深度学习目标检测入门论文合集讲解
目标检测
YOLO系列解析,包括最新的:目标检测之YOLO算法:YOLOv1,YOLOv2,YOLOv3,TinyYOLO,YOLOv4,YOLOv5,YOLObile,YOLOF,YOLOX详解
毕设项目演示地址: 链接
毕业项目设计代做项目方向涵盖:
目标检测、语义分割、深度估计、超分辨率、3D目标检测、CNN、GAN、目标跟踪、竞赛解决方案、人脸识别、数据增广、OpenCV、场景文本识别、去雨、机器学习、风格迁移、视频目标检测、去模糊、显著性检测、剪枝、活体检测、人脸关键点检测、3D目标跟踪、视频修复、人脸表情识别、时序动作检测、图像检索、异常检测等
YOLOX

输入端
mosaic+mixup
Backbone
同YOLOv3的Darknet53
后面也有CSP版本
Neck
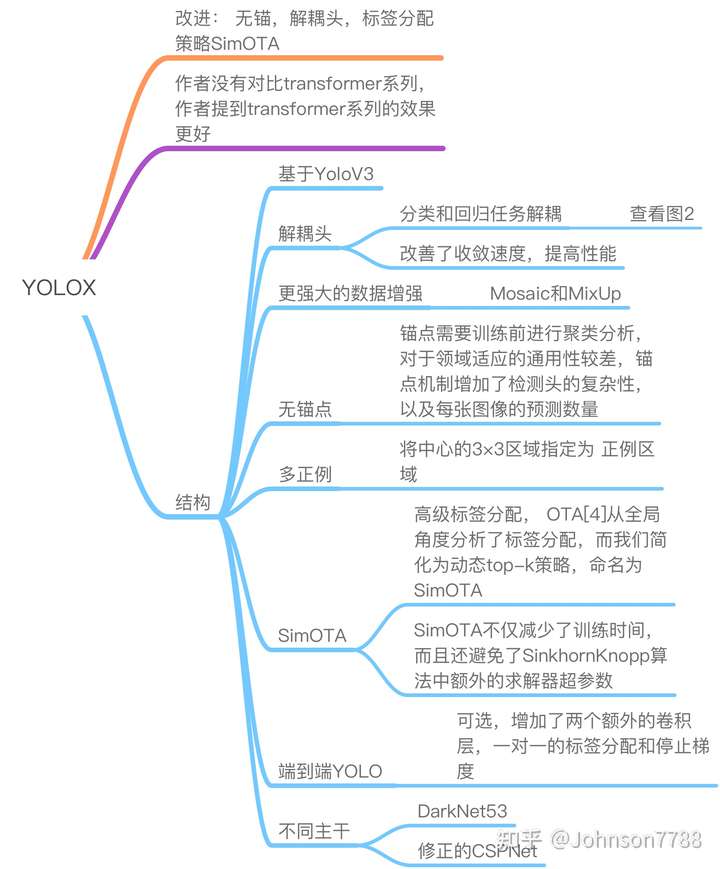
FPN
输出层
End-to-End YOLO:无NMS直接输出
Decoupled Head:解耦头,类别和回归分开。
Anchor-free:直接为每个box预测一个中心偏移和高宽
Multi positives:将GT中心点周围的3×3区域都视为正样本,从而增加正样本的数量。
SimOTA:正负样本选择策略,很麻烦,但很重要
End-to-End(无NMS)
因为掉点,所以并没有使用。
Object detection made simpler by eliminating
heuristic nms——按照这个论文中的方法,添加一个用于PSS分支(Pos-sample selector),来避免使用NMS
根本没看懂怎么做的。。。。
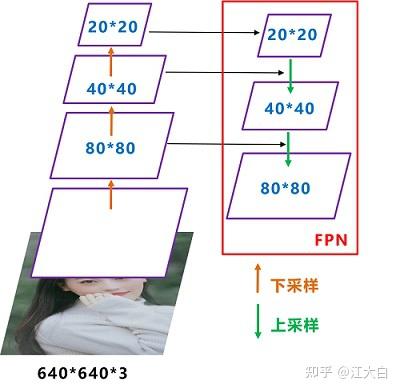
Decoupled Head(轻量解耦检测头)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nTcQIusp-1664027113927)(https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2021%2F0720%2F2e0fe238j00qwjnsj0013c000hs009rg.jpg&thumbnail=650x2147483647&quality=80&type=jpg)]
从上图的Prediction中,我们可以看到,有三个Decoupled Head分支。每个解耦头对应分类、回归、置信度三个分支,是解耦的。
为什么使用Decoupled Head?
