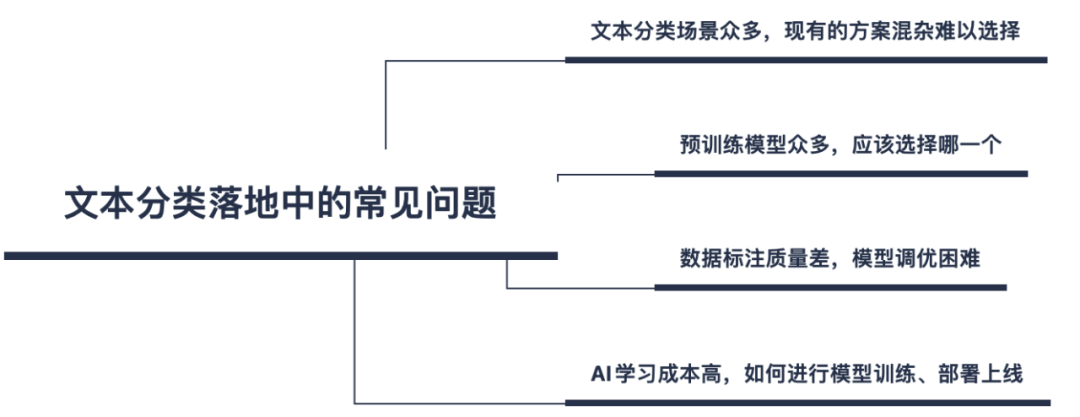
近日,PaddleNLP针对以上工业落地中种种常见问题,开源了一整套文本分类场景方案,接下来我们将详细解读其技术特色:
-
方案全覆盖:涵盖文本分类高频场景,开源微调、提示学习、基于语义索引多种分类技术方案,满足不同文本分类落地需求;
-
模型高效调优:强强结合数据增强能力与可信增强技术,解决脏数据、标注数据欠缺、数据不平衡等问题,大幅提升模型效果;
-
产业级全流程:打通数据标注-模型训练-模型调优-模型压缩-预测部署全流程,助力开发者简单高效地完成文本分类任务。
如有帮助,欢迎STAR支持我们的工作,项目地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification
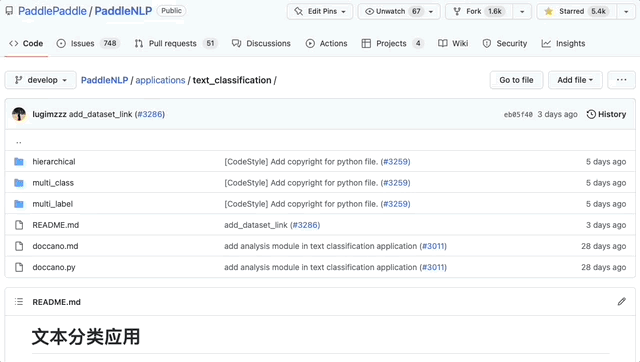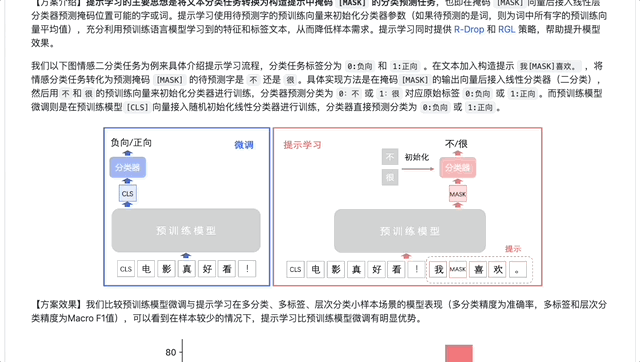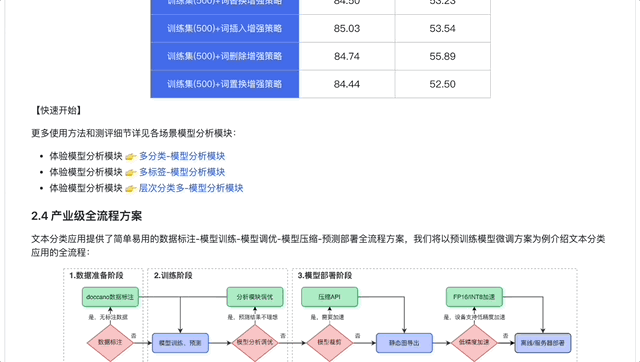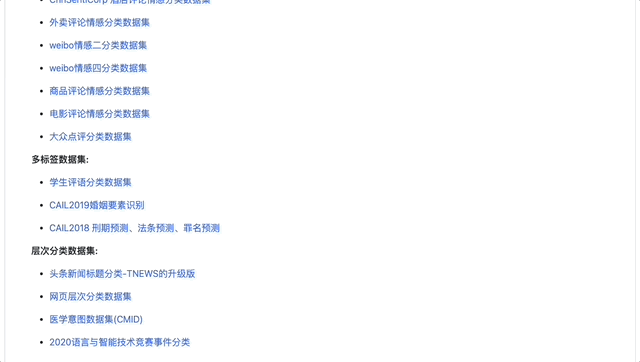
图:PaddleNLP文本分类详细文档一览
特色一
方案全覆盖

图:三类文本分类场景
PaddleNLP基于多分类、多标签、层次分类等高频分类场景,提供了预训练模型微调、提示学习、语义索引三种端到端全流程分类方案:
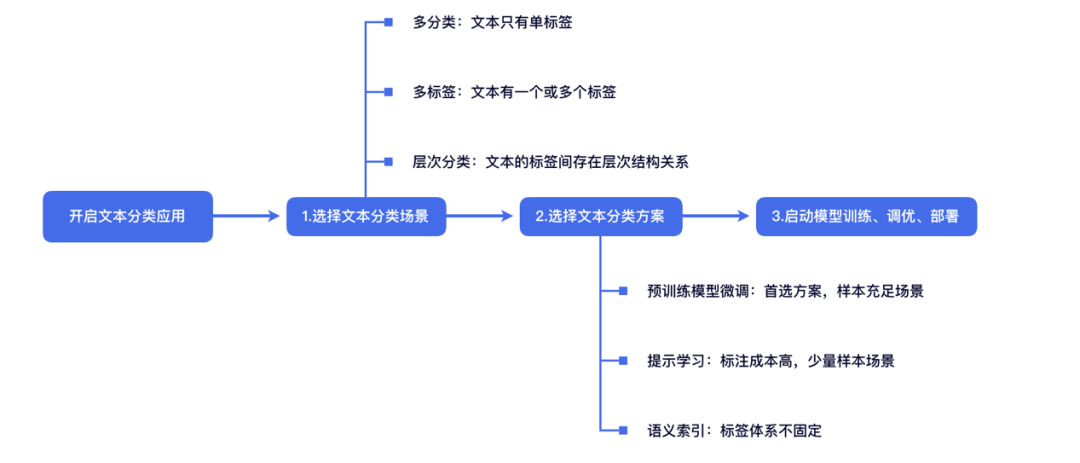
方案一: 预训练模型微调
预训练模型微调是目前NLP领域最通用的文本分类方案。预训练模型与具体的文本分类任务的关系可以直观地理解为,预训练模型已经懂得了通用的句法、语义等知识,采用具体下游任务数据微调训练可以使得模型”更懂”这个任务,在预训练过程中学到的知识基础可以使文本分类效果事半功倍。
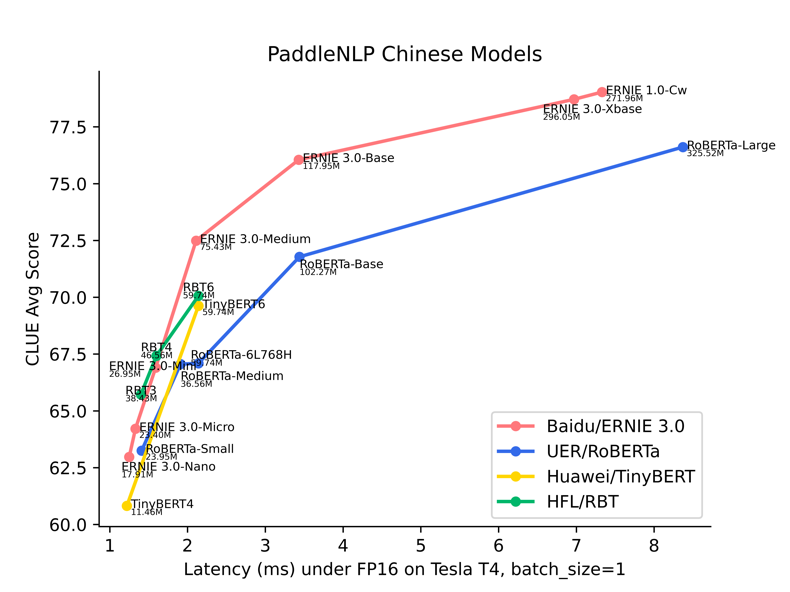
图:模型精度-时延图
在预训练模型选择上,文心ERNIE系列模型在精度和性能上的综合表现已全面领先于UER/RoBERTa、Huawei/TinyBERT、HFL/RBT、RoBERTa-wwm-ext-large等中文模型。PaddleNLP开源了如下多种尺寸的文心ERNIE系列预训练模型,满足多样化的精度、性能需求:
• 文心ERNIE 1.0-Large-zh-CW(24L1024H)
• 文心ERNIE 3.0-Xbase-zh(20L1024H)
• 文心ERNIE 2.0-Base-zh (12L768H)
• 文心ERNIE 3.0-Base (12L768H)
• 文心ERNIE 3.0-Medium (6L768H)
• 文心ERNIE 3.0-Mini (6L384H)
