ElasticSearch入门笔记
全文检索
是 一种非结构化数据的搜索方式
结构化数据一般存入数据库,使用sql语句即可快速查询。但由于非 结构化数据的数据量大且格式不固定,我们需要采用全文检索的方 式进行搜索。全文检索通过建立倒排索引加快搜索效率。
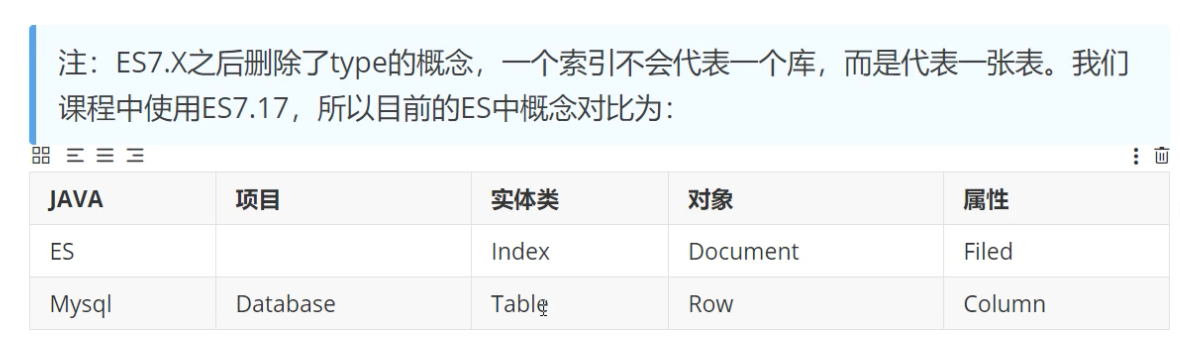
索引
将数据中的一部分信息提取出来,重新组织成一定的数据结构,我 们可以根据该结构进行快速搜索,这样的结构称之为索引。 索引即目录,例如字典会将字的拼音提取出来做成目录,通过目录 即可快速找到字的位置。
索引分为正排索引和倒排索引。
docker run --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=singlenode" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --name='elasticsearch' --net elastic -d elasticsearch:7.17.0
docker run --name kibana --net elastic --link elasticsearch:elasticsearch -p 5601:5601 -d kibana:7.17.0
docker run --name kibana --restart=always -e ELASTICSEARCH_URL=http://43.138.222.42:9200 -p 5601:5601 -d kibana:7.8.0
Elasticsearch常用操作_文档操作
创建有结构的索引
PUT /索引名
{
"mappings":{
"properties":{
"域名1":{
"type":域的类型,
"store":是否单独存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
}
如:
PUT /student1
{
"mappings": {
"properties": {
"id":{
"type": "integer"
},
"name":{
"type": "text"
},
"age":{
"type": "integer"
}
}
}
}
删除索引
DELETE 索引名
如: DELETE student
-
新增/修改文档 :id值存在就是修改,不存在就是新增
注:id值不写时自动生成文档id,id和已有id重复时修改文档
POST /索引/_doc/[id值]
{
"field名":field值
}
如:
POST /student1/_doc/1
{
"id":1,
"name":"tanyang",
"age":22
}
-
根据id查询文档
GET /索引/_doc/id值 如:GET student1/_doc/1 -
删除文档
DELETE /索引/_doc/id值
```
-
根据id批量查询文档
GET /索引/_mget { "docs":[ {"_id":id值}, {"_id":id值} ] } -
查询所有文档
GET /索引/_search { "query": { "match_all": {} } } -
修改文档部分文字字段
POST /索引/_doc/id值/_update { "doc":{ 域名:值 } }
Elasticsearch执行删除操作时,ES先标记文档为deleted状态, 而不是直接物理删除。当ES存储空间不足或工作空闲时,才会 执行物理删除操作。 Elasticsearch执行修改操作时,ES不会真的修改Document中 的数据,而是标记ES中原有的文档为deleted状态,再创建一个 新的文档来存储数据。
Elasticsearch常用操作_域的属性
PUT /索引名
{
"mappings":{
"properties":{
"域名1":{
"type":域的类型,
"store":是否单独存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
}
index
建立倒排索引: 给某个域添加"index":true才能建立倒排索引
在声明的时候声明域名 添加"index":true
查询"name":“love” 就能查询 i love you 的文档 这就是倒排索引
该域是否创建索引。只有值设置为true,才能根据该域的关键词查 询文档。
// 根据关键词查询文档
GET /索引名/_search
{
"query":{
"term":{
搜索字段: 关键字
}
}
}
store

是否单独存储。如果设置为true,则该域能够单独查询。
// 单独查询某个域:
GET /索引名/_search
{
"stored_fields": ["域名"]
}
分词器
standard analyzer:Elasticsearch默认分词器,根据空格和标点 符号对英文进行分词,会进行单词的大小写转换。
默认分词器是英文分词器,对中文的分词是一字一词。
语法:
GET /_analyze
{
"text":测试语句,
"analyzer":分词器
}
使用:
GET /_analyze
{
"text":"I love Spring",
"analyzer": "standard"
}
查询结果:
{
"tokens" : [
{
"token" : "i",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "love",
"start_offset" : 2,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "spring",
"start_offset" : 7,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
IK分词器
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词 工具包。提供了两种分词算法:
-
ik_smart:最少切分
-
ik_max_word:最细粒度划分
测试分词器效果
GET /_analyze
{
"text":"测试语句",
"analyzer":"ik_smart/ik_max_word"
}
IK分词器词典
IK分词器根据词典进行分词,词典文件在IK分词器的config目录中。 main.dic:IK中内置的词典。记录了IK统计的所有中文单词。 + IKAnalyzer.cfg.xml:用于配置自定义词库。
<properties>
<comment>IK Analyzer 扩展配置
</comment>
<!--用户可以在这里配置自己的扩展字典 --
>
<entry
key="ext_dict">ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词
字典-->
<entry
key="ext_stopwords">ext_stopwords.dic</ent
ry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry
key="remote_ext_dict">words_location</entr
y> -->
<!--用户可以在这里配置远程扩展停止词字
典-->
<!-- <entry
key="remote_ext_stopwords">words_location<
/entry> -->
</properties>
拼音分词器
将拼音分词器安装到es的plugins目录后重启
拼音分词器只能粉刺所有字的首字母拼音和每个字的拼音 不能分成词组拼音。
测试分词效果
GET /_analyze
{
"text":测试语句,
"analyzer":pinyin
}
自定义分词器
自定义分词器配置

PUT /索引名
{
"settings" : {
"analysis" : {
"analyzer" : {
"ik_pinyin" : { //自定义分词器名
"tokenizer":"ik_max_word", // 基本分词器
"filter":"pinyin_filter"
// 配置分词器过滤
}
},
"filter" : { // 分词器过滤时配置另一
个分词器,相当于同时使用两个分词器
"pinyin_filter" : {
"type" : "pinyin", // 另一
个分词器
// 拼音分词器的配置
"keep_separate_first_letter" : false, // 是否
分词每个字的首字母
"keep_full_pinyin" :
true, // 是否分词全拼
"keep_original" : true,
// 是否保留原始输入
"remove_duplicated_term"
: true // 是否删除重复项
}
}
}
},
"mappings":{
"properties":{
"域名1":{
"type":域的类型,
"store":是否单独存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
测试自定义分词器
GET /索引/_analyze
{
"text": "你好百战程序员",
"analyzer": "i love spring"
}
1.查询students索引下的全部文档
GET /students/_search
{
"query":{
"match_all": {}
}
}
2.match:全文检索。将查询条件分词后再进行搜索。
条件查询 查询students索引下的info "JAVA很好的会进行分词查询"
GET /students/_search
{
"query": {
"match": {
"info": "Java很好的"
}
}
}
注:在搜索时关键词有可能会输入错误,ES搜索提供了自动 纠错功能,即ES的模糊查询。使用match方式可以实现模糊 查询。模糊查询对中文的支持效果一般,我们使用英文数据 测试模糊查询。
GET /students/_search
{
"query": {
"match": {
"info":{
"query":"love",
"fuzziness":2
}
}
}
}
range:范围搜索。对数字类型的字段进行范围搜索
{
"query":{
"range":{
搜索字段:{
"gte":最小值,
"lte":最大值
}
}
}
}
gt/lt:大于/小于
gte/lte:大于等于/小于等于
match_phrase:
短语检索。搜索条件不做任何分词解析,在搜 索字段对应的倒排索引中精确匹配。
{
"query":{
"match_phrase":{
搜索字段:搜索条件
}
}
}
term/terms:
单词/词组搜索。搜索条件不做任何分词解析,在 搜索字段对应的倒排索引中精确匹配
{
"query":{
"term":{
搜索字段: 搜索条件
}
}
}
{
"query":{
"terms":{
搜索字段: [搜索条件1,搜索条件2]
}
}
}
Elasticsearch搜索文档_复合搜索
GET /索引/_search
{"query": {
"bool": {
// 必须满足的条件
"must": [
搜索方式:搜索参数,
搜索方式:搜索参数
],
// 多个条件有任意一个满足即可
"should": [
搜索方式:搜索参数,
搜索方式:搜索参数
],
// 必须不满足的条件
"must_not":[
搜索方式:搜索参数,
搜索方式:搜索参数
]
}
}
}
Elasticsearch搜索文档_结果排序
ES中默认使用相关度分数实现排序,可以通过搜索语法定制化排 序。
默认是按照相关度排序的 _source
GET /索引/_search
{
"query": 搜索条件,
"sort": [
{
"字段1":{
"order":"asc"
}
},
{
"字段2":{
"order":"desc"
}
}
]
}
Elasticsearch搜索文档_分页查询
GET /索引/_search
{
"query": 搜索条件,
"from": 起始下标,
"size": 查询记录数
}
Elasticsearch搜索文档_高亮查询
我们可以在关键字左右加入标签字符串,数据传入前端即可完成高 亮显示,ES可以对查询出的内容中关键字部分进行标签和样式的设 置。
GET /索引/_search
{
"query":搜索条件,
"highlight":{
"fields": {
"高亮显示的字段名": {
// 返回高亮数据的最大长度
"fragment_size":100,
// 返回结果最多可以包含几段不连续
的文字
"number_of_fragments":5
}
},
"pre_tags":["前缀"],
"post_tags":["后缀"]
}
}
实战
@Document(indexName = "product",createIndex
= true)
@Data
public class Product {
@Id
@Field(type = FieldType.Integer,store =
true,index = true)
private Integer id;
@Field(type = FieldType.Text,store =
true,index = true,analyzer =
"ik_max_word",searchAnalyzer =
"ik_max_word")
private String productName;
@Field(type = FieldType.Text,store =
true,index = true,analyzer =
"ik_max_word",searchAnalyzer =
"ik_max_word")
private String productDesc;
}
@Document:标记在类上,标记实体类为文档对象,一般有如 下属性: indexName:对应索引的名称 createIndex:是否自动创建索引
@Id:标记在成员变量上,标记一个字段为主键,该字段的值会 同步到ES该文档的id值。
@Field:标记在成员变量上,标记为文档中的域,一般有如下 属性: type:域的类型 index:是否创建索引,默认是 true store:是否单独存储,默认是 false analyzer:分词器 searchAnalyzer:搜索时的分词器