- 将模型改为End-to-End时,如果不使用解耦头,性能会下降很多。
- 使用解耦头,网络的收敛速度加快。
- 所以:目前Yolo系列使用的检测头,表达能力可能有所欠缺,没有Decoupled Head的表达能力更好。
- 缺点:增加一些计算量,所以作者使用1×1降维,最终只增加了一点计算量。
anchor-free
anchor的缺点:
(1) 为获得最优检测性能,需要在训练之前进行聚类分析以确定最佳anchor集合,这些anchor集合存在数据相关性,泛化性能较差;
(2) anchor机制提升了检测头的复杂度
(3)anchor-free要比anchor-base少2/3的参数量,因为anchor-base一个位置要预测3个长宽不同的bbox,而free只预测一个。
Multi positives
YOLO是直接把GT中心位置的anchor作为正样本,其他的都是负样本,造成了正样本的严重不平衡。
所以这里将GT中心位置的anchor的3×3领域(共9个位置)都视为正样本,增加了正样本的数量。
SimOTA
简化版的OTA,主要是针对正负样本的选择问题,尤其是一些有歧义的anchor(多个目标都包含该anchor),FCOS会直接将该anchor分配给与其IOU大的GT,而这样分配必然会对其他GT的梯度产生不利影响,因此不能这样分配。
所以SimOTA转换思路:更好的分配策略应该摆脱对每个gt对象进行最优分配的惯例,而转向全局最优的思想,类似于KM匹配中的最优匹配,换句话说,为图像中的所有gt对象找到全局的高置信度分配。
流程如下:
- 初步筛选,确定正样本的候选区域。
以后所有的正样本都是从这个候选区域中选取。
共两种方法:根据中心点来判断、根据目标框来判段(也就是上面的Multi Positives方法)。- 根据中心点来判断:将GT内包含的所有anchor都视为正样本。
- 根据目标框来判断:将GT中心对应的anchor的5×5领域都视为正样本。
- 精细化筛选
这就是SimOTA。- 计算GT和anchor的IOU,并为每个GT分配10个IOU最大的候选框。
- 计算候选框和GT的cost。
cost就是OneNet中提出的包含了位置和分类信息的代价函数。 - 使用IOU确定每个GT的dynamic_k(GT应该匹配的anchor数量)。将10个IOU值求和,然后向下取整,从而确定每个GT应该匹配几个anchor。
- 为每个GT取cost最小的前dynamic_k个anchor作为正样本,其余为负样本。
- 过滤共用的候选框:如果一个anchor匹配多个GT,那么就选cost更小的。
- 至此得到所有的正样本,其余的(8400)全部都是负样本,使用正负样本计算loss。
参考链接
吊打一切YOLO!旷视重磅开源YOLOX:新一代目标检测性能速度担当
深入浅出Yolo系列之Yolox核心基础完整讲解——重点看这个,讲的非常好,很详细的讲解了SimOTA(举例说明了,很明了)
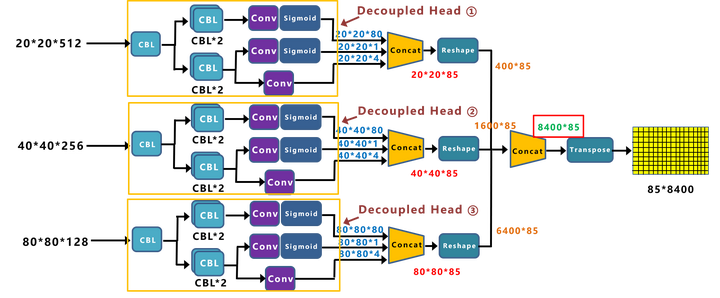
Swin-Transformer