• 文心ERNIE 3.0-Micro (4L384H)
• 文心ERNIE 3.0-Nano (4L312H)
• … …
除中文模型外,PaddleNLP也提供文心ERNIE 2.0英文版、以及基于96种语言(涵盖法语、日语、韩语、德语、西班牙语等几乎所有常见语言)预训练的多语言模型文心ERNIE-M,满足不同语言的文本分类任务需求。
方案二: 提示学习
提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。提示学习的主要思想是将文本分类任务转换为构造提示(Prompt)中掩码的分类预测任务,使用待预测字的预训练向量来初始化分类器参数,充分利用预训练语言模型学习到的特征和标签文本,从而降低样本量需求。PaddleNLP集成了R-Drop 和RGL等前沿策略,帮助提升模型效果。
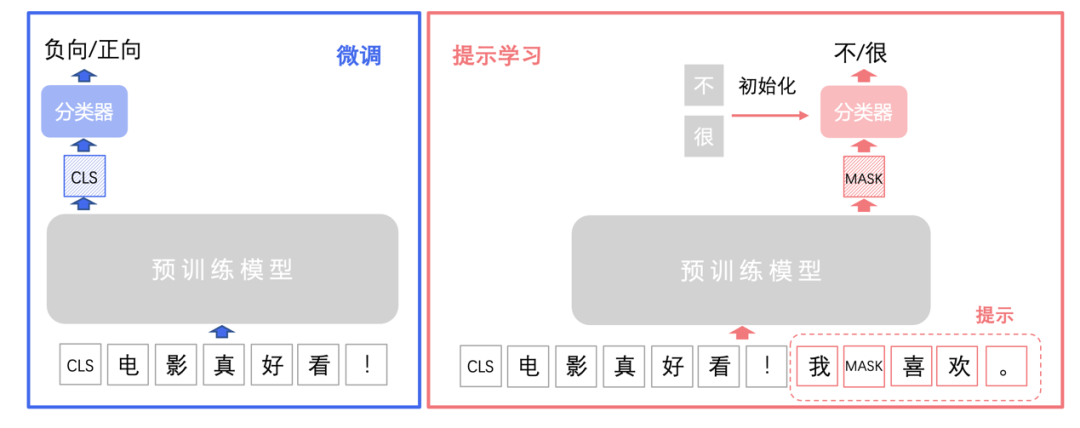
图:预训练模型微调vs提示学习
如下图,在多分类、多标签、层次分类任务的小样本场景下,提示学习比预训练模型微调方案,效果上有显著优势。
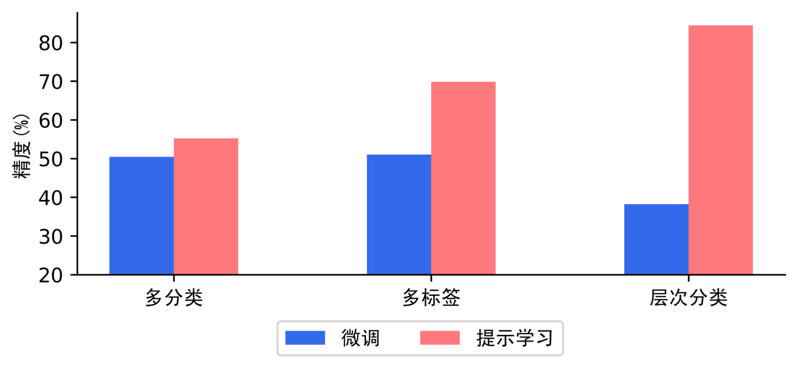
方案三: 语义索引
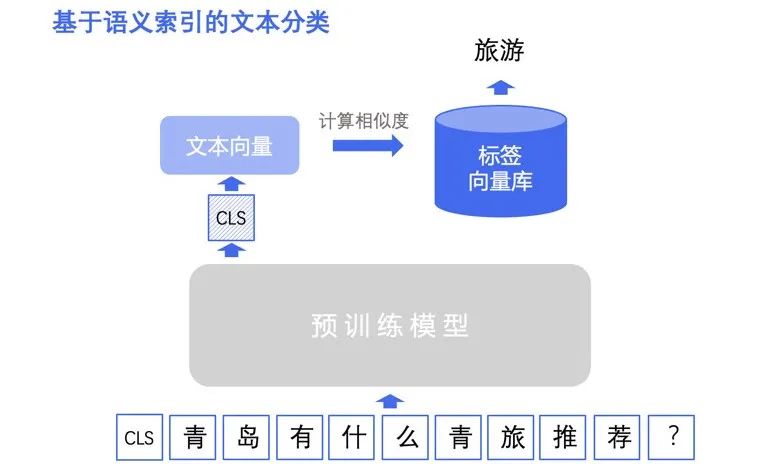
