我在windows环境下的YOLOV3环境搭建过程
我的操作系统系统为windows11,采用的python版本是python37,如何安装python就不说了。
一、安装pytorch
1.1安装过程
首先在安装pytorch之前,先要安装CUDA,因为一般我们都是用GPU去跑深度学习程序。具体安装过程我是参考的以下链接安装成功的:
Pytorch安装,这一篇就够了,绝不踩坑_孔德浩的博客-CSDN博客_pytorch安装
【超详细】windows10系统下深度学习环境搭建CUDA11.3+cuDNN,以及tensorflow,Keras,pyTorch对应版本_勋章DhR的博客-CSDN博客
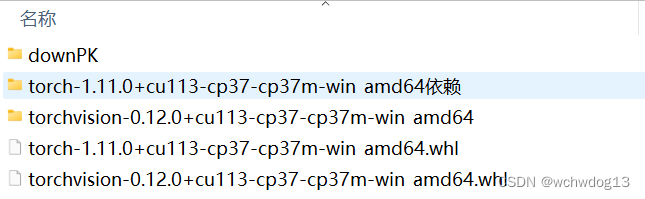
安装的pytorch相关软件版本如下图:
最后,输入以下不报错,则说明安装pytorch成功:
import torch
from torch import nn
import torchvision
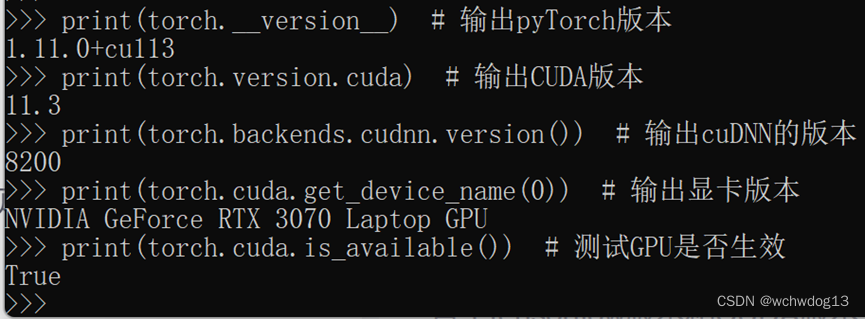
输入以下,输出相关结果则说明GPU环境配置成功:
print(torch.__version__) # 输出pyTorch版本
print(torch.version.cuda) # 输出CUDA版本
print(torch.backends.cudnn.version()) # 输出cuDNN的版本
print(torch.cuda.get_device_name(0)) # 输出显卡版本
print(torch.cuda.is_available()) # 测试GPU是否生效
1.2下载whl依赖包
我现在有torch-1.11.0+cu113-cp37-cp37m-win_amd64.whl包,我想获取该包的依赖包。可以执行x下面命令,依赖包即下载到了downPK目录中。当然,如果你想在线安装,可以跳过该命令,直接使用pip install ...进行安装。
pip download -d D:\software\python\PyTorch\downPK torch-1.11.0+cu113-cp37-cp37m-win_amd64.whl二、YOLOV3下载
下载地址为:
https://download.csdn.net/download/wchwdog13/86669879
三、数据信息标注
3.1深度学习标注工具下载
我采用的标注工具为labelmev5.0.1,可以在网上下载到。
3.2数据标注
我一共标注了8张图片,共有2个目标分类,分别为ship和ball,其标注界面如下:

标注完成后,为每张图片生成一个json文件,json文件中主要记录了图片中的每个标记框信息,如下图:

其中label表示标注框的类别为ship,points为一个二维数组,第一个元素为矩形框的左上角(x1,y1),第二个元素为矩形框的右下角(x2,y2)。
四、生成模型配置文件
之前下载的PyTorch-YOLOv3项目目录如下:

进入config文件夹,执行create_custom_model.sh文件即可生成PyTorch-YOLOv3的模型配置文件, create_custom_model.sh是linux环境下的执行文件,而当前的环境为windows,可以使用构建git运行该文件,我下载的git版本为Git-2.37.1-64-bit.exe,安装成功后,在config目录中右击鼠标,点击Git Bash Here,进入终端,如下图所示。

 在该终端环境可运行linux命令,输入命令bash create_custom_model.sh 2,其中参数2是指的是任务的类别(即前面提到的ship和ball),如下图:
在该终端环境可运行linux命令,输入命令bash create_custom_model.sh 2,其中参数2是指的是任务的类别(即前面提到的ship和ball),如下图:

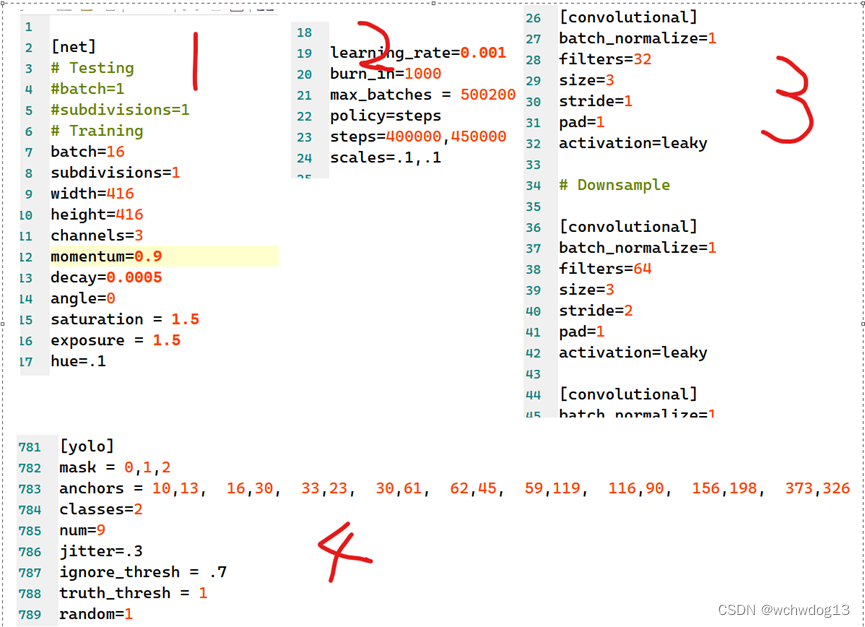
回车运行成功,在当前目录中生成了一个名为yolov3-custom.cfg的文件,该文件中包含了YOLOV3的网络架构和相关配置,如下图,其中1、2为卷积神经网络训练时的相关参数设置,3为卷积神经网络结构,4为yolo相关参数,anchors为9个预测框的形状大小,classes代表2个类别等。
五、标签格式转换(labelme生成标签格式转yolo所需标签格式)
在前面,我使用labelme工具对每张图像进行标注,对为每张图像生成了对应的json文件,json文件通过矩形标注框的左上角(x1,x2)和右下角(y1,y2)进行描述,而yolo所需标签格式为(Cx,Cy,W,H),Cx和Cy为目标预测框中心点位位格子的偏移量,映射到区间为0-1,W和H为预测框的宽和高,这部分知识点可以查阅YOLOV3的相关论文解析。因此需要进行转换,下面的代码为转换所需的代码(也可到这个地址进行下载:https://download.csdn.net/download/wchwdog13/86695113):
import json
import os
name2id = {'ship': 0, 'ball': 1} # 标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = 'D:\\development\YOLO\\数据集\\train\\txt\\' + json_name[0:-5] + '.txt'
# 存放txt的绝对路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312', errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = 'D:\\development\YOLO\\数据集\\train\\json\\'
# 存放json的文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
print(json_name)
decode_json(json_floder_path, json_name)运行后,生成的txt文件内容如下图:

六、数据准备
将相关数据放入\data\custom路径中相应子目录或文件中,该路径如下:

6.1放置图片
将图片放入images目录中,这里我共放了8张图片,当然太少了,我只是为了测试。如下图:

6.2放置标签文件
将前面labelme工具生成并经过转换得到的标签放入labels目录中,如下图:

标签名和图片名必须是相同的,在训练时,程序才能正确找到每张图片对应的标签文件。
6.3修改classes.names文件
将classes.names文件内容改为任务中的类别名字(即ship和ball两类),如下图:

需要注意的是,在最后一行需要加一个回车。
6.4 设置训练用图片
在train.txt中写入参加训练的图片路径和名称,如下图:

由于我的图片比较少,为了进行测试,我让全部的图片都参与了训练。
6.5设置校验用图片
在valid.txt中写入参加校验的图片路径和名称,如下图:
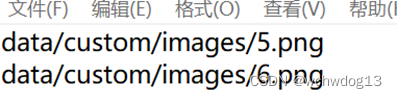
由于我的图片比较少,为了进行测试,我从参与训练的图片中取了2张参与校验。
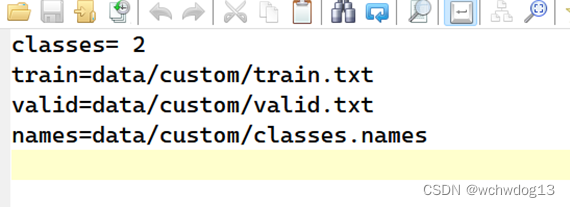
6.6设置config/custom.data文件内容
前面设置了train.txt、valid.txt和classes.names等文件,为了使程序能找到这些文件,还需要设置config/custom.data文件内容,如下图:
七、训练
7.1pycharm准备
我采用的集成开发环境为pycharm,由于我新安装了pytorch等环境,因此需要在pycharm中对pytorch相关程序进行拦截配置。首先打开pycharm,在file中点击setting,如下图:
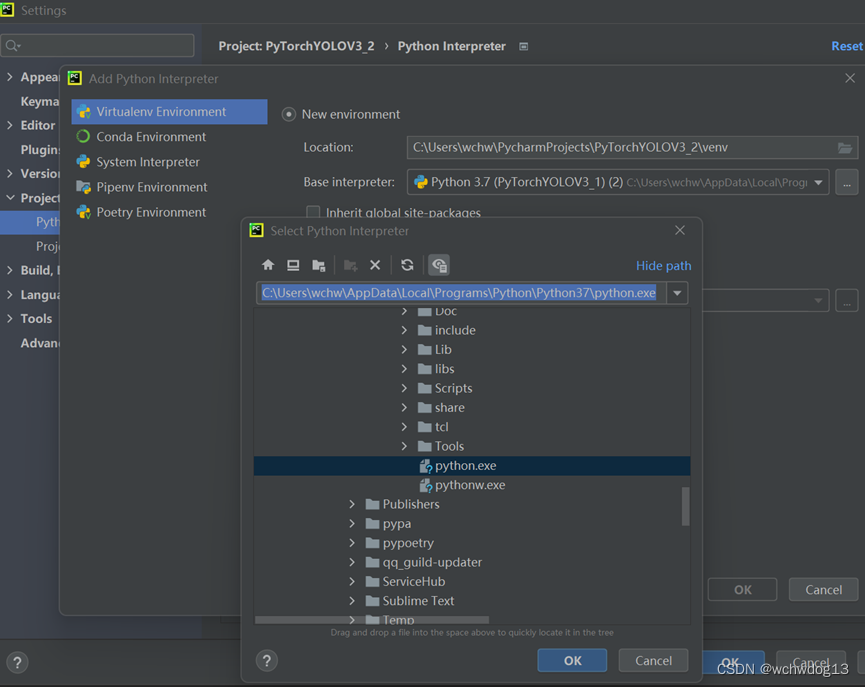
在setting界面中点击下图所示红圈,并选择add选项,在弹出的窗口中选择我用于安装pytorch的python.exe。即完成。

 在pycharm中创建名为PyTorchYOLOV3_3的项目,在创建项目界面中选择我之前配置的python.exe,如下图所示:
在pycharm中创建名为PyTorchYOLOV3_3的项目,在创建项目界面中选择我之前配置的python.exe,如下图所示:

创建项目成功后,将PyTorch-YOLOv3项目内容复制到创建的pycharm项目中,并做出相应调整,如下图所示:
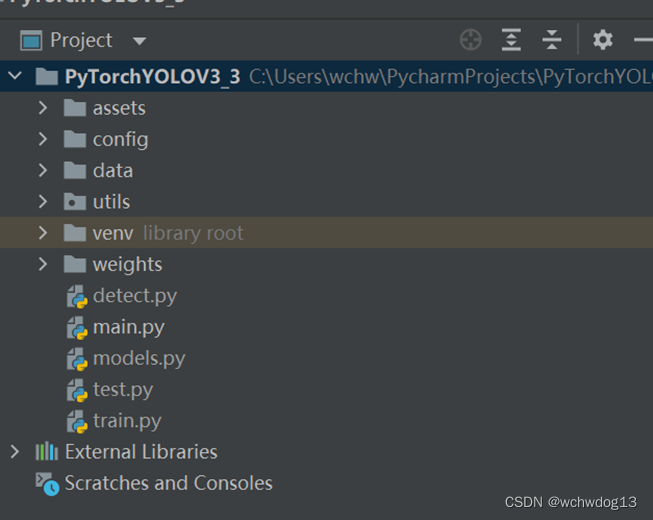
7.2参数设置与训练
需要将原PyTorch-YOLOv3项目中的相关环境配置参数设置为当前pycharm项目的可运行环境。
修改train.py:
parser.add_argument("-m", "--model", type=str, default="config/yolov3-custom.cfg", help="Path to model definition file (.cfg)")
parser.add_argument("-d", "--data", type=str, default="config/custom.data", help="Path to data config file (.data)")

