9月24日计算机视觉基础学习笔记——经典机器学习_02
文章目录
- 前言
- 一、决策树
- 二、非监督学习中的 k-means
前言
本文为9月24日计算机视觉基础学习笔记——经典机器学习_02,分为两个章节:
- 决策树;
- 非监督学习中的 k-means。
一、决策树
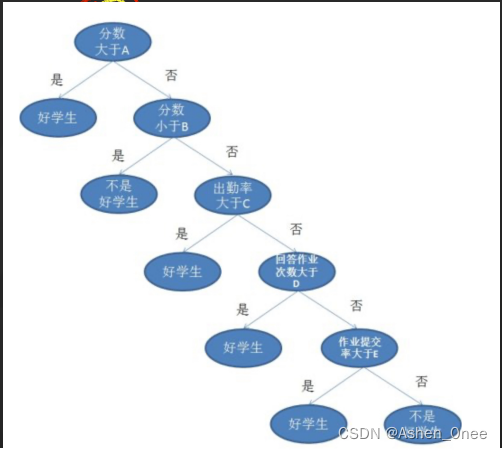
- 信息熵: 熵越小,分得越好,纯度越大。
- 示例:10个样本、3个否、7个是,信息熵为:
∑ i − P i l o g P i = − 0.3 × l o g 0.3 − 0.7 × l o g 0.7 = 0.26 \sum_{i} - P_i\ logP_i = -0.3\times log0.3 - 0.7\times log0.7 = 0.26 i∑−Pi logPi=−0.3×log0.3−0.7×log0.7=0.26
- 示例:10个样本、3个否、7个是,信息熵为:
分类后总熵为0。
决策树代码如下:
import torch
feature_space=[[1., 3., 2., 2., 3., 0.,3.],
[2., 0., 2., 5., 1., 2.,3.],
[3., 2., 3., 3., 2., 3.,2.],
[4., 0., 3., 3., 2., 0.,1.],
[3., 1., 2., 2., 5., 1.,3.],
[1., 4., 3., 3., 1., 5.,2.],
[3., 3., 3., 3., 1., 0.,1.],
[5., 1., 1., 4., 2., 2.,2.],
[6., 2., 3., 3., 2., 3.,0.],
[2., 2., 2., 2., 5., 1.,4.]]
def get_label(idx):
label= idx
return label
def cut_by_node(d,value,feature_space,list_need_cut):
right_list=[]
left_list=[]
for i in list_need_cut:
#import pdb
#pdb.set_trace()
if feature_space[i][d]<=value:
right_list.append(i)
else:
left_list.append(i)
#return right_list,left_list
e1=get_emtropy(list2label(left_list,[0,0,0,0,0,0,0,0,0,0]))
e2=get_emtropy(list2label(right_list,[0,0,0,0,0,0,0,0,0,0]))
n1 = float(len(left_list))
n2 = float(len(right_list))
e = e1*n1/(n2+n1) + e2*n2/(n1+n2)
return e,right_list,left_list
def list2label(list_need_label,list_label):
for i in list_need_label:
label=get_label(i)
list_label[label]+=1
return list_label
def get_emtropy(class_list):
E = 0
sumv = float(sum(class_list))
if sumv == 0:
sumv =0.000000000001
for cl in class_list:
if cl==0:
cl=0.00000000001
p = torch.tensor(float(cl/sumv))
#print(p)
E += -1.0 * p*torch.log(p)/torch.log(torch.tensor(2.))
return E.item()
def get_node(complate,d,list_need_cut):
e = 10000000
node=[]
list_select=[]
complate_select=[]
for value in range(0,8):
complate_tmp=[]
etmp=0
list_select_tmp=[]
sumv=0.000000001
for lnc in list_need_cut:
#import pdb
#pdb.set_trace()
etmptmp,r_list,l_list=cut_by_node(d,value,feature_space,lnc)
etmp+=etmptmp*len(lnc)
sumv+=float(len(lnc))
if len(r_list)>1:
list_select_tmp.append(r_list)
if len(l_list)>1:
list_select_tmp.append(l_list)
if len(r_list)==1:
complate_tmp.append(r_list)
if len(l_list)==1:
complate_tmp.append(l_list)
etmp = etmp/sumv
sumv=0
if etmp<e:
e=etmp
node=[d,value]
list_select=list_select_tmp
complate_select=complate_tmp
for ll in complate_select:
complate.append(ll)
return node,list_select,complate
def get_tree():
all_list=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]
complate=[]
for d in [3,4,2,5,0,1,6]:
node,all_list,complate=get_node(complate,d,all_list)
print("node=%s,complate=%s,all_list=%s"%(node,complate,all_list))
if __name__=="__main__":
get_tree()
概率是个连续量,无法计算 E:
- 纯度: P l V A R ( Y l ) + P r V A R ( Y r ) P_l\ VAR(Y_l) + P_r\ VAR(Y_r) Pl VAR(Yl)+Pr VAR(Yr).
二、非监督学习中的 k-means
-
步骤:
- 设 k=3;
- 从数据中随机取 k个数据;
- 按照距离将其他数据分配给这 k个数据,即将数据聚成了 k类;
- 对每个类内的所有数据求 mean,得到 k个数据;
- 重复3和4,直到停止条件达成。
-
停止条件:
- 数据分类不变化;
- k个数据中心点不再变化;
- 达到设定最大迭代次数。
-
如何增强:
- 选一个数据,作为第一个类中心 C C C;
- 计算其余点到所有类中心的距离;
- 取离所有类中心距离最远的为新的类中心 C i + 1 C_{i+1} Ci+1;
- 重复2和3,直到 i + 1 = k i+1=k i+1=k.