基于语义索引的文本分类方案适用于标签类别不固定****或大规模标签类别的场景。在新增标签类别的情况下,无需重新训练模型。语义索引的目标是从海量候选召回集中快速、准确地召回一批与输入文本语义相关的文本。基于语义索引的文本分类方法具体来说是将标签集作为召回目标集,召回与输入文本语义相似的标签作为文本的标签类别,尤其适用于层次分类场景。
特色二
模型高效调优
有这么一句话在业界广泛流传,“数据决定了机器学习的上限,而模型和算法只是逼近这个上限”,可见数据质量的重要性。PaddleNLP文本分类方案依托TrustAI可信增强能力和数据增强API开源了模型分析模块,针对标注数据质量不高、训练数据覆盖不足、样本数量少等文本分类常见数据痛点,提供稀疏数据筛选、脏数据清洗、数据增强三种数据优化策略,解决训练数据缺陷问题,用低成本方式获得大幅度的效果提升。
策略一: 稀疏数据筛选
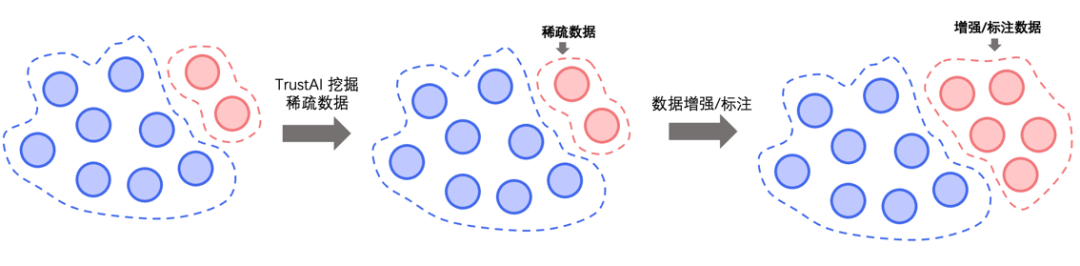
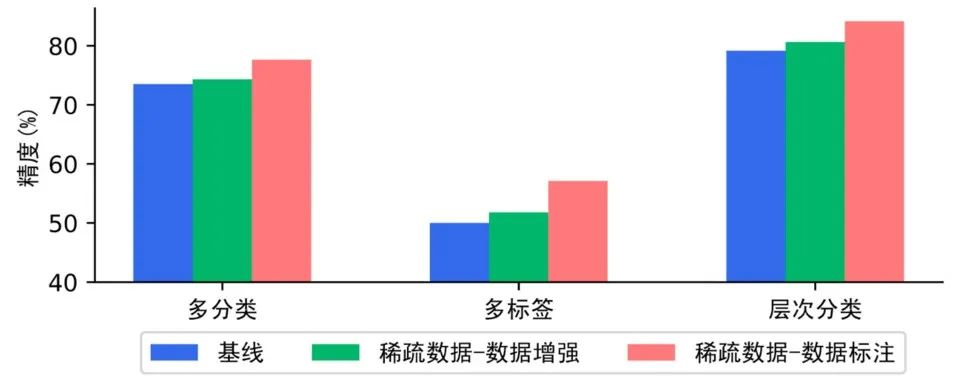
基于TrustAI中可信增强方法挖掘待预测数据中缺乏训练集数据支持的数据(稀疏数据),然后使用特征相似度方法选择能够提供证据支持的训练数据进行数据增强,或选择能够提供证据支持的未标注数据进行数据标注,这两种稀疏数据筛选策略均能有效提升模型表现。
策略二: 脏数据清洗