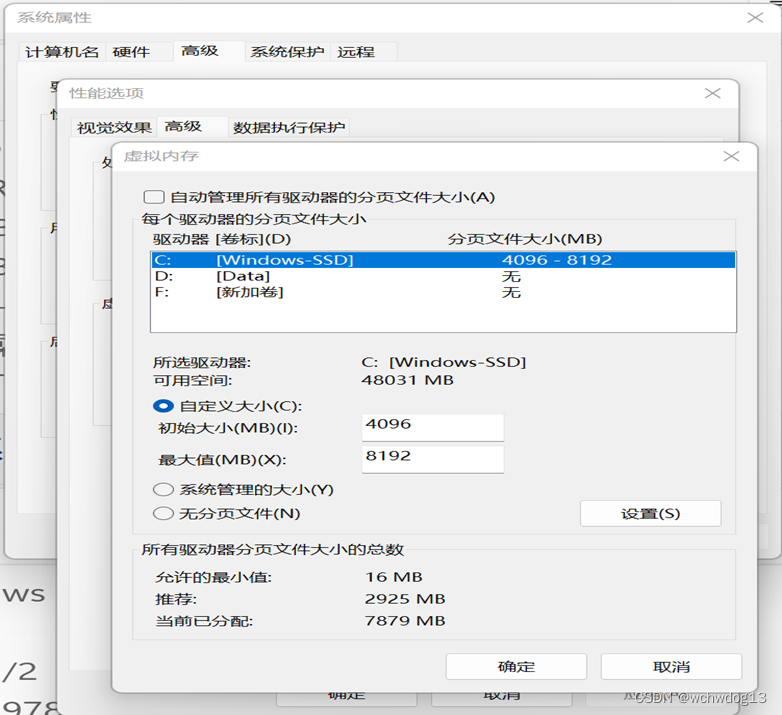
可能需要设置虚拟内存,如下图:
然后再pycharm中运行train.py,如果报“OSError: [WinError 1455] 页面文件太小,无法完成操作。”的错误,如下图所示,则将train.py中的n_cpu置为0,如下所示:

![]() 再次执行train.py,则开始训练过程,如下:
再次执行train.py,则开始训练过程,如下:

训练完成后,在checkpoints目录中即生成训练的模型,这里默认共300个epochs,生成了300个模型,如下图:

7.3预测
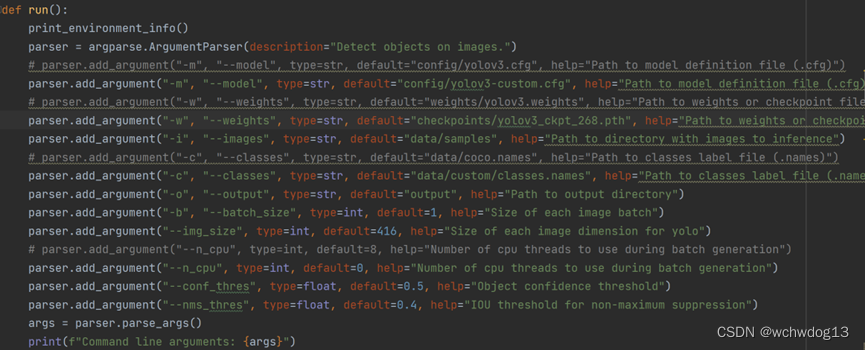
取得训练的模型后,我使用该模型进行预测。对detect.py文件进行相应参数的修改,如下:
parser.add_argument("-m", "--model", type=str, default="config/yolov3-custom.cfg", help="Path to model definition file (.cfg)")
parser.add_argument("-w", "--weights", type=str, default="checkpoints/yolov3_ckpt_268.pth", help="Path to weights or checkpoint file (.weights or .pth)")
parser.add_argument("-c", "--classes", type=str, default="data/custom/classes.names", help="Path to classes label file (.names)")
parser.add_argument("--n_cpu", type=int, default=0, help="Number of cpu threads to use during batch generation")
截图为:
将预测的图片放入data/samples目录中,同时删除output目录下的文件,如下:

这里只是个人学习测试,所以我还是用训练的8张图片来进行预测用。
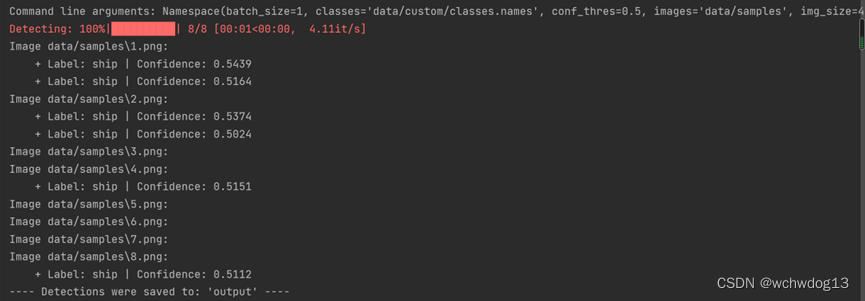
然后执行detect.py文件,进行预测。如下图:
再进入output目录,里面为图片预测结果,随便打开一张图片,如下所示:
