记录一次超大(200+G)数据量导入ES的解决办法
文章目录
- 业务需求
- 特点
- 解决思路
- 解决效果
- 解决方案
- 读
- 写
- 其他
- 结语
业务需求
将12个CSV文件中的数据,共200多G,导入到ES中,要求性能好一些,速度越快越好。
此处我们不讨论需求的合理性,只对处理办法进行讨论。
特点
- 单索引操作,数据量很大
- 数据含有位置数据,可能会涉及经纬度问题
- 需要注意导入性能与速度问题
解决思路
为满足业务需求,该问题可以拆分为两个部分,一个是读取,如何快速读取csv格式文件数据,内存消耗要小,读取速度要快,更要稳定。另一个是写入,写入ES如何做到写入性能最大。
硬件条件:1台8C64G服务器,硬盘足够大(不过是机械的)
解决效果
读写速度可达5000条每秒 其中读 10万条每秒 写 大约5000条每秒
解决方案
读
横向对比
自己写:多线程非IO阻塞式文件流读取,速度达标,但实现麻烦
POI工具包: 性能不高,速度慢
easyexcel:最终方案,10万条一批,速度性能非常好
写
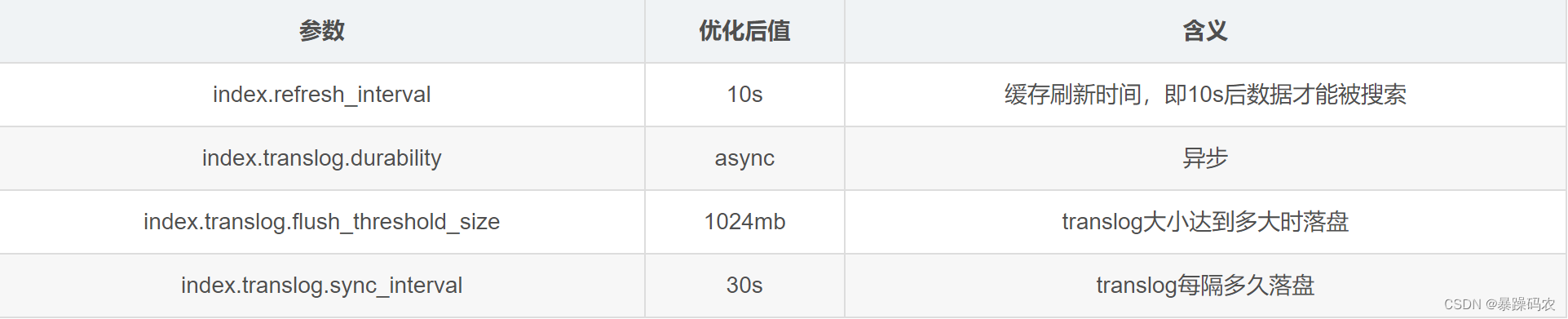
由于服务器操作受限,只能单机ES,针对ES写入性能优化,修改了如下参数
PS:es5以上就不能通过修改es的yml文件来配置了。
kibana示例:
PUT 索引名称/_settings
{
“index” : {
“refresh_interval” : “1m”,
“translog.durability” : “async”,
“translog.flush_threshold_size” : “1024mb”,
“translog.sync_interval” : “30s”
}
}
curl 命令curl -u elastic -XPUT -H "Content-Type: application/json" -d '{"index":{"refresh_interval" : "5m","translog.durability" : "async","translog.flush_threshold_size" : "1024mb","translog.sync_interval" : "30s"}}' localhost:9200/索引名/_settings优化前后差别不是很大,应该还是要上集群,需要注意的是,导入完成后记得将更新时间调整回去
其他
在这个过程中,还遇到了以下问题
- CSV文件内容格式不正确导致抛映射错误异常,csv文件中的数据行不能出现双引号""
- 多表头导致类型不匹配异常
- 文件编码不是utf-8导致的中文乱码问题
近20G的CSV编辑工具选择就非常重要了,我用的EverEdit,虽然收费,但有一个月的免费使用,使用非常流畅,另存为可以修改文件编码格式,批量操作等功能也非常好用,推荐~!
结语
可能这个方案还达不到你的业务需求标准,后面可以考虑ES集群写入效率会更高,如果可以,希望在评论区留下你的解决办法,可以让我学习一下。没有附源码的原因主要和编码没有什么太大的关系,主要是思路和工具的选用,选对了工具就可以了,代码都demo级的东西。