基于TrustAI的可信增强能力,采用表示点方法(Representer Point)计算训练数据对模型的影响分数,分数高的训练数据表明对模型影响大,这些数据有较大概率为脏数据(被错误标注的样本)。脏数据清洗策略通过高效识别训练集中脏数据,有效降低人力检查成本。
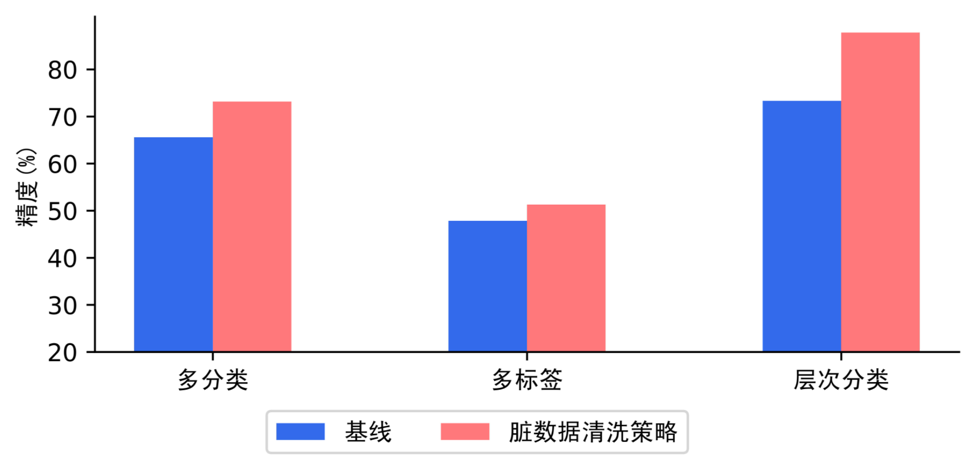
我们在多分类、多标签、层次分类场景中评测脏数据清洗策略,实验表明脏数据清洗策略对文本分类任务有显著提升效果。
策略三: 数据增强
PaddleNLP内置数据增强API,支持词替换、词删除、词插入、词置换、基于上下文生成词(MLM预测)、TF-IDF等多种数据增强策略,只需一行命令即可实现数据集增强扩充。我们在某分类数据集(500条)中测评多种数据增强 策略,实验表明在数据量较少的情况下,数据增强策略能够增加数据集多样性,提升模型效果。
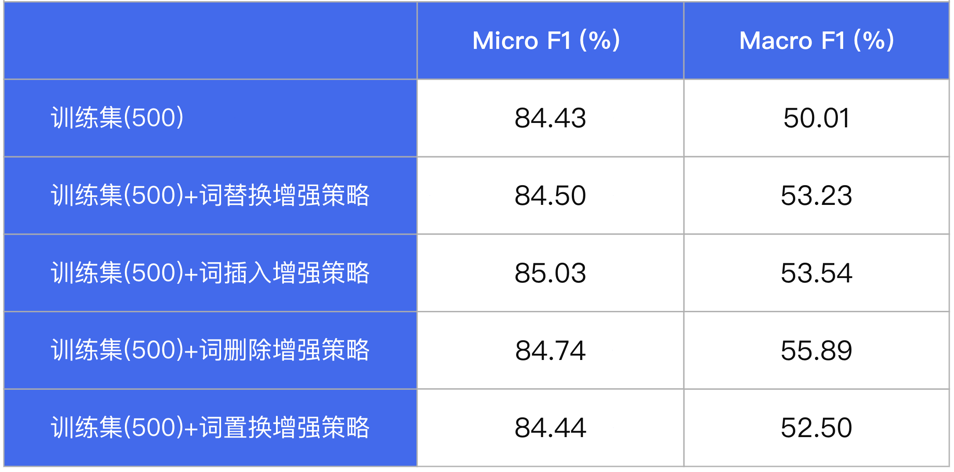
表:数据增强策略效果
特色三
产业级全流程
文本分类应用提供了简单易用的数据标注-模型训练-模型调优-模型压缩-预测部署全流程方案,方案流程如下图所示。
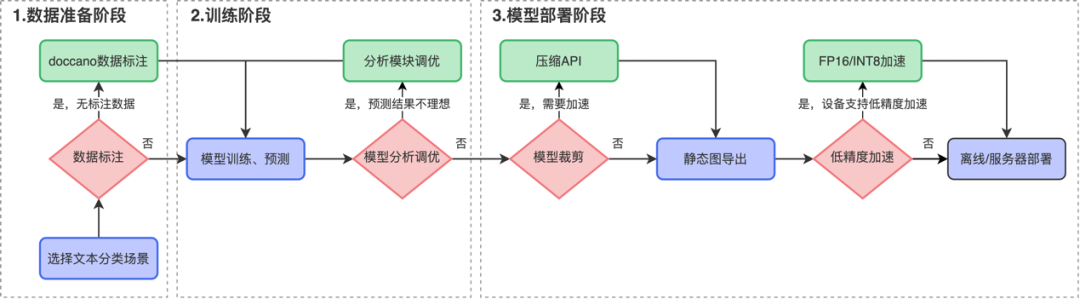
开发者仅需输入指定格式的数据,一行命令即可开启文本分类训练。对于训练结果不理想情况,分析模块提供了多种模型调优方案,解决文本分类数据难题。