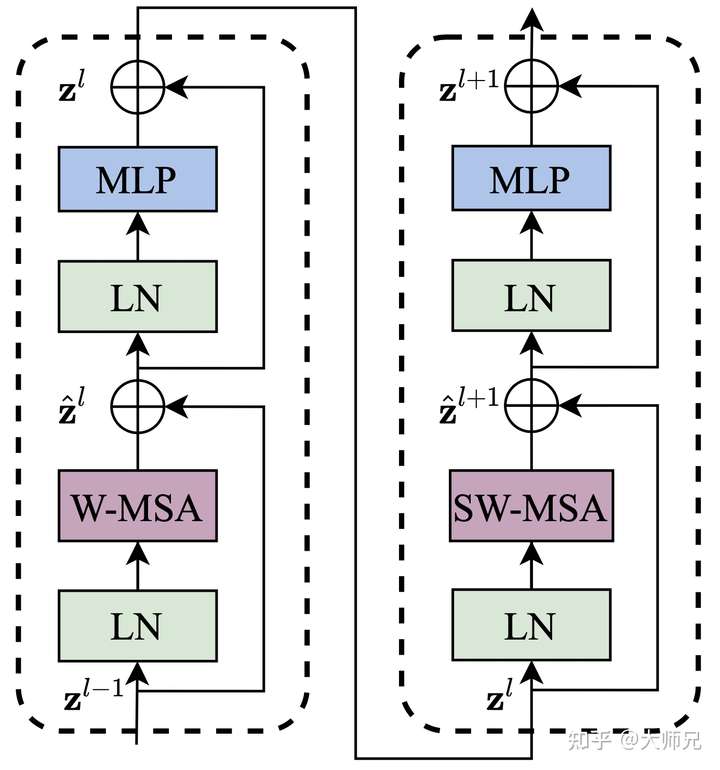
和ViT的区别
ViT直接以小尺寸的图像作为输入,这种直接resize的策略无疑会损失很多信息。
而Swin Transformer的输入是图像的原始尺寸;也使用CNN中最常用的层次网络结构,即随着网络层次的加深,节点的感受野也在不断扩大。
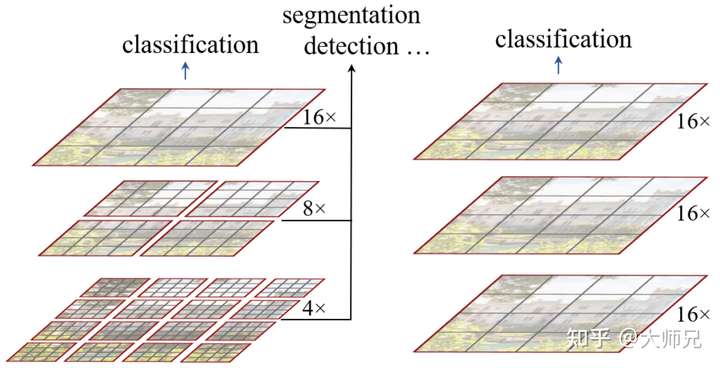
Patch Merging
和YOLOv5中的Focus操作一模一样,为了提高感受野,和Pooling意义一样。
对比Pooling:
优点:不会丢弃任何信息。
缺点:带来了运算量的增加。
(下图最后的全连接不要看)

Window Attention(W-MSA)
传统的Transformer都是基于全局来计算注意力的,因此计算复杂度十分高。而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量。
我们先简单看下公式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5IaYSaqj-1664027113945)(https://www.zhihu.com/equation?tex=Attention%28Q%2C+K%2C+V%29+%3D+Softmax%28%5Cfrac%7BQK%5ET%7D%7B%5Csqrt%7Bd%7D%7D%2BB%29V+%5C%5C)]
主要区别是在原始计算Attention的公式中的Q,K时加入了相对位置编码。后续实验有证明相对位置编码的加入提升了模型性能。
Shifted Window Attention(SW-MSA)
上面的W-MSA,只在每个窗口下计算注意力,window间没有信息交互,因此,提出shifted window实现窗口间的信息交互。
计算方法:
- 同W-MSA,也是在窗口内部计算注意力。
- 但是在计算Attention的时候,让具有相同index QK进行计算,而忽略不同index QK计算结果。
即下图(1c)中,只计算黄色区域和左上角3×3窗口各自的自注意力,其余红色和蓝色的注意力全部忽略。
原因:图像边缘之间的注意力没有意义。——暂时不知道为啥。。。
图(1)SW划分方法:

图(2)实际的SW中的注意力计算方法:
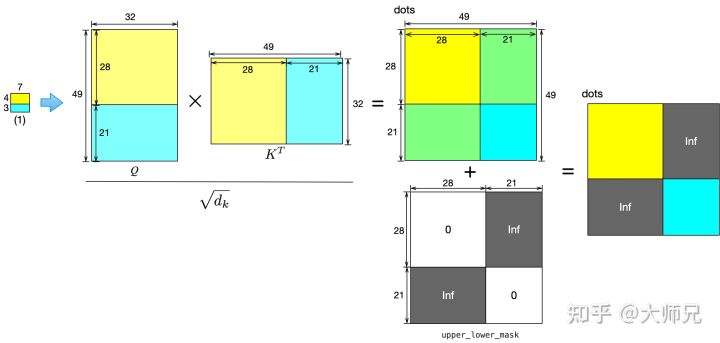
和W-MSA的区别就是,会多出很多小块,而经过上面的图像循环移动之后,会导致不相邻的图像挨边,这样直接使用self-attention就会导致融合不合理区域的信息,所以文中的方法就是在正常的self-attention后,乘一个mask来抑制掉那些不想干的相似度关系,如下图所示。
按照 Swin Transformer 的代码实现 (下面会有讲解),还是做正常的 self-attention (在 window_size 上做),之后要进行一次 mask 操作,把不需要的 attention 值给它置为0。
