【C语言数据结构】03.双链表
前言
- 本节主要进行C语言数据结构双链表的学习。
目录
- 前言
- 1.双链表介绍
- 2.单循环链表实现
1.双链表介绍
- 单链表中,每个结点包含下一个结点的地址,但没有其先前结点的任何记录,所以单链表只能在一个方向上遍历。
- 这就需要寻找另一种数据结构来克服单链表的这一缺点,这种结构就是双链表。
- 双向链表也是采用的链式存储结构,它与单链表的区别就是每个数据结点中多了一个指向前驱元素的指针域。所以从双向链表的任意一个结点开始都可以很方便的访问其前驱元素和后继元素。
- 由于双链表的每个结点都包含其先前结点的地址,因此可以通过使用存储在每个结点的前一部分内的先前地址来找到关于前一结点的所有细节。
- 因此,双链表与单向链表相比有以下优势:因每个节点都记录了上一个节点,所有插入删除不需要移动元素,可以原地插入删除,可以双向遍历。
- 需要注意的是,操作时涉及到node>next->pre的情况,所以要考虑到node是否为最后一个元素,即node->next==NULL的情况,不然会内存访问出错,造成段错误。

2.单循环链表实现
- 实现内容与前章相同,1.初始化;2.插入节点:头插法、尾插法;3.删除节点;4.遍历链表。
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
typedef struct Node//定义数据结构,包含数据域域next域
{
int data;//data域
struct Node* pre;//pre指针域
struct Node* next;//next指针域
}Node;
Node* initList()//初始化头节点
{
Node* list=(Node*)malloc(sizeof(Node));//开辟空间,新建节点
list->data=0;//链表默认个数为0
list->pre=NULL;
list->next=NULL;//链表为空,故头节点next域为空
return list;
}
void headInsert(Node* list,int data)//头插法
{
Node* node = (Node*)malloc(sizeof(Node));//开辟空间,新建节点
node->data = data;//data给到新建节点的数据域
node->pre = list;//pre指向头节点
node->next = list->next;//新建节点的next指向的是原先链表的第一个节点,也就是头节点指向的节点
if(list->data!=0) list->next->pre=node;//不为空时,原第一个节点的pre前一个节点变成了新节点node
list->next = node;//头节点指向新建节点
list->data++;//插入链表使data域节点数加一
}
void tailInsert(Node* list,int data)//尾插法
{
list->data++;//插入链表使data域节点数加一
Node* node = (Node*)malloc(sizeof(Node));//开辟空间,新建节点
node->data = data;//data给到新建节点的数据域
node->next = NULL;//新建节点指向list
while(list->next!=NULL)//寻找最后一个节点
{
list=list->next;
}
node->pre = list;
list->next=node;//最后一个节点指向新建节点
}
bool delete(Node* list,int data)//删除
{
Node* node=list->next;//保存第一个节点开始,从它开始遍历
while(node!=NULL)//遍历,可使用头节点data进行for循环遍历
{
if(node->data==data)//找到data
{
node->pre->next=node->next;//将前一个节点的next指向要要删除节点的下一个节点
if(node->next!=NULL) node->next->pre=node->pre;//不是最后一个节点,则将下一个节点的pre指向要要删除节点的前一个节点
free(node);//释放要铲除节点的堆内存空间
break;//退出循环
}
node = node->next;//未找到data则往后继续遍历
}
if(node!=NULL)//未遍历到头,说明删除成功
{
list->data--;
return true;
}
else return false;//能遍历到头,说明未找到data,删除失败报错
}
void printList(Node* list)//遍历操作
{
Node* node=list->next;//循环链表的第一个节点给到新建节点node,即头节点的下一个
while(node)
{
printf("%d->",node->data);
node=node->next;
}
printf("NULL\n");
}
int main()
{
Node* list= initList();//初始化头节点,创捷链表节点
headInsert(list,5);
headInsert(list,4);
headInsert(list,3);
headInsert(list,2);
headInsert(list,1);
tailInsert(list,6);
tailInsert(list,7);
tailInsert(list,8);
tailInsert(list,9);
tailInsert(list,10);
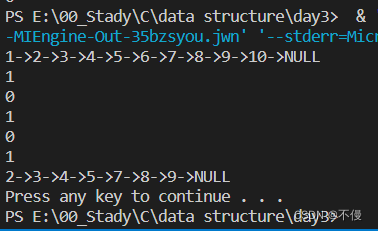
printList(list);
printf("%d\n",delete(list,1));
printf("%d\n",delete(list,11));
printf("%d\n",delete(list,6));
printf("%d\n",delete(list,6));
printf("%d\n",delete(list,10));
printList(list);
system("pause");
}
参考资料:
链接1: UP从0到1带你手撕数据结构全集(C语言版)
链接2: 双链表详解(C语言版)