对于模型部署上线要进一步压缩模型体积的需求,文本分类应用接入PaddleNLP模型压缩API 。采用了DynaBERT中宽度自适应裁剪策略,对预训练模型多头注意力机制中的头(Head )进行重要性排序,保证更重要的头(Head )不容易被裁掉,然后用原模型作为蒸馏过程中的教师模型,宽度更小的模型作为学生模型,蒸馏得到的学生模型就是我们裁剪得到的模型。实验表明模型裁剪能够有效缩小模型体积、减少内存占用、提升推理速度。此外,模型裁剪去掉了部分冗余参数的扰动,增加了模型的泛化能力,在部分任务中预测精度得到提高。通过模型裁剪,我们得到了更快、更准的模型!

表:模型裁剪效果
完成模型训练和裁剪后,开发者可以根据需求选择是否进行低精度(FP16/INT8)加速,快速高效实现模型离线或服务化部署。
9月21日,飞桨开发者刘积斌将分享智慧城市业务中上报事件工单分类的技术方案,详细讲解如何使用语义检索技术实现多层次分类任务。除工单分类外,还将带来工单推荐、合并、企业政策匹配、企业简历匹配等实践案例。欢迎扫码加入课程。

扫码还可获得文本分类常用数据集、PaddleNLP学习大礼包等超多福利!
PaddleNLP项目地址:
https://github.com/PaddlePaddle/PaddleNLP
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~