例1: 比如右上角这个 window,如下图6所示。它由4个 patch 组成,所以应该计算出的 attention map是4×4的。但是6和4是2个不同的 sub-window,我们又不想让它们的 attention 发生交叠。所以我们希望的 attention map 应该是图7这个样子。
因此我们就需要如下图8所示的 mask。
例2: 比如右下角这个 window,如下图9所示。它由4个 patch 组成,所以应该计算出的 attention map是4×4的。但是1,3,7和9是4个不同的 sub-window,我们又不想让它们的 attention 发生交叠。所以我们希望的 mask 应该是图10这个样子。
输出层
由于每个stage的输出都是一个feature map,因此后面直接接上目标检测中的head就可以了。
应该把swin-transformer视为一个backbone,根据具体任务替换相应的head即可。
参考链接
搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(十六)——介绍的非常详细(主要看这个,也有VIT的讲解)
OneNet
无NMS的网络——主要是提出一种新的正负样本选择策略,和SimOTA很像。
anchor-base和anchor-free都存在多个预测框对应一个GT的问题,所以必须使用NMS。而NMS也涉及到超参数的设置,因此设想如何不要产生冗余的预测框,从而不使用NMS。
改进点
目前已有的标签分配方法主要有两种:基于anchor与GT的IOU分配(anchor-based:YOLO、RCNN),和基于GT中心点距离的分配(anchor-free:CenterNet、FCOS、YOLOX)。
可以看出以上方法,都只考虑了位置代价来分配标签。在缺少分类代价的情况,单独的位置代价将将导致推理过程中产生很多冗余的高置信度得分框,从而使 NMS 成为必要的后处理。
因此,本文提出将分类损失引入标签分配之中,同时提出最小代价分配的标签分配方法(就这一个点,通过在标签分配中引入分类损失,从而达到去除NMS的作用)。
引入分类的匹配损失
之前方法是通过IoU或者是点的距离来进行匹配的,我们把这种方式总结为位置损失,位置损失定义为:
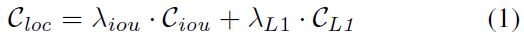
其中, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2MsEhHXS-1664027113952)(https://www.zhihu.com/equation?tex=C_%7Biou%7D)] 是IoU损失, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fmf4MAQJ-1664027113956)(https://www.zhihu.com/equation?tex=C_%7BL1%7D)] 