关于HashMap中重写equals与hashcode的一下问题
目录
什么时候对equals,hashcode重写?
什么是hashcode方法?
为什么在Hashmap中重写equals一定要对hashcode重写?
怎样重写hashcode与equals方法?
hashCode书写方法
为什么使用31?为什么使用hashCode方法
什么时候对equals,hashcode重写?
1 当需要比较对象是否相同时需要重写equals
2 当需要使用HashMap并且需要重写equals方法时,都需要重写hashcode方法!不需要使用hashmap的话是不需要重写的
什么是hashcode方法?
hashcode方法是Java的java.lang.Object提供的本地方法,这个方法在jvm中实现,它能返回当前对象在内存中地址。
public native int hashCode();为什么在Hashmap中重写equals一定要对hashcode重写?
1(正向论证) HashMap在put一个键值对时,会先根据键的hashCode和equals方法来同时判断该键在容器(红黑树或表)中是否已经存在,如果存在则覆盖,反之新建。所以如果我们在重写equals方法时,没有重写hashCode方法,那么hashCode方法还是会默认使用Object提供的原始方法,而Object提供的hashCode方法返回值是不会重复的(也就是说每个对象返回的值都不一样)。所以就会导致每个对象在HashMap中都会是一个新的键。
2(反向论证) 若一个类中重写了 equals 方法,没有重写hashCode方法;且该类的两个对象具有不同属性但 hashCode 相等(有可能是相等的),在hashMap 以该对象为键进行存储时,会出现hash冲突现象,但发现该类重写了equals 方法,且通过该类的equals 比较之后也是相等,就会出现 hashMap 中只保存了一个对象,采用get 方法获取时,就会获取到别的对象,从而导致获取对象错乱。
怎样重写hashcode与equals方法?
我们直接上实例,然后再说明
import org.w3c.dom.Entity;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
public class Main {
public static void main(String[] args) {
Map_1();
}
public static void Map_1()
{
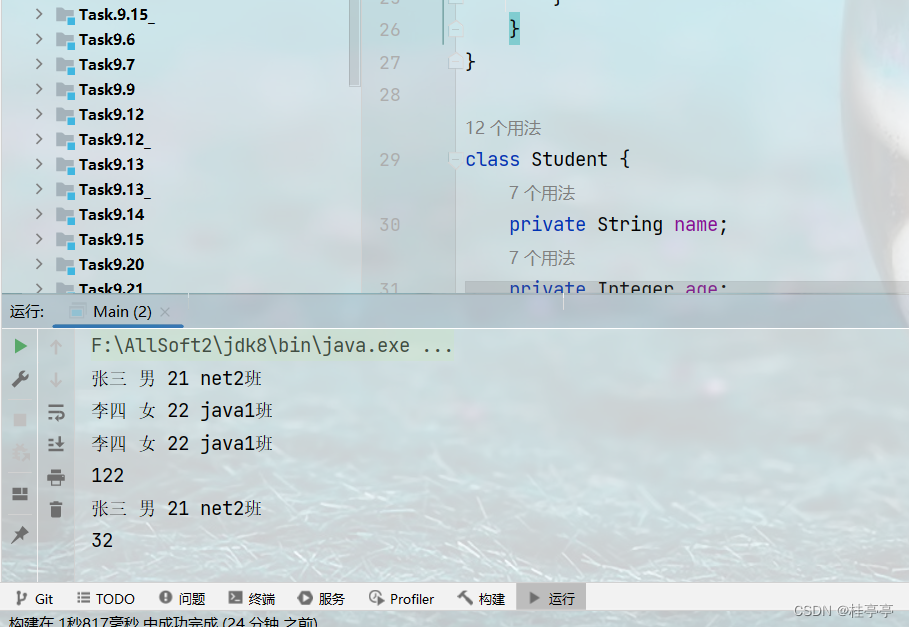
Student s1=new Student("张三",21,"男","net2班");
Student s2=new Student("李四",22,"女","java1班");
boolean s=s1.equals(s2);
System.out.println(s1.toString());
System.out.println(s2.toString());
HashMap<Student,Integer> ha1=new HashMap<Student, Integer>();
ha1.put(s1,32);
ha1.put(s2,122);
for(Map.Entry<Student,Integer> entry:ha1.entrySet()){
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
}
class Student {
private String name;
private Integer age;
private String sex;
private String className;
Student(String name, Integer age, String sex, String className) {
this.name = name;
this.age = age;
this.sex = sex;
this.className = className;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
/**
* @param sex 男 女
*/
public boolean setSex(String sex) {
if (!Objects.equals(sex, "男") && !Objects.equals(sex, "女")) {
return false;
} else {
this.sex = sex;
return true;
}
}
public String getClassName() {
return className;
}
public void setClassName(String className) {
this.className = className;
}
@Override
public String toString() {
return name + " " + sex + " " + age + " " + className;
}
@Override
public boolean equals(Object o) {
if (o instanceof Student) {
return Objects.equals(((Student) o).getName(), this.name) && Objects.equals(((Student) o).getAge(), this.age) && Objects.equals(((Student) o).getClassName(), this.className) && Objects.equals(((Student) o).getSex(), this.sex);
} else
return false;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((sex == null) ? 0 : sex.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + ((className == null) ? 0 : className.hashCode());
result = prime * result + (age == null ? 0 : age.hashCode());
return result;
}
}
hashCode书写方法
1 我们比较对象中的每一个属性 如果属性==null,我们返回hashcode为0,
反之将调用hashCode方法获得当前属性的地址+(31*result) 并将结果赋值给result
2 直到每一个属性都已比较完成,我们返回累加的result值
为什么使用31?为什么使用hashCode方法
1 其实每次计算result*31的作用是为了,防止hash冲突!因为如果不设置一个乘积因子,result计算的结果比较小,非常容易在累加的过程后出现相同的hash值,这种情况不是我们想见到的!
2 首先我们需要知道,我们是通过对象的域来计算hash的, 在对象中域无非数组、引用类型、基本数据类型,有这么多类型的域,我们肯定不能选择某一个域的hash值来作为对象的hashcode方法的返回值;因此我们考虑将域的hash值累加起来返回!
- 基本数据类型,大家可以参考其对应的包装类型的hashcode方法
- (我们可以发现实例代码中age属性使用的是Integer而不是int类型)
- 引用类型则直接调用hashcode()
- 数组类型则需要遍历数组,依次调用hashcode()