是L1损失,在框分配中, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JymiBIUL-1664027113958)(https://www.zhihu.com/equation?tex=%5Clambda_%7BL1%7D%3D0)] ,在点分配中, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9AJvHNBo-1664027113960)(https://www.zhihu.com/equation?tex=%5Clambda_%7Biou%7D%3D0)] 。
但是,检测是个多任务,既有分类又有回归,所以只使用位置损失并不是最优的,会导致高置信度的冗余框的出现,导致后处理的时候需要NMS。因此,我们把分类损失引入匹配损失中,定义如下:
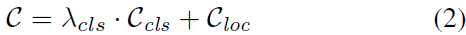
分类损失使用交叉熵,定位损失使用L1。在dense的检测器中,**分类损失可以使用Focal Loss,定位损失可以同时包含L1和GIoU Loss。**最终代价如下:
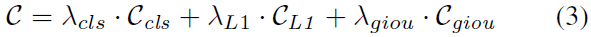
最小代价分配
很简单,等同于CenterNet的分配方法:CenterNet是将GT中心点落入的位置记为正样本,其余都是负样本。
这里对于每个真值,在所有样本中仅选择一个最小代价样本作为正样本,其余都是负样本。该方法不涉及手动制定的启发式规则或者复杂的二分图匹配。
以下为CenterNet和OneNet的正样本对比。在CenterNet中,正样本都在gt框附件的网格点上,这种方法对框的回归是有好处的,但是对正负样本的分类并不是最好的选择,比如第一列图片上的人,第一排是CenterNet的框,由于人身体的扭曲,导致了网格点定位到了人身体的边缘上,并不是特征区分最明显的区域。而对于OneNet,可以看到,正样本定位到了人的身体上,是最具特征区分性的地方。
图 5:正样本的可视化。第 1 行是位置代价。第 2 行是分类代价与位置代价。正网格点由圆圈突出显示,画出来的边框为真值框。仅有位置代价分配的正样本是最接近真值框中心的网格点。添加分类代价,使得正样本成为更具识别区域的网格点。例如图 5 中斑马的头部。
参考链接
这两个链接内容差不多,看哪一个都可以
无需NMS的目标检测,OneNet
OneNet论文解读:一阶段的端到端物体检测器,无需NMS
PSS
End-to-End
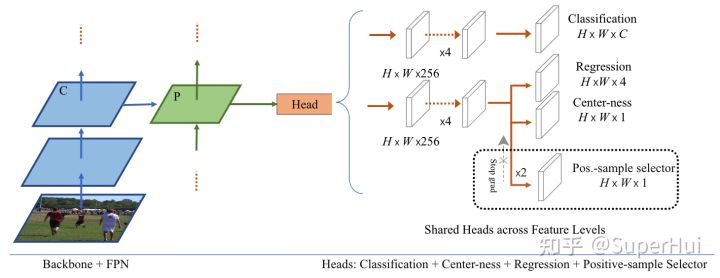
就是在最后增加了一个PSS分支,用来代替NMS的,并提出了与其相匹配的loss,就这两点。
inference 的时候,最终 bbox 得分是 $\sigma(pss)·\sigma(s)·\sigma(ctr) $吗,和原始 FCOS 相比,就多乘一个 σ ( p s s ) \sigma(pss) σ(pss),然后正负样本是直接对这个数进行排序,取topk得到的,无NMS过程。
正负样本选择:FCOS是一个目标对应多个正样本,而PSS就是从多个正样本中选择一个最优的正样本来训练PSS,(选择依据就是分类损失+回归损失,类似OneNet)